1. 키워드 인자 와 포지셔널 인자에 대하여 설명하시오.🐱🏍
파이썬에서 함수 호출할때 인자(argument)를 전달하는 방법에는 2가지
위치인자(Positional Arguments)와 키워드 인자(Keyword Arguments)로 나뉩니다.
- 위치 인자(Positional Arguments)
함수 호출시 전달하는 인자가 함수 정의의 매개변수(parameter)의 위치에 따라 매핑되는 방식
즉, 인자의 순서가 함수 정의에서 매개변수의 순서와 일치해야함
def greet(name, age):
print(f"Hello, {name}. You are {age} years old.")위에서 함수는 name과 age라는 두 개의 parameter를 받아 인사말과 나이를 출력한다.
위 함수를 위치인자를 사용하면 다음과 같다.
greet("Alice",30)위 함수는 name에 "Alice"라는 값이, 그리고 age에 30이라는 값이 매핑되어 함수가 실행됨.
- 키워드 인자(Keyword Arguments)
키워드 인자는 함수 호출시 인자의 이름을 지정하여 함수 정의에서 해당 이름과 매핑되도록 전달하는 방식 이를 통해 인자의 순서를 신경쓰지 않고 명확하게 어떤 값이 해당하는 지 지정가능
greet(age=30, name="Alice")이렇게 키워드 인자를 사용하면 인자의 순서와 상관없이 명확하게 지정 가능
파이썬에서는 위치인자와 키워드 인자 혼합 사용도 가능하지만, 키워드 인자를 사용하려면 위치인자가 먼저 나와야함.
greet("Bob",age=25)위 호출시 name에 "Bob"이라는 인자가 먼저 왔고, age에는 키워드 인자로 25가 전달됨.
하지만, 이렇게 위치 인자와 키워드 인자를 혼합해서 사용하는 방식은 지양하는게 좋다.
햇갈린다 포지션은 위치기반 키워드는 지정식!
2. 아래가 에러가 나는 이유는?
def mul(x,y,/): # /는 포지션 인자만 받겠다는 표시
return x * y
mul(x=4,y=5)
TypeError: mul() got some positional-only arguments passed as keyword arguments
포지션 전용 인자(positional-only arguments)로 설정된 파라미터에 키워드 인자(keyword arguments)로 값을 전달해서, 포지션 인자로 mul(4, 5)만 기입시 정상 출력
mul(4, 5) # 올바른 호출 방법 (위치 인자로 전달)or
함수정의에서 / 기호를 제거하면 포지션 전용이 아니라서 정상 출력
def mul(x, y): # 포지션 전용이 아님
return x * y
mul(x=4, y=5) # 키워드 인자로 호출 가능포지션 전용 인자를 쓰는 이유
- 가독성 향상:
함수 호출 시 특정 인자는 키워드 인자로 사용하지 않게 제한함으로써 코드 가독성을 높입니다. - 혼란 방지:
일부 매개변수는 키워드 인자로 사용되면 오해를 불러일으킬 수 있습니다. - 호환성 유지:
기존 코드와의 호환성을 유지하기 위해 포지션 전용 인자를 사용하는 경우가 있습니다
3. 아래가 에러가 나는 줄은 몇번째 줄이며 이유는?
def only_keyword(*,x,y): # 키워드 인자만 받겠다
return x + y
only_keyword(x=1,y=2)
only_keyword(1,2)
TypeError: only_keyword() takes 0 positional arguments but 2 were given
위와 반대로 키워드 인자만 받아야 작동하므로,
def only_keyword(*,x,y): # 키워드 인자만 받겠다
return x + y
only_keyword(x=1,y=2)위처럼 수정하거나 def only_keyword(x,y) 사용 "*" 제거
4. 아래와 같은 함수가 있다. mix_fun 함수를 호출하여 결과 물이 나오도록 하시오.
def mix_fun(a,b,/,h,i,,x,y): #a,b,/ 는 포지션 ,x,y는 키워드
print(a-b)
print(h-i)
print(x*y)
mix_fun( 파라미터 )
def mix_fun(a,b,/,h,i,*,x,y): #a,b,/ 는 포지션 *,x,y는 키워드
print(a-b)
print(h-i)
print(x*y)
mix_fun(3,4,3,4,x=3,y=4)
#출력
-1
-1
125. 아래의 출력이 어떻게 나오는지 예측하고, 그이유는?
d = dict(a=1,b=2,c=3) #딕셔너리 생성
vo = d.items() # d.items() 딕셔너리의 (key,value)쌍을 반환하는 view 객체 생성
for kv in vo: # 첫 번째 for 루프
print(kv) # 키 값 출력 kv = keyvalue 표현
d['a'] = d['a'] + 3 # 값 수정 # 'a'키값을 3증가 (a:4)
d['c'] += 2 # 'c'의 값 2증가 (c:5)
for kv in vo:
print(kv) # 키, 값 출력
출력
('a', 1)
('b', 2)
('c', 3) #첫 번째 for 루프에서 여기까지 출력
('a', 4)
('b', 2)
('c', 5) #두 번째 루프에서 변경된 값이 여기까지 출력 6. 아래의 소스코드를 컴프리헨션으로 줄여 보시오.
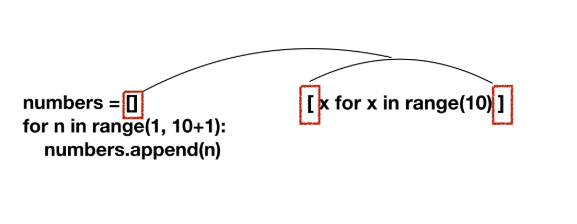
d1 = dict(a=1,b=2,c=3)
d2 ={}
for k,v in d1.items():
d2[k] = v*2
print(d2)
#컴프리 헨션으로 채우시오.
d2 = { } ## d1의 값을 두 배 늘린 딕셔너리 생성
print(d2)
컴프리헨션 원리
d2 = [k for v in v*2]
d1 = dict(a=1,b=2,c=3)
d2 = {k: v * 2 for k, v in d1.items()} # k: d1의 키값 유지 v*2 밸류값은 2배
print(d2)
출력값
{'a':2, 'b':4, 'c':6}7.map을 예를 들어 설명해 보시오.
map(function, iterable) map() 함수는 iterable의 각 요소에 대해 function 함수를 적용한 결과를 새로운 iterator로 반환합니다. 이때, function 함수는 각 요소를 인자로 받아서 처리하며, 함수의 반환값이 새로운 iterator의 각 요소가 됩니다.
예제
def square(x):
return x**2
numbers = [1, 2, 3, 4, 5]
squared_numbers = map(square, numbers)
print(list(squared_numbers)) # [1, 4, 9, 16, 25]map 함수를 사용하는 이유
- 지연평가(lazy evaluation) 방식: map() 함수는 lazy evaluation 방식을 사용합니다. lazy evaluation이란 필요한 시점까지 연산을 늦추는 방식으로, 불필요한 연산을 최소화하여 성능을 향상시키는 방법입니다. 입력으로 받은 iterable 객체를 순회하면서 각 요소에 대해 함수를 적용하여 새로운 iterable 객체를 생성하지만, 이 과정에서 실제로 변환된 결과값들이 생성되는 것이 아니라, 필요할 때까지 기다리는 것입니다. 이런 방식으로 인해 변환된 결과값이 모두 메모리에 저장되지 않고 부분만 계산하여 처리할 수 있기에 불필요한 메모리 사용을 줄일 수 있습니다.
- 간결성: map() 함수를 이용하면 반복문을 작성하지 않아도, 한 줄의 코드로 여러 개의 리스트를 동시에 처리할 수 있습니다.
- 가독성: map() 함수를 이용하면, 코드의 가독성을 높일 수 있습니다.
성능: map() 함수는 내부적으로 C로 구현되어 있으므로, 파이썬 반복문보다 빠르게 처리할 수 있습니다. - 메모리 사용량: map() 함수는 새로운 리스트를 생성하지 않고, iterator 객체를 반환하므로, 메모리 사용량을 최소화할 수 있습니다. 하지만, 매우 큰 이터레이터 객체를 처리할 경우, 메모리 사용량이 매우 높아질 수 있습니다.
- 제약사항: map() 함수는 입력된 모든 이터레이터 객체의 길이가 같아야 하므로, 이러한 제약 사항을 고려하여 사용해야 합니다.
8.filter 함수를 예를 들어 설명하시오.
파이썬의 내장 함수 filter() 함수는 iterable한 객체, 리스트와 같은 자료들을 필터링하는 역할을 하는데 여기서 필터링이란 특정 조건에 맞는 요소들만 출력한다는 의미입니다.
filter() 함수 기본 형태 : filter(function, iterable)
- function 인자는 조건을 정하는 함수이며, iterable은 list와
같은 순회 가능한 자료형입니다.
- filter() 함수를 사용하게 되면 코드를 조금 더 간결하게 만들 수 있습니다.
필터를 사용하지 않았을 때
num_list = [10, 20, 30, 40, 50, 60, 70, 80]
for n in num_list :
if n > 40 :
filter_list.append(n)
print(filter_list)
>>> [50, 60, 70, 80]필터를 사용했을때
num_list = [10, 20, 30, 40, 50, 60, 70, 80]
filter_list = list(filter(lambda n : n > 40, num_list))
print(filter_list)
>>> [50, 60, 70, 80]9. 아래가 돌아가도록 sum 함수를 만드시오.
st1 = [1,2,3]
st2 = [3,2,1]
st3 = list(map(sum,st1,st2)) # 함수에 파라미터가 두개 있을 경우
st3 # 출력[4, 4, 4]
# 두 개의 파라미터를 받아 더하는 sum 함수 정의
def sum(a, b):
return a + b
# 입력 리스트
st1 = [1, 2, 3]
st2 = [3, 2, 1]
# map을 사용하여 각 요소를 더한 새로운 리스트 생성
st3 = list(map(sum, st1, st2))
print(st3) # 출력: [4, 4, 4]
10. 아래의 함수를 완성하시오.
s1 = ['one', 'two','three']
ref = list(map(함수,s1))
print(ref)
출력
#['eno', 'owt', 'eerht']
# 문자열을 뒤집는 함수 정의
def reverse_string(s):
return s[::-1]
# 입력 리스트
s1 = ['one', 'two', 'three']
# map 함수로 리스트 요소에 reverse_string 함수를 적용
ref = list(map(reverse_string, s1))
# 결과 출력
print(ref) # ['eno', 'owt', 'eerht']
11. filter 함수를 써텍스트서 'gender' 가 M 인 사람의 이름만 뽑아내시오.
users = [{'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'gender': 'M'},
{'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'gender': 'F'}]
# 주어진 데이터
users = [
{'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'gender': 'M'},
{'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'gender': 'F'}
]
# filter 함수를 사용하여 gender가 'M'인 사람의 이름만 추출
male_users = list(filter(lambda user: user['gender'] == 'M', users))
#lamda 함수가 user 딕셔너리의 gender키가 'M'인지 확인
male_names = [user['name'] for user in male_users]
print(male_names) # 출력: ['Brett Holland']
동일작업을 List Comprehension
```python
male_names = [user['name'] for user in users if user['gender'] == 'M']
print(male_names) # 출력: ['Brett Holland']- 위의 예제에서 filter 함수를 써서 'gender' 가 F 인 사람을 리스트로 뽑아내시오.
# 주어진 데이터
users = [
{'mail': 'gregorythomas@gmail.com', 'name': 'Brett Holland', 'gender': 'M'},
{'mail': 'hintoncynthia@hotmail.com', 'name': 'Madison Martinez', 'gender': 'F'}
]
# filter 함수를 사용하여 gender가 'F'인 사람의 이름만 추출
fmale_users = list(filter(lambda user: user['gender'] == 'F', users))
#lamda 함수가 user 딕셔너리의 gender키가 'F'인지 확인
fmale_names = [user['name'] for user in fmale_users]
print(fmale_names) # 출력: ['Madison Martienez']
13. 아래 결과를 예측하시오.
nums = (1,2,3,4,5)
first, *others, last = nums
패킹(Unpacking)이란?
언패킹은 리스트, 튜플 등의 자료구조를 개별 변수에 할당하는 기능입니다. * 연산자는 여러 요소를 리스트로 묶어서 변수에 할당하는 역할을 합니다.
print(first) # 출력: 1
print(others) # 출력: [2, 3, 4]
print(last) # 출력: 5
14 .함수에서 단독으로 쓰일때와 , 변수명 쓰일때의 차이는?
Python 함수에서 는 여러 요소를 한꺼번에 처리할 수 있도록 해주는 강력한 문법입니다. 하지만 의 사용 방식에 따라 의미가 달라집니다. 여기서는 단독 사용과 변수명 사용의 차이를 설명하겠습니다.
Python 함수에서 는 여러 요소를 한꺼번에 처리할 수 있도록 해주는 강력한 문법입니다. 하지만 의 사용 방식에 따라 의미가 달라집니다. 여기서는 단독 사용과 변수명 사용의 차이를 설명하겠습니다.
def example_func(a, b, *, c, d):
print(f"a: {a}, b: {b}, c: {c}, d: {d}")
# 호출 시 반드시 c, d는 키워드 인자로 전달
example_func(1, 2, c=3, d=4) # 출력: a: 1, b: 2, c: 3, d: 4
# 오류 발생: c, d가 위치 인자로 전달됨
# example_func(1, 2, 3, 4) # TypeError 발생
- 튜플에서 이 언패킹 하는 케이스를 예를 들어 설명하시오.
변수명을 사용하면 여러 개의 위치 인자를 하나의 튜플로 묶어 함수 내부에서 처리할 수 있습니다.
def example_func(*args):
print(f"args: {args}")
example_func(1, 2, 3, 4) # 출력: args: (1, 2, 3, 4)
*args는 가변 인자로, 함수 호출 시 입력된 여러 개의 위치 인자를 튜플 형태로 받습니다.
example_func(1, 2, 3, 4)를 호출하면 args는 (1, 2, 3, 4)라는 튜플이 됩니다.
16.다음을 프로그래밍 하시오.
c = Circle(10)
c.get_area() # 314
rec = Rectangle(10)
rec.get_area() # 100
import math
# 원 클래스
class Circle:
def __init__(self, radius):
self.radius = radius #radius 반지름
# 원의 면적 계산
def get_area(self):
return math.pi * (self.radius ** 2)
#원의 면적은 3.14* r^2 math.pi 사용하면 더 정확한 파이값 가능
# 사각형 클래스
class Rectangle:
def __init__(self, side):
self.side = side
# 사각형의 면적 계산
def get_area(self):
return self.side ** 2 # 정사각형의 면적: 한 변의 길이의 제곱
# 객체 생성 및 테스트
c = Circle(10)
print(f"원의 면적: {c.get_area():.2f}") # 출력: 원의 면적: 314.16 (소수점 2자리까지)
rec = Rectangle(10)
print(f"사각형의 면적: {rec.get_area()}") # 출력: 사각형의 면적: 100
세줄요약:
1.결과 데이터 반환을 위해 filter 와 컴프리 헨션으로 효율적 코딩 가능하다.
2.언패킹 하는 케이스는 튜플로 함수 호출 할때 이다.
3.함수 파라미터에서 단독으로 쓰일때와 파라미터명 으로 쓰일때를 구분하자
