서론
우리는 JAVA에서 비슷한 속성의 데이터가 여러개일 때 배열을 사용합니다. 그러나 배열은 치명적인 단점이 있습니다. 그 단점은 크기가 불변하다는 것인데요. 배열을 선언할 때 크기를 같이 선언해야 하기때문에 초기에 선언한 크기를 그대로 사용해야 합니다. 줄이거나 늘릴 수 없습니다. 이런 단점으로 인해 한 가지 단점이 더 생기는데요. 바로 중간의 데이터를 제거한다면 이미 0번부터 마지막 인덱스까지의 메모리 크기를 할당받았기 때문에 사용하지 않는 배열의 중간 데이터는 메모리를 낭비하게 됩니다. 이러한 문제점이 발생하여 JAVA는 컬렉션 인터페이스와 컬렉션 인터페이스의 구현체 클래스를 포함한 Collection Framework 라는 것을 버전 1.2부터 탑재합니다. 오늘 우리는 이 컬렉션 프레임워크에 대해서 알아볼 것입니다. 필자도 그렇게 경력이 긴 개발자는 아니지만 컬렉션 프레임워크의 구현체를 제대로 못다루는 사람들을 봐왔습니다. 데이터의 삽입, 삭제가 빈번한데 ArrayList를 사용한다던가, Map이나 Set을 사용하면 되는데 List를 사용해서 시간복잡도를 기하급수적으로 증가시키는 등의 사례를 봐와서 이 글을 읽는 분들은 좀더 효율적인 코드를 짜기를 바라며 글을 씁니다. 이 글에서는 List만을 다룹니다. 컬렉션 프레임워크에 대해서 설명해야 하는 양이 너무나 방대하기 때문에 각 인터페이스인 List, Set, Map에 걸쳐서 글을 나눠 쓰겠습니다.
본론
컬렉션 프레임워크에는 크게 3가지 인터페이스가 있습니다. List, Set, Map이 바로 그것입니다. 소스코드를 보면 알 수 있겠지만, 컬렉션 프레임워크의 인터페이스들은 아래와 같은 상속구조를 갖습니다.
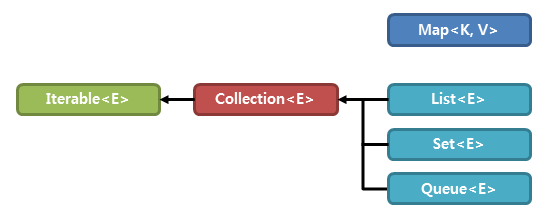
출처 : TCP School
이 중 Iterable의 의미는 '반복가능한' 입니다. 즉, List, Set, Queue는 반복 가능한 클래스입니다. 그러나 Map은 구조상의 차이로 인해 컬렉션 인터페이스와는 별도로 정의됩니다.
List
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
(순서가 있는 컬렉션입니다. 이 인터페이스의 사용자는 각 요소가 삽입된 리스트의 정확한 위치를 제어할 수 있습니다. 사용자는 리스트의 정수 인덱스로 요소에 접근할 수 있고,(리스트가 가진 위치에 한해서) 리스트의 요소를 검색할 수 있습니다. )
출처 : 오라클 List 문서
먼저 가장 많이 사용하는 List 인터페이스에 대해서 알아볼 것입니다. List는 순서가 있는 데이터의 집합으로, 데이터의 중복을 허용합니다. 배열과 상당히 유사한 구조를 가지고 있지만, 크기가 가변적인 점은 배열과 차이를 두고 있습니다. 아래 그림을 보겠습니다.

위 그림을 설명하면 표의 상단은 인덱스 번호, 하단은 삽입된 객체의 주소를 포함하고 있습니다. 특히, 하단의 1번 인덱스와 3번 인덱스가 하나의 객체를 가리키고 있는데, 이는 리스트에 중복된 값이 허용된다는 것을 의미하고, 중복된 값이 들어갈 때 새로운 객체를 만들지 않고 중복되는 객체를 가리킨다는 것을 알 수 있습니다. 이는 String이 같은 문자열이 할당되면 String Constant Pool에 있는 데이터를 사용하는 것과 유사한데, JAVA는 이런식으로 메모리를 절약합니다.
List는 기본적으로 인터페이스, 즉 기본 설계도에 불과하므로 이를 구현한 구현체를 실제로 사용하게 됩니다. List의 구현체는 대표적으로 ArrayList, LinkedList, Vexctor 등이 있습니다. 이 외에도 List의 구현체가 많이 있지만, 가장 대표적으로 사용되는 것을 꼽았습니다.
ArrayList
ArrayList는 List 인터페이스를 구현한 구현체 클래스로, 크기가 가변적으로 변하는 선형 리스트입니다. 선형 리스트는 자료구조의 일종으로, 차후에 자료구조를 다룰 때 자세하게 알아보겠습니다. 간단하게 말하면 입력 순서대로 저장하는 데이터입니다.
오라클의 List 인터페이스 문서를 보면 알 수 있겠지만 List 인터페이스에는 add() 메소드가 있어 맨 처음 add() 메소드로 추가되는 데이터의 인덱스는 0, 그 다음 추가되는 데이터의 인덱스는 1이 됩니다. 이처럼 입력되는 순서로 데이터가 저장되는 자료구조를 선형 리스트라고 합니다.
아래 코드로 보겠습니다.
transient Object[] elementData;
private int size;
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}기본적으로 ArrayList는 Object 배열입니다. 앞에서 말씀 드렸듯이, 배열의 크기는 고정입니다. 그런데 이상합니다. ArrayList를 써보신 분들은 아시겠지만, ArrayList는 크기가 고정이 아닙니다. 그리고 중간에 데이터를 추가할 수도 있습니다. 그렇다고 기존의 중간에 있던 데이터는 덮어씌워지지 않고 한칸씩 밀립니다. 즉, 크기가 늘려졌다는 뜻이죠. 그러면 어떻게 크기를 늘릴까요?
그에 대한 해답은 add 메소드와 grow 메소드에 있습니다. 우리는 보통 ArrayList에 데이터를 넣을 때 add() 메소드를 사용합니다. add 메소드는 private 메소드인 add를 실행합니다. 그리고, private add 메소드는 크기를 비교하여 한계치에 도달한 상태에서 add 메소드가 호출되면 grow 메소드를 호출합니다. 아래는 grow 메소드의 소스코드입니다.
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,newCapacity(minCapacity));
}public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,Math.min(original.length, newLength));
return copy;
}grow 메소드는 단어의 의미처럼 크기를 늘려주는 메소드입니다. 즉, ArrayList의 초기 크기에 도달했을 때 add 메소드가 호출 될 경우 grow 메소드를 호출함으로써 ArrayList의 실제 값인 Object 배열의 크기를 늘려줍니다. 그 근거로, Arrays.copyOf 메소드를 추적하다 보면 가장 마지막에 System.arraycopy 라는 메소드가 나옵니다. 이 메소드는 전에 StringBuilder, StringBuffer에 대해서 설명 드릴 때 말씀드렸듯이, 배열의 필요한 부분만 복사하기 때문에 자원을 아끼면서 복사할 수 있습니다.
데이터를 추가하는게 끝났으면 조회도 해야합니다. get 메소드도 같이 보겠습니다.
public E get(int index) {
Objects.checkIndex(index, size);
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}추적을 하여 elementData 라는 메소드를 보면, 단순히 elementData 배열에 index로 접근합니다.
종합하자면, ArrayList는 핵심 데이터가 Object 배열로 되어있습니다. 배열의 크기는 불변하기때문에, 데이터를 추가할 때마다 배열을 새로 선언하기 때문에 자원을 많이 사용합니다. 크기가 999개인 ArrayList에 데이터를 1개 더 추가한다면 크기가 1000인 배열을 다시 선언해서 데이터를 복사 후 추가할 데이터를 추가합니다.
LinkedList
LinkedList는 ArrayList와 마찬가지로 List 인터페이스를 구현한 구현체입니다. 그럼 ArrayList와는 뭐가 다를까요? 내부 클래스를 보겠습니다.
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
/**
* Pointer to first node.
*/
transient Node<E> first;
/**
* Pointer to last node.
*/
transient Node<E> last;
public LinkedList() {
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}LinkedList에는 ArrayList의 Object 배열이 없으나, 대신 내부 클래스인 Node 클래스의 item으로 데이터를 관리합니다. 그리고 전역변수에는 first, last 멤버변수가 있는데 설명을 각각 보면 첫 번째 노드를 가리키는 포인터, 마지막 노드를 가리키는 포인터 라는 설명이 있습니다. 또한, Oracle 공식 문서를 살펴보면 다음과 같습니다.
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end, whichever is closer to the specified index.
(리스트와 덱 인터페이스의 구현체인 이중연결리스트입니다. 모든 선택적인 리스트 명령을 구현하고, null을 포함한 모든 element를 허용합니다. (갖습니다. ))
(모든 명령은 이중 연결 리스트처럼 실행됩니다. 리스트에 대한 인덱싱 명령은 특정 인덱스에 더 가까운 시작점, 혹은 마지막 지점부터 리스트를 순회합니다.
출처 : 오라클 LinkedList 문서
이름과 문서를 보시면 알 수 있듯이, 자료구조인 이중 연결 리스트로서 작동하고, 인덱스로 접근할 때 순회를 하여 접근합니다. 즉, 데이터를 추가할 때는 포인터로 가리키기만 해서 따로 핵심 데이터의 크기를 늘리거나 줄일 필요가 없고, 데이터에 접근할 때는 순회를 하여 접근하기 때문에 ArrayList와는 상반된 성격을 띕니다. ArrayList가 탐색에 최적화된 컬렉션이라면, LinkedList는 데이터를 하나씩 추가하기에 최적화된 컬렉션입니다.
그럼 하나씩 알아봅시다. add() 메소드를 어떻게 구현했는지 알아보도록 하겠습니다.
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}우선, add 메소드는 linkLast 메소드를 호출합니다. linkLast 메소드는 타겟 데이터로 노드 데이터를 만들어준 후 마지막 노드가 타겟데이터로 만든 노드를 가리키게 합니다. 그러면 타겟 데이터로 만든 노드가 마지막 노드가 되겠죠. 마지막으로 size를 키워줍니다.
이런 과정을 통해 LinkedList는 데이터를 추가할 때 O(1) 의 시간복잡도를 가집니다.
그렇다면 탐색은 어떻게 할까요? 위 오라클 문서 2번째 문단에 "리스트에 대한 인덱싱 명령은 특정 인덱스에 더 가까운 시작점, 혹은 마지막 지점부터 리스트를 순회합니다. " 라고 되어있는데, 이는 get(int index) 메소드를 보면 알 수 있습니다.
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}get(int index) 메소드는 인덱스 검증을 한 후 node(int index) 메소드를 호출합니다. node 메소드는 size를 시프트 연산자로 2를 나눈 뒤, index와의 크기를 비교한 후 찾을 index가 첫번째 노드에서 가까우면 첫번째 노드부터 시작하여 정순으로 순회하고, 마지막 노드에서 가까우면 마지막 노드에서부터 역순으로 순회합니다.
이런 이유로 인해 시간복잡도는 O(n)입니다. 왜 O(n^2) 이 아니냐고 하시는 분들이 있을 수 있습니다. 시간복잡도 표기 중 하나인 big-O 표기법은 n개의 입력이 있을 때 몇번을 반복해야 결과를 얻어낼 수 있는지이기 때문에 엄밀히 따지면 O(1/2*n) 입니다만, 점근 표기법 규칙 중에서 상수가 아닌 n이 있을 때는 숫자를 제외한다는 규칙이 있으므로 1/2은 제외하고 O(n)이라고 표기하는겁니다.
Vector
마지막으로 Vector 입니다. Vector 클래스에 대해서 문서를 참고하겠습니다.
The Vector class implements a growable array of objects. Like an array, it contains components that can be accessed using an integer index.
(Vector 클래스는 커질 수 있는 object의 배열을 구현합니다. 배열처럼, Vector는 정수 index를 사용하여 접근할 수 있는 요소를 가집니다. )
...
Vector is synchronized. If a thread-safe implementation is not needed, it is recommended to use ArrayList in place of Vector.
(Vector는 동기화를 지원합니다. 스레드 세이프한 구현체가 필요하지 않다면 Vector보다는 ArrasyList 를 사용하는 것을 추천합니다. )
출처 : 오라클 Vector 문서
Vector는 JAVA 1.0 부터 지원하던 기능입니다. 그러나, 컬렉션 프레임워크가 등장한 후 확장되어 컬렉션 프레임워크의 구현체 중 하나가 되었습니다. Vector는 아래 소스코드를 보시면 알 수 있듯이, ArrayList와 매우 닮아있는 모습을 알 수 있습니다. 그러므로 ArrayList와 장, 단점을 공유합니다.
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
protected Object[] elementData;
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public synchronized boolean add(E e) {
modCount++;
add(e, elementData, elementCount);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
elementCount = s + 1;
}
}ArrayList와 다른 점은 딱 한가지 입니다. 메소드 앞에 synchronized라는 지시자를 추가해줬습니다. 이 지시자는 이전에 StringBuilder, StringBuffer 차이에 대해 설명했듯이, 동기화를 지원하며, 스레드를 락/언락하는 자원이 들기 때문에 동기화를 지원하지 않는 클래스에 비해 조금 더 느립니다. 위 오라클 문서에서도 스레드 세이프한 환경이 아닌 곳에서는 ArrayList를 사용하는 것을 오라클에서도 공식적으로 추천합니다.
