In Defense of Lazy Visual Grounding for Open-Vocabulary Semantic Segmentation [ECCV 2024]
논문 리뷰
목록 보기
10/16
논문 원문 링크 : https://arxiv.org/pdf/2408.04961
Abstract
- lazy visual grounding : open-vocabulary semantic segmentation 을 위해 object grounding에 따라 unsupervised object mask discovery를 수행하는 2단계 approach
- 많은 선행 연구는 이 작업을 object 수준 이해 없이, pixel-to-text classification로 처리하여 pretrain된 VLM의 image-to-text classification capability을 활용
- 우리는 segmentation는 본질적으로 vision task이기 때문에 prior text 정보 없이도 visual object를 구별할 수 있다고 주장함
- lazy visual grounding는 먼저 반복적인 Normalized cut으로 이미지를 커버하고 있는 object mask를 발견한 다음 late interaction manner로 발견한 객체에 text를 할당
- 이 모델은 additional training이 필요하지 않으면서도 5개의 public dataset에서 뛰어난 성능을 보임: Pascal VOC, Pascal Context, COCO-object, COCO-stuff, ADE 20K
- 특히 시각적으로 매력적인 segmentation 결과는 모델이 object를 정확하게 localize함을 보여줌
1. Introduction
- open-vocabulary semantic segmentation (OVSeg) 작업은 클래스가 텍스트를 기반으로 하는 이미지 분할 작업
- OVSeg는 이미지 세그먼트를 텍스트에 설명된 잠재적으로 보이지 않는 클래스와 정렬하는 것을 목표로 함
- 이 작업을 해결하기 위해 CLIP[76]과 같은 이미지-텍스트 인코더가 텍스트 설명을 인식하는 데 자주 사용됨
- 일련의 work는 image patch & text embeddings의 alignment(정렬)을 활용하여 pixel-to-text classification를 통해 OVSeg를 해결합니다.
- 그러나 이러한 pixel grounding approach은 distingushable object를 거의 이해하지 못함
- 최신 multi-modal segmentation model의 부정확한 segmentation은 segmentable한 visual unit으로 이루어진 이미지에 대해 고전적인 컴퓨터 비전 기법을 다시 생각해 보도록 유도함
- 잔디 위에 있는 네발 달린 동물을 segmentation하고자 한다고 상상해 보자.
- Q. segmentation하기 전에 그 동물의 이름이 필요할까요?
- 수십 년 전부터 접근해 온 image segmentation은 주로 vision task이며, 우리는 text 형태로 object의 이름을 몰라도 vision input만으로 object를 visual unit으로 구분할 수 있다고 주장함
Contributions
- 먼저 object를 discover한 다음, open-vocabulary semantic segmentation을 위해 나중에 interaction 방식으로 object에 text를 할당하는 LaVG(Lazy Visual Grounding)를 소개함
- mask가 모든 이미지 픽셀을 덮을 때까지 반복적으로 object mask를 발견하기 위해 Normalized cut을 재검토하며, 이를 Panoptic cut이라고 부름
- 이 모델에는 추가 train이 필요하지 않으므로 train cost이 전혀 들지 않음
- graph partitioning을 기반으로 하는 간단한 방법은 SOTA open-vocabulary segmentation model들을 정량적으로 능가하며 훨씬 더 정밀한 객체 경계를 가진 segmentation mask를 생성함
2. Related Works
2.3.Vision-and-Language Representation Learning
CLIP 소개하는 내용
- 그 중 대표적인 VLM인 CLIP은 4억 개의 웹 크롤링 이미지와 텍스트 쌍을 사용하여 크로스 모달 임베딩 유사성을 학습
- CLIP은 positive image-text pair 간의 embedding similarity가 training batch의 다른 pair보다 크도록 two-tower image-text transformer encoders를 훈련함
- 오픈 소스 CLIP 모델은 OVSeg를 비롯한 zero-shot classification, long-tailed recognition, referring segmentation, cross-modal retrieval 다양한 Vision & Language 작업에 활용됨
2.4.Open-Vocabulary Semantic Segmentation (OVSeg)
- Open-vocabulary segmentation : category가 text로 설명돼있는 pixel-level image classification task
- 사전에 정의된 target class 집합을 사용하는 semantic segmentation의 고전적인 정의와 비교할 때, OVSeg의 target class 집합은 open-vocabulary text로 구성되며 반드시 사전 정의될 필요 X
- 다양한 수준의 training supervision을 감안할 때 OVSeg method은 mask-supervised, image-text pair supervised(즉, weakly-supervised) 또는 training-free으로 분류됨
- 이 work는 pretrained neural network들을 이용하여 additional training이 필요 없는 OVSeg에 해당함
- 예를 들어, training-free method 중 하나인 SCLIP은 query의 attention layer와 key cross-similarity을 각 임베딩의 self-similarity으로 대체하여 local region의 homogeneous(동질적인) context에 주목하도록 함
- object에 대한 이해 없이 각 이미지 픽셀을 pixel-text similarity로 directly 분류하는 기존 work과 차별화됨
- 반면, 우리의 method은 text 정보가 없는 상태에서 여러 object를 먼저 identify한 후, 식별된 object에 text entity를 lazy visual grounding 방식으로 할당함
- 또한 training-free method은 MaskFormer segmentation model을 학습시켜 클래스에 구애받지 않는 mask를 얻은 다음 grounding하는 trainable OVSeg method과도 차별점이 있음
3. Lazy Visual Grounding (LaVG)

2 Stages of LaVG
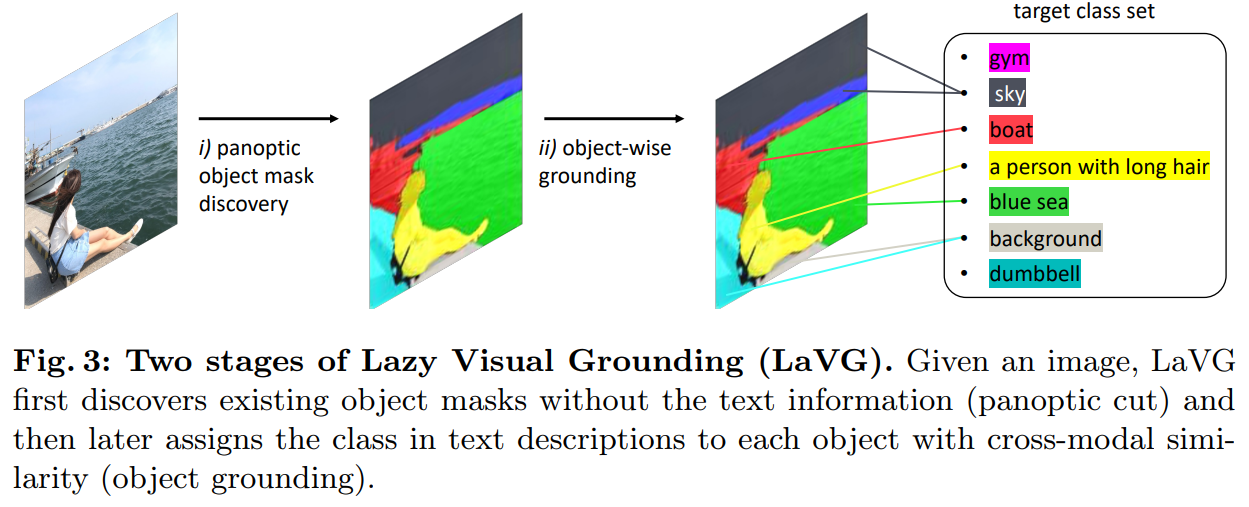
3.1 Panoptic Object Mask Discovery with Normalized Cut
Preliminary: Normalized cut
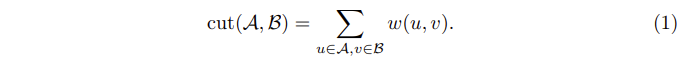
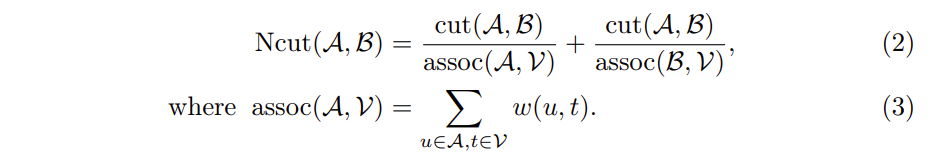

Panoptic cut : unsupervised object mask discovery step
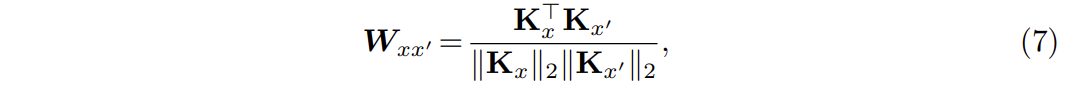
- Normalized cut을 기반으로 한 최근 object discovery work의 아이디어를 따름 => semantic segmentation에 adapt시킴
- DINO ViT의 feature map을 Normalized cut의 input feature로 활용하는 방법을 제시
- panoptic segmentationtask에서 사용되므로 이 unsupervised object mask discovery step = Panoptic cut이라고 불림
3.2 Object Grounding with Class Descriptions in Text
1. Object mask grounding with cross-modal similarity
- image-text multi-modal encoder backbone
- cross-modal similarity 매칭을 통해 각 발견된 마스크에 text entity를 할당
- SCLIP 백본의 patch embedding을 사용하여 각 patch embedding & local image context를 대략적으로 allign
- 주어진 Y개의 텍스트 클래스 집합에서, 텍스트 클래스 설명은 CLIP text encoder에 입력되어 텍스트 임베딩 집합를 얻음
- input image는 SCLIP image encoder에 입력되고, feature map를 return함
- 클래스 분포는 객체 프로토타입과 텍스트 임베딩의 코사인 유사도로 얻어짐
2. Segmentation prediction
predicted object mask = highest cross-modal similarity class index
Qualitive Result
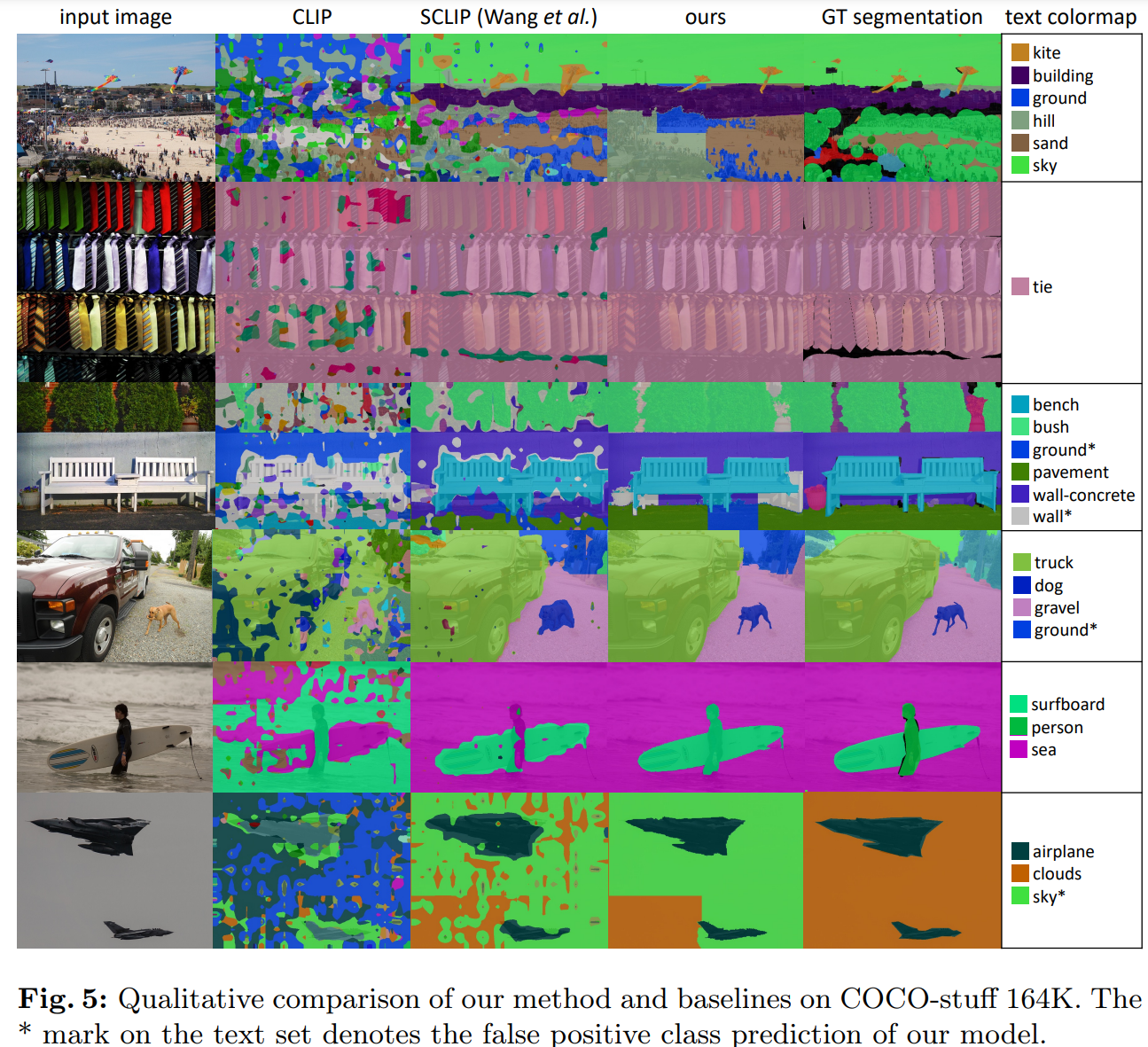
Limitations
4가지 특징적인 한계 가짐
1. 본질적인 문제는 graph-based partitioning algorithm을 활용함으로써 발생하는 광범위한 계산 시간과 메모리 소비
- Normalizaed cut은 일반적으로 N × N 크기의 affinity matrix을 사용하기 때문에 메모리를 과도하게 사용
- e.g. 512 × 512 RGB 이미지에서 Normalizaed cut을 실행하면 메모리 부족 오류가 바로 발생
- DINO attention의 well-abstracted downsampled feature map을 사용하면 메모리 사용량이 크게 줄어들고 단일 일반 GPU 장치(예: Nvidia RTX 3090)에서 원활하게 실행 가능 - inference-only approach이므로 학습 시간이 필요하지 않으며, 학습 모델보다 계산 효율이 더 높음
- 최종 작업 성능 측면에서는 그림 5-6에서 볼 수 있듯이 현저한 Qualitively 향상을 확인할 수 있지만, mIoU 값을 직접적으로 크게 향상시키지는 못함
- 이유 : 평가 지표(mIoU)가 정렬된 가장자리나 깔끔한 물체 모양을 선호하기보다는 픽셀 수준의 분류이기 때문
- 제안된 방법은 때때로 object 자체를 잘못 분류하는 경우가 있어 mIoU 성능에 부정적인 영향을 미침
- sliding-window segmentation inference 기법으로 인해 crop된 영역은 part-whole ambiguity 문제를 겪어 때때로 잘못된 class로 예측됨
- figure 5의 마지막 예에서 정성적으로 관찰 가능
- 이러한 부작용은 텍스처가 없는 영역에서 종종 관찰됨
e.g.) figure 5의 마지막 예에서 모델이 하늘과 구름을 혼동함 - 그러나 이미지 전체를 인식하면 part-whole ambiguity을 해결할 수 있지만, 그와 동시에 저해상도 이미지의 정확도는 떨어짐
- CLIP으로 구현된 out method은 medical / industrial vision과 같은 specialized domain의 closed-vocabulary segmentation에는 부적절할 수 있음
- 그러나 specific domain에서 이러한 문제를 해결하기 위해 lazy grounding 개념은 domain-specific encoder와 함께 사용할 수 있음
이렇게 limitation 부분을 친절히 써놓은 논문은 귀한 것 같다..

안녕하세요😊 컴퓨터비전을 공부하고 있는 대학원생입니다 🙌