한 줄 정리
untrimmed video에서 action이 어디에 위치하는지, ex) 줄넘기를 하는 영상이라면 영상 내에서 실제로 줄넘기라는 action이 언제 시작 & 종료되는지 그 구간을 예측하는 temporal action localization을 할 때 multi-stage 3D CNN을 도입한 첫 논문
Abstract
- 실생활에서 사용되는 동영상은 일반적으로 unconstrained(제약이 없음) & 여러 action instance와 background scene 또는 기타 activity들의 동영상 콘텐츠를 포함하기 때문에 이 task가 중요함
- 이 까다로운 문제를 해결하기 위해 우리는 3개의 segment-based 3D ConvNet을 통해 temporal action localization에서 deep network의 효과를 활용함
(1) proposal network는 action을 포함할 수 있는 긴 비디오에서 candidate(후보) segments를 식별
(2) classification network는 localization network의 initialization 역할을 하는 one-vs-all action classification model을 학습
(3) localization network는 학습된 classification network를 fine-tune하여 각 action instance를 localize함 - 우리는 temporal overlap(시간적 중복)을 명시적으로 고려하고, 높은 temporal localization accuracy를 달성하기 위해 localization network에 새로운 loss function를 제안함
- 결국 prediction할 땐 proposal network와 localization network만 사용됨
- 2개의 대형 데이터셋(MEXaction2, THUMOS 2014)에서 SOTA 달성
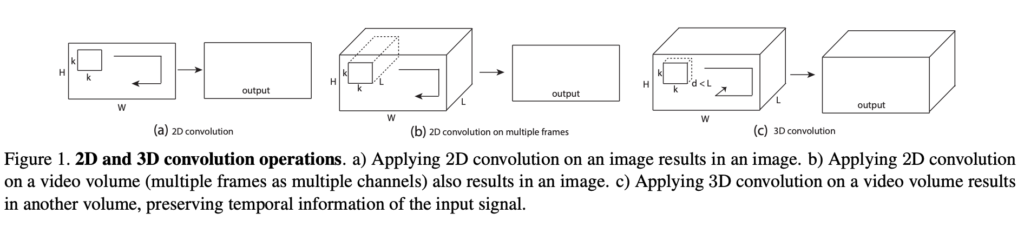
3D Convolution
- video는 frame의 연속임 -> frame과 frame 사이의 연관 관계인 시간 정보, temporal information도 중요하게 작용함
- 이를 위해 3D conv는 시간축으로도 convolution filtering이 진행됨
- 결국 2D에 비해, 3D conv filter는 time에 대한 축이 1개 늘어나게 되고, frame 간의 정보를 받아오게 됨
3D Convolution vs. 2D Convolution
2D Convolution
-
input data = (3 , 16 , 171 , 128) => 3 channel (RGB), 16 frame, resolution=171 x 128
-
convolution filter dimension = (16, 3, 3)
=> depth = 16, kernel size = 3 x 3 -
2D convolution을 적용하면, 16개 frame에 대해 한꺼번에 연산 진행됨
=> frame 간의 temporal feature를 효과적으로 추출 불가능
3D Convolution
-
input data = (3 , 16 , 171 , 128) => 3 channel (RGB), 16 frame, resolution=171 x 128
-
convolution filter dimension = (3, 3, 3)
=> depth = 3, kernel size = 3 x 3 -
3D convolution을 적용하면, 16개 frame을 3개씩 살펴보면서(depth = 3), frame 방향으로도 stride 연산이 진행됨
(그림 (c) 참고)
2D conv는 multiple frame에 대해 적용해주면, 2D 형식의 feature map이 생성되면서 temporal information을 읽게 되지만,
3D conv는 multiple frame에 대해 적용해주면, 3D 형식의 volume을 가지는 featurem map이 생성되면서 temporal information 유지하게 됨
=> video에선 spatio-temporal(시공간적) feature 추출하기 위해 3D conv 사용함!
2. Related work
Temporal action localization
이 주제는 2가지 방향으로 연구됨
1. training data에 video-level category label만 있고 temporal annotation이 없는 경우
- 이를 weakly supervised problem 또는 multiple instance learning problem으로 공식화하여 untrimmed video에서 key evidence를 학습하고 key instance를 선택하여 action을 temporally localize함.
- 웹 이미지에서 지식을 이전하여 트림되지 않은 웹 비디오의 시간적 위치 측정을 해결했습니다.
- THUMOS처럼 untrimmed video의 action instance에 대해 temporal boundaries가 annotated 된 데이터로부터 학습하는 데 중점을 둠
- 이러한 작업의 대부분은 이를 classification problem로 제기하고 각 window을 분류 대상 action candidate로 간주하는 temporal sliding window approach을 채택
- 최근에는 2가지 방향이 SOTA을 주도하고 있습니다.
- (1) 밀집된 trajectories을 따라 HOG, HOF, MBH feature을 추출할 것을 제안했고, 이후에는 카메라 움직임을 고려했습니다.
- 여러 time skip으로 feature을 쌓으면 더 많은 개선을 이룰 수 있음
3. Detailed descriptions of Segment-CNN
3.1. Problem setup
Problem definition
input video
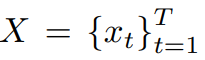
- T : 비디오 X의 전체 프레임 개수
temporal action annotation
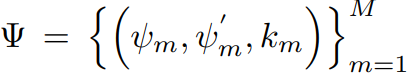
- M : 비디오 X안에 있는 action instance들의 전체 개수
- ψ_m = m 번째 action의 시작 시간
- ψ'_m = m 번째 action의 종료 시간
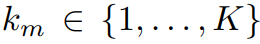
- k_m = m 번째 action의 action label
training 시에는 \tau = trimmed video의 집합, \U = untrimmed video의 집합 사용
각 trimmed video 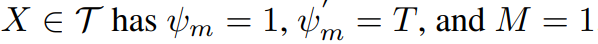
Multi-scale segment generation
input for the proposal network
먼저 각 frame은 171(width) x 128(height)픽셀으로 resize됨
-
untrimmed video에선 75% overlap돼있는 다양한 길이의 temporal sliding windows(16 , 32 , 64 , 128 , 256 , 512 frames)에서 16 frame을 uniformly sampling 해서 segment 구성
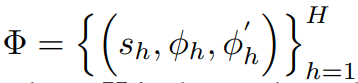
이때 H = untrimmed video에서 segment 개수 -
trimmed video에선 바로 16 frame을 uniformly sampling하여 segment 만듦
=> detection에서 후보군 만들기 위해 하는 방법과 비슷함
3.2. Training procedure
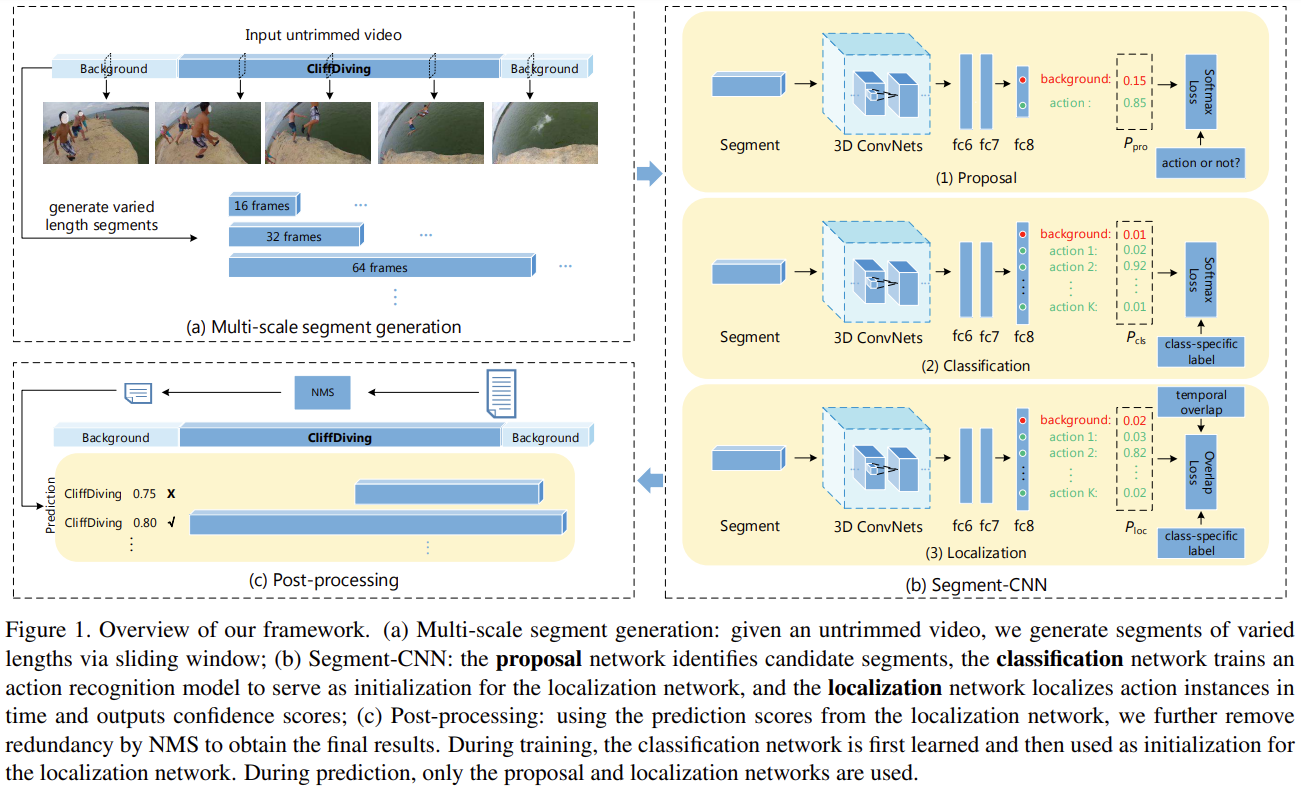
The proposal network
- input으로 들어온 segment들이 foreground(action)인지 background인지 구별하는 역할
- trimmed video로부터 들어온 input이라면 당연히 action만 존재함 => positive한 label 부여
- untrimmed video로부터 들어온 input이라면 groundtruth와 IoU를 측정해서 일정 threshold를 넘기면 action, 넘기지 못하면 background로 label 부여
The classification network
- proposal network에 의해 상당한 background segments가 제거된 이후, classification model을 K개의 action 카테고리에 대해 학습시킴
- 각 segment들을 network에 통과시켜 softmax 처리를 통해, 각 action label이 무엇인지 예측을 수행
- Image Classification의 video 버전이라고 생각하면 됨!
The localization network
- action의 시작과 끝지점을 예측하는 역할
- ground truth와 더 많이 겹치는 segment들의 score를 높이고, 적게 겹치는 segment들의 score를 낮추는 network
bad localization의 예시
- classification network를 통과하고 다음의 3개 segment들이 넘어왔음
- B에 해당하는 segment를 남기고 싶고, A & C는 버리고 싶은 상황
- but 이 상태에서 NMS(Non-Maximum-Suppression) 진행하면, B와 C가 버려짐
=> 따라서 localization network에선 이런 상황을 방지하기 위해, 실제 GT 영역과 더 많이 겹치는 segment들의 score를 더 높여주고, 적게 겹치는 segment들의 score를 낮춰주는 것임

이를 위해 새로운 loss function 정의함
- overlap이 어느 정도인지에 따라 gradient를 update할 수 있는 loss
- input : segment 형식, GT와 얼마나 겹치는지를 나타내는 overlap measurement (v)가 함께 input으로 들어옴
overlap measurement (v)
- trimmed video의 segment : v = 1
- untrimmed video의 segment : v = IoU with Ground Truth
새로운 loss function
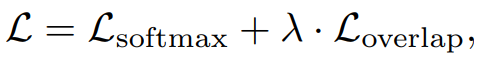
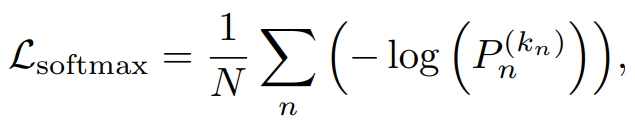
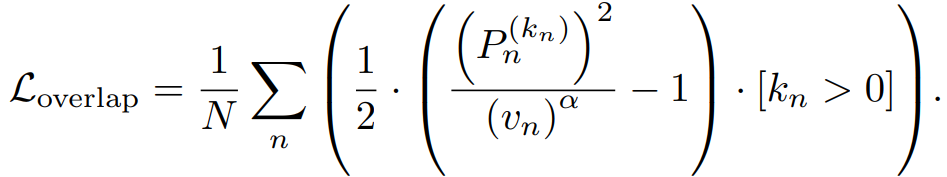
주목해서 봐야 하는 부분은 overlap을 담당해주는 Loss함수
[k_n > 0] 의 의미 : Segment가 action label을 가지고 있다면 1을 할당해주고 , Segment가 Background라면 0을 할당해주는 것
분모에 있는 v_n 값으로 detection Score인 P를 조절함
-
high overlap이라면 Score를 Boost 시켜주고 , low overlap이라면 Score를 Reduce 해줌
-
α 값을 조절하여 score의 강도를 조절해줌
=> 이러한 Loss를 설계함으로써 Overlap에 따른 Score를 할당할 수 있음 -> 이를 통해 Localization Task를 수행
3.3. Prediction and post-processing
