이 논문을 왜 읽었나?
원하는 음악을 잘 표현할 수 있는 텍스트를 뽑는 방법이 궁금했기 때문
- 모델을 사용해서 classify 하는 방법이 좋을까?
- LLM prompt chaining을 하는 방법이 좋을까?
최근 멀티모달 생성 모델이 텍스트에서 이미지 또는 비디오로의 변환에서 큰 성과를 이루었으나, 텍스트에서 오디오로의 변환은 여전히 부족한 실정이다.
이 이유로는 크게 두 가지로 나눌 수 있다.
1. 고품질 텍스트-오디오 데이터셋의 부족
2. 길고 연속적인 오디오 데이터를 모델링하는 복잡성
👉 이를 해결하고자 Make-An-Audio라는 모델을 만들었는데 이 모델의 핵심 아이디어는, 언어가 없는 오디오(예를 들어, 사람이 말하지 않은 단순한 소리나 음악 등)에 대해 언어적인 설명(즉, 관련된 자연어 텍스트)을 생성할 수 있도록 하여, 오디오와 관련된 텍스트가 부족한 상황을 해결하려는 것이다.
1. 프롬프트 강화(pseudo prompt enhancement)
언어가 없는 오디오를 활용하여 언어 기반의 오디오와 잘 맞는 자연어를 생성하는 방식이다.
1.1 Expert Distillation
오디오 캡션 생성 모델과 오디오 텍스트 검색 모델을 활용하여 프롬프트를 생성하는 방식이다.
1.1.1 오디오 캡션 생성
이 모델은 주어진 오디오 클립에 대해 다양한 자연어 문장을 생성하여 오디오의 내용을 설명한다. 예를 들어 오디오에 비가 내리는 소리가 있다면 "비가 내린다"라는 문장을 생성하는 것이다.
1.1.2 오디오-텍스트 검색
이 모델은 자연어 텍스트를 쿼리로 사용해서 데이터 베이스에서 관련된 오디오 파일을 검색한다. 예를 들어, 비오는 소리를 검색하면 이에 맞는 오디오 파일을 찾아주는 식이다.
- 이 두 가지는 공동으로 distill하여 오디오에 잘 맞는 캡션(설명)을 생성한다.
- 생성된 후보 캡션들 중에서 CLAP(Constrastive Language-Audio Pretraining) 점수가 높은 캡션을 사용한다. (CLAP 점수는 텍스트와 오디오의 일치 정도를 나타낸다)
1.2 Dynamic Reprogramming
2. 텍스트 표현
텍스트 유도 합성(Text-guided synthesis) 모델은 자연어 입력의 의미를 잘 파악할 수 있는 강력한 텍스트 인코더가 필요하다.
2.1 Constrastive Pretraining
- CLIP 처럼 이미지-텍스트 데이터에 대해서 사전 훈련된 모델이 텍스트와 이미지를 연결하여 공동공간(joint space)에 매핑하는 방법이다. 최근에는 CLAP 기법이 발전하면서 zero-shot generalization을 통해 좋은 성과를 보였다.
2.2 대규모 언어 모델링(LLM)
- BERT, T5와 같은 언어 모델을 사용해서 텍스트 유도 생성을 수행하는 것이다. 이 모델들은 텍스트 전용 데이터로 훈련이 되고, 훈련에 사용되는 데이터의 양이 다양한 멀티 모달 데이터보다 크다. 텍스트의 분포를 풍부하게 학습 할 수 있다.
Make-An-Audio에서는 일반적인 방법처럼, 텍스트 인코더의 가중치를 고정(freeze)시킵니다. 이 실험에서 CLAP과 T5-Large를 사용하여 성능을 비교한 결과, 두 모델 모두 벤치마크 평가에서 비슷한 성과를 보였지만, CLAP이 LLM에서 요구하는 임베딩 계산을 오프라인에서 하지 않아 더 효율적이라고 판단했다.
3. 오디오 표현
3.1스펙토그램 오토인코더(spectogram autoencoder)
기존의 오디오 생성모델은 waveform을 예측하는 방식이였는데, Make-An-Audio는 스펙토그램을 예측하는 오토인코더를 사용해서 자기지도학습을 통해 오디오의 특성을 파악한다.
- 스펙토그램이란?
스펙토그램은 오디오 신호를 2차원의 추파수 영역에서 나타낸 것이다. 가로축이 시간, 세로축이 주파수의 형태가 되는 것으로, 각 시간 구간에서 어떤 주파수 성분이 얼마나 포함이 되어있는지를 보여준다. - 스펙트로그램은 시간과 주파수에 따른 에너지 분포를 2D 형태로 보여주기 때문에 2D 이미지처럼 처리될 수 있으며, 컴퓨터 비전이나 신경망 모델이 다루기 쉬운 형태이다.
- 자기 지도 학습은 라벨이 없는 데이터를 통해서 모델을 학습 시키는 방법임을 알고 있을텐데, 오디오의 경우 스펙토그램을 예측하게 된다.
- 이 모델은 주어진 스펙토그램에서 다음에 올 스펙토그램을 예측하는 방식으로 동작한다.
즉, Make-An-Audio는 스펙트로그램 오토인코더를 활용하여 오디오 데이터를 자기 지도 학습 방식으로 모델링한다. 이 방식은 긴 연속적인 파형을 모델링하는 어려움을 해결하고, 고수준의 의미적 이해를 보장합니다. 스펙트로그램을 사용하면 오디오의 주파수 성분을 효율적으로 압축하여 다룰 수
4. X-to-Audio
모든 입력 모달리티에 대해 오디오를 생성할 수 있도록 한다.
5. 평가 지표
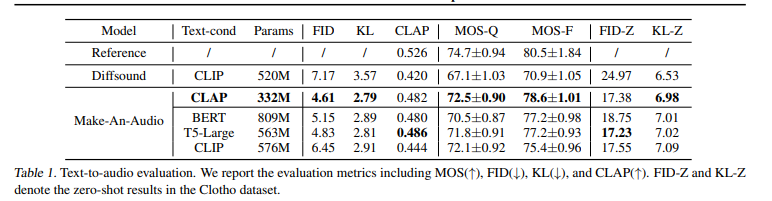
5.1 MOS (Mean Opinion Score)
MOS-Q: 오디오의 품질을 평가하는 지표로, 일반적으로 주관적인 평가를 기반으로 오디오의 자연스러움, 선명도 등을 측정한다. 값이 클수록 더 나은 품질을 의미
MOS-F: 오디오의 정확성을 평가하는 지표로, 텍스트 설명에 대해 얼마나 충실하게 오디오를 생성했는지를 측정한다. 이 값이 클수록 텍스트에 맞는 오디오 생성이 잘 이루어졌다는 것을 의미
5.2 FID (Fréchet Inception Distance)
FID는 생성된 오디오와 실제 오디오의 유사도를 측정하는 지표이다. 이 값이 낮을수록 생성된 오디오가 실제 오디오와 더 비슷하다는 것을 의미한다. 즉, 값이 낮을수록 더 정확한 생성이 이루어졌음을 나타낸다.
5.3 KL (Kullback-Leibler Divergence)
KL 발산은 생성된 오디오 분포와 실제 오디오 분포 간의 차이를 측정하는 지표이다. 이 값이 낮을수록 생성된 오디오가 실제 오디오와 유사한 분포를 가짐
5.4 CLAP (Contrastive Language-Audio Pretraining)
CLAP은 텍스트와 오디오 간의 일치도를 측정하는 지표로, 값이 높을수록 텍스트와 생성된 오디오 간의 일치도가 높다는 것을 의미한다. 즉, 모델이 텍스트 설명을 잘 이해하고 그에 맞는 오디오를 생성한 정도를 나타낸다.
5.5 FID-Z, KL-Z
FID-Z와 KL-Z는 제로샷 방식으로 Clotho 데이터셋에서 측정된 값들로, 특정 모델이 새로운 데이터에 대해 얼마나 잘 일반화되는지를 평가하는 지표이다.
🔥나의 생각
- 원하는 음악을 잘 표현할 수 있는 텍스트를 뽑는 방법
- CLAP (Contrastive Language-Audio Pretraining) 지표를 보면, 텍스트와 오디오 간의 높은 일치도를 달성하는 모델이 중요한 역할을 한다는 것을 알 수 있다. Make-An-Audio가 CLAP에서 좋은 성과를 보인 점은, 텍스트 설명을 음악으로 잘 변환하는 데 필요한 모델 설계에 대한 유용한 참고가 될 수 있다. 즉, 텍스트와 음악의 일치도를 높이는 것이 중요하다.
- T5 모델은 이미 텍스트 조건 생성에서 잘 알려져 있고, 논문에서도 T5-Large와 같은 모델을 사용한 실험 결과가 좋았다. 이는 텍스트를 효과적으로 생성하고 음악에 맞는 텍스트를 뽑는 데 유용할 수 있다는 점에서, T5와 같은 모델을 사용할 때 좋은 선택이 될 수 있다.
