
TIL (Today I Learned)
2023.10.12
오늘 읽은 범위
에피소드 22. 자료구조와 알고리즘은 필수라고?
에피소드 23. 배열이 뭐죠?
에피소드 24. 알고리즘의 속도는 어떻게 표현할까?
에피소드 25. 검색 알고리즘이 뭐죠?
오늘 TIL 3줄 요약
- 알고리즘은 컴퓨터에 명령할 지시사항들, 자료구조는 데이터를 효율적으로 정리하는 방법들
- 배열은 휘발성 메모리인 램, 쉽게말해 잃어버릴 수 있는 기억창고에 놓여있는 번호적인 상자들의 나열
- 작업 단계 수가 많아질수록 시간 복잡도는 커진다.
책에서 기억하고 싶은 내용
📌알고리즘 : 컴퓨터에게 명령할 지시사항들
1️⃣이부자리 정리
2️⃣씻기
3️⃣옷입기
4️⃣커피 내리기
5️⃣가방 챙기기
6️⃣집 나서기
출근이나 등교 준비를 빠르게 할 수 있는 방법들이 있듯이, 알고리즘 중에도 더 좋은 알고리즘이 있다.
예) 지도앱 - 목적지까지의 최단 거리 및 시간을 안내해주는 알고리즘 : 패스파인더(pathfinder) 알고리즘
예) PNG, JPG - 이미지 손상을 최소화하면서 용량은 줄여주는 알고리즘 : 이미지 압축(compression) 알고리즘
📌자료구조 : 데이터를 효율적으로 보관하고 찾기 위한 데이터 정리 방식
데이터 = oil(원유)
인공지능은 데이터 없이 아무 일도 시작 못한다. 일단 원유인 데이터가 있어야 가공을 하든 정리를 하든 뭐든 할 수 있다. 근데 이런 데이터가 정리가 되어 있으면 원하는 데이터를 쉽고 빠르게 찾을 수 있다.
택배회사의 창고에 짐이 정리되어 있어야 시간 내에 고객에게 배달을 하고, 방에 물건이 잘 정리되어 있어야 필요한 물건을 빠르게 찾을 수 있듯이, 데이터도 분류 및 정리가 잘 되어 있어야 작업 속도가 빨라진다. 어떤 자료구조를 사용하는지(마치 어떤 방식으로 짐 정리를 하는지)에 따라 프로그램 속도(필요한 물건을 찾는 속도)가 좌우된다.
짐을 정리하는 방식
- 선반 이용하기
- 박스 이용하기
- 서랍 이용하기
- 라벨 붙히기
자료구조 방식
- 데이터를 크기 기준으로(데이터를 작은 것 부터 큰 순서로) 정리하는 자료구조 방식
- 검색을 위해 인덱스 기준으로(이름표를 붙여서) 정리하는 자료구조 방식
- 생성 시간 기준으로(데이터가 들어오는 순서로) 정리하는 자료구조 방식
어떤 자료구조를 필요로 하는지는 프로그램 마다 다르기 때문에 목적에 맞는 자료구조 방식을 쓰면 된다.
📌메모리
메모리는 컴퓨터의 기억 공간을 의미한다. 마치 기억 창고.
종류
- 휘발성 메모리: 컴퓨터 끄면 데이터 모두 날아감
- 램(RAM, random access memory): 전원 off시, 물건(기억)을 잃어버릴 수 있는 창고
- 창고에 물건을 잠시 저장해 뒀다가 전원 off시 상자가 다 사라지는 것과 같다.
- 램은 데이터에 접근하는 속도가 매우 빠르다.
- 비휘발성 메모리: 휘발성 메모리의 반대
- 하드 드라이브(C,D 드라이브)
📌배열(array)
-
번호가 적인 상자들이 나열된 것
-
배열의 특징을 알려면 배열의 읽기(read), 검색(search), 추가(add), 삭제(delete) 과정에서의 시간복잡도(time complexity)를 알아야한다.
-
배열을 만들 때는 배열의 길이를 컴퓨터에게 알려줘야 한다.
"길이가 4인 배열을 램에 할당해줘."
🟰"박스 4개를 붙여서 창고에 놓아줘. -
배열의 맨 처음 박스 번호는 0이다. 0번째 박스가 첫 박스다.
✔️ 램이 속도가 빠른 이유?
램 안에는 번호가 적힌 상자들이 나열되어 있고 각 상자안에는 데이터를 1개씩 저장할 수 있다.
각 상자의 번호를 보고 "4번 상자에 있는 데이터를 봐"라고 명령함으로써 빠르게 상자를 찾을 수 있다.
✔️ '검색'은 '읽기' 보다 시간이 더 필요하다.
만약 "몇번째 상자를 봐"가 아닌 "피자를 찾아"라고 검색한다면? 배열에서 박스 안의 데이터를 모두 확인해야 하기 때문에 시간이 오래 걸린다. 그래서 검색은 읽기 보다 시간이 더 걸린다. 만약 운 좋게 0번째 박스에 피자가 있다면 검색이 바로 끝나겠지만, 가장 마지막 상자 안에 피자가 있었거나 혹은 처음부터 피자가 아무데도 없었다면 시간은 시간대로 걸리고 피자는 못찾을 것이다.
✔️ 배열에 데이터를 삽입하는 원리와 속도
토마토를 추가하고 싶다고 가정해보자.
- 방법 1) 배열 맨 마지막에 토마토를 추가하는 방법
| 배추 | 감자 | 당근 | 파 | 토마토 |
|---|
- 방법 2) 배열 중간(예를 들어, 감자 뒤)에 토마토를 추가하는 방법
당근과 파를 한 단계씩 뒤로 밀어야한다. 일일히 하나씩 뒤로 밀어야하기 때문에 배열 길이가 길때는 시간이 오래 걸린다.
| 배추 | 감자 | 토마토 | 당근 | 파 |
|---|
- 방법 3) 배열에 데이터가 꽉 차있을 때 토마토를 추가하는 방법
- 데이터를 추가하는 3가지 방법 중 가장 느리다.
더 큰 배열을 새로 만들기 -> 기존 데이터 복사하기 -> 큰 새 배열에 붙여넣기
✔️ 배열에서 데이터를 삭제하는 원리와 속도
| 배추 | 감자(❌) | 당근 | 파 |
|---|
⬇️ 감자 삭제 후 당근과 파를 한칸씩 앞으로 당기기.
| 배추 | 당근 | 파 |
|---|
데이터를 삭제할 때 맨 마지막에 데이터를 삭제할 때 제일 쉽고 맨 앞에 있는 데이터를 삭제할 때 제일 어렵다.
✔️ 배열의 원리
- 배열은 램이라는 기억 창고에 줄줄이 나열되어 있는 상자열이다.
- 배열을 만들때는 컴퓨터에게 배열의 시작 번호와 길이를 알려줘야한다. 그렇기 때문에 배열 '읽기'데 걸리는 속도는 매우 빠르다. "4번째 상자 안의 데이터를 읽어줘"
- 배열은 맨 앞에 부터 차곡차곡 채워져야 하기 때문에 맨 마지막 상자의 데이터를 삭제 및 삽입할 때 속도가 제일 빠르고, 맨 첫번째 상자의 데이터를 삭제 및 삽입할 때 속도가 제일 느리다.
📌시간 복잡도(time complexity)
시간복잡도는 작업 속도를 의미한다. 시간 복잡도는 '준비~시작!'과 같이 실제 시간을 재는 것이 아니라 작업이 얼마나 많은 단계를 거치는지를 측정한다. 어떤 작업을 하는데 있어 어떤 코드는 5단계, 다른 코드는 20단계를 거친다면 5단계를 거치는 코드가 시간 복잡도가 적은 코드라고 할 수 있다.
알고리즘으로 작업을 완료할 때 까지 걸리는 단계 수 N을 이용해서 ,과 같이 표현하는데 이를 빅오(Big-O) 표기법이라고 한다.
- 배열 arr의 첫번째 데이터를 출력하는 코드
def print_first(arr):
print(arr[0])배열의 길이와 상관없이 이 함수는 딱 한번 실행되고 끝나기 때문에 시간복잡도가 이다.
'시간 복잡도 '은 '상수 시간(constant time)내에 실행된다'는 말로도 표현한다.
- 배열 arr의 첫번째 데이터를 2번 출력하는 코드
def print_first(arr):
print(arr[0])
print(arr[0])Big-O는 실행 단계에 영향을 주는 요소만 보기 때문에 이 경우에도 시간 복잡도는 이다.
- 배열 arr의 모든 데이터를 출력하는 코드
def print_all(arr):
for n in arr:
print(n)시간 복잡도는
- 배열 arr의 모든 데이터를 중첩 반복문으로 출력하는 코드
def print_twice(arr):
for n in arr:
for x in arr:
print(x,n)시간 복잡도는
📌검색 알고리즘
어떤 알고리즘을 선택하는지에 따라 작업 속도에 엄청난 차이가 생긴다.
✔️선형 검색(linear search) 알고리즘
- 배열을 맨 앞에서부터 차례대로 하나씩
검색하는 알고리즘 - 배열의 길이가 N이면 시간 복잡도는 이다.
- 최악의 경우는 찾는 데이터가 가장 마지막에 있을 때다.
- 의 그래프 형태를 가지며, 배열의 길이가 길어지면 '검색' 시간도 길어진다.
✔️이진 검색(binary search) 알고리즘
- 배열의 크기가 클때(데이터가 많을 때) 선형 검색보다 훨씬 좋은 알고리즘
데이터의 정렬이 끝난 배열에서만 사용할 수 있다. 즉, 이진 검색 알고리즘을 사용하고 싶다면 배열은 항상 정렬되어 있어야 한다. 12345 또는 54321 같이 순서대로 정렬된 데이터. 34251같은 데이터에서는 안됨.- 검색 방법
배열의 중간값과 찾는 숫자를 비교해서 확인 할 필요가 없는 쪽은 보지 않는다.

- 이진 검색이 빠른 이유는 단계마다 배열의 절반을 제외할 수 있기 때문이다.
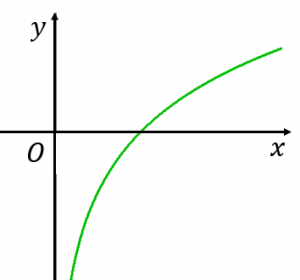
- 의 그래프 형태를 갖는다.
배열 길이가 길어져도 검색 시간이 확 커지지 않는다.
오늘 읽은 소감 및 떠오르는 생각
요즘 카카오톡 클론코딩을 하면서 HTML,CSS에만 빠져 지냈는데 역시 개발자라면 알고리즘과 자료구조 쪽을 그냥 넘어갈 수 없는 것 같다. 시간이 걸리더라도 나중에 다시 봤을 때도 이해가 갈 정도로 정리하고 꼭 명확히 짚고 넘어가려고 한다.
오늘 읽은 다른 사람의 TIL
m13465님: 중요한 부분에 하이라이트를 주셔서 눈에 잘 보였습니다.
psm3560님: 깔끔하게 잘 정리되어 핵심을 잘 볼 수 있었습니다.
summereuna님: '알고리즘은 보통 대기업 면접 볼 때 꼭 쳐야 하는 시험 느낌이 강했는데 이렇게 재밌는지는 꿈에도 몰랐다'는 표현이 인상깊었습니다.
