[Data Engineering] 데이터 엔지니어링
기업들의 기술블로그들을 살펴보다 보면 아래와 같은 Data flow를 볼 수 있습니다.
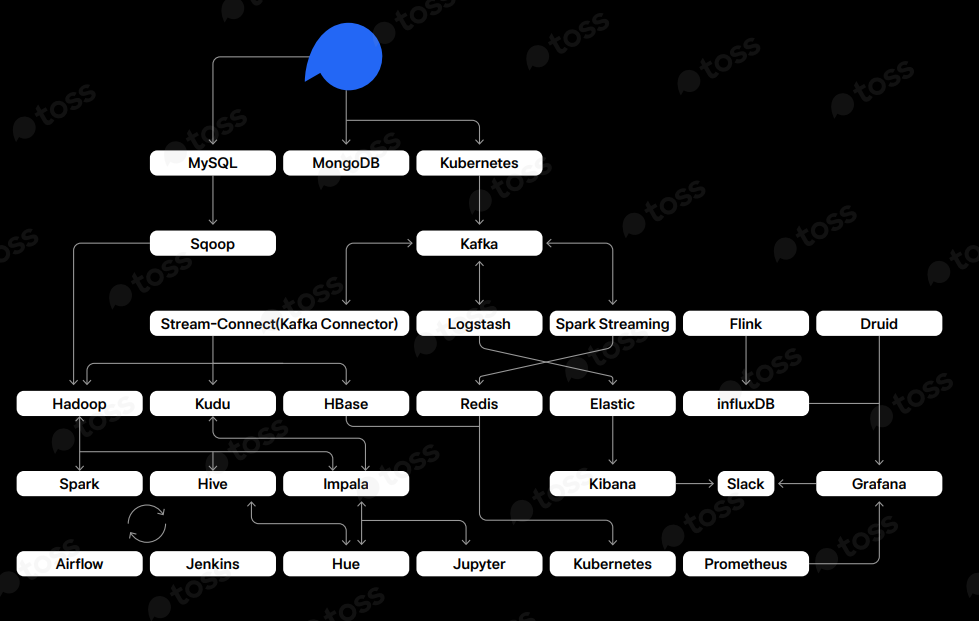
(출처: 토스 SLASH2021 )
좀 복잡해 보이지만 앞으로 글을 작성하면서 하나하나 알아보려고 합니다.
그 전에, Data engineering이란 무엇일까요?
검색해 보니 유사한 직무로 Data science, Data analysis 등등이 나옵니다.
관련 개념부터 정리하고 넘어가봅시다.
Data Science의 정의
우선 Data science는 이름처럼 '데이터'를 이용한 '과학'입니다. 기존의 과학도 '데이터'들을 이용하는데 왜 따로 이름을 붙이는 걸까요? Data science는 '빅 데이터'라는 개념이 사용되고부터 사용되기 시작했습니다.
'Big data'는 전통적인 데이터 프로세싱 방법으로 처리할 수 없을 정도로 대규모이거나 복잡한 데이터를 말합니다. 흔히 3V[Volumne-볼륨, Variety-다양성, Velocity-속도]라 불리는 특성을 가지고 있습니다. 볼륨은 대규모 크기를 의미하며, 다양성은 비표준 형식의 광범위한 범위를, 그리고 속도는 신속하고 효율적으로 처리되어야 하는 특성을 의미합니다.
The term "Data Science" describes expertise associated with taking (usually large) data sets and annotating, cleaning, organizing, storing, and analyzing them for the purposes of extracting knowledge. It merges the disciplines of statistics, computer science, and computational engineering.
데이터 사이언스이란 보통 큰 데이터셋에 대해 어노테이션, 클리닝, 핸들링, 저장, 분석을 하여 그로부터 유용한 지식을 추출하는 것을 말합니다.
수 많은 데이터를 수집할 수 있는 환경이 되고나서 많은 양의 사소한 정보들을 처리/분석하여 서비스 개선에 활용하는 기업이 생기고 광고와 마케팅에 사용함으로 돈을 벌어들이기 시작했습니다. 이런 사례들이 널리 알려지게 되고 '빅 데이터'라는 개념이 생길 정도로 데이터에 대한 관심이 증가했습니다. 양이 많은 '빅 데이터'의 분석에는 기존 분석과 완전히 다른 접근을 해야 해서 많은 관련 기술과 단어가 생겼는데, 그 중 하나가 Data science 입니다. 일반적으로 컴퓨터 메모리에 한번에 올라가지 않는 수준의 빅데이터를 다루며 도메인에 대한 이해를 필요로 합니다. 도메인에 대한 이해를 바탕으로 데이터의 noise가 어디서 발생되었는지 분석이 가능합니다.

위 그림처럼 데이터를 분석하기 위한 기본 지식(CS, Statistics)뿐만 아니라 해당 데이터의 도메인에 대한 이해도 필요합니다. 사실 기존 분석과 빅 데이터 분석의 경계가 모호하고 최근에 나온 개념이다 보니, 빅 데이터는 각 회사나 조직별로 상황에 맞게 정의하고 적용을 하고 있습니다.
Data science & Data engineering
위와 같은 이유로 데이터 엔지니어링도 명확하게 딱 정의할 순 없지만, 빅 데이터 분석은 크게 데이터 엔지니어링과 데이터 사이언스로 전문화 되었습니다. 이 두 업무는 협업을 하는 관계입니다.

위의 그림에서 볼 수 있듯이 데이터 엔지니어는 데이터에 관심이 많은 프로그래머, 데이터 사이언티스트는 데이터에 관심이 많은 분석가가 적합하다고 볼 수 있습니다.
Data Engineer
그렇다면, 데이터 엔지니어는 어떤일을 할까요? 회사마다 하는 직무가 다르기 때문에 참고만 하는 것이 좋습니다. 구글에 검색해보니 바로 카카오 기술블로그가 나오네요. 카카오에서는 데이터 엔지니어가 어떤일을 하는지 살펴봅시다.
카카오 데이터 엔지니어
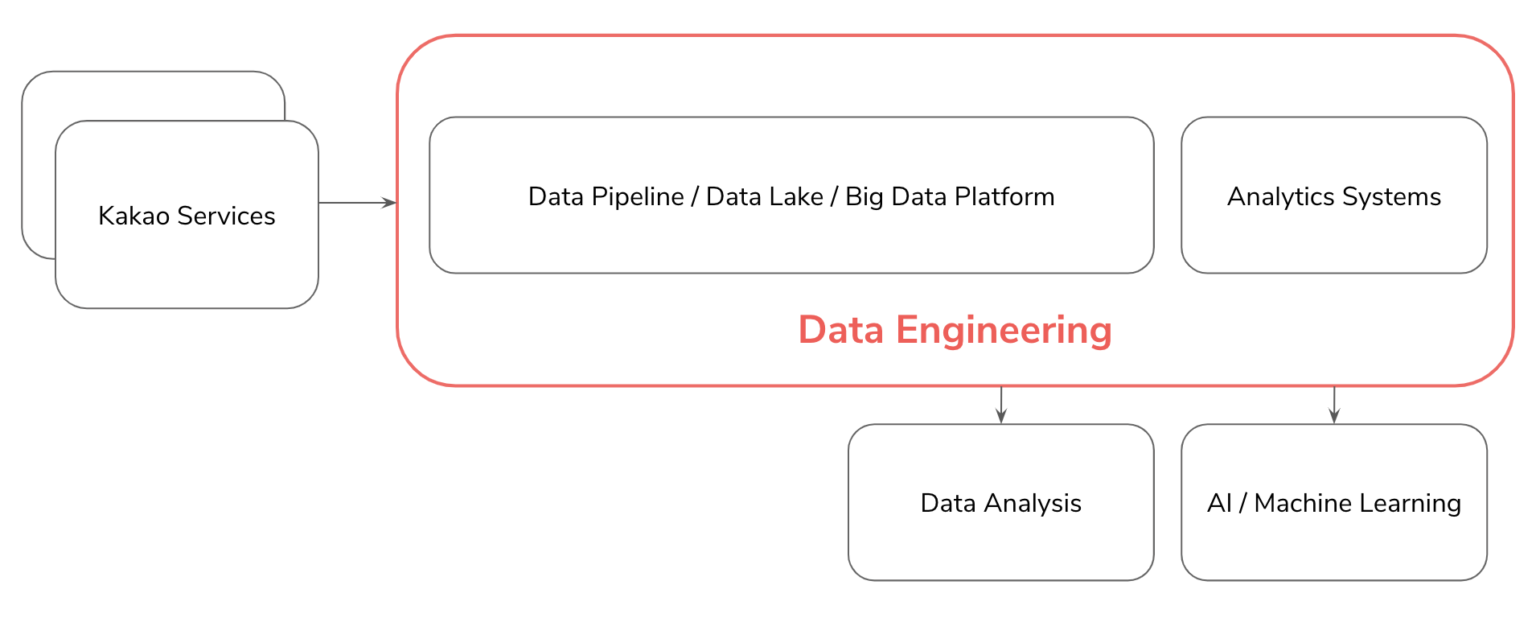
카카오의 수많은 서비스들의 데이터는 데이터 파이프라인으로 모이고 이 수많은 데이터는 쓰기 편하고 안전한 형태로 가공이 되어 저장됩니다. 이 빅 데이터를 활용해서 서비스에서 의사 결정을 할 수 있는 분석 시스템을 만들고, 데이터 사이언티스트는 고도화된 분석을 하며 AI/ML 업무를 수행합니다.
-
수집, 가공, 저장
수많은 서비스에서 생산된 데이터를 모을 수 있도록 거대한 데이터 파이프라인을 설계, 구축합니다. 모두가 쉽고 안전하게 다룰 수 있도록 가공을 하며, 데이터의 성격에 따라 스트리밍 혹은 배치 처리를 합니다. 이것을 제대로 하려면 적합한 기술들의 선택과 조화로운 설계가 필요합니다.
스트리밍 데이터를 모으기 위해 logstash, fluentd 같은 수집기와 kafka, rabbitMQ 같은 MQ(Message Queue)를 사용하고 스트리밍 데이터 가공을 위해 storm, flink, spark streaming등을 사용합니다. 배치 처리는 hadoop MR(Map Reduce), hive, spark등을 사용하며 용도에 따라 다른 기술을 사용하기도 합니다. 이런 처리를 하는 환경에서는 프로그래밍이 필요하며 python, scala, java같은 언어들이 주로 쓰이고 있습니다.
분석을 하기 위해 데이터를 가공하는 작업을 하는데, 이를 ETL(Extract, Transform, Load)라고 합니다. 이 용어는 다음 포스팅에서 다뤄보도록 하겠습니다. -
분석
저장된 데이터에서 hive등의 쿼리로 일회성 분석을 하기도 합니다. visualization tool을 통해 self service BI(직원 누구나 접속하여 분석할 수 있는 환경)을 개발하기도 합니다. 중요한 데이터에 대해서는 서비스 조직에서 수시로 확인할 수 있도록 analytics system을 개발하기도 합니다. 즉 데이터를 조직원들이 쉽게 분석할 수 있는 환경을 만들어 주는 역할입니다.
- 협업
심화된 분석,ML,AI등을 하는 데이터 사이언티스트들과 협업이 필요합니다. 어떤 데이터들을 쓰고 있고, 어떤 데이터들이 필요한지 알아야 일이 원활하게 진행이 되니까요. 일이 원활하게 진행이 된다면 서비스는 점점 더 사용자가 원하는 콘텐츠를 추천하게 될 것입니다.
서비스 조직과 협업도 필요합니다. 예를 들어, 서비스 개편을 위해 ab test를 한다면 여러 가설을 세우고 실험을 하고 분석을 같이 해야 합니다.(이는 노하우가 생긴다면 프로세스화 할 수 있겠죠..) 이후 서비스 개편 후에 대한 성과 분석 지표를 analytics system에 나오도록 한다면 이미 수집하고 있는 데이터로 충분한지 확인해보고, 부족하다면 니즈에 맞으며 확장성 있게 데이터를 추가 수집해야 합니다.
결론
결국 데이터 엔지니어는 서비스에서 생성되는 정보(어떤 로그를 수집할지도 정해야 됩니다.)를 조직에서 쉽게 사용할 수 있도록 시스템을 구축하고 데이터를 정제하는 역할을 합니다. 이를 위해 해당 서비스 도메인에 대한 이해가 필요합니다.
예전에 데이터셋을 구축하는 일을 해봤었는데, 공개된 데이터셋과 달리 취득된 데이터는 쓸모없는 데이터도 많아 이를 정리하는데 오랜 시간이 걸렸던 기억이 있습니다. 실제 서비스에서도 로그가 항상 올바르게 취득된다고 보장할 수 없으니 사용할 수 있는 데이터를 만들기 위해 많은 고민이 필요하다고 생각됩니다.(도메인에 대한 이해가 있으면 더 수월하겠죠?)
참고사이트
https://3months.tistory.com/330
https://tech.kakao.com/2020/11/30/kakao-data-engineering/
https://www.redhat.com/ko/topics/big-data
