그리디 알고리즘에 초점을 두어 파일 압축 알고리즘 => 허프만 코딩
문자별로 다른 크기의 코드를 부여해야함!
- 빈도수가 높을수록 짧은 코드 부여
코드가 이진수 => 이진 트리를 연관 지어보자
- 왼쪽 자식으로 내려갈 때 : 0
- 오른쪽 자식으로 내려갈 때 : 1
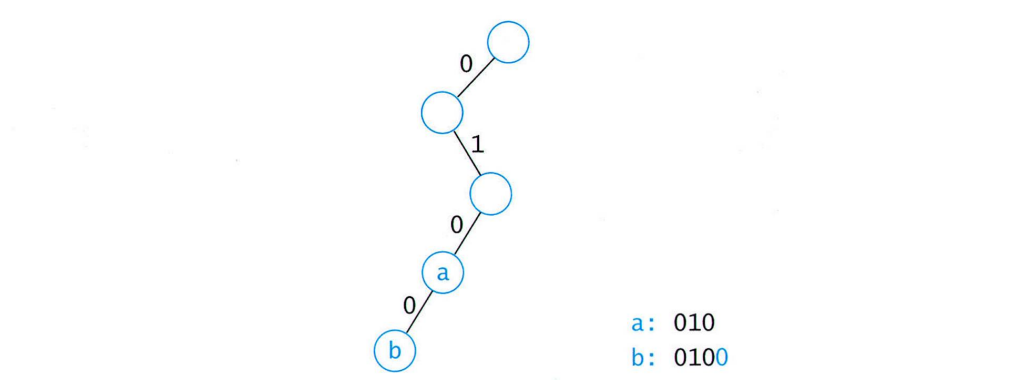
코드(010100...)로 변환 후 복원할 때 몇 개씩 끊어서 바꿔야할지 모름
-> 특수 문자를 끼워 넣자 but 압축 성능 저하
-> 특수 문자 안 쓰려면
한 문자의 코드가 다른 문자의 코드의 앞부분과 같으면 안 됨 => "Prefix-free 속성"
📌 Prefix-free 속성
- 어떤 코드도 다른 코드의 앞부분과 다름
- 코드가 Prefix-free 속성 가지려면 이진 트리의 내부 노드(이파리가 아닌 노드)에 문자가 있으면 안 됨
-> 문자는 이파리에만 있어야 함!
📌 이진트리인 허프만 트리 생성 그리디 알고리즘
- 각 문자의 빈도수 계산
- 문자마다 문자 & 빈도수 가진 이파리(제일 끝) 노드 만듦
- 빈도수가 가장 적은 2개 노드의 부모를 만들어 빈도수의 합을 저장
- if 노드가 1개만 남으면:
- 남은 노드를 허프만 트리의 루트로 반환
- else:
- 자식이 된 노드를 제외하고 go to 3.
📌 복원(Decoding) 알고리즘
- 허프만 트리의 루트에서 시작하여 0;왼쪽 / 1;오른쪽 자식으로 내려가서 이파리(맨끝)에 도달하면 그 이파리가 가진 문자로 복원
📌 수행시간
- 최소 힙 만드는데 O(n)
- 최소 빈도수 가진 2개 노드의 부모 만들기 (n-1)회 수행
(새 부모 노드 1개 추가, 2개의 노드는 사라짐)=> 총 1개 감소
- 최소 힙에서 2회 루트 삭제 + 새 부모 노드 삽입 : O(logn) - 총 수행시간
=> O(n) + (n-1)*O(logn) = O(nlogn)

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌