논문 리뷰
1.3D Copy-Paste: Physically Plausible Object Insertion for Monocular 3D Detection

단안 3D 객체 검출의 주요 과제는 실제 데이터 세트에서 객체의 다양성과 양이 제한적이라는 것이다.가상 객체로 실제 장면을 증강하는 것은 객체의 다양성과 양을 모두 향상시킬 가능성이 있지만 복잡한 실제 캡처 장면에서 효과적인 3D 객체 삽입 방법이 없기 때문에 여전히
2.Virtual Occlusions Through Implicit Depth [CVPR 2023]
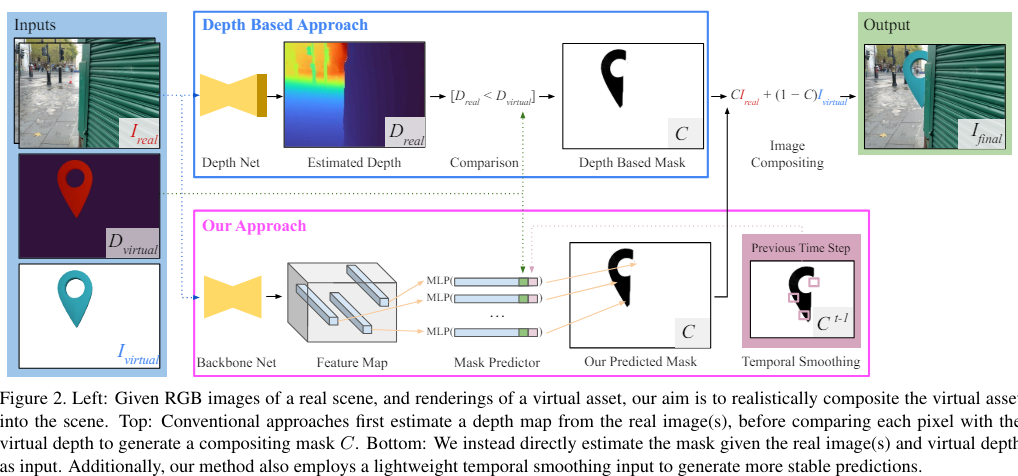
증강 현실(AR)에서는 virtual assets이 실제 객체 '사이에 위치'하는 것처럼 보이는 것이 중요구현돼야하는 점가상 요소는 plausible depth ordering (그럴듯한 깊이 순서)에 따라 실제 물질을 가리거나 실제 물질에 의해 가려져야함
3.Retrieval-Augmented Layout Transformer for Content-Aware Layout Generation(RALF)[CVPR 2024]
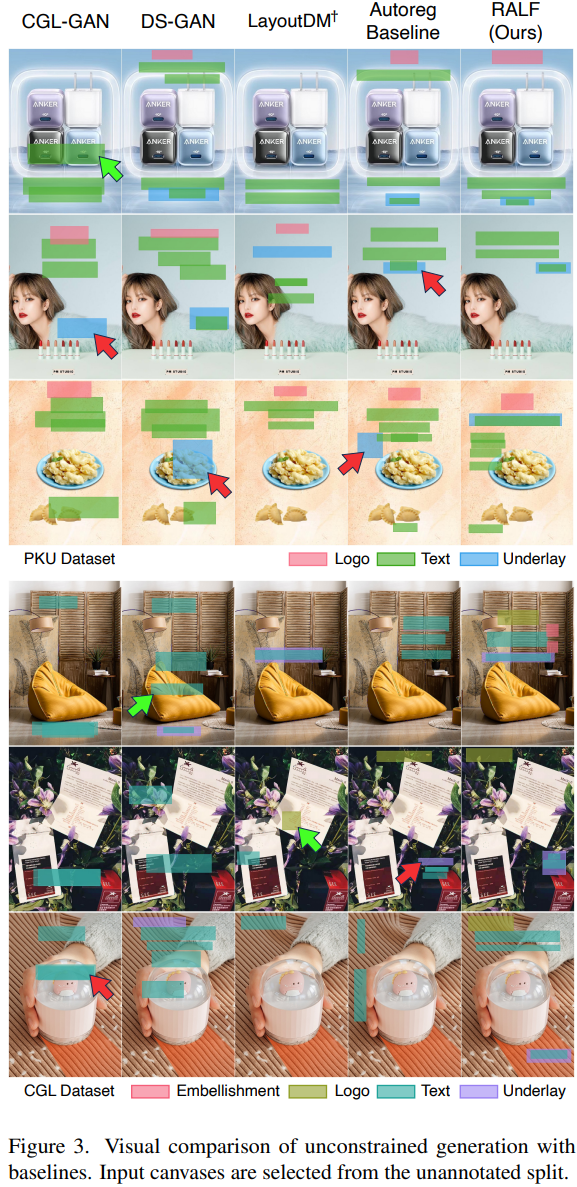
Content-aware graphic layout generation : 이커머스 제품 image와 같이 주어진 콘텐츠에 따라 시각적 요소를 자동으로 정렬하는 것이 목표임high-dimensional layout 구조 학습을 위한 제한된 training data 문제
4.SAM (Segment Anything)

논문 원문 링크 0. Abstract 모든 분야에서 광범위하게 사용할 수 있는 image segmentation을 위한 모델, 데이터 세트인 SA(Segment Anything) 프로젝트 1. Introduction > 목표 : image segmentation의
5.PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation [CVPR 2017]
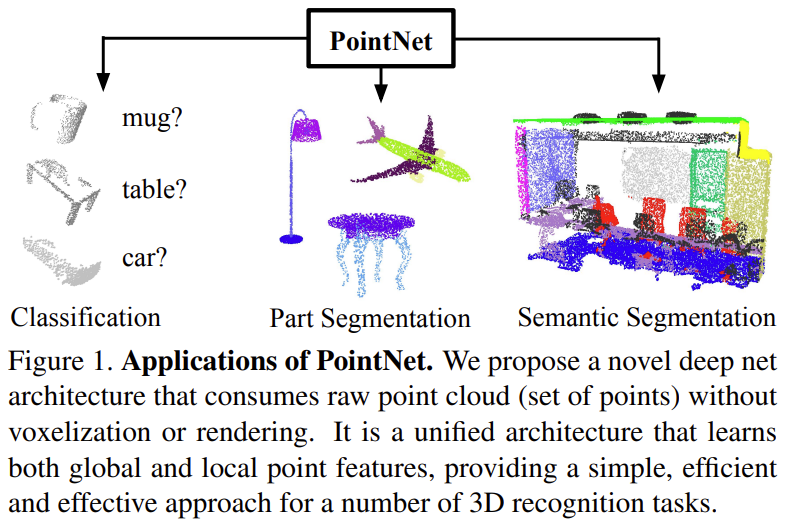
논문 원문 링크 0. Abstract point cloud : geometric data 구조 중 중요한 형태임 irregular한 format 때문에, 대부분 연구자들은 regular한 3D voel grid 또는 image들의 집합으로 변환해서 사용함 하지만 이렇게
6.Object pop-up: Can we infer 3D objects and their poses from human interactions alone? [CVPR 2023]
프로젝트 페이지 링크 논문 원문 링크 0. Abstract Human Object Interaction(HOI) 분야에서 많은 사람들이 가장 흔하게 초점을 두는 것은 Object임 예를 들어서, 의자가 있으면 앉아야하고, 컵이 있으면 손으로 쥐어야하는 것처럼 대부분
7.InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions [CVPR 2023 Highlight]
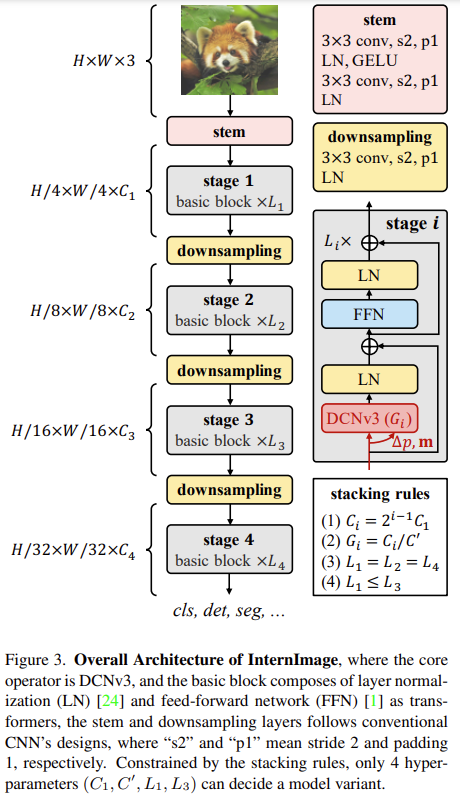
최근 몇 년간 대규모 비전 트랜스포머(ViT)가 크게 발전한 것에 비해 CNN 기반의 대규모 모델은 아직 초기 단계에 머물러 있음이 연구에서는 ViT와 같이 매개변수와 학습 데이터를 늘려서 이득을 얻을 수 있는 새로운 대규모 CNN 기반 기초 모델인 InternImag
8.CAST: Cross-Attention in Space and Time for Video Action Recognition [NeurIPS 2023]
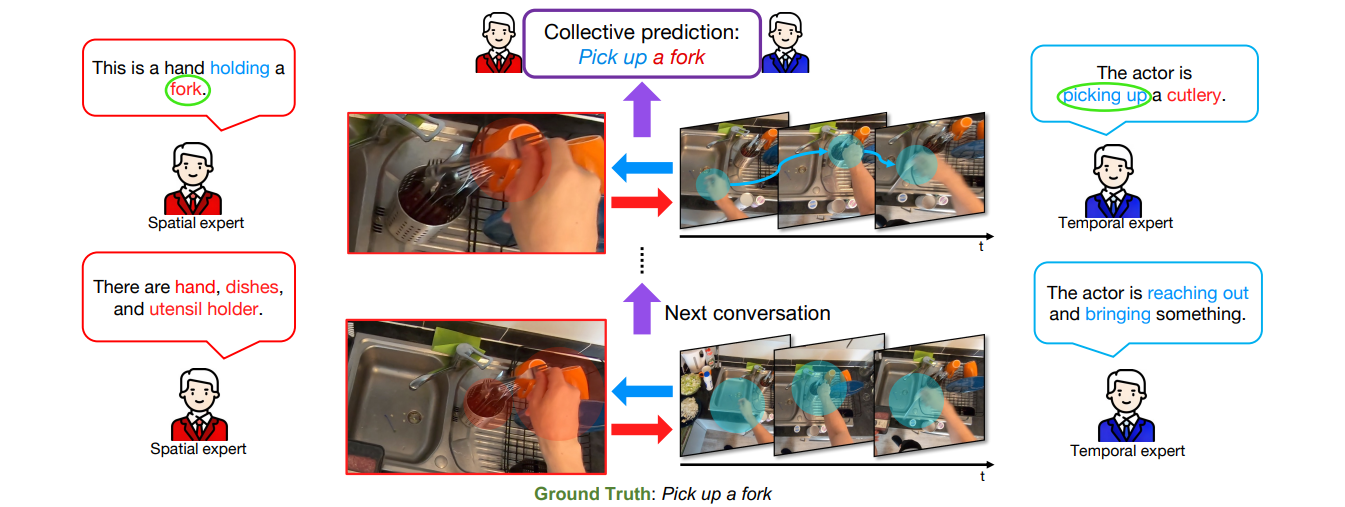
https://docs.google.com/presentation/d/1Xf2kT3-RNO3qlZUcFuaW3vl2i-K-DabJZbUcfwkIOXc/edit#slide=id.g2f4e517a4a40186 논문 원문 링크 : https://arxiv.org/pdf/2
9.CLIP: Learning Transferable Visual Models From Natural Lanugage Supervision
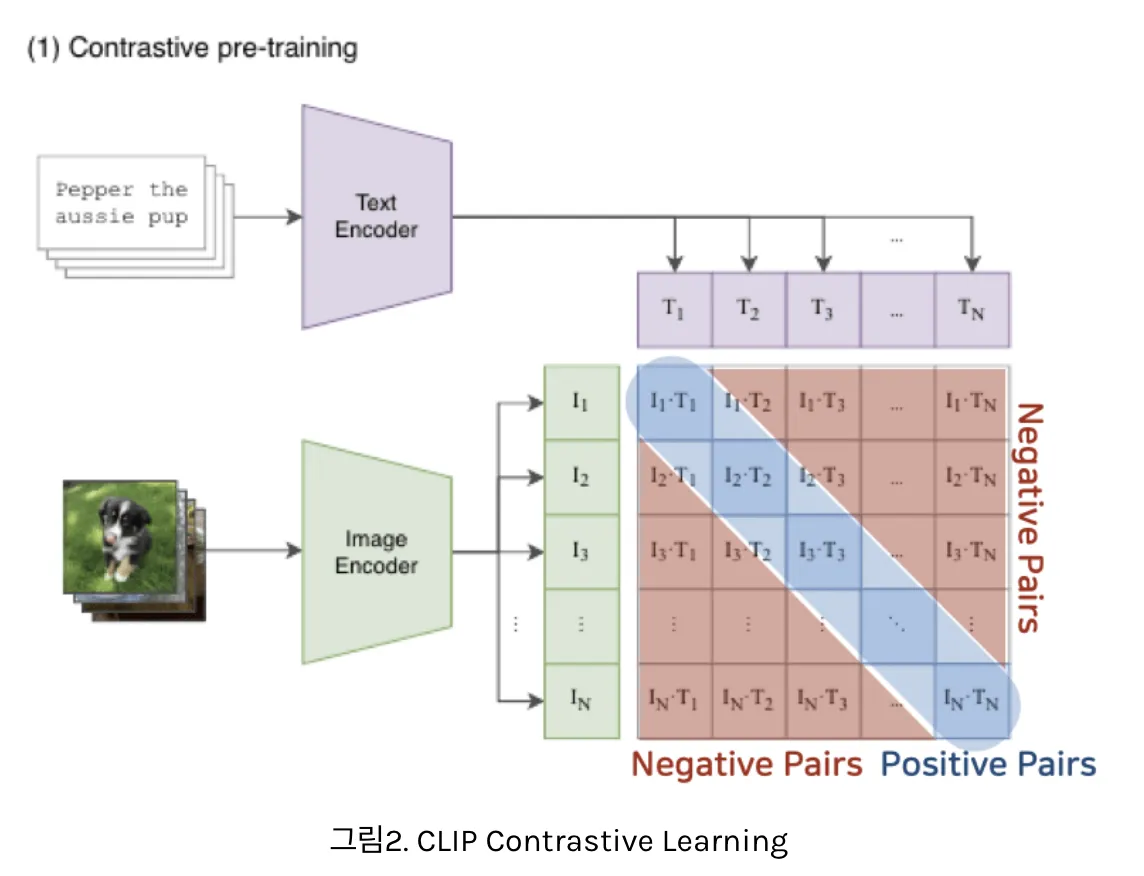
딥러닝 모델이 인간보다 성능이 낮은 이유 : train dataset에서 in-distribution performane’를 향상시키도록 학습하기 때문Domain(Distribution) Shift : train data와 test data의 분포 차이도메인 변화에 효
10.In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation [ECCV 2024]
논문 원문 링크 : https://arxiv.org/pdf/2408.04961 Abstract lazy visual grounding : open-vocabulary semantic segmentation 을 위해 object grounding에 따라 unsupervised object mask discovery를 수행하는 2단계 approach 많은 선...
11.DDIM : Denoising Diffusion Implicit Models [ICLR2021]
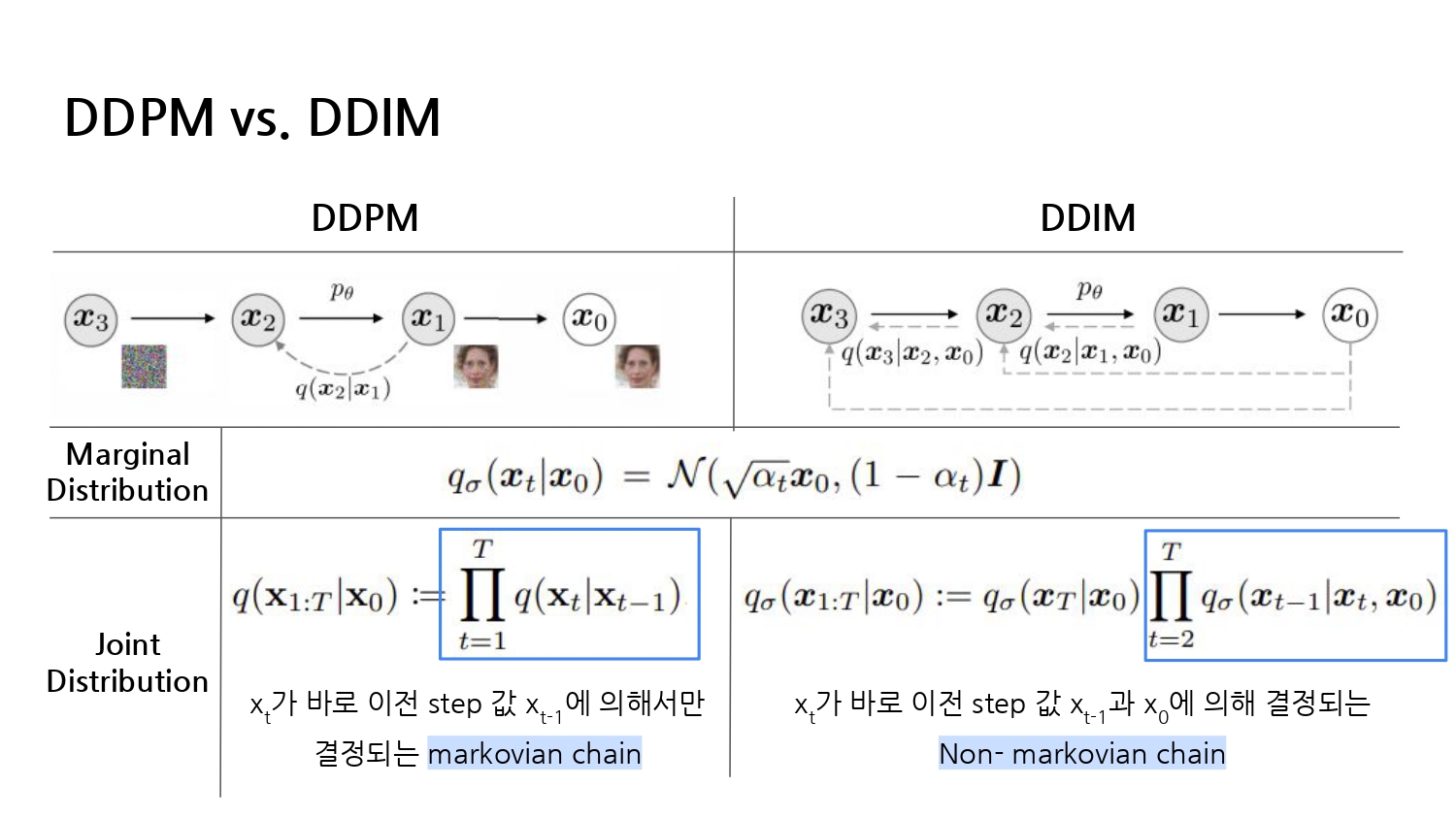
Diffusion Study에서 발표한 DDIM 논문 리뷰입니다.
12.Hierarchical Open-vocabulary Universal Image Segmentation [NeurIPS 2023]
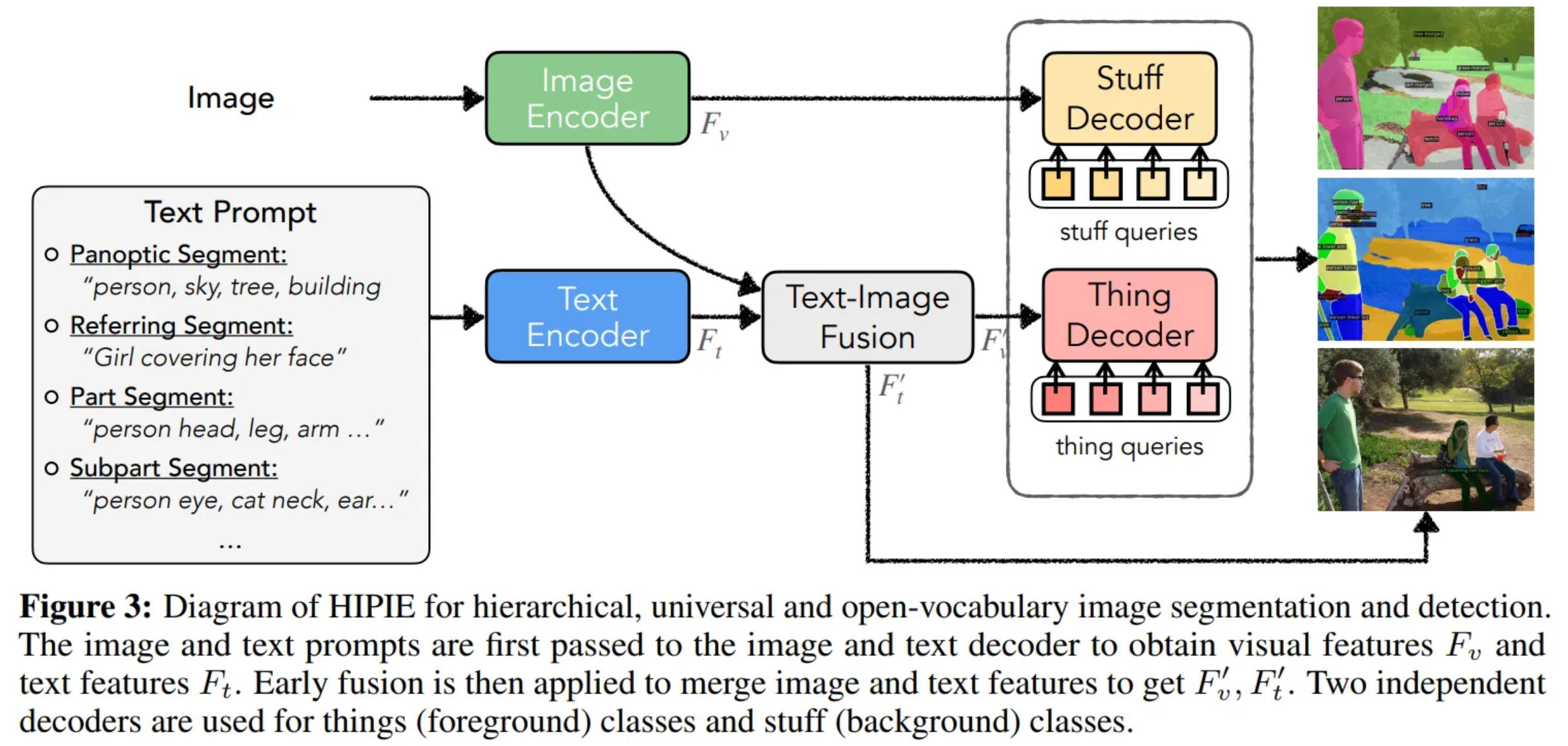
논문 원문 링크 : https://arxiv.org/abs/2307.00764 Abstract Open-vocabulary image segmentation : 임의의 텍스트 설명에 따라 이미지를 의미론적 영역으로 분할하는 것을 목표 그러나 복잡한 시각적 장면은 자연
13.Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs [CVPR 2016]
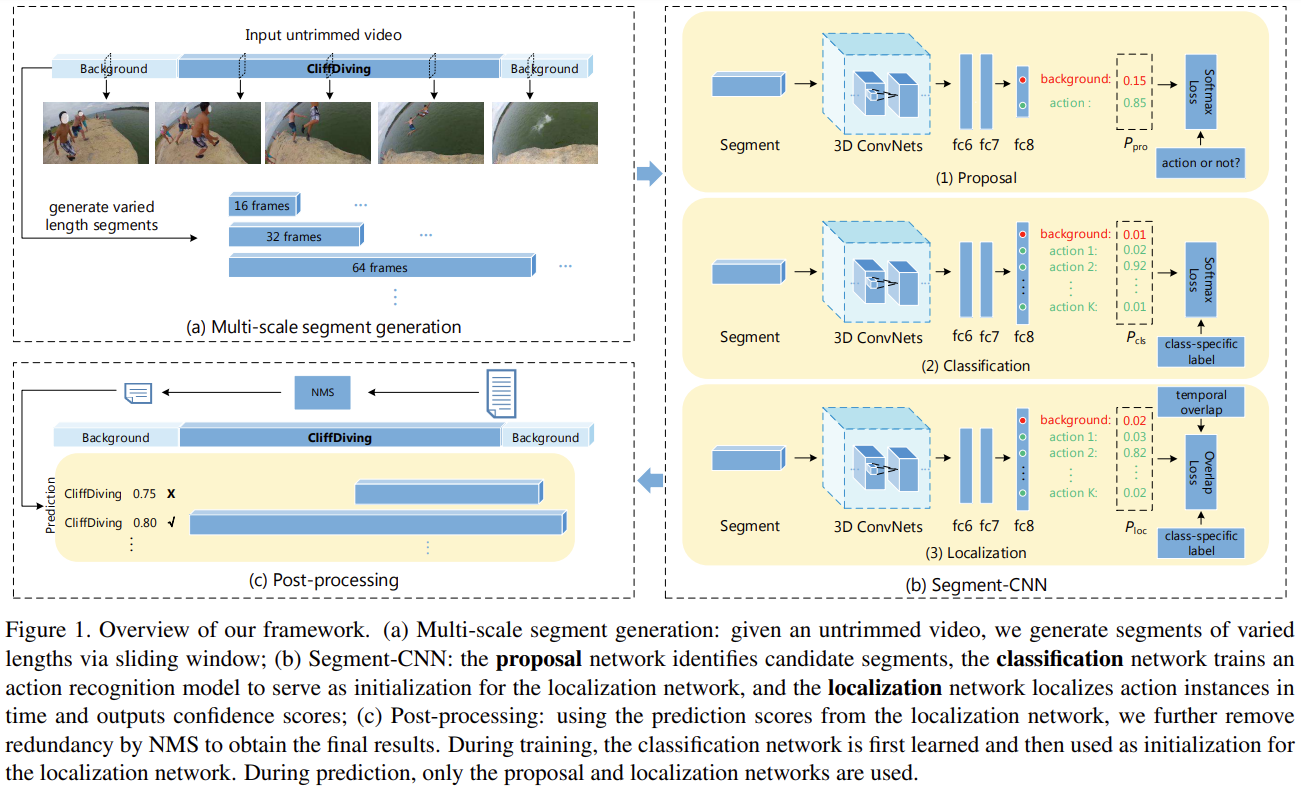
긴 비편집 동영상(untrimmed long video) 에서 temporal action localization을 처리함실생활에서 사용되는 동영상은 일반적으로 unconstrained(제약이 없음) & 여러 action instance와 background scene
14.BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
논문 원문 링크 : https://arxiv.org/pdf/2201.12086 논문 2줄 요약 기존 VL-Pretraining 모델에서 사용한 web data의 noisy caption 문제 -> CapFilt 구조 제시를 통해 해결 Text generation,
15.Emergent Visual-Semantic Hierarchies in Image-Text Representations [ECCV 2024(Oral)]
Abstract Motivation CLIP과 같은 VLM은 text와 image를 공통된 semantic space 상에서 분석하는데는 강력하지만, 이런 모델들은 image를 설명하는 text들의 계층적 구조를 explicitly(명시적으로) 모델링하진 않음 반면,
16.Recognize Anything: A Strong Image Tagging Model
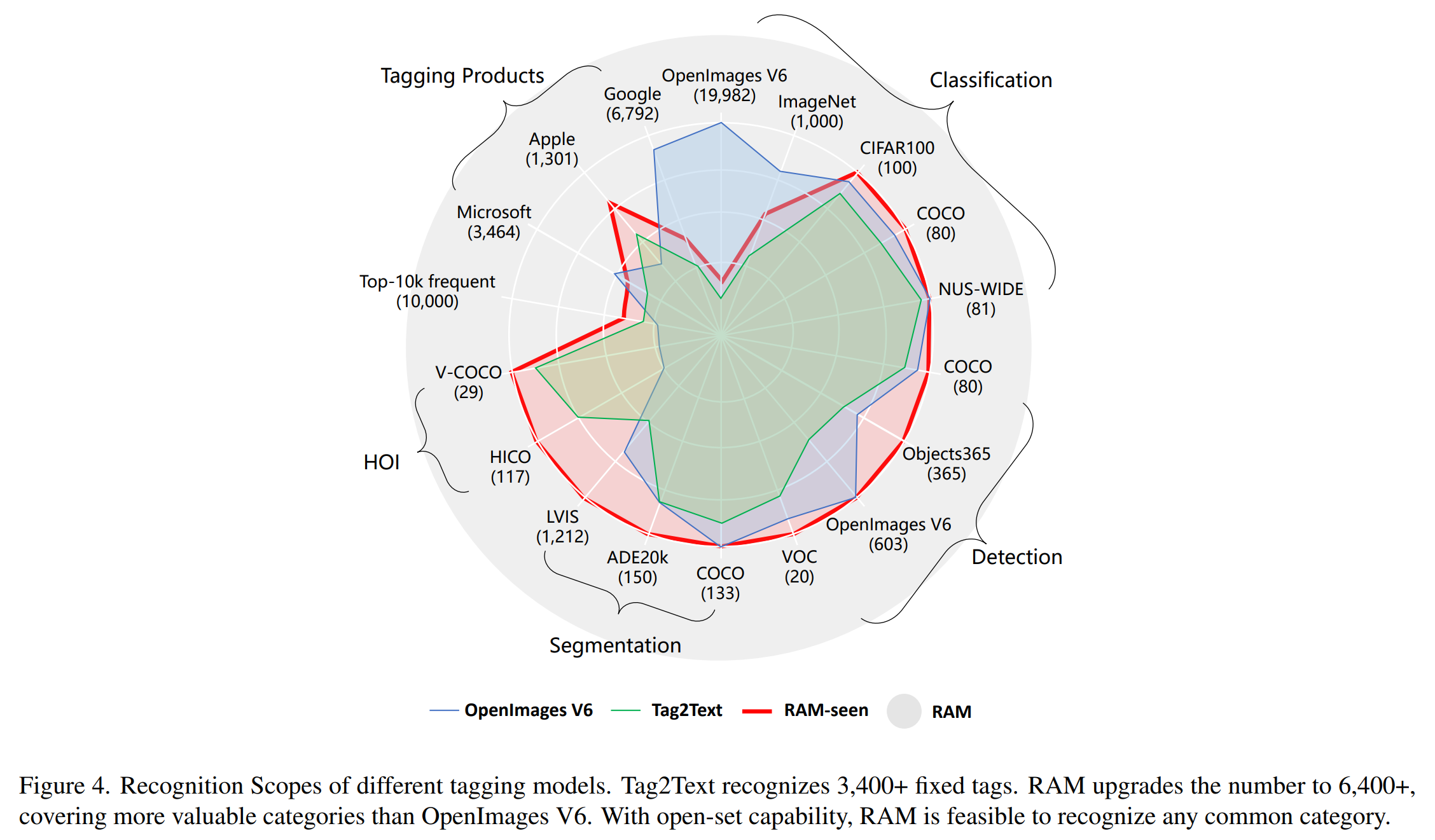
논문 원문 링크 : https://arxiv.org/pdf/2306.03514 Abstract RAM : manual annotations 대신에 large-scale image-text pairs를 이용하여 image tagging을 하는 strong foundat