해당 논문은 다음과 같은 출처를 갖습니다.
출처: REFRAG: Rethinking RAG based Decoding
먼저 논문에서 이야기하는 문제점에 대해서 살펴보자.
논문에서 제기하는 기존 RAG의 문제점은 다음과 같다.
서론
1. RAG의 장점과 단점
대규모 언어 모델(LLM)은 검색 증강 생성(RAG)과 같은 애플리케이션에서 외부 지식을 활용하여 답변의 품질을 혁신적으로 향상시켰다. 그러나 이러한 강력한 능력 뒤에는 해결해야 할 중요한 과제가 있다. 바로 '긴 컨텍스트(Long-Context)' 처리의 비효율성이다.
LLM에 길고 방대한 정보를 입력할수록 다음과 같은 문제가 발생한다:
-
높은 지연 시간 (Latency):
특히 첫 번째 토큰을 생성하는 데 걸리는 시간(TTFT, Time-To-First-Token)이 입력 길이에 따라 제곱에 비례하여 증가한다. -
막대한 메모리 소비 (Memory Consumption):
키-값 캐시(KV Cache)가 입력 길이에 비례하여 커지면서 GPU 메모리를 과도하게 사용한다. -
낮은 처리량 (Throughput):
지연 시간과 메모리 문제로 인해 단위 시간당 처리할 수 있는 요청 수가 줄어든다.
이러한 문제들은 LLM 기반 RAG 시스템이 고성능과 낮은 지연 시간을 요구하는 실제 서비스 환경에 적용되는 것을 제약하는 핵심 요인이다. [REFRAG] 논문은 이러한 일반적인 문제점을 RAG의 '고유한 특성'에 주목하여 더욱 심층적으로 분석하고, 그 해결책을 제시한다.
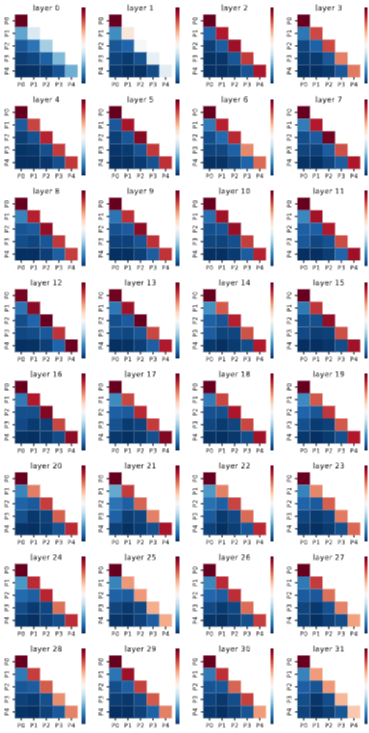
이미지는 LLaMA-2-7B 모델의 32개 레이어(layer 0 ~ layer 31) 각각에서 계산된 어텐션 값의 평균을 시각화한 것이다.
축의 의미 (P0, P1, ...): 여기서 P0, P1, P2, P3, P4는 RAG 시스템이 사용자의 질문에 답변하기 위해 외부 데이터베이스(예: 벡터 DB)에서 검색해 온 5개의 서로 다른 텍스트 문단(passage)을 의미한다
쉽게 말하면 다음 과정과 같다.
- 해당 논문에서는 기존 RAG와 유사하게 방대한 원본 문서들을 벡터 DB에 저장하기 좋은 크기로 나눈다.
- 이 단위를 논문에서는 패시지(Passage)라고 부르며, 실험 설명에서 "각 passage는 200단어 미만을 포함한다"고 명시하고 있다.
- 즉, 벡터 DB에 저장된 하나의 단위 = Passage이다.(이 단계에서는 'passage'가 일반적인 의미의 'chunk'와 같다고 볼 수 있다)
REFRAG의 전체 과정을 설명하면 아래와 같다.
- 이제 사용자가 질문을 하면, RAG 시스템은 이 벡터 DB에서 질문과 가장 관련성 있는 패시지 여러 개를 검색해 오고
- 검색된 것이 패시지가 위 이미지의 P0, P1, P2 등을 의미한다.
- REFRAG는 검색된 P0, P1, P2의 패시지들을 입력으로 받고, 이 패시지들을 경량 인코더로 압축하기 위해 다시 고정된 크기 (k)의 더 작은 단위로 자르는데, 이것을 '청크(Chunk)'라고 부른다
- 예를 들어, 200단어짜리 패시지(P0) 하나를 입력받고 압축률(k)이 32라면, 이 패시지를 32단어짜리 청크 약 6개로 잘라 각각을 압축하는 것이다.
갑자기 위해서 모든 설명을 간단하게 해보았는데, 더 정확하게 살펴보기 위해 다시 천천히 살펴보자.
2. 문제의 핵심: RAG 컨텍스트의 '희소한 어텐션' 패턴
[REFRAG] 논문이 지적하는 가장 근본적인 문제점은 RAG 컨텍스트가 불필요한 계산을 유발하는 독특한 내부 구조를 가지고 있다는 것이다. 이 논문은 LLM이 RAG 컨텍스트를 처리할 때 다음과 같은 현상을 발견했다.
2.1. 시각적 증거: Figure 7을 통한 어텐션 패턴 분석
논문 Figure 7은 LLaMA-2-7B-Chat 모델의 32개의 레이어에서 RAG 컨텍스트 내의 여러 Passage(P0, P1, P2, P3, P4) 간에 얼마나 어텐션(주의)을 주고받는지를 각 레이어별로 시각화한 히트맵이다. 여기서 두 가지 중요한 패턴을 확인할 수 있다.
색상의 의미:
- 강력한 내부 어텐션 (대각선 붉은색):
P0-P0, P1-P1과 같이 대각선에 위치한 칸들은 짙은 붉은색을 띠고 있다. 이는 각 Passage 내부의 토큰들이 서로에게 매우 강하게 어텐션하고 있음을 의미한다.
이는 지극히 당연하며 필수적인 현상이다. 하나의 Passage는 특정 주제나 정보를 담고 있으므로, 그 Passage 안의 단어들은 서로 긴밀하게 연결되어야 LLM이 문맥을 정확하게 이해하고 의미론적 일관성을 유지할 수 있다.
- 극도로 약한 상호 어텐션 (비대각선 파란색):
반면 P0-P1, P1-P2와 같이 비대각선에 위치한 칸들은 대부분 옅은 파란색을 띠고 있다. 이는 서로 다른 Passage들 간의 토큰들이 서로에게 어텐션하는 정도가 매우 약하다는 것을 보여준다. 즉, P0 Passage의 토큰들이 P1 Passage의 토큰들에게는 거의 "주의를 기울이지 않는다"는 의미한다.
원인 분석: 논문은 이러한 현상이 RAG 시스템의 특성 때문이라고 설명한다. 검색된 Passage들은 때때로 다양성 확보나 중복 제거 등의 과정을 거치면서, 실제로는 LLM의 추론 과정에서 서로 간의 의미론적 관련성이 낮은 경우가 많다는 것이다.
이것이 논문의 핵심적인 관찰이다. RAG에서 사용되는 여러 검색 문단들은 서로 내용이 중복되지 않도록 처리되는 경우가 많아, 문단 간 상호작용이 거의 없는 블록-대각선(block-diagonal) 형태의 희소한(sparse) 어텐션 패턴이 나타난다는 것이다.
REFRAG는 바로 이 "불필요한 계산"을 줄여 속도를 높이는 아이디어에서 출발한다.
2.2. 희소한 어텐션 패턴이 야기하는 비효율성
이러한 '희소한(sparse) 어텐션' 패턴은 LLM의 연산 방식과 맞물려 심각한 비효율성을 초래한다.
-
불필요한 (O(L^2)) 계산 낭비:
트랜스포머 모델의 어텐션 메커니즘은 입력 시퀀스 길이 (L)에 대해 (O(L^2))의 계산 복잡도를 가진다. RAG 컨텍스트에서는 여러 Passage가 연결되어 (L)이 매우 커지는데, Figure 7이 보여주듯이 대부분의 (L^2) 계산이 실제로 중요한 상호작용(비대각선)에는 기여하지 않고 낭비된다. LLM은 유용한 정보를 얻지 못하는 비대각선 어텐션 계산에 막대한 자원을 소모하고 있는 것이다. -
RAG 고유의 비효율성:
-
비효율적인 토큰 할당:
RAG 컨텍스트에는 실제로 답변에 거의 기여하지 않는 정보(uninformative passage)가 포함될 수 있다. 모든 토큰에 동일한 메모리와 계산 자원을 할당하는 것은 낭비이다. -
정보의 불필요한 재처리:
검색 단계에서 이미 Passage들이 전처리되고, 쿼리와의 관련성에 대한 정보(벡터화, 재랭킹 등)가 있지만, 디코딩 과정에서는 이러한 정보가 버려지고 LLM이 처음부터 다시 모든 토큰을 처리한다. -
구조화된 희소 어텐션:
Figure 7에서 드러나듯이, Passage 간의 낮은 의미론적 유사성 때문에 대부분의 교차 어텐션이 0에 가깝다. 이는 일반적인 LLM 생성 작업과는 다른 RAG 컨텍스트만의 특징적인 문제이다.
3. 결론: RAG 특화 최적화의 필요성
[REFRAG] 논문은 이러한 분석을 통해, 단순히 LLM의 긴 컨텍스트 문제를 일반적인 방식으로 해결하는 것을 넘어, RAG 시스템의 고유한 컨텍스트 구조와 그로 인한 비효율성에 특화된 최적화 전략이 필요하다고 주장한다. Figure 7은 이러한 주장의 핵심적인 근거이며, [REFRAG]가 컨텍스트를 압축하고, 중요도를 감지하며, 필요할 때만 확장하는 새로운 디코딩 프레임워크를 제안하게 된 배경이 된다. 이러한 비효율성을 해결함으로써 RAG 시스템의 지연 시간과 메모리 문제를 획기적으로 개선할 수 있는 길이 열리는 것이다.
그럼 논문에서 말하는 문제점에 대해서 살펴봤으니 이제 REFRAG가 무엇인지에 대해서 정확히 살펴보자.
본론
대규모 언어 모델(LLM)이 검색 증강 생성(RAG)과 같은 애플리케이션에서 방대한 외부 지식을 활용하여 탁월한 성능을 보이는 것은 분명하다. 하지만 이러한 과정에서 발생하는 긴 컨텍스트 입력은 시스템 지연 시간과 막대한 메모리 소모를 야기하며, 이는 지식 풍부화와 시스템 효율성 사이의 근본적인 트레이드오프를 만들어낸다. REFRAG는 이러한 RAG 시스템의 고유한 문제점을 해결하기 위해 제안된 효율적인 디코딩 프레임워크이다.
1. 기존 RAG의 한계점
기존의 일반적인 RAG 시스템은 사용자 질문에 대해 임베딩 모델을 거쳐 유사한 문서를 벡터 데이터베이스(Vector DB)에서 K개 찾아낸다. 그리고 이렇게 검색된 K개의 문서 원본 내용과 사용자 질문을 LLM의 입력 프롬프트로 함께 넣어 응답을 생성한다. 이 과정에서 다음과 같은 비효율성이 발생한다.
-
긴 프롬프트 길이: 검색된 다수의 문서를 LLM에 통째로 입력하게 되면 프롬프트 길이가 매우 길어진다. 이는 LLM의 추론 시 높은 지연 시간(특히 Time-To-First-Token, TTFT)을 유발한다.
-
막대한 메모리 소모: 긴 프롬프트는 Key-Value (KV) 캐시를 위해 많은 메모리를 필요로 하여 LLM의 처리량을 저하시킨다.
-
정보 비효율성: 검색된 문서 K개에 담긴 내용 중 실제로 답변 생성에 필요한 핵심 정보는 극히 일부인 경우가 많다. 이 때문에 문서 전체를 입력하는 것은 불필요한 연산 낭비를 초래한다.
REFRAG는 이러한 문제를 인식하고, RAG 컨텍스트의 희소성(sparsity)과 특이한 주의(attention) 패턴을 활용하여 대부분의 불필요한 연산을 제거하고자 한다.
2. REFRAG의 핵심 아키텍처 및 작동 원리
REFRAG는 크게 세 가지 단계를 통해 RAG 시스템의 효율성을 극대화한다.
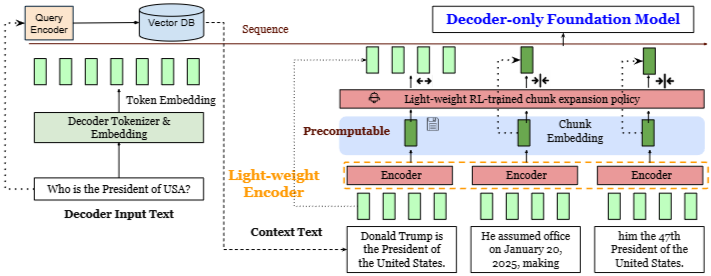
[단계 1] 쿼리 처리 및 컨텍스트 검색
이 단계는 기존 RAG와 동일하다. 사용자의 질문(쿼리)은 Query Encoder를 통해 임베딩되고, 이 임베딩을 이용해 Vector DB에서 쿼리와 관련성이 높은 문서들을 K개 검색한다. 이 문서들은 하나로 합쳐져서 1개의 Context Text가 된다.
이때
사용자의 질문은 벡터 DB를 검색하기 위한 Query Encoder 과정
최종 입력으로 들어가기 위한 Decoder Tokenizer & Enbedding 과정
2가지로 나뉘어진다.
[단계 2] 컨텍스트 청크 분할 및 압축 (Light-weight Encoder)
청크 분할:
검색된 여러 문서가 합쳐진 Context Text는 각각 고정된 길이의 작은 단위인 청크(Chunk)로 나뉜다. 예를 들어, 하나의 검색된 긴 문서가 여러 개의 청크로 쪼개진다.
위 이미지에서는 하나의 Context Text가 3개의 청크로 쪼개진 것을 확인할 수 있다.압축 과정:
각 청크는 Light-weight Encoder에 입력되기 위해서 토큰화가 진행된다. 위 이미지에서는 하나의 청크가 4개의 토큰으로 쪼개졌고, 쪼개진 토큰인 Light-weight Encoder의 입력으로 들어갔다. 이 인코더는 LLaMA와 같은 거대 LLM보다 훨씬 작은 모델(예: RoBERTa)이다. Light-weight Encoder는 각 청크에 포함된 모든 토큰의 의미론적 정보를 통합하고 응축하여 하나의 고정 길이 벡터, 즉 청크 임베딩(Chunk Embedding)으로 변환한다.'압축'의 의미:
경량 인코더의 압축 방식
경량 인코더(논문에서는 RoBERTa와 같은 모델을 예로 듭니다 )는 텍스트를 요약 문장으로 만드는 대신, 다음과 같은 과정을 통해 의미를 압축한 '청크 임베딩'을 생성한다.
입력 (Input): 먼저, 하나의 청크를 구성하는 전체 토큰 시퀀스(예: 256개의 토큰)를 입력으로 받는다.
문맥 이해 (Contextualization): 인코더 내의 여러 레이어와 셀프 어텐션(Self-Attention) 메커니즘을 통해 청크 내 모든 단어 간의 관계를 파악한다. 예를 들어, "미국", "대통령", "트럼프"라는 단어들이 서로 어떻게 연관되어 있는지 종합적으로 이해하여 문맥적 의미를 파악한다.
정보 집약 (Aggregation/Pooling): 청크 내 모든 토큰의 문맥적 의미를 파악한 후, 이 정보들을 하나의 대표 벡터로 응축시킨다. 이는 주로 다음과 같은 방법으로 이루어진다.
특수 토큰 활용: 문장 맨 앞에 [CLS]와 같은 특수 토큰을 추가하고, 모델이 전체 문장을 읽은 후 이 토큰에 담긴 최종 결과 값을 청크 전체의 대표 값으로 사용한다.
평균 풀링 (Mean Pooling): 청크 내 모든 토큰이 가진 각각의 최종 결과 벡터들을 모두 더한 후 평균을 내어 하나의 대표 벡터를 만든다.
출력 (Output): 이 집약 과정을 거쳐 나온 최종 결과물인 단 하나의 벡터가 바로 '압축된 청크 임베딩'이다. 이 벡터 안에는 원본 청크(256개 토큰)의 핵심적인 의미 정보가 수학적으로 농축되어 있다.
효과:
이 과정을 통해 Decoder-only Foundation Model이 처리해야 할 컨텍스트의 입력 시퀀스 길이가 획기적으로 줄어든다. 예를 들어, 청크 하나가 16개 토큰으로 구성되고 이를 1개의 청크 임베딩으로 압축하면, 시퀀스 길이가 16배 감소하는 효과를 얻는다.Precomputable: 이렇게 생성된 청크 임베딩은 미리 계산하여 저장해둘 수 있으므로, 여러 추론 요청에 대해 재사용이 가능하여 효율성을 더욱 높인다.
[단계 3] 선택적 청크 확장 정책 (Light-weight RL-trained chunk expansion policy)
필요성:
모든 청크를 압축된 형태로만 디코더에 제공할 경우, 정보 손실로 인해 답변의 품질이 저하될 우려가 있다. REFRAG는 이를 방지하기 위해 Light-weight RL-trained chunk expansion policy를 도입한다.모델 특성:
이 정책은 강화 학습(Reinforcement Learning, RL)으로 훈련된 경량 모델이다.역할:
이 정책의 역할은 압축된 청크 임베딩들 중에서 LLM의 답변 생성에 특히 중요하다고 판단되는 일부 청크에 대해, 압축된 형태(하나의 벡터) 대신 해당 청크의 원본 토큰 임베딩 시퀀스를 Decoder-only Foundation Model에 제공할지 말지 '선택'하는 것이다.작동 방식:
이 정책은 이미 압축된 임베딩에서 원본 토큰을 '복원'하거나 '추출'하는 것이 아니다. 대신, 각 청크에 대해 압축된 청크 임베딩과 원본 청크 두 가지 형태의 정보가 미리 준비되어 있으며, RL 정책은 이 중 어떤 형태를 Decoder-only Foundation Model에 보낼지 '선택'하는 방식으로 작동한다.조금 더 기술적으로 설명하면 다음과 같다.
두 가지 경로(Path)의 정보 준비:
RAG를 통해 검색된 패시지들을 청크 단위로 자른 뒤, 시스템은 각 청크에 대해 두 가지 형태의 표현(representation)을 모두 준비한다.
경로 A (압축 경로): 청크를 경량 인코더에 통과시켜 얻은 단일 청크 임베딩 벡터.
경로 B (원본 경로): 청크를 구성하는 원본 토큰들의 임베딩 시퀀스. (예: 32개 토큰으로 구성된 32개의 토큰 임베딩 벡터들)
RL 정책의 역할: '스위치(Switch)'
RL 정책은 일종의 '스위치' 또는 '교통 정리 요원' 역할을 한다. 각 청크에 대해 "경로 A의 정보를 보낼 것인가, 아니면 경로 B의 정보를 보낼 것인가?"를 결정한다.중요하지 않다고 판단하면 → 경로 A를 선택하여 단일 청크 임베딩을 디코더로 보낸다. (속도 향상)
매우 중요하다고 판단하면 → 경로 B를 선택하여 원본 토큰 임베딩 시퀀스 전체를 디코더로 보낸다. (정보 손실 방지)
학습 근거:
RL 모델은 next-paragraph prediction perplexity의 음수값(-Perplexity)을 보상(reward)으로 삼아 학습된다. 즉, 정책의 선택이 Decoder-only Foundation Model의 다음 토큰 예측 정확도(낮은 perplexity)를 높이면 높은 보상을 받아, 중요한 정보를 효과적으로 선별하는 방법을 스스로 학습한다. 이를 통해 성능 손실 없이 대부분의 청크를 압축된 상태로 유지하면서, 답변 생성에 필수적인 정보는 원본 형태로 제공할 수 있다.
[단계 4] Decoder-only Foundation Model의 최종 처리
Decoder-only Foundation Model (예: LLaMA)은 REFRAG에 의해 구성된 혼합된 입력 시퀀스를 입력받는다. 이 입력 시퀀스는 다음 세 가지 정보의 조합으로 이루어진다.
- 사용자 질문의 토큰 임베딩
- Light-weight RL-trained chunk expansion policy에 의해 압축된 형태로 선택된 청크들의 임베딩 (고정 길이 벡터)
- Light-weight RL-trained chunk expansion policy에 의해 원본 토큰 형태로 확장된 청크들의 임베딩 시퀀스
이 LLM은 이러한 혼합된 컨텍스트를 바탕으로 사용자의 질문에 대한 최종 답변을 직접 생성한다.
3. REFRAG의 주요 장점
REFRAG는 이러한 혁신적인 아키텍처를 통해 RAG 기반 애플리케이션의 LLM 추론 효율성을 획기적으로 개선한다.
- 획기적인 TTFT 가속화:
컨텍스트 입력 시퀀스 길이의 대폭 감소는 Decoder-only Foundation Model의 초기 연산량(어텐션 메커니즘)을 줄여, 첫 번째 토큰을 생성하는 시간(TTFT)을 최대 30.85배까지 단축한다. 이는 기존 최첨단 방법인 CEPE Yen et al., 2024 대비 3.75배 빠른 속도이다.
- 메모리 사용량 감소:
입력 시퀀스 길이가 줄어들면서 KV 캐시 크기도 감소하여 메모리 효율성을 크게 향상시킨다.
- 성능 유지 및 향상:
정보 손실을 최소화하는 압축 방식과 RL-trained chunk expansion policy를 통한 중요 청크의 선택적 확장은 퍼플렉서티(perplexity)나 다운스트림 태스크의 정확도 손실 없이 우수한 성능을 유지한다. 오히려 확장된 컨텍스트 윈도우를 활용해 일부 애플리케이션에서는 정확도를 향상시키기도 한다.
- 다양한 RAG 애플리케이션 지원:
기존 방법론들이 주로 접두사(prefix) 컨텍스트에 제한되어 인과적 구조를 방해할 수 있었던 것과 달리, REFRAG는 컨텍스트의 어느 위치에서든 유연한 압축 및 확장이 가능하다. 이는 다중 턴 대화, 긴 문서 요약 등 다양한 RAG 기반 시나리오에 효과적으로 적용될 수 있음을 의미한다.
REFRAG는 RAG 시스템의 고유한 특성을 면밀히 분석하고, 이를 바탕으로 LLM 추론의 효율성을 극대화하는 실용적이고 확장 가능한 솔루션을 제공한다. 이는 지연 시간에 민감한 지식 집약적 애플리케이션에 LLM을 배포하는 새로운 가능성을 열어줄 것이다.
방법론
REFRAG는 RAG(Retrieval-Augmented Generation) 시스템에서 대규모 언어 모델(LLM)의 효율성과 성능을 극대화하기 위한 혁신적인 방법론을 제시한다.
이 방법론은 크게 연속 사전 학습(CPT), 강화 학습(RL) 기반의 선택적 압축, 그리고 지도 미세 조정(SFT)이라는 세 가지 축으로 구성되며, 기존 연구인 CEPE의 한계를 극복하는 데 집중한다.
1. 연속 사전 학습 (CPT)을 통한 인코더-디코더 정렬
REFRAG는 경량 인코더 모델과 디코더 기반 LLM의 협업을 통해 동작한다. 여기서 가장 중요한 초기 단계는 인코더가 생성하는 압축된 컨텍스트 정보를 디코더가 효과적으로 이해하고 활용할 수 있도록 두 모델을 '정렬'하는 과정이다. 이를 위해 REFRAG는 CPT(Continual Pre-training)를 활용한다.
-
CPT의 역할:
CPT는 이미 사전 학습된 LLM을 특정 목표나 데이터 형식에 맞게 추가 학습시키는 과정이다.
REFRAG에서는 인코더와 디코더가 압축된 컨텍스트 임베딩을 통해 정보를 주고받는 방식을 학습하도록 돕는다. -
Next Paragraph Prediction 태스크:
논문은 CPT를 위해 'Next Paragraph Prediction' 태스크를 사용한다. 이는 전체 입력 토큰 (T) 중 (s)개의 컨텍스트 토큰((x{1:s}))을 인코더를 통해 압축된 '청크 임베딩(chunk embeddings)'으로 변환한 후, 이 임베딩과 질문 토큰을 디코더에 입력하여 다음 (o)개의 출력 토큰((x{s+1:s+o}), 즉 다음 문단)을 예측하도록 학습하는 방식이다. -
정렬 원리:
이 태스크를 통해 디코더는 압축된 청크 임베딩이 원본 컨텍스트의 핵심 정보를 효과적으로 담고 있음을 인식하고, 이를 기반으로 다음 내용을 예측하는 능력을 기른다. 동시에 인코더 또한 디코더가 유용하게 사용할 수 있도록 정보 손실을 최소화하며 청크를 압축하는 방법을 학습하게 된다. -
재구성 태스크(Reconstruction task):
CPT의 성공을 위해 REFRAG는 재구성 태스크를 함께 사용한다. 이는 인코더가 (x{1:s})를 입력받아 압축하고, 디코더가 이 압축된 임베딩을 이용해 (x{1:s})를 다시 재구성하도록 학습하는 과정이다.
이를 통해 인코더와 프로젝션 레이어는 최소한의 정보 손실로 토큰을 압축하고, 이를 디코더의 토큰 공간으로 효과적으로 매핑하는 법을 배우게 된다.
이는 모델이 매개변수 기억(parametric memory)보다는 컨텍스트 기억(context memory)에 의존하도록 유도한다. -
커리큘럼 학습(Curriculum learning):
재구성 태스크는 청크 길이가 길어질수록 매우 복잡해진다. REFRAG는 이 최적화 문제를 해결하기 위해 커리큘럼 학습을 적용한다. 이는 쉬운 태스크(예: 단일 청크 재구성)부터 시작하여 점진적으로 어려운 태스크(예: 여러 청크 재구성)의 비중을 늘려가는 방식으로, 모델이 복잡한 기술을 효과적으로 습득하도록 돕는다.
조금 더 쉽게 위 과정을 정리해보자
- 연속 사전 학습 (CPT): 새로운 언어 가르치지
CPT의 목표는 똑똑한 LLM(디코더)에게, 경량 인코더가 만든 "압축 요약본(청크 임베딩)'이라는 새로운 언어를 가르치는 것과 같다.
재구성 테스트(Reconstruction task): 단어 시험 보기
인코더에게 "사과"라는 단어를 압축해서 보여주게 하고, 디코더에게 "이 압축된 정보를 보고 '사과'라고 다시 말해봐"라고 시키는 과정이다.
이 과정을 통해 디코더는 압축된 정보가 원래 어떤 단어였는지 이해하는 법을 배우고, 인코더는 디코더가 잘 알아맞힐 수 있도록 압축하는 법을 배운다.
이것이 '정렬' 과정이다.
커리큘럽 학습(Curriculum Learning): 쉬운 것부터 진행
- 처음부터 긴 문서를 외우게 할 수는 없기 때문에 짧고 쉬운 단어부터 시작한다.
- "사과" 같은 단어 하나부터 시작해서, "나는 사과를 먹는다"같은 짧은 문장, 그리고 점차 긴 문단 순서로 난이도를 높여가며 학습을 진행한다.
다음 문단 예측(Next Paragraph Prediction): 뒤 이야기 예측하기
- 이제 단어와 문장을 학습했기 때문에, 이를 기반으로 추론 방법을 가르친다
- 소설의 앞부분을 "압축 요약본"으로 보여준 뒤, "이 요약본을 보고 뒷내용이 어떻게 전개될지 써봐"라고 시킨다
- 이 훈련을 통해 디코더는 압축된 정보만 보고도 전체 맥락을 파악하고 다음 내용을 추론하는 능력을 갖추게 된다.
2. REFRAG: CEPE를 뛰어넘는 RAG 최적화
REFRAG는 기존의 장문맥 LLM 효율화 연구인 CEPE(Yen et al., 2024)의 한계를 명확히 개선한다.
- CEPE의 한계:
CEPE는 크로스-어텐션 메커니즘을 통해 KV 캐시와 어텐션 계산량을 줄이지만, 프리픽스 컨텍스트(prefix context) 애플리케이션에만 제한적이다.
이는 컨텍스트의 인과적 구조를 방해하여 멀티턴 RAG나 장문서 요약 등 다양한 시나리오에 적용하기 어렵게 한다. 또한, 토큰 압축을 활용하지 않아 디코딩 지연 시간 개선이 제한적일 수 있다.
- REFRAG의 혁신적 개선점:
압축된 청크 임베딩의 활용: REFRAG는 검색된 문맥의 원시 토큰 대신, 사전에 계산된 압축 청크 임베딩을 디코더에 직접 입력한다.
이는 디코더의 입력 길이를 획기적으로 줄여 토큰 할당 효율성을 높인다.
검색 단계에서 이미 계산된 임베딩을 재사용하여 중복 계산을 없앤다.
어텐션 계산 복잡도가 토큰 수가 아닌 청크 수((L))에 비례하는 (\mathcal{O}(L^2))로 감소하여 매우 효율적이다.
-
획기적인 TTFT 가속화:
REFRAG는 CEPE 대비 3.75배 빠른, 최대 30.85배의 TTFT 가속화를 달성한다. 이는 첫 토큰 생성 시간을 대폭 단축하여 사용자 경험을 크게 향상시킨다. -
대규모 컨텍스트 확장:
모델의 컨텍스트 처리 능력을 최대 16배까지 확장할 수 있어, 훨씬 많은 정보를 동시에 처리하며 복잡한 태스크를 수행할 수 있다. -
다양한 애플리케이션 지원:
REFRAG는 '압축된 청크 임베딩'을 프롬프트 내 임의의 위치에 삽입할 수 있으며, 디코더의 자기회귀적 특성을 보존한다. 이로 인해 RAG, 멀티턴 대화, 에이전트 애플리케이션, 장문서 요약 등 CEPE가 지원하기 어려웠던 광범위한 RAG 기반 태스크에 유연하게 적용할 수 있다. -
기존 LLM 아키텍처 변경 불필요:
REFRAG는 기존 LLaMA 모델 등의 아키텍처를 수정하거나 새로운 디코더 매개변수를 추가할 필요 없이 이러한 성능 향상을 이룬다.
3. 강화 학습 (RL) 기반의 선택적 압축
REFRAG의 또 다른 핵심은 선택적 압축(Selective Compression)이다. 이는 모든 컨텍스트 청크를 압축하는 것이 아니라, 태스크에 대한 중요도에 따라 압축 수준을 동적으로 조절하는 방식이다.
-
선택적 압축의 개념:
질문에 답변하는 데 모든 컨텍스트 정보가 동일하게 중요하지는 않다. REFRAG는 덜 중요한 컨텍스트 청크는 압축된 임베딩 형태로 디코더에 제공하고, 핵심적인 정보를 담고 있는 청크는 원래의 토큰 형태로 '확장(expand)'하여 제공한다. 이를 통해 정보 손실을 최소화하면서도 효율성을 극대화한다. -
강화 학습(RL)의 필요성:
어떤 청크를 압축하고 어떤 청크를 확장할지 결정하는 문제는 가능한 조합이 매우 많고 이산적(discrete)이므로, 일반적인 미분 기반 최적화로는 풀기 어렵다. 강화 학습(RL)은 이러한 '순차적 의사 결정 문제'에 특화된 접근 방식이다. -
RL 정책 학습:
REFRAG는 RL을 사용하여 '정책 네트워크((\pi_\theta))'를 훈련한다.
입력: 정책 네트워크는 모든 청크의 임베딩을 입력으로 받는다. -
결정:
이 네트워크는 어떤 청크들을 원래의 토큰 형태로 유지할지((T')개의 청크를 선택) 결정하는 '정책'을 학습한다. -
보상:
정책 학습을 위한 보상으로 'Next-Paragraph Prediction Perplexity'의 음의 값(-Perplexity)을 사용한다. 즉, 디코더가 다음 문단을 더 정확하게 예측할 수 있도록(Perplexity를 낮추도록) 청크를 선택하는 것이 좋은 정책으로 학습된다. 이 과정을 통해 REFRAG는 최적의 압축-확장 균형을 찾아내어 유연하고 효율적인 컨텍스트 처리를 가능하게 한다.
4. 지도 미세 조정 (SFT)을 통한 하위 태스크 적응
CPT와 RL 기반 선택적 압축을 통해 REFRAG 모델은 효율적인 컨텍스트 처리 능력을 갖추게 되지만, 실제 특정 RAG 애플리케이션에서 최상의 성능을 내기 위해서는 추가적인 조정이 필요하다. 이때 지도 미세 조정(SFT, Supervised Fine-tuning)을 적용한다.
-
SFT의 목적:
CPT가 일반적인 컨텍스트 이해 능력을 높이는 데 초점을 맞춘다면, SFT는 모델이 특정 하위 태스크(downstream tasks)의 고유한 요구사항과 목표에 맞춰 응답을 생성하는 방법을 학습하도록 돕는다. -
적용 시나리오:
REFRAG는 RAG 기반 질문 답변, 멀티턴 대화, 장문서 요약과 같은 다양한 애플리케이션을 위해 별도의 SFT를 수행한다. 각 태스크의 레이블링된 데이터로 모델을 미세 조정함으로써, REFRAG는 CPT로 확보한 효율성을 바탕으로 실제 환경에서 요구되는 정확도와 품질을 달성한다.
이러한 다단계 방법론을 통해 REFRAG는 RAG 시스템의 근본적인 한계인 지연 시간과 메모리 소비 문제를 해결하며, LLM 기반의 지식 집약적 애플리케이션의 실용성과 확장성을 크게 향상시킨다.
평가
학습 및 평가 데이터셋 (Training and Evaluation Datasets)
-
학습 데이터셋:
LLM 사전 학습을 위한 오픈 소스 데이터셋인 Slimpajama (Arxiv, Book 도메인)에서 20B 토큰의 데이터를 샘플링하여 사용했다. -
평가 데이터셋:
Slimpajama의 Book 및 ArXiv 도메인 외에, PG19 및 Proof-pile 데이터셋을 사용하여 모델의 일반화(generalization) 성능을 평가했다.
기준 모델 (Baselines)
공정한 비교를 위해 LLaMA-2-7B를 기반으로 하는 다양한 기준 모델들을 사용했다.
-
LLaMA-No Context:
컨텍스트 없이 출력 토큰만으로 평가하는 모델이다. -
LLaMA-Full Context:
전체 시퀀스(컨텍스트 + 출력)를 입력으로 사용하여 평가하는 모델로, 이론적인 성능 상한선(upper bound)을 보여준다. -
CEPE (Cross-Attention to Prefix Encoding):
기존의 메모리 효율적인 장문맥 모델이다.
LLaMA-32K: 32K 컨텍스트 길이로 파인튜닝된 LLaMA-2-7B 모델이다. -
REPLUG:
검색 증강 언어 모델링(Retrieval-augmented language modeling) 프레임워크이다. -
LLaMAK:
REFRAG와 동일한 수의 컨텍스트 토큰을 사용하도록 마지막 K개의 토큰만 전달하여 평가한다. -
REFRAGk:
압축률이 k인 REFRAG 모델을 의미하며, REFRAGRL은 RL 기반 선택적 압축을 사용한 모델을 지칭한다.
주요 실험 결과
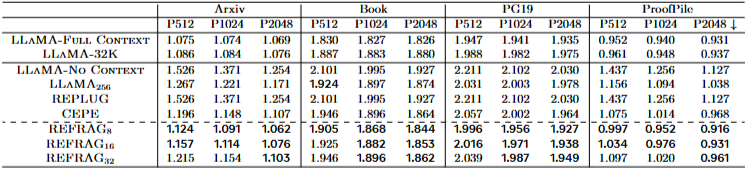
Perplexity 개선:
REFRAG8 및 REFRAG16은 대부분의 평가 설정에서 다른 기준 모델(CEPE, REPLUG 등)보다 일관되게 우수한 Perplexity 성능을 보였다 (Table 1).
특히, REFRAG8은 LLaMA256(동일한 토큰 수)보다 성능이 좋았는데, 이는 압축된 청크 임베딩의 효율성을 보여준다.
REFRAG16은 CEPE 대비 평균 9.3%의 Perplexity 개선을 달성했다.

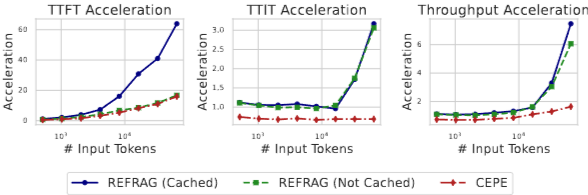
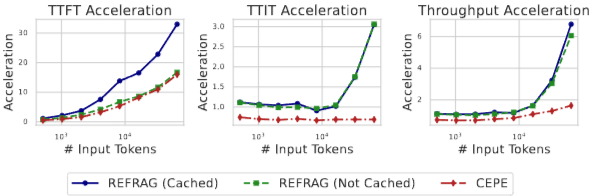
TTFT (Time-To-First-Token) 가속:
REFRAG16은 LLaMA 대비 16.53배의 TTFT 가속을, CEPE 대비 2.01배의 가속을 달성했다.
REFRAG32는 LLaMA 대비 30.85배, CEPE 대비 3.75배의 획기적인 TTFT 가속을 달성하면서도 CEPE와 유사한 Perplexity를 유지했다 (Figure 8, Table 2).
컨텍스트 확장:
REFRAG는 LLM의 컨텍스트 크기를 16배 확장할 수 있음을 보여주었습니다. 이는 기존 LLaMA-2-7B의 4k 컨텍스트 윈도우 한계를 뛰어넘는 것이다.
TTIT (Time-To-Iterative-Token) 및 Throughput:
REFRAG는 장문맥 시나리오에서 TTIT를 3배 가속하고, LLaMA 대비 최대 6.78배, CEPE 대비 6.06배의 Throughput 가속을 달성했다 (Figure 2).
RL(Reinforcement Learning) 기반 선택적 압축의 이점

Figure 3은 RL 기반 선택적 압축(RL-based selective compression) 정책이 휴리스틱 기반(perplexity-desc, perplexity-asc) 또는 무작위(random) 선택보다 Perplexity 측면에서 일관되게 우수한 성능을 보임을 보여준다.
이는 RL 정책이 중요 컨텍스트 청크를 선택적으로 확장하여 성능 저하를 최소화하면서도 압축 효율성을 높이는 데 효과적임을 입증한다.
Ablation Study (요소 연구)
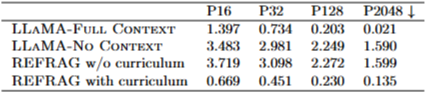
커리큘럼 학습(Curriculum learning)의 중요성:
재구성(reconstruction) 태스크의 성공을 위해 커리큘럼 학습이 필수적임을 보여주었다 (Table 11). 즉, 쉬운 태스크부터 점진적으로 어려운 태스크로 난이도를 높이는 학습 방식이 효과적이었다.
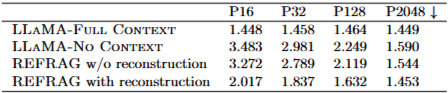
재구성 태스크의 중요성:
사전 학습 단계에서 재구성 태스크로 모델을 초기화하는 것이 지속적인 사전 학습(continual pre-training)의 성공에 중요함을 입증했다 (Table 12).
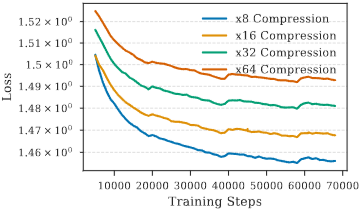
다양한 압축률:
압축률이 증가할수록 성능 저하가 발생하지만, REFRAG32까지는 경쟁력 있는 성능을 유지하며, 압축률 64는 너무 공격적이어서 성능이 크게 감소함을 보여주었다 (Figure 10).
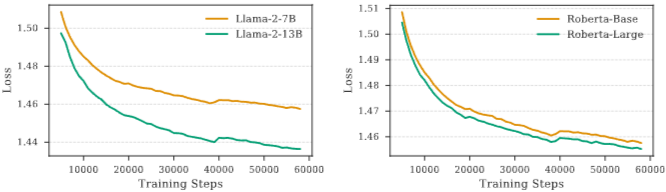
인코더-디코더 모델 조합:
디코더 모델의 파라미터 수 증가(예: LLaMA-2-7B에서 LLaMA-2-13B)는 손실 감소에 큰 영향을 미쳤지만, 인코더 모델의 크기 증가(예: RoBERTa-Base에서 RoBERTa-Large)는 상대적으로 미미한 개선만을 보였다 (Figure 11, Figure 12).
결론
이 논문은 RAG(Retrieval-Augmented Generation) 애플리케이션을 위해 특별히 고안된, 새롭고 효율적인 디코딩 프레임워크인 REFRAG를 소개하고 있다. REFRAG의 핵심은 RAG 컨텍스트에 내재된 희소성(sparsity)과 특유의 블록-대각선(block-diagonal) 어텐션 패턴을 효과적으로 활용하는 데 있다. 이를 위해 REFRAG는 컨텍스트 표현을 압축하고, 그 중요도를 감지하며, 필요에 따라 확장하는 고유한 메커니즘을 사용하고 있다.
이러한 접근 방식을 통해 REFRAG는 LLM 디코딩 과정에서 발생하는 메모리 사용량과 추론 지연 시간, 특히 첫 번째 토큰을 생성하는 데 걸리는 시간인 TTFT(Time-To-First-Token)를 획기적으로 줄이는 데 성공했다. 다양한 장문맥 애플리케이션에 걸쳐 수행된 광범위한 실험에서, REFRAG는 RAG, 멀티턴 대화, 장문서 요약과 같은 작업에서 뛰어난 성능을 입증하였다. 특히, 퍼플렉시티(perplexity)나 다운스트림(downstream) 정확도 손실 없이 TTFT를 최대 30.85배 가속화하는 놀라운 결과를 보여주었는데, 이는 이전의 최첨단(state-of-the-art) 방법과 비교했을 때 3.75배 향상된 수치이다.
이러한 결과는 RAG 기반 시스템을 다룰 때 일반적인 LLM 추론 방식과는 다른, 보다 특화된 접근 방식이 중요하다는 점을 명확히 보여주는 것이다. 또한, REFRAG는 효율적인 대규모 컨텍스트 LLM 추론을 위한 새로운 방향을 제시하고 있는 것이다. 궁극적으로, REFRAG는 지연 시간에 민감하고 방대한 지식을 활용해야 하는 LLM 애플리케이션을 실제로 배포하는 데 있어 매우 실용적이고 확장 가능한 해결책을 제공하고 있는 것이다.
