1. 아래의 메모리 그림을 그려서 설명 부탁드리겟습니다.
def add_tuple(t1,t2):
t1 += t2 #새로운 튜플을 생성하여 t1에 할당
return t1
tp = (1,3) # 기존 튜플 tp는 (1,3)
tp = add_tuple(tp, (5,7)) #새로운 튜플 (1, 3, 5, 7)
print(tp) #출력: (1, 3, 5, 7)2. 아래의 원본이 바뀌지 않도록 코드를 수정하시오.
def min_max(d):
d.sort() #리스트 d를 오름차순으로 정렬
print(d[0], d[-1], sep = ",") # 첫번째 요소(최소값)와 마지막 요소(최대값) 출력
l = [3,1,5,4]
min_max(l)
def min_max(d):
sorted_d = sorted(d) #정렬된 새로운 리스트 생성
print(sorted_d[0], sorted_d[-1], sep=",")
l = [3, 1, 5, 4]
min_max(l) # 출력: 1, 5
print(l) # 원본 그대로
or
import copy
def min_max(d):
d = copy.deepcopy(d) # 딥카피로 객체를 새로 생성
d.sort()
print(d[0], d[-1], sep = ",")
l = [3, 1, 5, 4]
min_max(l) # 1,5
print(l) # 원본 리스트가 변하지 않도록 수정
3. iterable 객체 와 interator 객체에 대하여 설명하시오.
- 컬렉션 타입
- list, tuple, set, dictionary와 같이 여러개의 요소(객체)를 갖는 데이터 타입
- 시퀀스 타입
- list, tuple, range, str등과 같이 순서가 존재하는 데이터 타입!
Iterable 객체란? for문과 같이 반복문에서 하나씩 값을 꺼내어 순회할 수 있는 객체입니다. 예를 들어, 리스트, 튜플, 문자열 등과 같이 요소들을 순서대로 접근할 수 있는 자료 구조가 Iterable입니다.
비슷한듯 다른 Iterable Iterator
Iterable 한 것은 next메소드가 존재하지 않고, Iterator는 존재하며,
a = [1, 2, 3]
print(a.__next__) # AttributeError 발생그냥 list타입의 데이터는 next 메소드가 없어서 에러 발생
a = [1, 2, 3]
print(type(a)) # list 출력
a = iter(a)
print(type(a)) # list_iterator 출력
print(a.__next__()) # 첫 실행시 1 출력
or
a = [1, 2, 3].__iter__()
print(type(a)) #list_iterator하지만 위처럼 iter함수를 이용 또는 iter 메소드를 통해 Iterator로 만들어 정상작동
Iterable한 객체를 Iterator로 만들 수도 있습니다.
- iter() 메서드를 구현하고 있어야 합니다.
- iter() 함수를 호출하면 해당 객체의 Iterator를 반환합니다.
- for문과 같은 반복문을 사용하면 내부적으로 iter() 함수를 호출하여 Iterator를 생성하고, 이를 통해 요소를 하나씩 가져옵니다.
my_list = [1, 2, 3] #my_list 는 Iterable 객체
print(iter(my_list)) # <list_iterator object> #iter(my_list)는 리스트에 대한 Iterator를 반환합니다. Iterator 객체는 데이터를 하나씩 순서대로 꺼내 올 수 있는 객체입니다. Iterable에서 *iter()를 호출하면 Iterator가 반환되며, next() 메서드를 사용하여 다음 값을 가져옵니다.
- iter() 메서드와 next() 메서드를 구현하고 있어야 합니다.
- next() 함수를 호출하면 요소를 하나씩 반환합니다.
- StopIteration 예외가 발생할 때까지 계속 값을 반환합니다.
my_list = [1, 2, 3]
iterator = iter(my_list) # Iterator 생성
print(next(iterator)) # 1
print(next(iterator)) # 2
print(next(iterator)) # 3
# 더 이상 요소가 없으면 StopIteration 예외 발생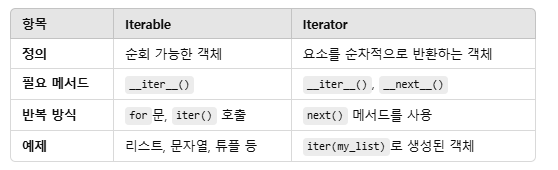
파이썬의 for문은 내부적으로 Iterator 생성하여 동작
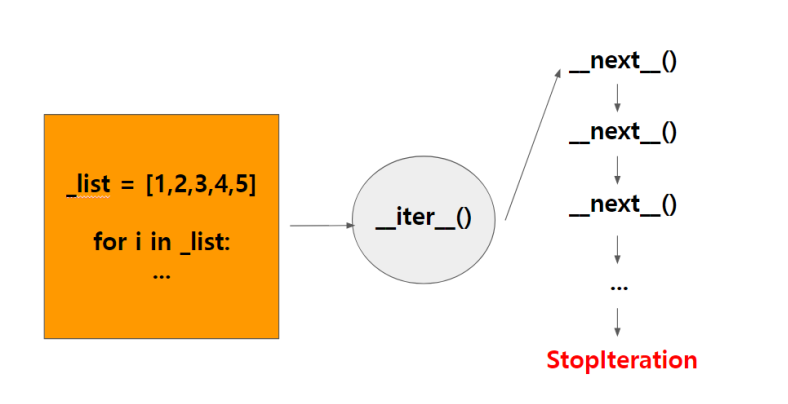
직접 Iterator 객체 구현
class MyIterator:
def __init__(self, data): #생성자 메서드
self.data = data #반복할 데이터 저장
self.index = 0 #반복시작할 인덱스 초기화
def __iter__(self): #반복 가능한 객체 반환
return self
def __next__(self): # 다음 값을 반환하는 메서드
if self.index < len(self.data): #인덱스가 데이터 길이보다 작을때만 반환
result = self.data[self.index] # 현재 인덱스 위치의 값 저장
self.index += 1 #인덱스를 1증가 시켜 다음 값으로 이동
return result #현재 값을 반환
else:
raise StopIteration # 인덱스가 데이터보다 작지않을때 예외 발생
#MyIterator 객체 생성
my_iter = MyIterator([10, 20, 30]) #반복가능한 객체 생성
for item in my_iter: #for 문을 통해 데이터 출력
print(item)
출력
10
20
304. 아래를 코딩하시오.
counter = Counter(3)
for i in counter:
print(i, end=' ') #0,1,2
# Counter 클래스 정의
class Counter:
def __init__(self, max_value):
self.max_value = max_value # 최대 반복 횟수 설정
def __iter__(self):
self.current = 0 # 시작 인덱스 초기화
return self
def __next__(self):
if self.current < self.max_value:
value = self.current # 현재 값을 저장
self.current += 1 # 1 증가하여 다음 값 준비
return value # 현재 값 반환
else:
raise StopIteration # 더 이상 반복할 값이 없으면 반복 종료
# Counter 객체 생성 및 반복
counter = Counter(3)
for i in counter:
print(i, end=' ') # 출력: 0 1 2
- 함수도 객체인 증거를 대시오?
6 . 아래의 결과를 예측하고 설명하시오.
def say1():
print('hello')
def say2():
print('hi')
def caller(fct):
fct() ==================
caller(say1())
caller(say2)
-
일반함수를 람다함수로 바꾸는 방법에 대하여 설명하시오.
-
아래를 람다 함수로 바꾸어 보시오.
def fct_fac(n):
def exp(x): # 함수 내에서 정의된, x의 n제곱을 반환하는 함수
return x ** n
return exp # 위에서 정의한 함수 exp를 반환한다.
f2 = fct_fac(2) # f2는 제곱을 계산해서 반환하는 함수를 참조한다.
f3 = fct_fac(3) # f3는 세제곱을 계산해서 반환하는 함수를 참조한다.
f2(4) # 4의 제곱은?
16
f3(4) # 4의 세제곱은?
62
- 이름(name), 전화번호(tel) 필드와 생성자 등을 가진 Phone 클래스를 작성하고, 실행 예시와 같이 작동하는 PhoneBook클래스를 작성하라.
10.문자열을 입력받아 한 글자씩 회전시켜 모두 출력하는 프로그램을 작성하라.

세줄요약:
함수도 객체이다.
튜플을 함수로 넘길때, 원본이 변화 되지 않는 특성을 잘 이해 하자.
람다를 이용하면 효율적인(?) 함수 작성이 가능하다.
