Computer Vision - 3) AlexNet, Fine Tuning, RCNN
R-CNN 모델은 Object Detection 모델입니다. 입력 이미지에 대해 다중객체의 위치를 찾고(Localization), Class를 분류(Classification)하는 작업을 진행합니다. R-CNN 모델은 2stage detector로, "물체가 있을만한 Region 후보를 추출하고"-"각 Region에 대해 classification"을 수행하는 두 단계로 이뤄져 있습니다. R-CNN에서는 기존에 미리 학습된 CNN모델을 사용하는데 먼저 그 모델에 대해 알아보겠습니다.
AlexNet
AlexNet은 2012년 이미지처리 대회에서 우승을 차지한 Image Classification CNN모델입니다. 기존 영상처리 알고리즘들의 50%대의 성능을 단번에 80%대로 끌어올려 딥러닝 부흥의 포문을 열었다고 평가받고 있습니다. AlexNet의 구조는 아래와 같습니다.
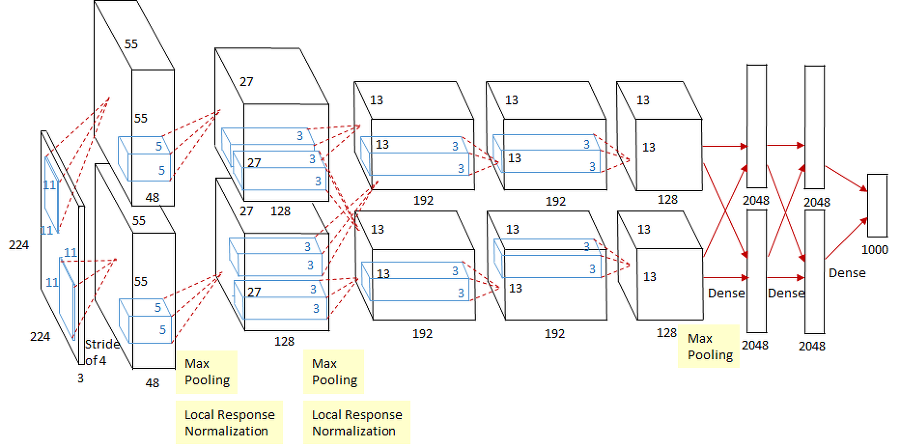
언뜻보면 복잡해 보이지만 크게 합성곱 연산을 수행하는 Convolution layer와 Fully-Connected Layer 두 가지로 이뤄져 있습니다. 그림을 보면, 병렬연산을 위해 모델을 위아래로 두개로 나눠서 학습합니다.
227x227x3 이미지가 입력으로 들어오면(그림에서는 224로 typo가 있습니다.)
1,2,3,4,5 번째의 Convolution layer를 통해 합성곱 연산을 진행하게 되고 ( 활성화 함수 : ReLU ),
6,7,8 번째의 FC layer를 통해 Class에 속할 확률을 구합니다. ( 활성화 함수 : ReLU, ReLU, Softmax )
총 파라미터의 개수는 약 6천만개이고, ImageNet Dataset으로 학습되었습니다. 학습시간은 'GTX 580 3GB GPU' 2대를 사용하여 5~6일이 걸린다고 합니다. 실제로 사용할때는 이 parameter들을 처음부터 학습시키면 시간이 오래걸리므로 이미 학습된 parameter들을 사용해 fine tuning을 거친 뒤 사용하게 됩니다.
AlexNet에서 성능향상을 위해 사용한 방법들
ReLU함수를 활성화 함수로 사용하여 더 빠르게 학습을 진행시켰습니다.(Tanh 대비 6배 빠른 속도)
Dropout을 사용했는데 이는 학습할 때 FC layer에서 일부 뉴런을 비활성화 시키는 방법입니다. Overfitting을 막고 Ensemble과 유사한 효과를 줍니다.
Overlapping Pooling, 즉 Kernel크기보다 Stride를 작게하는 방법입니다. Non-overlapping Pooling보다 차원수를 조금씩 줄이는 방법으로 에러율을 줄이는데 효과가 있습니다.
Local Response Normalization(LRN) 생물학의 lateral inhibition개념을 모방한 방법으로 강하게 활성화된 뉴런의 주변에 대해 normalization을 실행합니다.
Data Augmentation 과적합을 막기위해 데이터양을 늘리는 방법입니다. 하나의 이미지를 변형시켜 여러 장의 비슷한 이미지를 만들어 내는것 입니다.
Fine Tuning
Fine Tuning은 이미 학습되어 있는 기존 모델(Pre-trained model)을 다른 데이터셋에 맞게 변형시켜 parameter를 학습시키는 방법을 말합니다. 말 그대로 모델을 튜닝해서 사용하는것 입니다. 이렇게 학습시키는것을 Transfer Learning(전이학습)이라고 합니다.
앞에서 언급한 AlexNet의 경우 학습에 5-6일이 걸리는데 이를 토대로 Fine Tuning을 진행하면 데이터셋에 따라 몇시간, 혹은 몇십분 이내로 학습이 가능합니다.
직관적으로 생각해보면, Large Dataset을 학습시킨 AlexNet, VGG16 등의 모델의 CNN부분에서는 일반적인 사물들의 feature를 학습하고 FC 부분에서 해당 feature를 바탕으로 분류를 진행합니다.
다양한 class에 대해 많은 사진을 가지고 학습을 했으므로 대부분의 general feature들이 학습되었다고 가정할 수 있고, 분류에 해당하는 FC부분만 새로 학습하거나 낮은 learning_rate로 CNN부분을 일부 학습함으로써 좋은 성능을 낼 수 있습니다.
Fine Tuning도 다양한 전략이 존재합니다.(주로 기존의 Learning-rate 의 1/10정도로 학습 진행합니다. 왜냐하면 만약 높은값의 LR을 사용하면 새 데이터셋에 맞춰 전부 업데이트되어 전이학습을 하는 이유가 없어지기 때문입니다.)
- CNN과 FC 전부 새로 학습시키기
- CNN의 일부와 FC 새로 학습시키기
- FC만 새로 학습시키기
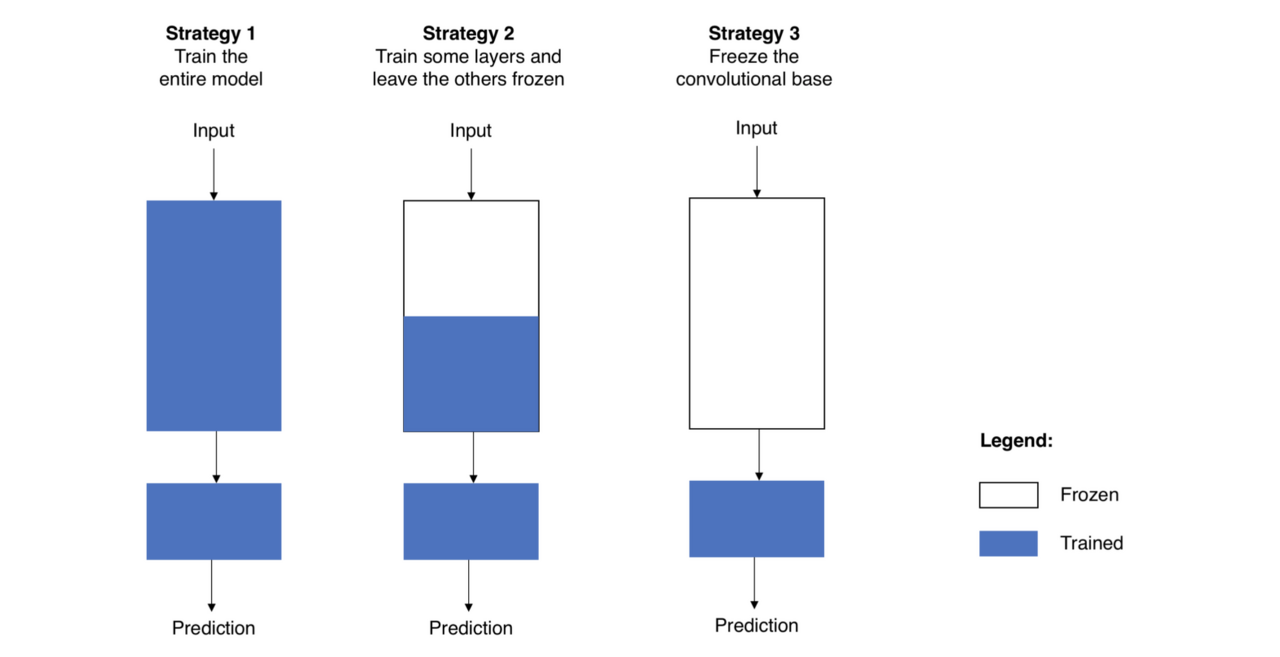
전체 모델을 새로 학습시키는 경우는, Pre-trained 모델과 전혀 다른 dataset을 학습시키며 데이터셋이 큰 경우입니다.
CNN의 일부계층과 FC를 새로 학습시키는 경우는 데이터셋이 충분하고, 기존에 Pre-trained 된 데이터셋과 비슷한 특징을 가지는 경우입니다. CNN의 경우 낮은 레벨의 계층(입력과 가까운부분)은 일반적인 특징을 나타내고, 높은 레벨의 계층(출력과 가까운 부분)은 문제에 따라 달라지는 구체적인 특징을 추출합니다. 기존 데이터셋과 유사한 데이터셋이므로 시간절약을 위해 CNN의 높은 레벨의 계층만 fine-tuning을 진행합니다. 이때 Learning-rate는 기존의 1/10값으로 학습을 진행합니다.
FC만 학습하는 경우는 데이터셋이 적지만, 기존의 pre-trained dataset과 비슷한 특징을 가지는 경우입니다. 이 때, CNN layer에도 학습을 진행하면 데이터가 적기때문에 over-fitting문제가 발생합니다. 따라서 FC layer에 대해서만 Fine-tuning을 진행합니다.
그렇다면 기존 데이터셋과 특징이 다르면서 데이터양이 적으면 어떻게 해야할까요? CNN의 일부 layer와 FC를 학습해야 되는데 CNN layer를 얼마나 학습시키느냐의 문제가 있습니다. 많은 layer를 새로 학습시키면 over-fitting의 문제가 발생하기 때문입니다.
R-CNN
Rich feature hierarchies for accurate object detection and semantic segmentation
위 논문에서 제안한 Object Detection 모델을 R-CNN(Regions with CNN features) 이라고 합니다. 3개의 모델들을 독립적으로 학습시켜 사용하고, Selective Search라는 알고리즘을 사용합니다.
대표적인 2 stage detector로 아래와 같은 순서에 따라 동작합니다.
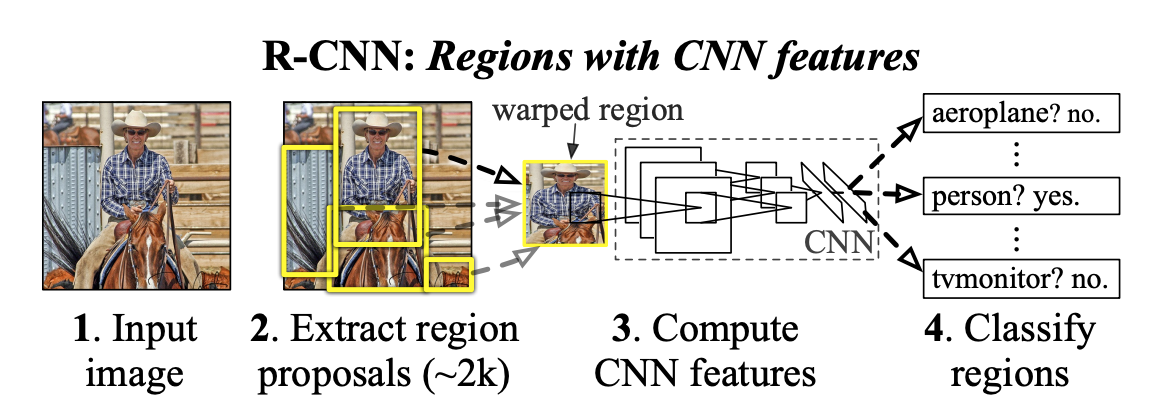
Stage 1 - ROI 추출
- 입력 이미지가 주어지면 Selective search 알고리즘을 통해 객체가 있을법한 후보영역(region proposal)을 2000개 추출하고, 각각을 227x227 크기로 warp 시켜줍니다.
이 후보영역을 ROI(Region of Interest)라고 합니다.
Stage 2 - Classification + a
- 모든 후보영역을 Fine tuning된 AlexNet에 입력하여 2000x4096 크기의 feature vector를 추출합니다.
- 추출된 feature vector를 Linear SVM 모델과 Bounding box regressor모델에 입력하여 각각 confidence score와 조정된 Bounding Box 좌표를 얻습니다.
- Non maximum suppression 알고리즘을 적용하여 겹치는 bounding box등을 조정하여 최적의 bounding box만을 출력합니다.
1. Selective Search

이미지의 주변 픽셀과의 색상, 무늬, 명암등을 비교해 작은 Region들로 나누고 유사한 영역들을 grouping해나가며 객체가 있을법한 후보영역을 추출하는 알고리즘 입니다. 한 개의 이미지당 2000개의 후보 영역을 추출합니다. CNN 모델에 입력하기 위해 227x227 크기로 warp(resize) 해줍니다.
2. Feature extraction using Fine-tuned AlexNet
2000개의 후보영역을 Fine-tune 된 AlexNet에 입력하여 2000x4096(2000개의 영역당 4096차원의 feature vector를 추출) 크기의 feature vector를 추출합니다.
기존 ImageNet 데이터셋을 통해 pre-trained 된 CNN 모델일 AlexNet을 사용하려는 Dataset에 맞게 fine-tuning 합니다.
R-CNN에서는 어떻게 Fine-tuning을 했을까?
해당 논문에서는 Fine-tuning을 위한 training set을 만들기 위해 selective search알고리즘을 이용해 객체영역과 배경영역의 데이터들을 만들었습니다. (Selective Search알고리즘은 R-CNN모델 추론시에도, AlexNet Fine-tuning에도 사용됩니다.)
먼저 PASCAL VOC 데이터셋에 Selective Search 알고리즘을 적용하여 후보영역을 추출하고, 후보영역의 Bounding Box와 Ground truth box와의 IOU(Intersection over Union)값을 구합니다. IOU값이 0.5 이상일 경우, positive sample(객체)로, 0.5미만인 경우, negative sample(배경)로 저장합니다. positive sample 32개, negative sample 96개로 mini batch(128개)를 구성하여 AlexNet에 입력하여 학습을 진행합니다.
3. Classification by linear SVM
Linear SVM 모델은 각 class에 해당하는지 판단하는 이진분류기(binary classifier)입니다. N개의 class + 배경 총 (N+1)개의 독립적인 Linear SVM모델을 학습시켜 사용합니다.
R-CNN에서는 어떻게 Linear SVM모델을 학습시켰을까?
Linear SVM 모델을 학습할때도 Selective search알고리즘을 이용하였습니다. Region proposal을 추출한 뒤, IOU값이 0.3미만인 Bounding Box를 negative sample로 저장합니다. IOU값이 0.3이상인 box는 무시하고 Ground Truth box만을 positive sample로 사용합니다. positive sample 32개, negative sample 96개로 mini batch(128개)를 구성하여 AlexNet에 입력하여 feature vector를 추출하고 이를 linear SVM에 입력하여 학습시킵니다. 한차례 학습 후, hard negative sampling기법을 적용하여 재학습시킵니다.
hard negative sampling은 모델이 학습에 실패하는 어려운(hard) sample들을 이용해 모델을 더욱 강건하게 학습시키는 방법입니다. mini batch에서 positive sample보다 negative sample이 더 많은 클래스 불균형(class imbalance)으로 인해 모델이 객체라고 예측했지만 실제로는 배경인 경우인 False Positive라고 예측하는 오류가 증가합니다. 이러한 문제를 해결하기위해 모델이 잘못 판단한 False Positive sample을 학습과정에 추가하여 재학습하면 모델은 보다 강건해집니다.
왜 AlexNet Fine-tuning과 Linear SVM학습 시 positive/negative의 정의가 다른가?
AlexNet Fine-tuning에는 과적합을 방지하기 위해 많은 데이터가 필요했고 위 과정처럼 진행하면 positive sample의 개수 차이가 30배정도 난다.
학습된 Linear SVM 모델에 2000x4096 크기의 feature vector를 입력하면 class와 confidence score를 반환합니다.
4. Bounding Box Regressor
Selective Search 알고리즘을 통해 얻은 box는 객체의 위치와 잘 맞지 않을 수 있습니다. 이런 문제를 해결하기 위해 bounding box의 좌표를 변환하여 객체의 위치와 맞게 조정해주는 Bounding Box Regressor모델을 사용합니다.
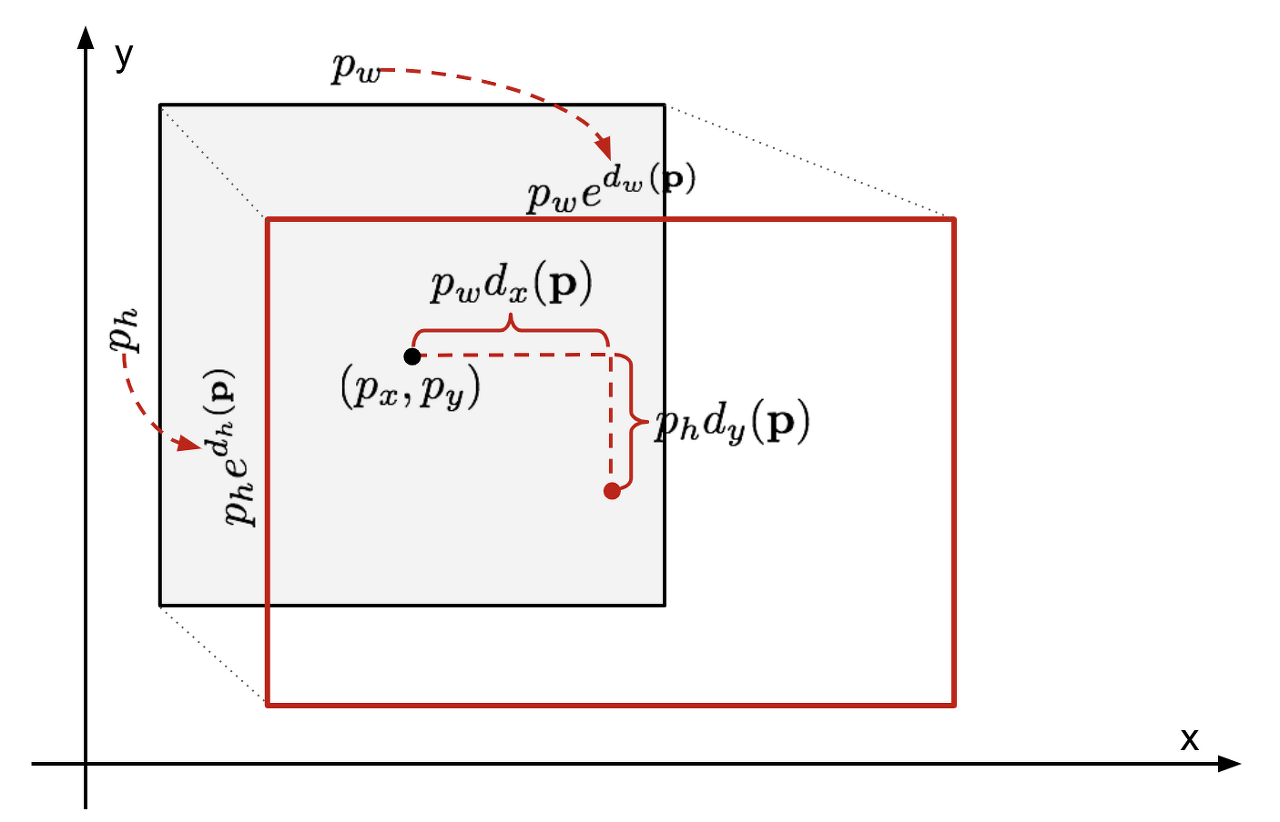
위 그림에서 회색 box는 Selective Search알고리즘으로 얻은 box이며, 빨간 테두리 box는 ground truth box입니다.
이 모델의 입력데이터는 Selective Search 알고리즘으로 얻은 region proposal 중 ground-truth와 IOU가 0.6이상인 sample을 fine-tuned된 AlexNet에 입력하여 얻은 feature vector를 Bounding-box regressor에 입력하여 학습시킵니다.
5. Non maximum Suppression
위의 과정들을 통해 얻은 2000개의 bounding box 중 특정 confidence score 이상의 box를 모두 표시할 경우, 하나의 객체에 대해 지나치게 많은 bounding box가 겹칠 수 있습니다. 이런 문제를 해결하기 위해 비슷한 위치에 있는 box들 중 가장 적합한 box를 선택하는 Non maximum suppression알고리즘을 적용합니다.

1. 특정 Confidence score 이하의 box를 제거합니다.
2. Bounding box를 confidence score에 따라 내림차순으로 정렬한 뒤, score가 높은 box부터 IOU가 특정 값 이상인 box들을 모두 제거합니다.
3. 남아있는 box만 선택합니다.
- Non maximum suppression 알고리즘은 confidence score threshold가 높을수록, IOU threshold가 낮을수록 많은 box가 제거됩니다.
결론.
지금까지 R-CNN의 학습방법과 추론과정을 살펴보았는데, 생각보다 복잡한 구조로 가지고 있는걸 알 수 있었습니다. R-CNN은 Selective Search 알고리즘을 통해 얻은 2000개의 후보군을 이용해 학습과 추론을 하다보니 매우 느린 속도를 가진다는 단점이 있습니다.(이미지 한 장에 47초) 또한 Fine tuned AlexNet, Linear SVM, Bounding box regressor라는 3가지 독립적인 모델을 사용하다보니 학습과정이 오래걸리고 복잡한 구조를 가지고 있다는 문제가 있습니다.
Reference
https://ganghee-lee.tistory.com/35
https://herbwood.tistory.com/5
https://bskyvision.com/421
*글을 좀 더 매끄럽게 다듬을 예정입니다.
