BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
논문 리뷰
논문 원문 링크 : https://arxiv.org/pdf/2201.12086
논문 2줄 요약
-
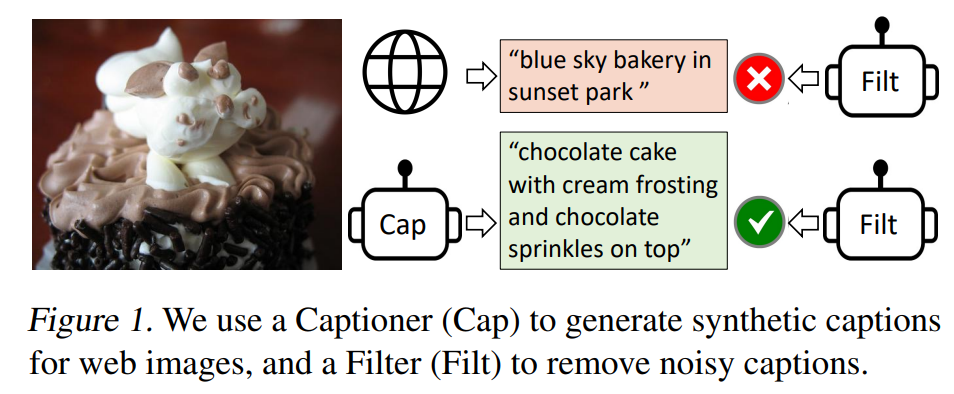
기존 VL-Pretraining 모델에서 사용한 web data의 noisy caption 문제 -> CapFilt 구조 제시를 통해 해결
-
Text generation, Image-text retrieval task를 모두 잘하는 새로운 모델 구조 제시(MED)
Abstract
- Vision-Language Pre-training (VLP)은 많은 vision-language task의 성능을 향상시킴
기존 VLP의 문제점
- 대부분 understanding-based tasks나 generation-based tasks에서만 뛰어난 성능을 발휘
- 웹에서 수집한 noisy한 image-text pair들로 데이터셋을 확장함으로써 성능 개선이 주로 이루어졌는데, 이는 차선책의 supervision 소스임
- 이 논문에서는 vision-language understanding & generation task에 모두 유연하게 적용할 수 있는 새로운 VLP framework인 BLIP을 제안
- BLIP은 captioner가 synthetic caption을 생성하고 필터가 noisy 캡션을 제거하는 bootstrapping 방식으로 noisy web data를 효과적으로 활용
- 다양한 vision-language task(image-text retrieval, image captioning, VQA) 에서 SOTA를 달성
- BLIP은 zero-shot 방식으로 video-language task에 바로 적용할 때 강력한 일반화 능력
1. Introduction
기존 방법론들의 2가지 major limitations
(1) Model perspective
- encoder-based models : text generation task에 바로 적용 하기 어려움
- encoder-decoder models : image-text retrieval task에 별로 적용 잘 안 됨
(2) Data perspective
- CLIP, ALBEF, SimVLM 같은 SOTA 모델들은 web에서 수집된 image-text pair에 pre-train됨
=> dataset을 scaling up한 것으로 성능이 향상된 거임 - 반면에 우리는 noisy web text가 vision-language learning에선 suboptimal하다는 걸 보여줄 거임
model & data perspective에서의 2가지 contribution
(a) Multimodal mixture of Encoder-Decoder (MED) : a new model architecture for effective multi-task pre-training and flexible transfer learning.
(b) Captioning and Filtering (CapFilt): new dataset boostrapping method for learning from noisy image-text pairs.
experiment 통해 얻은 사실
- captioner와 filter가 함께 caption을 bootstrappin하여 다양한 downstream task에서 상당한 성능 향상을 달성
- 더 다양한 caption을 생성할수록 더 큰 성능 향상이 이루어진다는 점 발견
- BLIP(Bootstrapped Language-Image Pretraining)은 image-text retrieval, image captioning, Visual Question Answering(VQA), visual reasoning(시각적 추론), visual dialog(시각적 대화) 등 다양한 vision-language task에서 SOTA 달성
- BLIP 모델을 video-language task인 text-to-video retrieval & videoQA에 transfer했을 때도 zero-shot 성능에서 SOTA 달성
2. Related Work
2.1. Vision-language Pre-training
- Vision-Language Pre-training(VLP)은 대규모 image-text 쌍을 활용하여 모델을 사전 학습함으로써, downstream vision and language tasks에서 성능을 향상시키는 것을 목표로 한다.
- 그러나 인간이 직접 라벨링한 text를 획득하는 비용이 너무 높기 때문에, 대부분의 연구는 웹에서 크롤링한 image-대체 텍스트(alt-text) 쌍을 사용
- 웹 텍스트에는 간단한 rule-based filters을 적용하지만, 여전히 노이즈가 많다.
- 하지만, 데이터셋의 규모를 확장하면 성능이 향상된다는 효과에 가려져 노이즈의 부정적인 영향은 대부분 간과되었다.
=> 본 연구에서는 노이즈가 많은 웹 텍스트가 vision-language learning에 최적화되지 않았음을 증명하며, web datasets을 더 효과적으로 활용할 수 있도록 CapFilt를 제안한다.
🔹 비전-언어 통합 모델 연구
여러 연구에서는 다양한 vision and language tasks를 단일 프레임워크로 통합하려는 시도를 진행해 왔다
이때 가장 큰 challenge는,
✅ understanding-based tasks(예: image-text retrieval)
✅ generation-based tasks (예: image captioning)
두 가지 모두를 수행할 수 있는 모델 아키텍처를 설계하는 것이다.
- 인코더 기반 모델(encoder-based models) &인코더-디코더 기반 모델(encoder-decoder models)은 두 ask를 모두 잘 해내지 못함
- 단일 통합 인코더-디코더 모델(single unified encoder-decoder)은 모델의 capability을 제한한다.
이에 따라, 본 연구에서는 멀티모달(Multimodal) 혼합 인코더-디코더 모델(mixture of encoder-decoder model)을 제안하여,
1️⃣ 다양한 다운스트림 과제에서 더 유연하고 높은 성능을 제공하고,
2️⃣ pre-training을 유지할 수 있도록 한다.
3. Method
3.1 Model Architecture
image encoder로 visual transformer(ViT) 사용 & task에 맞는 Loss 함수 사용
Multimodal mixture of Encoder-Decoder (MED)
다음의 3가지 기능 중 하나로 동작 가능
(1) Unimodal encoder
: separately encodes image and text
- text encoder = BERT와 동일, where a [CLS] token is appended to the beginning
of the text input to summarize the sentence.
(2) Image-grounded text encoder
: text encoder의 각 transformer block에다가 by self-attention (SA) layer & feed forward network (FFN) 사이에 cross-attention (CA) layer 1개를 추가적으로 끼워넣음 => injects visual information
- task-specific [Encode] token이 text에 추가됨
- output embedding of [Encode]이 image-text pair의 multimodal representation으로 사용됨
(3) Image-grounded text decoder
: image-grounded text encoder의 bidirectional self-attention layers를 causal self-attention layers로 대체함
- [Decode] token이 beginning of a sequence임을 표시하기 위해 사용됨
- 끝을 나타내기 위해 end-of-sequence token 사용됨
3.2. Pre-training Objectives
1. ITC(Image-Text Contrastive Loss) : activates the unimodal encoder
- 목표 : visual transformer & text transformer의 feature space를 align
- Contrastive Learning 개념을 그대로 도입
- 같은 {image, text} pair에 있으면 코사인 유사도가 높게, 반대이면 유사도가 낮도록 학습
ex) 한 batch에 16개 데이터가 있으면, 1개의 이미지는 자신과 매칭된 1개의 text와만 positive pair 관계, 나머지 15개의 text에 대해 negative pair되도록 학습 - noisy web data 특성상, 잘못된 정보가 많음 -> 제어하기 위해 momentum encoder를 사용하여 pseudo-label을 생성하여 활용 => image를 더 풍성하고 정확한 캡션과 연결 가능
2. Image-Text Matching Loss (ITM) : activates image-grounded text encoder
- 목표 : vision & language 간의 fine-grained alignment를 포착하는 image-text multimodal representation을 학습
- ITM : 주어진 multimodal feature를 갖고 {image, text} pair가 match 됐는지 여부(positive / negative)를 예측하는 binary classifaction task
- image encoder를 거쳐서 나오는 image 정보를 cross attention 연산을 통해 받음
- 학습 과정에서 negative sample 선택할 때, 최대한 image나 text의 semantic 정보가 비슷한 hard negative sample을 선택해서 학습함
3. Language Modeling Loss (LM) : activates image-grounded text decoder
- 목표 : 주어진 image에 대한 textual description 생성할 수 있도록 학습
- image encoder를 거쳐서 나오는 image 정보를 cross attention 연산을 통해 받음
=> 해당 image에 대한 캡션 생성
3.3. CapFilt (Captioning & Filtering )
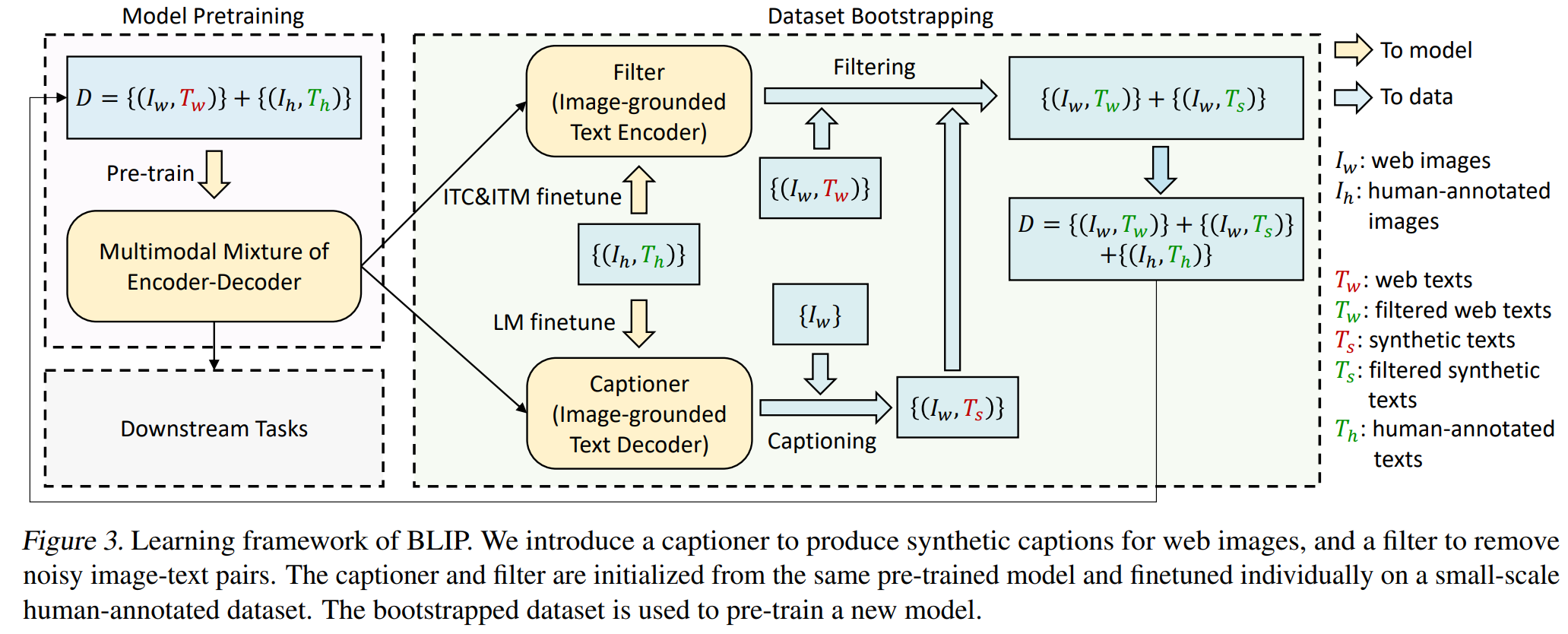
- 목표 : text corpus의 퀄리티 향상
2가지 module
이때 captioner랑 filter는 둘다 initialized from the same pre-trained MED model & finetuned individually on the COCO dataset (by lightweight procedure)
1) captioner: web image에 대한 caption 생성
- image-grounded text decoder임
- 주어진 image에 대해 text를 decoding하도록 LM objective에 의해 finetune됨
- 주어진 web image에 대해 captioner는 synthetic caption을 생성 (1장 당 캡션 1개)
2) filter : remove noisy image-text pairs
- image-grounded text encoder임
- text가 image와 matching되도록 ITC와 ITM objective에 의해 finetune됨
- original web texts Tw & synthetic texts Ts에서 noisy image-text pairs 제거
- ITM 모듈이 image와 unmatched로 예측한 경우 해당 텍스트를 노이즈로 간주하여 제거
=> 이렇게 filtering된 image-text pairs는 human-annotated pairs와 combine 되어 새로운 dataset 구축함
& 이 dataset으로 새로운 모델 pretraining함
4. Experiments and Discussions
4.2. Effect of CapFilt
-
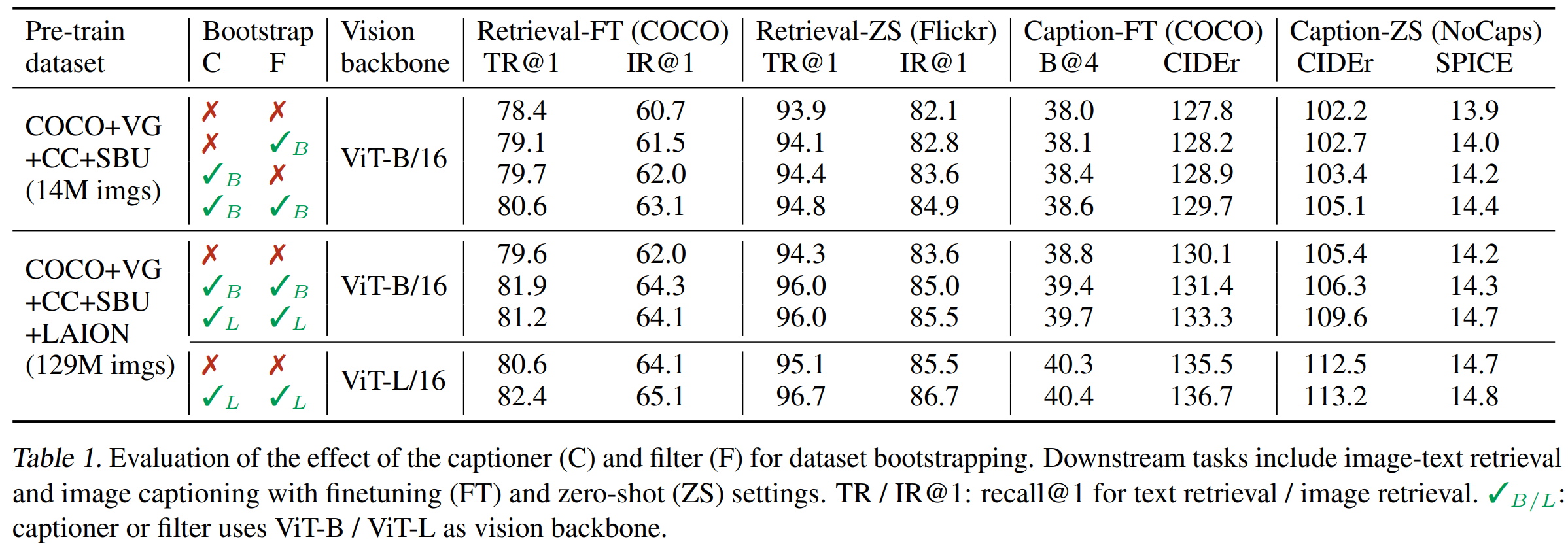
downstream task(image-text retrieval & image captioning with finetuned & zero-shot settings)에서의 CapFilt의 효과를 보기 위해 다른 dataset들에 pretrain된 모델의 성능을 비교해봄
-
captioner 또는 filter 중 하나만 dataset(14M images)에 적용된 경우, 성능 향상됨
-
둘다 적용된 경우엔 서로의 효과를 보완하여 기존 noisy web text 쓸 때보다 성능 훨씬 향상됨
-
CaFilt는 더 큰 데이터셋과 더 강력한 vision backbone을 활용하면 성능 더욱 향상
=> 데이터셋 크기와 모델 크기에서 모두 scalability 확인 -
대형 captioner & filter를 ViT-L과 함께 쓰면 base model의 성능도 향상됨
-
web text가 CapFilt에 의해 변경된 결과 caption 예시들

-
모델 파라미터 수 줄이기 위해 layer들의 파라미터 공유하는 방법 사용
=> Self attention layer 제외한 layer들의 파라미터를 공유하니 성능이 올라감
(self attention layer는 encoder와 decoder의 작업 자체가 달라서 충돌 일어날 수 있어서 공유 안 했음)

