

데이터 링크 계층에서 데이터를 부를 때 데이터를 프레임이라고 말한다.
프레임은 크게 3가지로 나뉘게 된다.
- 데이터 프레임
- 긍정 응답 프레임
- 부정 응답 프레임
긍정, 부정 응답 프레임은 수신자가 데이터를 받았을 때 너가 보내준 데이터 "잘 받았어" 혹은 "못 받았어"라고 응답을 해줄 때 보내는 응답 프레임이다.
긍정 응답 프레임 = 데이터를 잘 받았을 때
부정 응답 프레임 = 데이터를 못 받았을 때, 변형이 일어났을 때
그럼 전송 매체를 통해서 이동하고 있는 하나의 프레임이 있다고 가정을 했을 때
이 프레임이 데이터 프레임인지, 긍정, 부정 응답 프레임인지 어떻게 구분을 할까?
헤더나 트레일러에 어떤 프레임인지 구분하기 위한 추가되는 정보가 붙어 이를 알 수 있도록 한다.
또한 헤더나 트레일러에 오류가 발생했는지 아닌지를 검사하기 위해 필요한 정보가 들어간다.
그 외에 순서 번호, 송수신 호스트의 주소, 프로토콜에 필요한 제어 코드와 같은 정보가 붙게 된다.
데이터를 크게 3가지 종류로 분류하는 것 외에도
정보를 어떤 방식으로 표현하느냐에 따라서 크게 2가지로 구분된다.
- 문자로 표현할 것이냐 => 문자 프레임 => 데이터를 문자로 인식
- 비트로 표현할 것이냐 => 비트 프레임 => 데이터를 비트로 인식
이는 간단히 데이터 자체를 문자로 인식 할 것이냐 혹은 비트로 인식할 것이냐에 대한 것이다.

그럼 먼저 문자 프레임에 대해 살펴보자.
문자 프레임은 문자 데이터를 전송할 때 사용하며 아스키코드 로 동작한다.
아스키코드 방식은 0과 1의 비트값으로 문자를 표현할 때 7개의 비트를 가지고 아스키코드로 표현한다.
아스키코드 방식 이외에도 여러 문자로 표현하는 방식이 있지만 가장 많이 쓰이는 방식이다.
아스키코드가 표현하는 방식은 1바이트가 8비트인데 8비트에서 7비트를 문자로 인식하겠다는 것이다.
8비트 중 7비트는 문자를 표현하는 데 사용하고 남은 1비트는 무엇이냐
남은 1비트는 오류를 검출하는 용도로 활용된다.
1비트는 패리티 비트라고 말하며 패리티 비트 방식이 오류를 검출하는 방식 중 하나이다.
정리하면 프레임을 문자 프레임과 비트 프레임으로 나누는데
문자로 표현하는 방식은 아스키코드를 사용할 것이고
문자 프레임은 데이터를 문자로 표현하는데 8비트 단위로 잘라서
7비트는 온전히 문자를 표현하는데, 1비트는 오류를 검출하는 패리티 비트로 사용한다는 것이다.
데이터를 보낼 때 프레임은 아래 (a)라고 표시된 구조와 같다.

중간에 프레임 데이터가 존재하는데 이 프레임 데이터가 내가 보내고자 하는 문자이고,
그럼 앞, 뒤로 붙어있는 것들이 무엇이냐
STX는 Start of text로 내가 전달하고자 하는 문장이 여기서 시작한다는 의미이고
ETX는 End of text로 여기서 끝난다는 의미이다.
DLE = data od escape이고 지금은 알 필요 없이 넘어가도 된다.
아스키코드 표에서 제어 문자라고 해서 특수문자가 있는데 제어 문자 중 하나가 바로
DLE STX DLE ETX와 같은 애들이다.
그래서 문자 프레임은 아스키코드 표현 방식을 사용했을 때 시작과 끝을 구분하는 용도로 이러한 제어 문자를 사용한다.
이렇게 DLE STX DLE ETX로 시작과 끝을 구분해 주는 것은 좋은데 만약 내가 보내는 데이터에 DLE ETX라는 제어문자가 포함되어 있을 때는 어떻게 해야 하는가?
수민이가 철수에게 데이터를 보내는데 수민이가 보내는 데이터에 DLE ETX가 포함되어 있다면
철수는
아래 데이터 중에서

앞에 있는 DATA만 전달 받고 뒤에 있는 DATA는 전달 받지 못하는 상황이 벌어진다.
뒤에 있는 나머지는 그냥 비트 값으로 단순하게 인식이 될 것이다.
이렇게 되면 안 되기 때문에 이를 막기 위해서
스터핑이라는 방식이 도입된다.
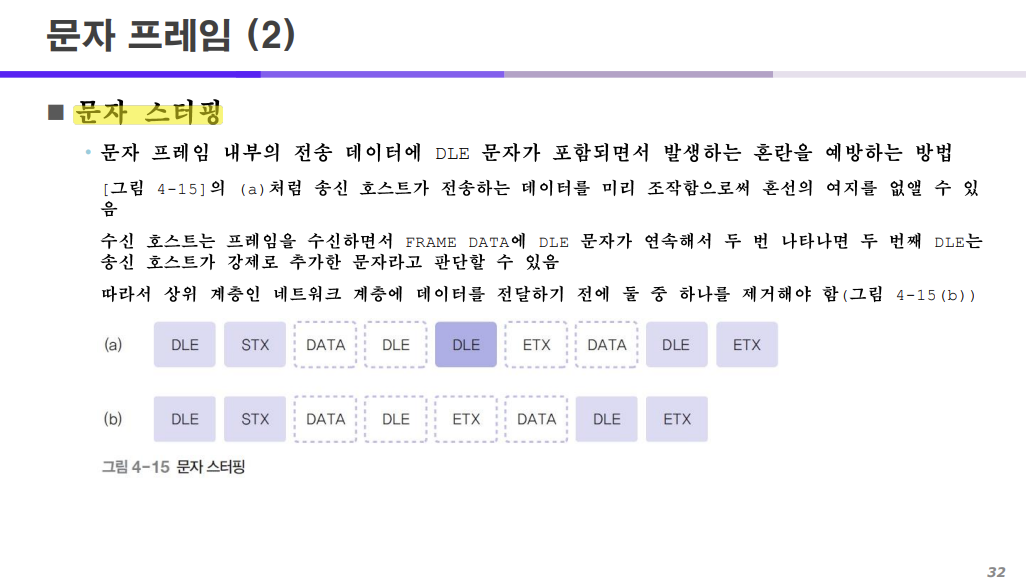
문자 프레임에서 사용되는 문자 스터핑의 의미는 다음과 같다.
보내고자 하는 텍스트에 끝나는(DLE ETX) 혹은 시작하는(DLE STX) 제어 문자가 들어 있을 경우에 DLE ETX 사이에 DLE를 하나 더 추가하는 방식이다.
즉 위 이미지와 같이 DLE DLE ETX가 되는 것이다.
그럼 철수는 다음과 같이 데이터를 전달받게 된다.
철수는 DATA DLE DLE ETX DATA를 받았을 때
DLE STX를 확인해 여기가 시작하는 부분임을 확인하고 DATA를 확인한 후
뒤에 DLE DLE ETX를 확인할 때 DLE 뒤에 나온 DLE를 통해 수민이가 일부터 DLE를 추가했다는 사실을 알아차리고 DLE 하나를 삭제한 후 다시 DATA DLE ETX DATA를 전달하게 되는 것이다.
즉 송신자는 내가 보내는 데이터에 DLE ETX라는 제어 문자가 있으면 사이에 DLE를 추가해 보내주는 것이고
수신자는 DLE DLE ETX를 확인해 DLE를 빼고 이를 데이터 링크 계층의 다음 계층인 네트워크 계층으로 올려 보내게 되는 것이다.
순서는 다음과 같다.
- 철수가 데이터를 물리 계층에서 받음
- 물리 계층에서 데이터 링크 계층으로 전달
- 데이터 링크 계층에서 문자 프레임에 DLE DLE ETX, DLE DLE STX가 있으면 DLE 하나를 삭제
- 네트워크 계층으로 전달
이렇게 문자 스터핑이라는 기법을 사용해서 내가 보내는 문장에 제어 문자가 포함되어 있는 경우 이러한 방식으로 해결을 한다는 것을 보여줬다.

다음은 비트 프레임이다.
비트 프레임은 단순하게 0과 1로 비트로 표현하는 것이다.
비트 프레임의 경우에 내가 보내고자 하는 의미를 가지는 0과 1의 숫자가 어디서 시작하고 어디서 끝나는지 알기 어렵기 때문에 앞, 뒤로 특정한 패턴의 0과 1의 숫자들을 놓는다.
특정 패턴의 비트는 다음과 같다.
8비트 중 앞에 0과 뒤에 0비트를 두고 나머지는 모두 1로 채우는 것이다.
1 2 3 4 5 6 7 8
0 1 1 1 1 1 1 0 이렇게 앞, 뒤로 0을 놓고 나머지는 1로 채워 시작과 끝을 표현하는 것이다.
위 특정 패턴 사이에 이제 내가 표현하고자 하는 내용을 비트로 표현하게 된다.
우리는 이 특정 패턴을 플래그라고 표현한다.
하지만 이도 마찬가지로 플래그에서는 1을 연속으로 6번 사용하는 패턴으로 표현을 한 것인데
사용자가 보내는 데이터의 내용 중 1이 연속으로 5번 발생하게 되면 플래그가 표현 되는 것을 막기 위해서 강제로 1이 5번 나오는 숫자의 뒤로 0을 붙이게 된다.
그래서 다음과 같이

비트 스터핑이라는 것이 도입되어
1이 연속으로 5번 발생하면 강제로 다음에 0을 추가해 전송하게 된다.
예시)
1 2 3 4 5 6 7 8
0 1 1 1 1 1 1 0
=>
1 2 3 4 5 6 7 8 9
0 1 1 1 1 1 0 1 0
이렇게 강제로 뒤에 0을 붙여서 연속으로 1이 6개가 되는 것을 막는다.
이를 비트 스터핑이라고 한다.
순서
- 송신 호스트가 보내는 데이터에 1이 연속으로 5개가 있으면 비트 스터핑을 통해 0을 추가
- 송신 호스트가 데이터를 전송
- 수신 호스트가 물리 계층에서 데이터를 받고 데이터 링크 계층으로 전송
- 데이터 링크 계층에서 01111110 패턴을 확인하면 그 뒤가 데이터임을 확인
- 확인된 데이터에서 1이 연속으로 5개 나오고 뒤에 0이 있으면 0을 제거
- 0이 제거된 후 네트워크 계층으로 전송


오류를 해결하는 방법에는 크게 2가지가 존재한다.
- 재전송하는 방법
- 변형된 오류를 내가 복구하는 방법
우리가 2번째 방식으로 변형된 오류를 복구하는 방법을 진행하려면 원래 데이터가 어떤 데이터인지에 대한 정보가 필요한데 이는 우리가 데이터를 보낼 때 통신사에서 함께 포함시켜서 보내게 된다.
1번째 방법인 재전송하는 방법은 처음에 데이터를 보낼 때 오류를 검출하기 위한 정보인 오류 검출 코드를 포함시켜서 전송하고 수신 호스트는 오류를 발견하기 위해서 포함된 코드를 사용해 오류 검출을 시도한다. 이때 오류가 검출되면 재전송 요청을 통해 재전송이 진행된다.
1번째 방법과 같이 재전송을 요청하는 방식은 역방향 오류 복구 방식이라고 하며 대표적인 방법이 패리티 비트 방법으로 패리티 비트를 가지고 검사하게 된다.
2번째 방법은 수신 호스트에서 자체적으로 오류를 복구하는 방법으로 오류를 복구하기 위한 코드가 전송할 때 함께 포함되어 전달된다. 이와 동시에 오류가 발생했음을 알 수 있게 오류 검출 코드도 함께 전송한다. => 데이터, 오류 검출 코드, 오류 복구 코드를 전송함
2번째 방법과 같이 수신 측에서 오류를 복구하는 방식을 순방향 오류 복구 방식이라고 분류한다.
우주 정거장과 같이 거리가 먼 곳으로 데이터를 보내는 경우엔 데이터를 보내고 똑같은 데이터를 한 번 더 보내서 데이터 변형을 예방하는데 이것 또한 역방향으로 재전송 요청이 없었기 때문에 순방향 오류 복구 방식에 해당한다.

순방향 오류 복구 방식이든 역방향 오류 복구 방식이든 모두 오류를 검출하고 행동을 취하는 것인데
그러면 오류를 검출하기 위한 방식에 대해서 이번 시간에 살펴보도록 하자.
오류를 검출하기 위한 대표적인 방식은 다음과 같다.
- 패리티 비트
- 블록 검사
- 다항 코드
먼저 패리티 비트를 보자.
패리티 비트 방식은 1바이트 즉 8비트의 구조에서
7비트의 아스키코드와 1비트의 패리티 비트로 이루어져 있다.
패리티 비트는 8개의 비트에서 1의 갯수가 짝수인지 홀수인지를 판단해 오류를 검출하는 기법이다.
패리티 비트는 짝수 패리티 비트와 홀수 패리티 비트 2개로 나뉘어 지는데
사전에 수민이와 철수가 짝수 패리티 비트 방식으로 협의를 진행한 후
수민이가 1의 갯수를 짝수개로 맞춰서 데이터를 전송하면 철수는 받은 데이터에서 1의 갯수가 짝수인지 아닌지를 확인해 오류를 확인하도록 한다.
짝수 패리티 비트는 1의 갯수가 짝수여야 정상이고 홀수는 1의 갯수가 홀수여야 정상이다.
만약 수민이가 0110110 7비트의 값을 보내고자 한다면 이미 7비트에서 1의 갯수가 짝수개이므로 남은 패리티 비트 1개는 0을 뒤에 붙여서 보내도록 하는 것이다.

이렇게 하면 짝수 패리티 방식으로 1개 갯수가 짝수인 상태에서 전달되는 것이다.
만약 철수가 데이터를 받았을 때 1의 갯수가 홀수이면 오류가 발생한 것을 확인할 수 있고 아니라면 데이터가 정상적으로 도착했음을 확인할 수 있다.

하지만 패리티 비트 방식에는 단점이 존재한다.
바로 수민이가
12345678
01101100과 같이 1을 짝수로 맞춰서 데이터를 보냈음에도 전송할 때 0과 1의 위치가 뒤바뀌는 상황이 존재한다.
이럴 경우 철수는
12345678
01110100과 같이 1은 짝수가 맞지만 수민이가 보낸 데이터와는 다른 데이터를 받게 되고 이는 패리티 비트 방식으로는 오류를 확인할 수 없다는 것이다.
이를 해결하기 위해서 바로 블록 검사가 존재한다.

블록 검사 방식은 다수의 비트에서 오류가 발생했을 때 오류를 검출하는 방법으로 패리티 방식을 개선한 방식이다.
이전에 패리티 비트 방식은 1개의 바이트에 대해서 1개의 비트를 가지고 검사를 진행하는 방식이었는데
위 블록 검사 방식은 검사하는 바이트를 1개가 아닌 여러 개의 바이트를 하나의 블록으로 구성해 수평, 수직으로 검사를 진행하도록 하는 방식이다.
따라서 위와 같이 짝수 패리티 방식을 사용하는 데 단 검사하는 바이트를 여러 개의 블록으로 구성해 오류를 검출할 수 있는 확률이 높은 방식이다.

하지만 블록 검사 방식은 아래와 같은 단점이 존재한다.
- 전송되는 데이터의 양과 비교해 오류 검출을 위한 오버헤드가 크다는 단점(검사할 게 많다.)
- 위 그림과 같이 수평, 수직 방향에서 사각형의 형태로 짝수개의 데이터 오류가 발생하는 경우 이를 검출하지 못한다는 단점
이러한 문제점을 해결하기 위해서 다항 코드를 사용한다.
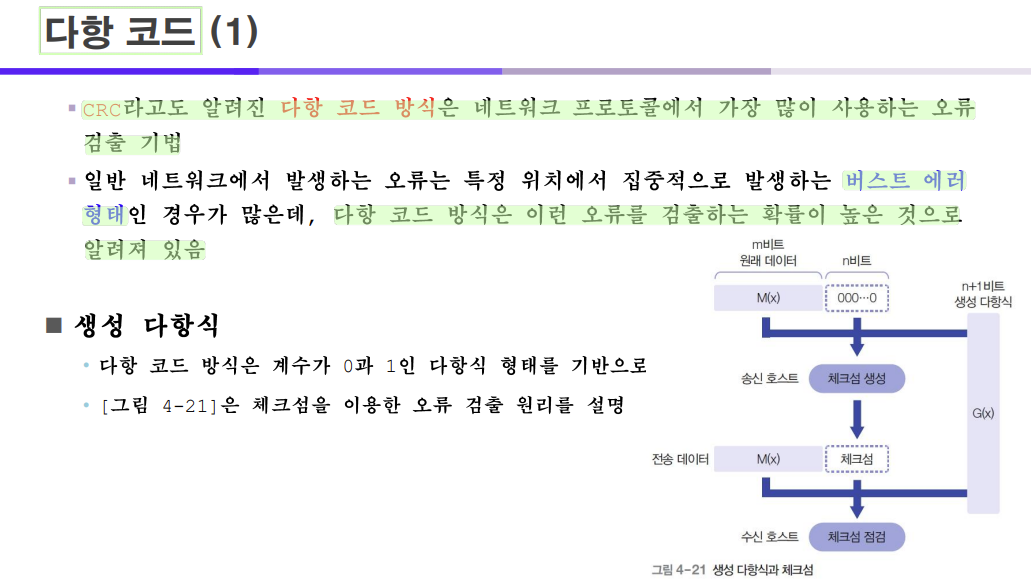
다항 코드 방식은 CRC라고 불리며 다항 코드 방식은 버스트 에러 형태에서 오류를 검출하는 확률이 높다.
버스트 에러란 여러 개의 비트가 한꺼번에 손상되는 경우를 의미한다.
0110100의 값이 100101과 같이 한 번에 뒤바뀌는 것이다.
다항 코드 방식은 말 그대로 다항식을 사용해서 에러를 검출하겠다는 것이다.
- 원본 데이터는 0과 1의 데이터이고 이 데이터를 다항식을 가지고 나누도록 한다.
- 나누어서 나눈 값은 에러를 검출하는 용도로 사용.
이게 다항 코드 방식이다.
다항 코드의 순서
- 수민이와 철수가 먼저 에러를 검출하는 용도로 다항식을 미리 정한다.
- 수민이가 철수에게 보내고자 하는 데이터가 있으면 다항식을 활용해서 나누어 나머지를 구한다.
- 수민이는 데이터를 철수에게 보낼 때 위에서 구한 나머지를 함께 데이터에 붙여서 보내도록 한다.
- 철수는 데이터와 나머지를 전달받고 수민이와 똑같은 다항식을 가지고 데이터를 나눈다.
- 철수는 다항식과 받은 데이터를 통해 구한 나머지 값을 받은 나머지와 비교한다.
- 이때 나머지 값이 같아야지 원본 데이터가 이상없이 도착한 것이고 같지 않다면 원본 데이터가 변형된 것이다.
예제를 확인해보자.
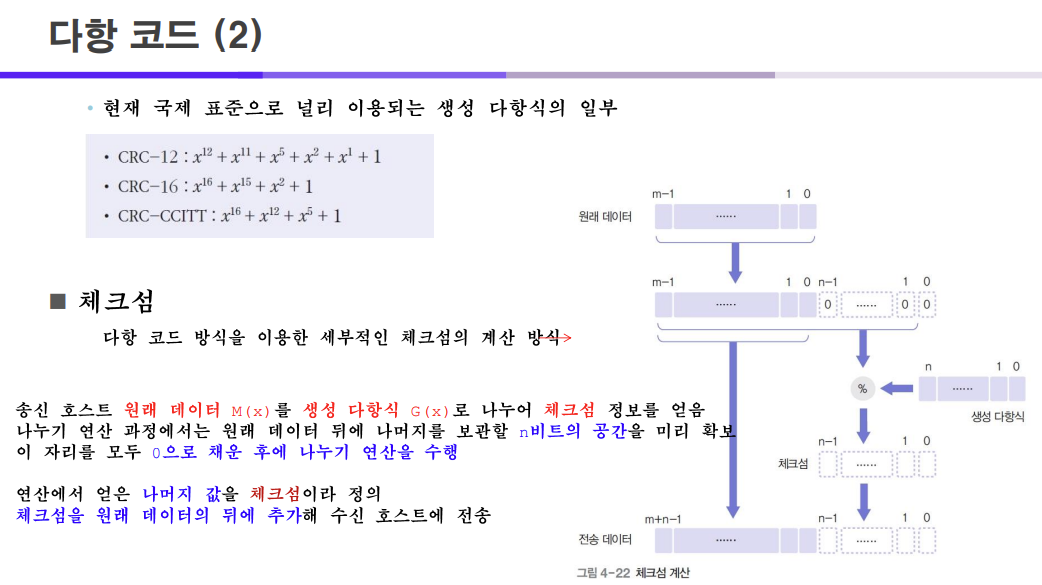
다항식은 국제 표준으로 널리 이용되는 것과 임의로 정한 다항식이 있다.

우리는 임의로 정한 다항식인 G(X)를 사용할 것이고 원본 데이터는 101101001이다.
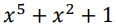
위 다항식은 아래와 같이 표현할 수 있다
따라서 100101이 되는 것이다.
그럼 위에서 궁금한 점이 왜 원본 데이터 뒤에 5개의 0을 추가로 붙여주었냐?
이는 다항 코드 방식에서 원본 데이터와 나머지를 추가로 전송해주기 때문에 이 자리를 미리 만들어 놓기 위해서이다.
원본 데이터 뒤에 붙는 0의 갯수를 구하는 방법은 다음과 같다.
다항식이 총 몇 비트인지 확인 후 다항식 비트 갯수에 -1을 한 갯수만큼 원본 데이터에 0을 붙이는 것이다.
다항 코드에서 진행하는 나눗셈의 경우엔 빼주지 않도 XOR 연산을 진행하도록 한다.
XOR 연산은 아래와 같다
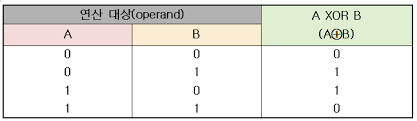
이미지 출처 : TTA정보통신용어사전
이와 같이 서로 다를 때 1이고 같으면 0인 연산이다.
따라서 연산은 다음과 같이 진행된다.
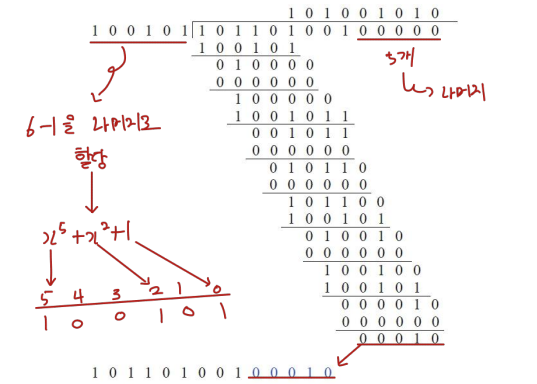
이때 나누고자 하는 값이 나누는 값보다 작더라도 우리는 가장 앞에 있는 숫자가 1이냐 혹은 0이냐를 파악해
1이면 몫이 1이 되고
0이면 몫이 0이 되는
방식으로 나눗셈을 진행한다.
크기를 따지지 않고 가장 앞에 있는 숫자만 파악한다.
이렇게 구한 나머지인 00010은
원본 데이터의 뒤에 붙어 전송된다.
그러면 수민이와 철수가 나눈 나머지가 같으면 정상인 것이고 다르면 원본 데이터에 변형이 일어난 것이다.
이러한 방식으로 오류를 검출하는 방식이 바로 다항 코드 방식이다.
나눈 나머지 값은 우리가 CRC 코드라고 한다.
