이 연구는 agent가 직접적인 보상 함수를 알지 못해도 인간의 선호 피드백을 기반으로 목표를 학습하도록 하는 방법을 제안한다. 해당 방법의 장점은 아래와 같다.
많은 과제들은 목표가 복잡하거나, 구체적이지 않거나, 명시하기 어렵다. 하지만 강화학습이 성공적으로 확장되어 온 사례는 주로 보상 함수가 명확하게 정의된 분야에 집중되어있었다.
따라서 인간 피드백을 바탕으로 보상 함수를 학습한 다음 그 보상 함수를 최적화하는 방식을 제안한다.
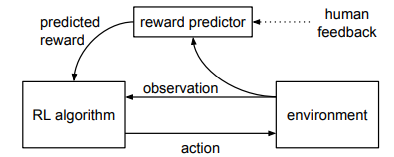
1. 기본 RL 용어 정리
1. Observation
- : 에이전트가 시각, 센서 등 환경에서 받아들이는 정보(관측 값)이다.
- 시점 마다 새로운 를 얻는다.
2. Action
- : 에이전트가 관측 값 에 따라 취하는 행동이다.
- 시점 마다 를 환경에 수행한다.
3. Reward
- (전통적인 RL 기준) : 에이전트가 행동을 취하면 환경이 주는 보상이다.
- 본 논문에서는 보상함수가 아닌 인간의 피드백을 사용한다.
4. Trajectory Segment(σ)$σ
- 에이전트가 연속적인 시간 단계에 걸쳐 수행한 관측-행동 쌍을 묶은 것이고 흔히 history라고 한다.
- 본 논문에서라 하면, 인간이 이라는 궤적을 보다 더 선호한다는 의미이다.
2. 목표
- 전통적인 RL에서는 환경이 보상을 직접 알려주기 때문에 환경에서 (가 주어짐) 에이전트가 이를 최적화하도록 학습한다.
- 본 논문은 보상함수를 모른다고 가정하고, 인간이 trajectory(궤적)을 비교해서 선호를 표시하는 피드백을 통해서 목표를 학습하게 한다.
- 따라서 에이전트는 사람이 선호하는 trajectory(궤적)을 만들어 내도록 학습하는 것이 목표이다.
3. 에이전트 행동에 대한 두 가지의 평가 방법
3.1 Quantitative 평가
- 사람의 선호가 어떤 보상 함수 로 표현된다고 가정하자.
- 예) 라 하면, 식으로, 의 누적 보상이 보다 더 큰 것을 의미한다.
- 이 경우, 보상 함수 만 학습했다면 에이전트가 얻은 누적 보상을 기반으로 정량적인 평가가 가능하다.
3.2 Qualitative 평가
- 때로 사람의 선호를 평가할 적절한 보상함수를 정의하지 못할 수 있다.
예) 사람의 취향 - 이 경우에는 에이전트의 행동이 얼마나 사람이 원하는 목표를 제대로 달성하는가? 하는 정성적인 평가만 가능하다.
4. 기본 구조
1. Policy 𝜋
- 에이전트는 정책 𝜋을 통해서 현재 환경을 관측한 결과에 맞춰 행동 를 결정한다.
- 이 정책 𝜋은 계속해서 학습되면서 업데이트는 강화학습의 핵심이다.
2. 추정 보상 함수
- 논문에서는 보상함수를 모른다고 가정하고, Deep Neural Network를 이용해서 를 학습한다.
- 의 파라미터(가중치)는 인간 피드백을 기반으로 갱신된다.
5. 진행 과정
5.1 Trajectory 생성
- 에이전트가 현재 정책 𝜋을 사용해서 환경에서 움직이며 여러 개의 trajectory (𝜏_1,𝜏_2,𝜏_3,𝜏_4,𝜏_5, ... 𝜏_i) 를 생성한다.
- 각각의 trajectory는 관측 행동 쌍 의 연속이며, 일정 길이로 묶어서 segment(궤적 조각)형태로 사용된다.
5.2 인간 피드백 수집
- 만들어진 trajectory 들에서 segment 쌍 을 뽑아서 “가 더 좋다”, “가 더 좋다”, 혹은 “동등하다” 등으로 피드백을 주고 받을 수 있다.
5.3 보상함수 업데이트
- 예를 들어 사람이 을 보다 선호한다고 했다면, 가 되도록 를 학습한다.
핵심은 이 세 과정이 비동기적으로 진행된다는 점이다. 각 단계가 순서대로 진행되는 것이 아니라, 병렬 또는 분산되어 돌아간다. 즉, 여러 agent가 동시에 데이터를 수집하고, 그 중 일부를 사람이 피드백하는 구조가 흔히 사용된다.
- 128개 워커 에이전트가 동시에 환경을 플레이함.
- 중앙 서버가 이들이 전송한 짧은 클립(trajectory)들을 저장하고, 일정 규칙(무작위, 다양성 보장 등)에 따라 샘플 추출.
- 사람이 웹 UI로 들어가면, 클립 쌍(또는 N개)을 보고 선호 투표를 함.
- 투표 결과가 서버로 전송 → 보상 함수 모델 업데이트.
- 업데이트된 보상 함수가 다시 128개 워커에게 브로드캐스트됨.
- 워커들은 새로운 보상에 맞춰 정책을 학습하거나 행동을 조정.
- 이 과정이 계속 비동기로 반복.
즉, 한 사람만 있어도 여러 에이전트가 추출한 클립 중 일부를 보고 선호 투표를 하면 이 보상 함수 모델이 엡데이트 된다는 것이다.
5.3.1 보상함수를 업데이트 하는 구체적인 방식
보상 함수를 업데이트 하는 방식에 대해서 말하자면, 정책 경사법(Policy Gradient) 계열의 알고리즘과 보상 정규화를 사용한다는 것이다.
이는 Non-stationary(비정상적인) 보상 때문이다.
1. 왜 보상이 비정상적인가?
- 전통적인 강화학습에서는 같은 상황에서 같은 행동을 하면 동일한 보상이 온다.
- 하지만 이 논문에서는 사람이 새로운 피드백(선호)을 줄 때마다 보상 함수 자체가 갱신된다.
2. 이게 왜 문제인가?
- RL 알고리즘은 보상을 기준으로 정책을 학습한다
- 하지만 보상 함수가 계속 변하면 알맞은 정책을 찾으려 할 때 혼란이 생긴다.
예) 어제는 특정 행동이 에서 5점을 받았는데, 오늘은 그 행동이 2점만 받거나 혹은 10점을 받을 수 있다. - 이처럼 보상이 고정되지 않고 계속 바뀌는 것을 Non stationary 하다고 부른다.
3. 이를 어떻게 해결하나?
- 보상이 변하더라도 민감하게 요동치지 않는 견고한 방법이 필요하다.
- 따라서 정책 경사법과 보상 정규화를 사용한다.
