0. Abstract
- 모든 분야에서 광범위하게 사용할 수 있는 image segmentation을 위한 모델, 데이터 세트인 SA(Segment Anything) 프로젝트
1. Introduction
목표 : image segmentation의 foundation이 되는 모델을 만들자!
-
목표의 성공 여부는 task, model, data에 달려있음
-
image segmentation에 대해 다음 질문들을 해결하려 함
- 어떤 task가 zero-shot generalization을 가능하게 하는가?
- 해당 model의 architecture는 무엇인가?
- 어떤 data가 이 task와 model을 뒷받침할 수 있는가?
1.1 Task
-
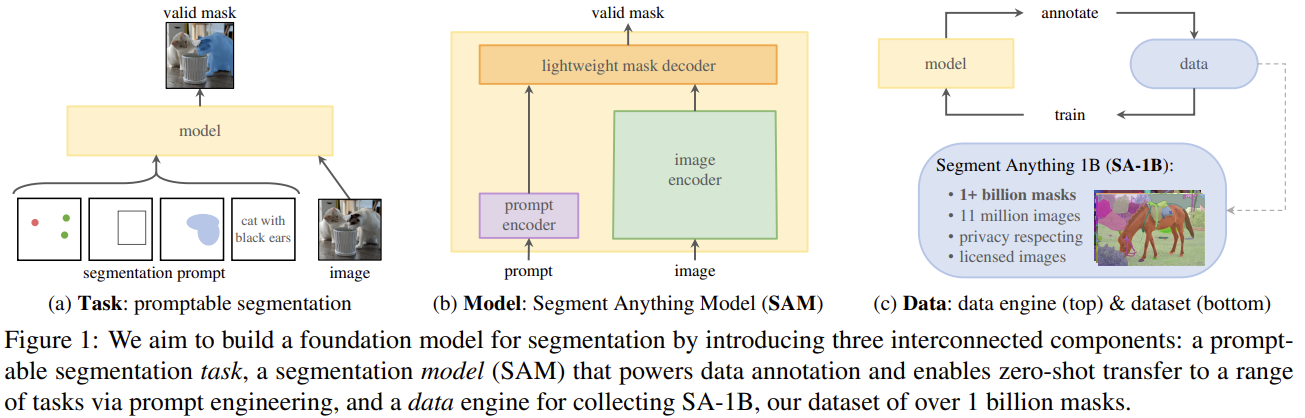
promptable segmentation task : 어느 segmentation prompt가 주어져도 valid segmentation mask를 return하는 것이 목표인 task
-
prompt : image에서 무엇을 segment할 것인지 특정해줌
- prompt는 object를 식별하는 spatial or text 정보를 포함할 수 있음
-
valid output mask : prompt가 모호하거나, 여러 개의 object를 가르키더라도, output은 그 object들 중 최소 1개의 reasonable한 mask가 돼야 한다는 뜻
1.2 Model
Model constraints
- flexible prompt 지원 가능해야함
- 대화형 사용이 가능하도록 실시간으로 mask를 계산해야함
- ambiguity-aware (모호성 인식) 가능해야함
- ex) point on a shirt may indicate either the shirt or the person wearing it)
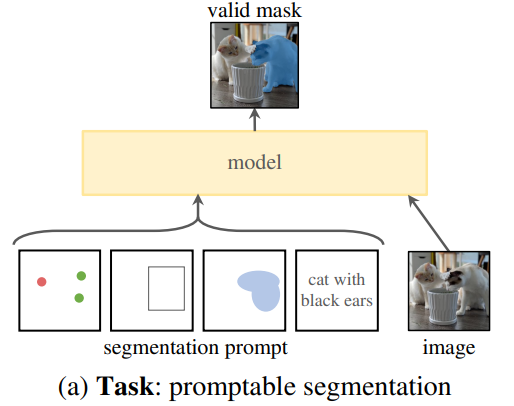
SAM 전체 구조
-
image encoder : image embedding 계산
-
prompt encoder : prompt embedding
=> 두 정보 소스를 lightweight mask decoder에서 결합하여 segmentation mask를 예측 -
image encoder / fast prompt encoder / mask decoder 로 분리하니까, 같은 image embedding이 다른 prompt와 함께 재사용 가능함
-
ambiguity-aware을 위해 single prompt에 대해 multiple mask 예측하도록 함
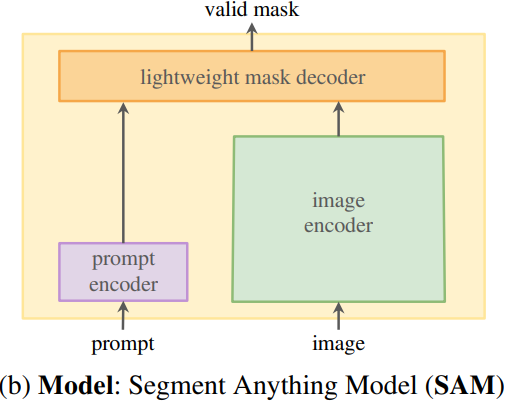
1.3 Data
2. Segment Anything Task
Task
- NLP에서의 prompt 아이디어를 segmentation 상황에 맞춰 생각해보자
- prompt가 될 수 있는 것 : image에서 segment하고 싶은 물체에 대한 어느 정보이던지 괜찮음
- foreground / background points
- a rough box or mask
- free-form text
- NLP와 유사하게 어떤 prompt가 주어져도 valid한 segmentation mask를 return해야함
- valid output mask : prompt가 모호하거나, 여러 개의 object를 가르키더라도, output은 그 object들 중 최소 1개의 reasonable한 mask가 돼야 한다는 뜻
- 이 task는 자연스러운 pre-training 알고리즘으로 이끌고, zero shot을 위한 prompting으로 downstream segmentation 하는 task에 보편적인 방법으로 이어지기 때문에 선정함
Pre-training
- 각 training sample에 대해 prompt의 sequence가 주어짐 (ex: points, boxes, masks)
- model이 예측한 mask와 ground truth mask를 비교함
- interactive segmentation 으로부터 차용한 method 이지만,
interactive segmentation은 충분한 user input 후에 valid mask를 예측하는 것과 달리,
우리는 prompt가 ambiguous한 경우에도 항상 valid mask를 예측하는 게 목표임
zero-shot transfer
- pre-training을 통해서 어떠한 prompt가 오더라도 valid한 마스크를 생성할 수 있는 모델이 있기 때문에, zero-shot transfer가 가능함
- 예를 들어 고양이에 bounding box가 쳐져 있다면, 이를 통해서 별다른 학습 없이 고양이를 segmentation하는 것이 가능
3. Segment Anything Model
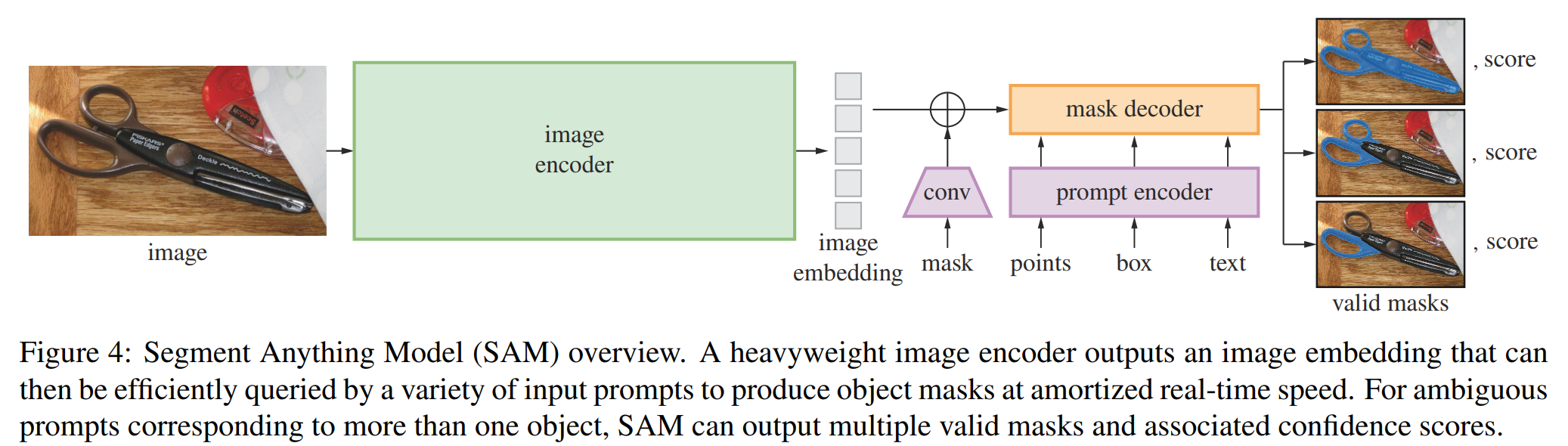
모델의 3가지 구성요소
image encoder + flexible prompt encoder + fast mask decoder
image encoder
- MAE pre-train된 Vision Transformer (ViT) 사용
- image encoder는 image 당 1번 실행됨
prompt encoder
2가지 집합의 prompt 고려
- sparse (points, boxes, text)
- dense (masks)
points and boxes : CLIP의 text encoder를 이용해 각 prompt type & 자유 형식 text에 대해 학습된 embedding들을 합하여 positional encodings으로 표현
mask decoder
-
image embedding & prompt embeddings & output token을 mask에 효과적으로 매핑시키는 역할
-
Transformer decoder block을 수정하여 dynamic mask prediction head를 사용함
-
수정된 decoder block은 모든 embedding들을 update하기 위해, prompt-to-image와 image-to-prompt로 양방향으로 prompt self-attention and cross-attention을 수행함
-
두 block을 실행한 후 image embedding을 upsample하고,
MLP가 output token을 dynamic linear classifier에 매핑한 뒤,
각 image 위치에서 mask foreground probability를 계산함
모델의 설정
Resolving ambiguity
- ambiguous prompt가 주어지면, 여러 개의 valid mask를 평균내어 1개의 output을 만들어냄
- 모델이 single prompt에 대해 여러 개의 output mask를 예측하도록 수정함
- 대게의 상황에서 3개의 mask output가 충분하더라 (whole / part / subpart)
- mask를 랭킹하기 위해 각 mask에 대한 confidence score (i.e., estimated IoU)를 예측함

- ex) green point : 유저가 클릭한 곳 - 3가지로 유추 가능 (벽 전체 / zurich / z)
=> 이 중 1개는 반드시 유저의 실제 의도와 일치해야함
Efficiency
- 미리 계산된 image embedding에 대해서 prompt encoder와 mask decoder가 돌아가는 것은 50ms 이내에 가능함
- 이것은 real-time interactive prompting이 가능한 수준
Losses & training
- Focal loss와 Dice loss를 linear하게 합쳐서 사용
Experimental Results: Zero-shot Transfer
- 5개의 하위 task (edge detection, segment everything, object proposal generation, segment detected objects, segment objects from free-form text 포함) 로 zero-shot transfer를 하여 SAM의 성능을 보여주는 실험 결과 섹션
- 모든 결과는 아래와 같이 SA-1B와 다른 distribution을 가진 새로운 데이터셋에 대해서 평가
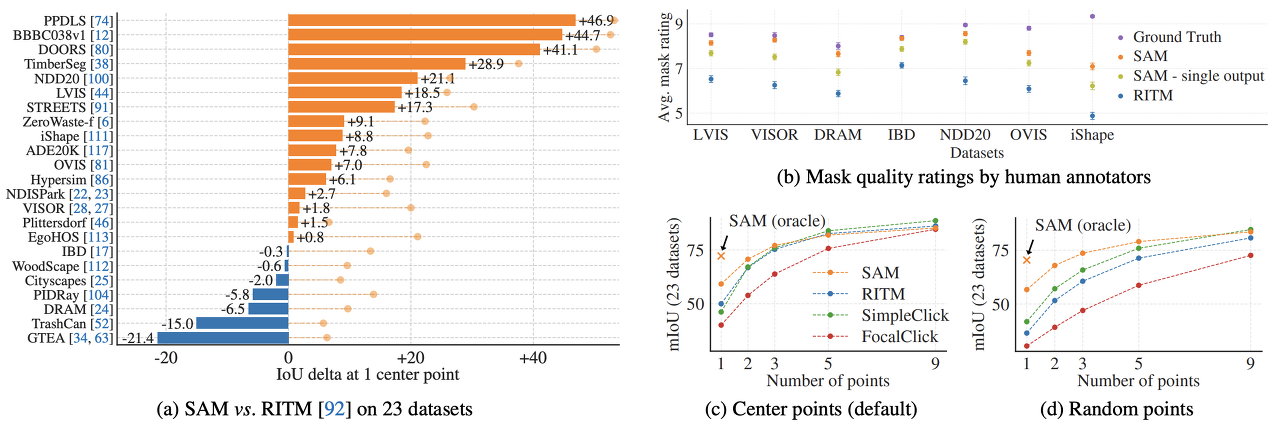
(1) Single Point Valid Mask Evaluation
- Task: foreground에 해당하는 곳의 중점만 prompt로 주어졌을 때 foreground segmentation mask를 추출해 내는 것.
- Result (Compare with RITM model)
- 23개의 데이터셋중 16개에서 RITM보다 높은 성능을 보임
- (b)에서는 사람이 정성적 평가한 결과를 보여주고 있다. 몇몇 데이터셋에서는 정량적 평가에서는 RITM보다 낮았지만, 정성적 평가에서는 더 높은 결과를 보이기도 한다.
- (c), (d)에서는 prompt로 주는 점의 개수를 달리할 때의 결과. 개수가 많아질수록 그 차이가 적어지지만 점이 개수가 적을 때는 SAM이 월등한 성적을 보임.
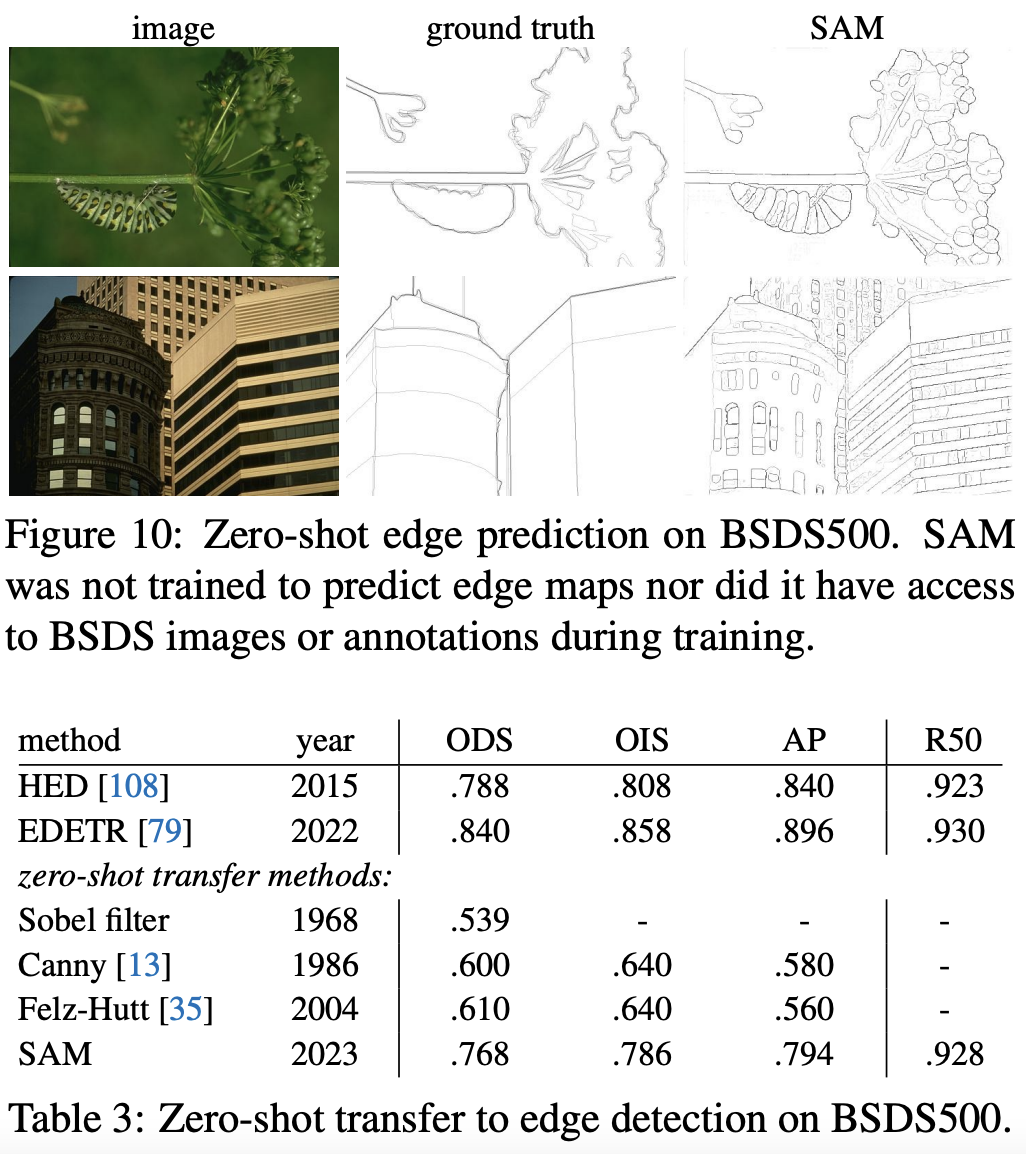
(2) Zero-Shot Edge Detection
- Approach: 전체 이미지에 대해서 segmentation을 진행한 결과에서 Sobel Filter를 써서 edge만 뽑아낼 수 있었음
- Result: Edge Detection에 대해서는 전혀 학습시키지 않았음에도 불구하고 준수한 성능을 보임.
SAM보다 좋은 성능을 낸 모델들은 테스트 데이터셋인 BSDS500의 트레이닝 데이터셋으로 학습된 것임을 감안하면, 아주 좋은 성능이라고 말함.
(3) Zero-Shot Object Proposals
- Approach: Object Detection에서 중요한 object proposal을 뽑아내는 성능을 평가하기 위해 output을 mask로 뽑아내는 pipeline대신 box를 뽑아내도록 zero-shot transfer 했다고 한다.
- Result
- ViTDet-H와 비교해 보면, 전반적으로 ViTDet이 더 좋은 성능을 보이긴 함
- 하지만 SAM이 rare한 케이스에서는 더 좋은 성능을 보이기도 하는 등 준수한 성능을 보인다
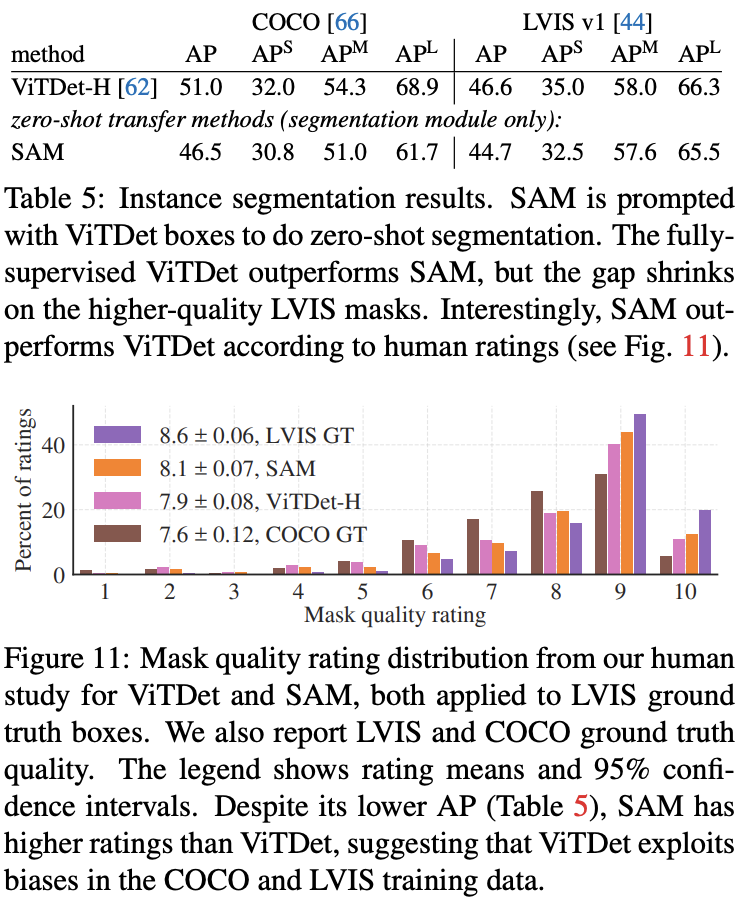
4) Zero-Shot Instance Segmentation
- Approach: 간단하게 위에서 얻은 proposal을 box prompt로 가지고 segmenation을 진행한 결과
- Result
- ViTDet-H보다 좋지 않은 box로 segmentation을 했음에도 불구하고 segmentation 결과는 비슷하다.
- 사람이 직접 정성적 평가를 했을 때는 더 좋은 경우도 많았다고 한다.
(5) Zero-Shot Text-to-Mask
- Approach: Text prompt를 주기 위해선 새로운 annotation이 필요하므로, 이를 피하기 위해서 CLIP의 이미지 인코더를 사용했다. 학습 시에 이미지 전체에 대해서 뽑아낸 마스크 중 100^2이 넘는 영역에 대해서 CLIP의 이미지 인코더로 뽑아낸 임베딩을 prompt로 주었다고 한다.
- Result
- Inference 시에는 text prompt를 사용하는데, 간단한 'a wheel'같은 것에 대해서는 좋은 성능을 보인다.
- text만 줬을 땐 틀렸던 것들도 point를 같이 주면 잘 해낸다.
