[DE] ETL 이란?
ETL (Extract, Transform, Load)
데이터 처리 관련하여 검색을 하다보면, ETL이라는 용어를 자주 볼 수 있습니다. 단어 자체를 풀이하자면 추출(Extract), 변환(Transform), 적재(Load)인데 정확히 어떤 개념인지 명확하게 떠오르지 않을 수 있습니다. 예시를 가지고 한번 살펴보도록 하겠습니다.
예시 상황

위와 같이 [시간]과 [작업번호], 유저의 [os]가 주어진다고 생각해봅시다. 이 데이터를 가공하여 아래와 같이 'android'유저의 데이터를 시간을 '월일'만 표시하여 아래와 같은 데이터를 얻는 작업을 수행한다고 생각해봅시다.
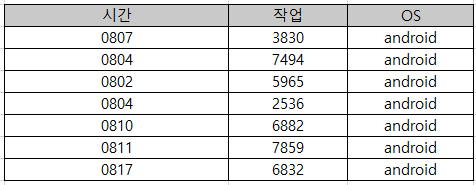
Extract (추출)
Extract는 하나 이상의 소스에서 데이터를 가져오는 프로세스입니다.(위 예시에서는 하나의 소스에서 데이터를 가져옵니다.) 일반적으로 데이터베이스에서 데이터를 가져오는 cost가 크기 때문에 DB에 접근하는 횟수를 줄이면 좋습니다.
예시 상황에서는 우선 OS = 'android'인 데이터만 가져오면 됩니다. 코드로는 여러가지 상황이 있겠지만 SQL에서는 SELECT, WHERE를 통해 OS = 'android'인 데이터를 가져오는 상황입니다.
Transform (변환)
Transform은 데이터를 정리하고 지정된 형식으로 만드는 작업입니다. 데이터 정리에는 중복되거나 불완전하거나 잘못된 데이터를 제거하는 작업이 포함됩니다.
예시 상황에서는 '2021-08-07'을 '0807'의 형식으로 변환하는 과정입니다.
Load (로드/적재)
Load는 형식이 지정된 데이터를 대상 데이터베이스, 데이터 저장소, 데이터 웨어하우스 또는 데이터 레이크에 삽입하는 프로세스입니다.
예시 상황에서는 추출, 변환을 거친 데이터들을 새로운 테이블로 만들어 저장하는 과정이 될 수 있습니다.
결론
아주아주 간단한 예시를 들어보았습니다. ETL을 통해 저장된 데이터를 다른 형태로 저장할 수 있습니다. ETL은 예를들면 데이터베이스 복제, 데이터 통합 등을 수행하는데 사용됩니다. ETL을 원활하게 수행하기 위해서는 원본 데이터(로그 등)와 저장 데이터의 형식(포맷)에 대한 이해를 잘 하고 있어야 Extract와 Load를 오류없이 수행할 수 있습니다. 또한 데이터 도메인에 대한 지식이 있다면 Transform에 대한 인사이트를 비교적 쉽게 할 수 있을것입니다.
참고사이트
https://cloud.google.com/learn/what-is-etl?hl=ko
https://itholic.github.io/etl/
