AirfoilRAG: Retrieval augmented generation framework for airfoil aerodynamic design knowledge discovery and application, 논문 정리
논문 정리
해당 논문은 다음과 같은 출처를 갖습니다.
- 논문 출처:
https://doi.org/10.1016/j.ast.2025.110933 - 제목:
AirfoilRAG: Retrieval augmented generation framework for airfoil aerodynamic design knowledge discovery and application
논문 키워드: 에오포일, 공력 설계, LLM, RAG
1. 초록 및 서론
배경
기존의 데이터 기반 익형(airfoil) 설계 방식은 전문 지식이 부족하고 해석이 어려우며, 전통적인 방식은 설계자의 경험에 크게 의존하여 신속한 설계가 어렵다는 문제가 있다.
따라서 논문에서는 이러한 문제점을 해결하기 위해 대규모 언어 모델인 LLM과 검색 증강 생성 기법인 RAG를 결합한 AirfoilRAG를 제안한다
주요 방법은 다음과 같다
-
먼저 공개 Airfoil 데이터를 활용해 익형의 이산적, 연속적, 공기역학적 특징에 따라서 데이터 셋을 구성한다.
-
익형의 기하학적 특징(이산적/연속적)과 공기역학적 특징을 결합하여 데이터를 검색하는 2단계 검색 모델을 구축한다.
-
LLM을 활용하여 익형의 기하학적 특징과 공기역학적 성능 데이터 간의 상관관계를 분석하고, LLM 미세 조정 기술(파인튜닝)을 통해 지식을 최적화한다
결과적으로 AirfoilRAG는 익형 공기역학적 예측에서 5% 미안의 평균 절대 백분율 오차(MAPE)를 보였다.
서론
효율적인 익형 공기역학적 설계는 항공기 설계의 핵심이지만, 반복적인 시행착오와 풍부한 경험을 요구한다. 최근 인공지능 기반의 데이터 중심 설계 방법이 등장했으나, 물리적 지식이 부족하고 결과의 해석이 어렵다는 한계가 있다.
이에 반해, LLM은 과학 및 공학 분야에서 전문 지식을 활용한 해석 가능한 추론 능력을 보여준다. 하지만 익형 공기역학 설계 분야에서 LLM을 활용한 연구는 아직 초기 단계로 이 논문은 RAG 프레임워크를 기반으로 전문가의 설계 경험을 설계 과정에 통합하여 데이터-지식 이중 구동 설계를 실현하는 것을 목표로 한다.
2. 관련 연구 및 논문 기여 내용
기존 연구의 한계
기존 익혁 공기역학 예측 및 역설계 연구는 데이터 기반 방법과 물리 정보가 내장된 신경망을 사용했지만, 전문가의 설계 경험이나 고전적인 설계 지식이 충분히 도입되지 않아 지식 표현과 설계 가능성이 부족했다.
논문의 주요 기여
- LLM과 RAG를 결합하여 익형 공기역학 지식 생성 및 성능 예측을 향상시킨 최초의 연구이다. 이를 통해 예측 정확도와 지식 해석 가능성을 크게 높였다.
- 익형 지식 검색을 위한 모델이 부족하다는 문제를 해결하기 위해, 기하학적 특징과 공기역학적 특징을 융합한 하이브리드 모델을 제안했다.
- 생성된 익형 지식의 유효성을 평가하기 위해, 프롬프트 구성 및 미세 조정을 통해 LLM이 익형 공기역학 예측 작업에서 생성된 지식의 합리성을 검증하는 프레임워크를 제안했다.
3. 방법론 - 전체 아키텍처 및 데이터베이스 구축 (AirfoilRAG의 4가지 주요 단계)
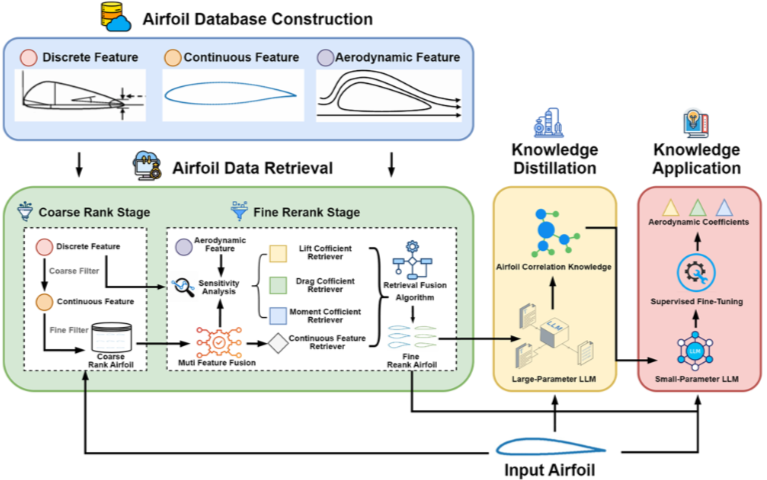
익형 데이터베이스 구축(Airfoil Database Construction)
논문은 다양한 공개 익형 데이터셋에서 데이터를 수집하여 3가지 특징을 기준으로 데이터베이스를 구성한다.
-
이산적 특징 (Discrete Feature)
: 익형의 형태를 수치적으로 요약한 11가지 핵심 매개변수 -
연속적 특징 (Continuous Feature)
: 익형을 구성하는 수많은 좌표점 데이터로 B-스플라인 보간법을 통해 연속적인 곡선 형태로 변환 -
공기역학적 특징 (Aerodynamic Feature)
: 익형의 성능 데이터로, 특정 유동 조건(받음각, 마하수, 레이놀즈 수)에서 양력 계수, 항력 계수, 모멘트 계수 등이 포함
이 단계는 LLM이 익형 데이터를 '이해'할 수 있도록, 설명 가능한 변수로 변환한 것이다.
익형 데이터 검색 (Airfoil Data Retrieval)
사용자의 익형 입력과 유사도 검사 과정
-
입력 익형
: 사용자는 .dat 또는 이와 유사한 형식의 익형 좌표 파일을 시스템에 업로드한다. 이 파일에는 익형 표면을 구성하는 수많은 점들의 (x, y) 좌표가 나열되어 있다. -
이산적 특징 추출
: 이 익형 좌표 파일을 곧바로 유사도 검사에 사용하는 것이 아니라, 먼저 논문에서 채택한 Parsec 매개변수화 방법을 통해 이산적 특징을 추출한다. 이 방법은 복잡한 익형 곡선을 11가지의 핵심 물리적 매개변수로 변환한다. -
유사도 검사
: 추출된 11가지 매개변수 값은 마치 익형의 지문처럼 사용된다. 시스템은 이 11가지 매개변수 값으 기준으로 데이터베이스에 저장된 다른 익형들의 매개변수 값과 비교하여 유사도를 계산한다. 이때 유클리드 거리 계산 방식이 활용된다. -
후보 선별
: 이 과정을 통해 입력 익형과 가장 유사한 상위 k개의 익형 리스트가 '이산적 특징 필터'에 의해 선별된다
즉, 시스템은 이미지를 직접 인식하는 것이 아니라, 이미지를 구성하는 데이터(좌표 파일)를 분석하여 핵심적인 수치 특징을 추출하고, 이를 기준으로 데이터베이스를 검색하는 것이다
그럼 본격적으로 검색 과정을 살펴보자.
검색 과정은 위에서 말했던 것처럼 총 2개 단계로 이루어진다.
그 중 1단계인 Coarse Rank Stage는 다음과 같다.
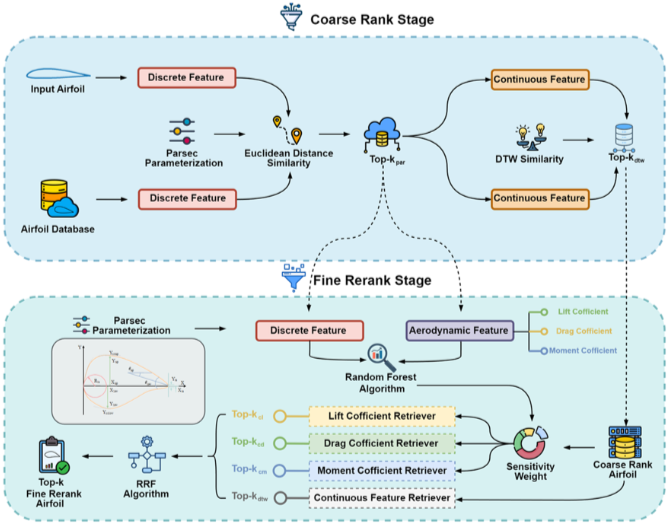
1단계: Coarse Rank Stage
이 단계는 모양만 보고 비슷한 익형들을 빠르게 걸러내는 과정이다.
- 이산적 특징 필터 (Coarse Filter)
: 입력 익형의 이산적 기하학적 특징(Discrete Feature, Parsec 매개변수화로 얻은 11가지 수치)을 사용한다. 이 특징들을 데이터베이스의 익형들과 비교하여 가장 유사한 상위 100개의 후보를 가져온다. 이 단계는 유클리드 거리 유사도(Euclidean Distance Similarity)를 기반으로 한다.
- 연속적 특징 필터 (Fine Filter)
: 이산적 특징 필터를 통과한 100개 후보 익형들을 대상으로, 입력 익형의 연속적 기하학적 특징(Continuous Feature, 전체적인 곡선 좌표)을 활용해 다시 한번 유사도를 평가한다. 이 과정에는 DTW(Dynamic Time Warping) 알고리즘이 사용된다. 이 단계에서 최종적으로 10개 정도의 익형으로 후보군이 좁혀진다.결과적으로 이 과정을 통해 Coarse Rank Airfoil이라는 10개의 익형 후보군을 얻게 된다.
2단계: Fine Rerank Stage
- 다중 특징 융합(Multi Feature Fusion)
: 1단계에서 얻은 10개의 후보 익형들을 바탕으로, 익형의 모양(기하학적 특징)과 성능(공기역학적 특징) 간의 상관관계를 분석하여 순위를 재정렬한다. 이 과정에서 랜덤 포레스트 알고리즘이 사용되어 각 기하학적 특징이 공기역학적 성능에 미치는 영향의 "민감도 가중치"를 계산한다.
- 민감도 분석 (Sensitivity Analysis)
: 논문은 랜덤 포레스트 알고리즘을 사용해서 익형의 11가지 기하학적 특징이 양력, 항력, 모멘트 계수에 얼마나 큰 영향을 미치는지 분석한다
- 가중치 부여
: 이 분석을 통해 각 특징에 대한 민감도 가중치(Sensitivity Weight)를 계산한다.
예를 들어, 어떤 익형에서는 뒷전 각도가 항력 계수에 매우 큰 영향을 미칠 수 있고, 다른 익형에서는 앞전 곡률이 양력 계수에 더 중요할 수 있다.
- 다중 검색 순위 융합
: 분석을 통해 얻은 가중치를 바탕으로 4가지 독립적인 검색기(Retriever)가 작동한다.
- 양력 계수 검색기 (Lift Coefficient Retriever)
: 양력에 중요한 기하학적 특징을 중심으로 10개 후보들의 순위를 매깁니다.- 항력 계수 검색기 (Drag Coefficient Retriever)
: 항력에 중요한 특징을 중심으로 10개 후보들의 순위를 매깁니다.- 모멘트 계수 검색기 (Moment Coefficient Retriever)
: 모멘트에 중요한 특징을 중심으로 10개 후보들의 순위를 매깁니다.- 연속적 특징 검색기 (Continuous Feature Retriever)
: 모양의 유사성에 따라 10개 후보들의 순위를 다시 확인합니다.4가지 검색기는 각각의 순위 리스트를 만든다. 이 순위들을 RRF(Reciprocal Rank Fusion) 알고리즘이라는 검색 융합 알고리즘을 사용해서 하나의 통합된 최종 순위로 합친다.
RRF 알고리즘은 각 순위 목록의 순위만을 사용하기 때문에, 서로 다른 기준으로 매겨진 순위들을 효과적으로 결합할 수 있다.
이렇게 최종적으로 선정된 익형들이 Fine Rerank Airfoil이 되며, 이 익형들의 데이터가 이후 대규모 언어 모델(LLM)의 지식 추출(Knowledge Distillation) 단계로 전달된다.
아래 이미지가 1단계와 2단계 과정을 설명하는 전체 이미지이다.
4. 지식 추출(Knowledge Distillation)
이 단계부터는 LLM이 핵심적인 역할을 수행한다.
- 과정
: 2단계에서 얻은 Fine Rerank Airfoil 리스트의 데이터(기하학적, 공기역학적 특징)가 LLM에 입력된다.
이 데이터는 특정 형식의 자연어 프롬프트로 변환되어 LLM에게 전달된다.
이 논문은 LLM이 정량적인 수치 대신 정성적인 분석을 하도록 특별히 설계된 프롬프트를 사용한다.
예시 프롬프트는 다음과 같다.
-
예시 프롬프트: "다음 익형 데이터(A, B, C...)를 분석하여, 익형의 '앞전 반경'이 '양력 계수'에 어떤 영향을 미치는지 설명하시오. '윗면 곡률'이 '항력 계수'와 어떤 관계가 있는가?"
-
LLM의 역할
: LLM은 제공된 데이터를 바탕으로 익형의 기하학적 특징과 공기역학적 성능 간의 정성적인 상관관계 지식을 생성한다. 이는 "앞전 반경이 증가하면 양력 계수가 약간 상승하는 경항이 있다."와 같은 문장으로 표현된다. 이 지식은 단순히 숫자를 나열하는 것이 아니라 현상을 설명해 준다.
따라서 이 과정을 통해 익형 설계에 대한 '해석 가능한' 지식이 생성된다.

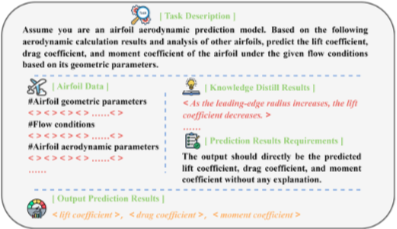
한국어 해석
이 이미지는 '지식 추출(Knowledge Distillation)' 단계에서 사용되는 프롬프트입니다. 대규모 LLM이 익형 데이터를 분석하여 '설명 가능한 지식'을 생성하도록 유도하는 내용이다.
-
Task Description (작업 설명):
역할 부여: "당신은 익형 공기역학 결과 분석 모델입니다."라는 역할을 부여하고 있다.
요청: "아래 공기역학적 계산 결과를 바탕으로, 주어진 유동 조건에서 익형 기하학적 매개변수가 공기역학적 성능 매개변수에 미치는 영향을 분석하세요."라고 요청하고 있다. -
Airfoil Data (익형 데이터):
모델이 분석에 사용할 익형의 기하학적 매개변수, 유동 조건, 공기역학적 매개변수 값이 제공된다.
#Airfoil geometric parameters: 익형의 모양을 나타내는 기하학적 매개변수 값
#Flow conditions: 유동 조건(마하수, 받음각 등)에 대한 정보
#Airfoil aerodynamic parameters: 다른 익형들의 공기역학적 성능 값 -
Knowledge Distill Requirements (지식 추출 요구사항):
핵심: "출력은 익형의 기하학적 매개변수가 변함에 따라 공기역학적 성능 매개변수가 보이는 경향과 패턴에 대한 정성적인 분석이어야 합니다."라고 명시하고 있다. 이는 모델이 숫자 대신 '왜' 그런 결과가 나왔는지를 설명하는 지식을 생성하도록 유도한다. -
Output Knowledge Distill Results (지식 추출 결과):
모델이 최종적으로 생성할 분석 결과의 예시가 표시돼 있다.
예시: "선두부 반경이 증가함에 따라 양력 계수는 감소합니다."와 같은 정성적인 설명이 출력된다.
해당 이미지는 AirfoilRAG 프레임워크에서 LLM이 에어포일의 공기역학적 지식을 추출하는 데 사용되는 프롬프트의 구조를 보여준다.
이 프롬프트는 LLM이 에어포일의 가하학적 특징과 공기역학적 성능 간의 상관관계를 정상적으로 분석하도록 지시한다.
각 구성 요소는 다음과 같다.
-
Task Description (작업 설명)
- LLM에게 "에어포일 공기역학 결과 분석 모델" 역할을 수행하도록 지시한다.
- 제공된 공기역학 계싼 결과를 바탕으로, 주어진 유동 조건(flow conditions) 하에서 에어포일의 기하학적 매개변수 (geometric parameters)가 공기역학적 성능 매개변수(aerodynamic performance parameters)에 미치는 영향을 분석하도록 명시한다.
-
Airfoil Data (에어포일 데이터)
- LLM에게 입력으로 제공되는 실제 데이터의 종류를 보여준다.
- #Airfoil geometric parameters
: 에어포일의 형상을 정의하는 기하학적 매개변수들(예: 앞전 반경(leading edge radius), 상하부 곡률 위치, 두께 등). 이는 Paper의 2.2절에서 설명된 Parsec 매개변수화 방법을 통해 얻은 11가지 물리적 매개변수를 의미한다. - #Flow conditions
: 유동장(flow field)의 상태를 나타내는 조건들 (예: 받음각(Angle of Attack, AoA), 마하 수(Mach number), 레이놀즈 수(Reynolds number)). Paper의 2.2절에서는 AoA, Mach number, Reynolds number를 언급한다. - #Airfoil aerodynamic parameters
: 에어포일의 공기역학적 성능을 나타내는 계수들 (예: 양력 계수(C_LCLC_LCL), 항력 계수(C_DCDC_DCD), 모멘트 계수(C_MCMC_MCM)). 이 값들은 Paper의 2.2절에서 XFOIL 도구를 사용하여 계산한다고 명시되어 있다. - 이러한 데이터는 LLM이 분석할 "문맥(context)" 역할을 한다
-
Knowledge Distill Requirements (지식 증류 요구사항)
- LLM에게 기대하는 출력의 형식과 내용을 정의한다.
- 출력은 에어포일의 기하학적 매개변수와 공기역학적 매개변수 간의 관계에 대한 정석적 분석이어야 함을 강조한다.
- 구체적으로, 기하학적 매개변수가 변함에 따라 공기역학적 성능 매개변수가 어떻게 경향과 패턴(trends and patterns)을 보이는지 설명해야 한다.
- 이는 LLM이 수치적인 예측보다는 "왜" 또는 "어떻게" 성능이 변하는지에 대한 설명을 제공하도록 유도하여 해석 가능성(interpretability)을 높이기 위함이다. Paper의 2.4절에서 LLM의 수치 이해 능력(numerical understanding ability)이 약하기 때문에 정성적 출력으로 제한한다고 명시하고 있다.
-
**Output Knowledge Distill Results (지식 증류 결과 출력)
- 예상되는 출력의 한 가지 예시를 보여준다.
: "<As the leading-edge radius increases, the lift coefficient decreases.>" - 이는 앞전 반경이 증가할 때 양력 계수가 감소하는 경향을 정성적으로 설명한 것이다.
- 예상되는 출력의 한 가지 예시를 보여준다.
이 프롬프트는 AirfoilRAG가 LLM의 강점인 자연어 이해 및 생성 능력을 활용하여 에어포일 설계 지식을 "정성적인 규칙" 형태로 추출하는 핵심적인 부분이다. LLM에 방대한 에어포일 데이터를 제공하고, 그 데이터 내에서 기하학적 변화가 공기역학적 성능에 미치는 영향을 설명하는 지식을 생성하도록 유도한다.
5. 지식 적용 및 평가 (Knowledge Application)
마지막 단계는 LLM이 생성한 지식이 실제로 유용한지 검증하는 과정이다.
- 과정
: 지식 추출 단계에서 얻은 지식을 학습 데이터로 사용해 **소규모 LLM(Small-Parameter LLM)을 미세 조정(fine-tuning)한다. 이는 대규모 LLM의 지식을 소규모 모델에 효율적으로 주입하는 '지식 증류(Knowledge Distillation)' 기법과 유사하다.
예를 들어 소규모 LLM에게 익형 데이터와 함께 "앞전 반경이 양력에 긍정적 영향을 준다"는 지식을 주입하고, 새로운 익형의 양력 계수를 예측하도록 훈련한다.
-
성능 평가
: 미세 조정된 소규모 LLM이 새로운 익형의 공기역학적 계수를 예측하고, 그 예측값과 실제값의 차이(오차)를 MAE와 MAPE 지표로 측정한다. -
결과
: 논문은 이 과정을 통해 예측 오차가 5% 미안므로 나타났음을 보여준다.
이는 AirfoilRAG가 추출한 지식이 실제로 익형의 성능을 예측하는 데 매우 효과적임을 증명하며, 이 지식을 활용하면 데이터만 사용하는 모델보다 성능이 향상됨을 입증한다.
이 이미지는 논문의 '지식 적용 및 평가(Knowledge Application)' 단계에서 사용되는 프롬프트이다. 대규모 언어 모델(LLM)이 추출한 지식을 바탕으로 소규모 LLM이 익형의 성능을 예측하도록 지시하는 내용이다.
-
Task Description (작업 설명):
역할 부여: "당신은 익형 공기역학 예측 모델입니다."라는 역할을 부여하고 있다.
요청: "아래의 공기역학적 계산 결과와 다른 익형들의 분석을 바탕으로, 주어진 유동 조건에서 익형의 기하학적 매개변수를 기반으로 양력, 항력, 모멘트 계수를 예측하세요."라고 지시하고 있다. -
Airfoil Data (익형 데이터):
모델이 예측을 위해 참고할 익형 정보가 담겨 있다.
#Airfoil geometric parameters: 익형의 모양을 나타내는 기하학적 매개변수 값
#Flow conditions: 유동 조건(마하수, 받음각 등)에 대한 정보
#Airfoil aerodynamic parameters: 다른 익형들의 공기역학적 성능 값 -
Knowledge Distill Results (지식 추출 결과):
핵심: "선두부 반경이 증가함에 따라 양력 계수는 감소합니다."와 같이, 대규모 LLM이 추출한 정성적인 지식이 입력되는 부분이다.
이는 소규모 모델에게 익형의 물리적 특성 간의 관계를 가르치는 역할을 한다. -
Prediction Results Requirements (예측 결과 요구사항):
명확한 지시: "출력은 어떠한 설명 없이 예측된 양력, 항력, 모멘트 계수를 직접적으로 나타내야 합니다."라고 명시하고 있다.
이는 모델이 불필요한 설명을 덧붙이는 '환각(hallucination)' 현상을 방지하고 정확한 수치 예측에 집중하도록 유도한다. -
Output Prediction Results (예측 결과 출력):
모델이 최종적으로 예측한 양력, 항력, 모멘트 계수 값이 출력되는 부분이다.
이 이미지는 AirfoilRAG 프레임워크 내에서 에어포일 공기역학적 지식의 유효성을 평가하고 검증하는 데 사용되는 프롬프트의 구조를 보여준다.
특히, 대규모 파라미터 LLM (Large Language Model)이 추출하고 정제한 지식(knowledge distillation)이 소규모 파라미터 LLM에 주입되었을 때, 이 소규모 LLM이 에어포일의 공기역학적 성능을 얼마나 정확하게 예측하는지를 확인하기 위한 입력 형식이다.
이 프롬프트는 다음과 같은 주요 구성 요소로 이루어져 있다.
-
Task Description (작업 설명)
- LLM에게 "에어포일 공기역학 예측 모델"의 역할을 부여하며, 주어진 공기역학 계산 결과와 다른 에어포일들의 분석을 바탕으로 특정 에어포일의 양력 계수(lift coefficient), 항력 계수(drag coefficient), 모멘트 계수(moment coefficient)를 예측하도록 지시한다.
- 이는 에어포일의 기하학적 파라미터와 주어진 유동 조건에 기반한다.
-
Airfoil Data (에어포일 데이터)
- 예측에 필요한 입력 데이터를 제공한다.
- Airfoil geometric parameters (에어포일 기하학적 파라미터): 예측 대상 에어포일의 이산적 및 연속적 기하학적 특징을 포함한다. (예: Rle, Xup, Yup 등)
- Flow conditions (유동 조건): 에어포일이 처한 유체 역학적 환경을 정의하는 파라미터이다. (예: 받음각(AoA), 마하 수(Mach number), 레이놀즈 수(Reynolds number) 등)
- Airfoil aerodynamic parameters (에어포일 공기역학적 파라미터): 검색(retrieval) 단계에서 찾아낸 유사 에어포일들의 양력 계수(C_LCLC_LCL), 항력 계수(C_DCDC_DCD), 모멘트 계수(C_MCMC_MCM) 등의 공기역학적 성능 데이터가 포함된다.
-
Knowledge Distill Results (지식 정제 결과)
- "As the leading-edge radius increases, the lift coefficient decreases."와 같이 대규모 파라미터 LLM이 에어포일 형상과 공기역학적 성능 사이에서 추출한 해석 가능한 지식(interpretable knowledge)을 제공한다.
- 이 지식은 소규모 LLM이 예측을 수행하는 데 있어 추가적인 맥락과 가이드를 제공한다.
-
Prediction Results Requirements (예측 결과 요구사항)
- LLM의 출력 형식에 대한 지침이다.
- 예측된 양력 계수, 항력 계수, 모멘트 계수를 어떠한 추가 설명 없이 직접적으로 출력해야 한다.
-
Output Prediction Results (예측 결과 출력)
- LLM이 생성해야 할 최종 출력 형식의 예시이다.
- 예측된 <lift coefficient>, <drag coefficient>, <moment coefficient> 세 가지 수치 값만 포함된다.
이 프롬프트는 논문의 2.4절 "Airfoil knowledge distillation and evaluation application"에서 설명된 소규모 LLM의 SFT(Supervised Fine-Tuning) 과정에 사용된다.
이 단계에서는 대규모 LLM이 생성한 지식 정제 결과를 바탕으로 소규모 LLM을 미세 조정하고, 에어포일 공기역학적 성능 예측 작업을 통해 지식의 합리성을 검증한다.
