해당 논문은 다음과 같은 출처를 갖습니다.
출처: RAPTOR
논문 제목:
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
RAPTOR: 트리로 구성된 검색을 위한 재귀적 추상 처리
0. 한눈에 보기
- 문제의식: 기존 RAG는 조각만 가져오기 때문에 전체 문서의 맥락과 계층 구조를 놓치기 쉽다.
- 핵심 아이디어: 문서를 SBERT로 임베딩 --> GMM+UMAP로 의미적으로 묶음 --> 각 묶음을 LLM 요약 --> 다시 임베딩해 트리를 하향식이 아니라 상향식으로 구성, 질의 시 트리 전체에서 적절한 추상화 레벨 노드를 검색
- 효율성/효과: 검색 품질 향상, 장문, 멀티홉 질의에 강함, 평균 약 72% 요약 압축률로 토큰 비용 절감
간단 요약: 긴 문서에 대해서 효율적으로 RAG를 진행하는 방식에 대한 내용
1. 배경 및 문제정의
1.1 RAG는 왜 필요한가?
- 거대 언어모델인 LLM은 파라미터 내 지식이 구버전이거나 특정 도메인 지식을 모두 포괄하기 어렵다. RAG는 이러한 문제를 외부 데이터를 가져와 질의 시 컨텍스트로 주입해 문제를 해결하도록 한다.
1.2 기존 RAG의 한계
- 유사도 검사를 통해 일부 관련 문서만 추출해오기 때문에 원본 전체 문서에 대한 이해를 제한하게 된다.
- 대부분 연속 청킹 후 상위 k개만 가져오는 방식으로 RAG가 활용되기 때문에 장문 내 원거리 의존성이나 계층적 주제 구조 포작이 어렵다.
- 긴 컨텍스트를 통째로 넣는 것은 성능 저하 및 비용 증가의 위험성이 있다.
예를 들어서 설명하면 "신데렐라는 어떻게 행복한 결말을 맞이했을까?" 라는 질문에 대해 RAG는 글의 처음부터 끝까지 이해하고 답변하는 것이 아니고, 상위 k개로 검색된 짧은 연속 텍스트로 답변하기 때문에 질문에 답변할 만큼 충분한 맥락이 포함되어 있지 않음
1.3 RAPTOR의 목표
- 계층적 요약 트리를 만들어, 동일 문서 내 주제-하위주제-세부사항을 여러 해상도로 보존
- 질의마다 적정 추상화 레벨의 노드를 가져와 정확성과 효율성을 동시에 달성
1.4 RAPTOR란?
-
텍스트 청크를 재귀적으로 임베딩, 클러스터링, 요약하는 새로운 접근 방식으로 하단에서 상단으로 요약 수준이 다른 트리를 구성한다.
-
추론에 RAPTOR 모델은 이 트리에서 검색하여 다양한 추상화 수준에서 긴 문서의 정보를 통합한다.
2. 방법론
2.1 전체 파이프라인 개요
- 청킹: 문서를 짧게 약 100 토큰 단위로 구분(문장 중간 절단은 피하기)
- 임베딩: SBERT로 벡터화 --> 리프 노드
- 클러스터링: UMAP로 차원 축소 후 GMM으로 의미적 군짐, BIC로 최적 군집 수 결정, EM으로 파라미터 추정
- 요약: 각 클러스터 텍스터를 GPT-3.5-turbo로 요약 --> 부모 노드 텍스트가 됨
- 재임베딩 & 반복: 요약문을 다시 임베딩해 상위 레벨을 반복 생성, 더 이상 군집이 의미 없을 때까지 상향식으로 트리 형성
- 스케일링: 빌드 시간, 토큰 소모가 선형에 가깝게 증가하도록 설계
2.2 청킹
- 문장 경계를 최대한 보존하여 문장이 도중에 끊기거나 의미가 파손되는 것을 방지
2.3 임베딩
- SBERT 기반 임베딩을 모든 노드(리드, 요약 노드)에 부여하여 단일 임베딩 공간에서 유사도 계산 가능
2.4 클러스터링(UMAP + GMM)
- UMAP: 고차원 임베딩의 지역/전역 구조 균형을 n_neighbors로 조절, 전역 -> 지역 2단계로 군집해 광범위한 주제부터 세부 주제까지 포착
- GMM(소프트 클러스터링): 한 노드가 여러 클러스터에 부분 소속될 수 있어, 다주제 조각의 정보 손실을 줄임
- BIC 선택: 모델 복잡도-적합도 균형으로 군집 수 자동 결정, 이후 EM으로 평균, 공분산, 가중치 추정
- 토큰 초과 방지: 요약 모델 토큰 한도를 넘는 클러스터는 재귀적 재클러스터링
2.5 요약
- 모델: GPT-3, GPT-4, UnifiedQA
- 프롬프트: "가능한 많은 핵심 정보를 포함한 다음 내용을 요약하라."
- 압축 통계: 평균 요약 131토큰, 자식 평큔 86토큰 x 평균 6.7개 -> 평균 압축 비율 ≈ 0.28 (≈72% 절감)
- 환각률: 표본 150개 노드 중 약 4%에 경미한 환각. 부모로 전파되지 않음. QA 성능에 유의미 영향 없음.
2.6 질의 단계
- 모든 노드는 동일 임베딩 공간에서 코사인 유사도로 검색
복잡도 및 비용
- 트리 빌드 시간, 토큰 비용 모두 선형 스케일링에 가깝도록 설계, 대규모 코퍼스에도 적용 가능
3. 실험(Experiments) 및 구현
3.1 데이터셋
- NarrativeQA: 책/영화 전체 본문 기반 자유서술형 QA. 지표: ROUGE‑L, BLEU‑1/4, METEOR.
- QASPER: NLP 논문 본문에 대한 질의응답(정답 유형: 정답/무정답, 예/아니오, 추상, 추출). 지표: F1.
- QuALITY: 평균 5k 토큰 문맥의 객관식 QA. Hard 서브셋은 인간도 많이 틀린 난도 높은 문항.
3.2 통제 비교(Controlled Baselines)
- Reader: 기본적으로 UnifiedQA‑3B.
- Retrievers: SBERT, BM25, DPR 각각에 대해 RAPTOR 적용 전/후 성능 비교.
- 결과 요약: 세 데이터셋 모두에서 각 리트리버 대비 RAPTOR 적용 시 항상 향상.
3.3 주요 수치 (발췌)
NarrativeQA 기준
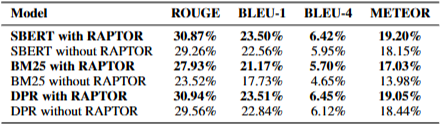
QuALITY and QASPER Performance With + Without RAPTOR
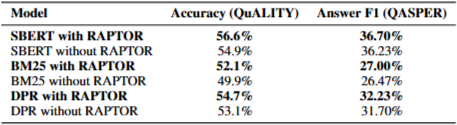
Controlled comparison of F-1 scores on the QASPER dataset, using three different lan-guage models (GPT-3, GPT-4, UnifiedQA 3B) and various retrieval method

3.4 정성 분석
동화(신데렐라) 질의에서 RAPTOR는 다층 노드를 선택해 질문 난이도/추상도에 맞춘 컨텍스트를 구성. DPR은 리프만 보통 집는다.
3.5 구현
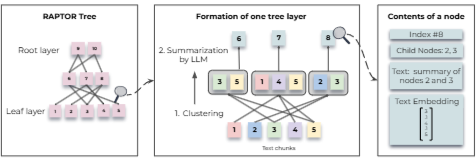
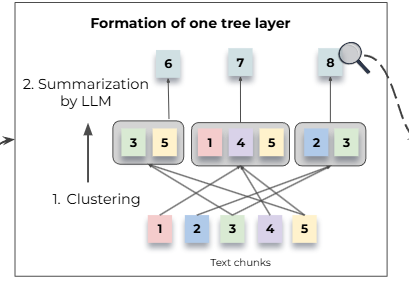
RAPTOR의 핵심은 트리 구조를 형성하는 것이다.
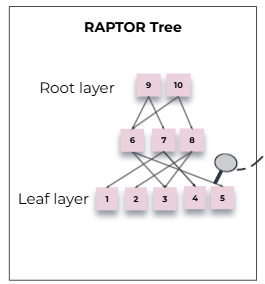
해당 트리는 다음과 같은 구조를 갖는다.
- 문장이 끊어지지 않는 조건에서 문서를 100 토큰 단위로 쪼개기
- 쪼갠 여러 개의 청크는 각각이 클러스터링 과정을 거치침
- 처음으로 클러스터링 된 청크들은 요약되어 Leaf layer로 구성됨
- 위 이미지에서는 요약된 1 ~ 5번 노드를 Leaf layer(노드)로 지정
- Leaf layer가 모두 구성되었다면 비슷한 것끼리 모아서 다시 클러스터링 진행
그냥 Leaf layer를 문장이라고 생각하면 편함
위 이미지는 RAPTOR Tree에서 처음으로 요약된 5번 노드의 전체 과정을 보여준 것이다.
- 먼저 문서를 Text chunks 들로 쪼갠다
- 이후 쪼갠 청크들을 클러스터링을 통해 모은다
- 이때 청크들은 여러 군집에 포함될 수 있음
- 모은 청크들은 LLM을 통해 요약된다.
- 이후 생성된 요약문들은 각각 6번, 7번, 8번 노드가 됨
요약된 8번 노드의 경우 처음 이미지를 보면 2번과 3번 텍스트 청크가 활용되었고
2번과 3번 텍스트 청크의 요약문이 8번 노드의 내용으로 들어가 임베딩 된 것을 확인할 수 있다.
- 그럼 위 이미지에서 6번, 7번, 8번 노드는 1 ~ 5번 노드가 비슷한 문장끼리 클러스터링 되고, 클러스터링 된 문장들의 요약본이라고 생각하면 됨
- 그럼 위에 9번 10번 노드도 마찬가지로 6번 7번 8번 노드가 비슷한 것끼리 클러스터링 되고, 클러스터링 된 문장들의 요약본이 노드가 된 것이라고 보면 됨
이렇게 점점 높은 레벨로 추상화해서 전체적은 RAPTOR의 트리 구조를 만드는 것이 핵심이다.
근데 최근에 긴 컨텍스트를 입력할 수 있는 대형 모델들이 많이 나오고 있는데 우리가 굳이 RAG에 신경을 써야 하나? 편하게 문서 하나를 통째로 입력으로 넣어서 질문을 추가하면 되는 거 아닌가??
이렇게 생각할 수 있지만
실제로 이와 같은 실험을 한 결과 긴 컨텍스트를 LLM에게 전달해준 경우 LLM은 너무 데이터가 많은 나머지 사용자가 원한 디테일을 살린 답변을 제대로 제공해주지 못한다.
그 이유는 컨텍스트의 길이가 증가함에 따라서 성능이 대체적으로 저하되기 때문이다.
추가로 긴 컨텍스트의 경우 비용과 시간이 더 많이든다는 단점이 존재한다.
4. 구성요소 기여/어블레이션
4.1 레이어 기여
-
전체 트리(상위 요약 + 리프)를 함께 검색할 때 가장 성능이 높음. 특정 스토리 예시에서 모든 레이어 사용(3단계)가 리프 전용보다 크게 우수.
-
대규모 분석에서 비리프(non‑leaf) 노드가 차지하는 비율이 상당(예: NarrativeQA의 경우 DPR 리트리버 사용 시 비리프 57% 등), 레이어 분포는 데이터셋/리트리버별 다름.
4.2 클러스터링 메커니즘 vs. 연속 요약 트리
- 동일 평균 윈도 크기(약 7조각)로 연속 청킹 기반 균형 트리를 만들어 비교 시, RAPTOR의 GMM 클러스터링이 정확도 56.6% vs 55.8%로 우위.
4.3 요약 품질/환각 분석
- 150 노드 표본의 수작업 평가에서 4% 경미 환각 확인. 부모 요약으로 전파 없음, QA 성능 영향 미미.
4.4 압축률 통계
- 평균 요약 131토큰, 자식 텍스트 평균 85.6토큰, 평균 자식 수 6.7 → 평균 압축비 0.28.
5. 결론
-
RAPTOR는 요약-클러스터 기반 계층 트리로 장문·복합 질의를 효과적으로 지원하는 검색 증강 프레임워크.
-
정량적으로 기존 BM25/DPR 대비 일관 향상, 정성적으로도 질의 추상도에 맞춘 컨텍스트 조합이 강점.
-
SOTA 갱신: QASPER, QuALITY, NarrativeQA 일부 지표.
6. 상세 내용
RAPTOR 트리 구축의 큰 흐름
전역 차원 축소 (UMAP)
고차원의 임베딩(768차원)을 UMAP으로 목표 차원 수(target dimension)(50차원)으로 줄여서, 군집이 잘 드러나도록 "공간"을 만든다.
UMAP은 가까운 이웃 관계를 보존해 주어, 이후 클러스터링에 유리한 저차원 표현을 준다.
전역 클러스터링 (GMM + BIC로 K군집을 선택)
전역 축소 결과에 대해 GMM을 다양한 K로 학습하고, BIC가 최소가 되는 K를 선택한다.
GMM은 각 군집을 정규분포의 혼합으로 모델링하고, 각 점의 클러스터 책임도를 준다.
즉 군집 개수 K를 여러 개수(K=2,3,4...)를 시험해 보고, BIC라는 점수로 제일 잘 맞는 K를 선택하도록 한다.
책임도(Responsibility)
각 점이 그룹에 속할 확률을 의미하는 것이다.
GMM은 단순히 "너는 2번 그룹" 이렇게만 주지 않기 때문에 대신 각 점에 대해 "1번 그룹에 속할 확률 70%, 2번 그룹에 속할 확률 25%, 3번 그룹에 속할 확률 5%"와 같이 알려준다.
이 확률을 책임도라고 부른다.
임계값(Threshold, τ)
위에서 각 점은 여러 그룹에 걸쳐 속할 수 있다고 했다.
그런데 RAG에서는 한 문서가 여러 그룹에 속할 수도 있고, 하나만 속해야 할 수도 있다.
그래서 임계값 τ을 정한다.
예 τ=0.25 --> 확률이 25% 이상인 그룹에는 다 넣어준다.
위와 같이 임계값을 정하면 한 점이 여러 그룹에 들어갈 수도 있고, 하나만 들어갈 수도 있고, 하나만 들어갈 수도 있다.
즉 이정도 확률이면 그 그룹에 넣자라는 컷 오프선을 설정해두는 것이다.
로컬 차원 축소 & 재클러스터링
전역 단계에서 생긴 각 큰 군집 내부만 떼어 다시 UMAP -> GMM을 돌리면, 더 미세한 서브클러스터가 나온다.
위와 같은 과정을 거치면
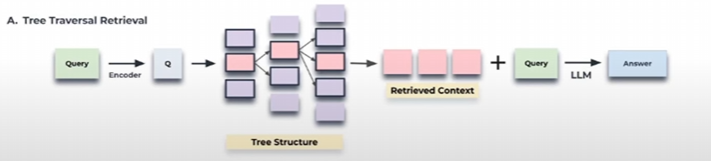
위와 같이 정리가 된다.
Tree Structure를 구성하게 되고 이후 구성된 것들 중 유사한 내용만 뽑아 쿼리와 결합시켜 결과를 출력하게 된다.

좋은 논문 정리 글 감사합니다 ^.^