1. 호텔 예약의 취소 여부를 미리 알 수 있을까?
고객들의 예약 취소는 호텔의 오랜 고민거리이다. 특히 아무런 연락 없이 예약 장소에 나타나지 않는 이른바 노쇼(No-Show)는 호텔뿐만 아니라 다른 고객들에게도 피해가 가기 때문에 끊임없이 문제 제기가 되고 있다. 그래서 호텔은 예약 취소로 인한 손실을 줄이고자 실제 객실 수보다 예약을 더 많이 받는 '초과 예약'을 시행하기도 한다. 그러나 만일 예약한 고객들이 다 도착해 객실이 부족하다면 그 피해는 고스란히 고객들에게 가기 때문에 무턱대고 훨씬 더 많은 예약을 받을 수도 없다. 하지만 만일 어떤 예약이 취소될지 미리 알 수 있다면 어떨까? 그럼 객실 운영을 보다 효율적으로 할 수 있지 않을까? 그래서 이번 프로젝트로 호텔 예약의 취소 여부를 판단하는 분류 모델을 만들어보기로 하였다.
1) 사용할 데이터 소개
- Hotel booking demand - From the paper: hotel booking demand datasets
- Jesse Mostipak, Kaggle (Attribution 4.0 International (CC BY 4.0))
"The data is originally from the article Hotel Booking Demand Datasets, written by Nuno Antonio, Ana Almeida, and Luis Nunes for Data in Brief, Volume 22, February 2019.
The data was downloaded and cleaned by Thomas Mock and Antoine Bichat for #TidyTuesday during the week of February 11th, 2020."
데이터셋은 캐글에서 가져왔으며, 원본 데이터셋은 포르투갈의 Algarve와 Lisbon에 있는 두 호텔의 PMS(Property Management System)에서 추출되어 가공되었다고 한다. 데이터셋에는 2015년 7월 1일부터 2017년 8월 31일 사이에 호텔에 도착하는 예약 기록이 있으며, 호텔의 유형, 숙박 날짜, 숙박 기간, 숙박 인원, 선택한 식사의 종류, 예약한 객실의 종류, 그리고 체크인 여부 등 호텔의 예약과 관련된 정보들이 담겨 있다. 다만, 실제 데이터이기 때문에 익명화를 위해서 예약한 여행사와 같은 항목은 이름 대신 숫자 형식의 코드로 제공되었다.
2) 문제 정의
데이터셋을 바탕으로 프로젝트를 위한 가상의 시나리오를 만들어보았다.
"A사 호텔 사업부에는 오랜 고민이 하나 있다. 바로 호텔의 주 고객인 단기 고객의 예약 취소율이 약 40%에 달한다는 점이다. 이렇게 높은 예약 취소율 때문에 A사 호텔 사업부는 객실의 효율적인 사용에 어려움을 겪고 있다. 이 문제를 더는 방치할 수 없다며 열띤 회의에 들어간 호텔 사업부는 단기 고객의 예약이 취소될지 아닐지 알려주는 시스템을 도입하기로 결정했다. 취소될 것으로 예상되는 예약 건에 대해서는 미리 확인 전화를 하고, 해당 예약 건수 만큼만 초과해서 예약을 받는 등 호텔 운영에 시스템을 적극적으로 활용할 계획이다. 이를 위해서 A사는 사내 데이터 분석팀에게 단기 고객의 각각의 예약이 취소될지 안 될지 판단하는 분류 모델을 만들라고 지시하였다. 모델 생성을 위해서 데이터 분석팀은 호텔 사업부에게 숙박 날짜, 숙박 기간, 숙박 인원, 예약한 객실의 종류 등 호텔 예약과 관련한 데이터를 제공받았다."
자, 지금부터 우리는 A사 데이터 분석팀의 데이터 사이언티스트이다. 우리가 해결해야 할 문제는 단기 고객의 각 예약이 취소될지 아닐지 판단하는 모델을 만드는 것이다. 즉, 각 예약을 '취소된다', '취소되지 않는다' 두 개의 클래스로 분류하는 이진 분류 문제이다. 그리고 타겟은 호텔 예약의 취소 여부이며, 0은 예약이 취소되지 않는 것을, 1은 예약이 취소되는 것을 말한다.
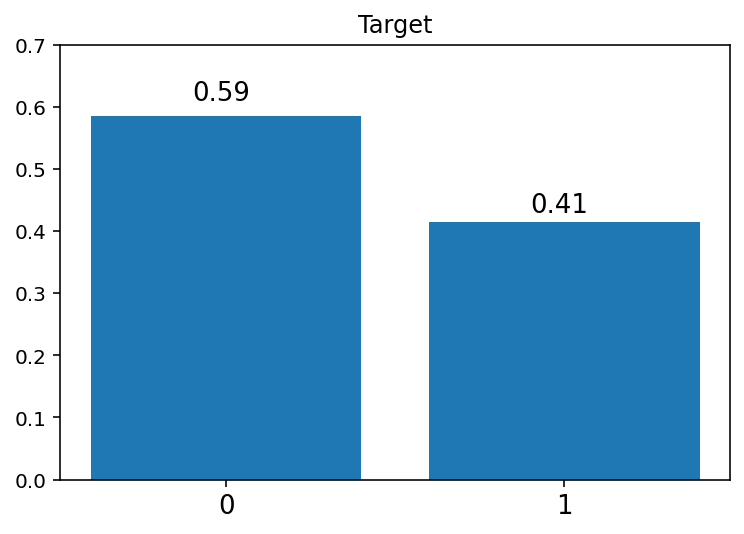
사용할 평가지표와 기준 모델을 정하기 위해서 위와 같이 타겟의 분포를 시각화하였다. 그림을 통해 알 수 있듯이, 0과 1이 약 6:4로 꽤 고르게 분포되어 있다. 따라서 모델의 성능을 평가할 지표로 정확도(Accuracy)를 사용하기로 하였다. 그리고 우리의 기준 모델은 데이터를 모두 최빈 클래스인 0, 즉 모든 예약이 취소되지 않을 것이라고 예측하는 것으로, 정확도는 약 0.59이다. 따라서 앞으로 우리가 만들 모델은 정확도가 약 0.59보다 높아야 학습이 잘 된 모델이라고 말할 수 있다.
2. 데이터 전처리
우선 '단기 고객의 예약 취소 여부 판단'이라는 문제에 맞게, 데이터셋에서 고객 유형(customer_type)이 단기 고객(Transient)인 것만 선택하였다. 그리고 이 데이터들을 대상으로 전처리를 진행하였다.
1) 결측치 처리
- 고객의 국적이 결측치인 기록: 삭제
- 예약한 여행사와 회사가 결측치인 기록: 'N/A'로 변경
전체 31개의 항목 중에서 결측치가 있는 항목은 고객의 국적(country), 예약을 한 여행사의 코드(agent), 그리고 호텔을 예약하거나 비용을 지불할 책임이 있는 회사의 코드(company) 총 3개였다. 먼저, 고객의 국적이 결측치인 기록은 총 439개로, 전체 기록의 약 0.5%이다. 결측치의 수가 1%도 되지 않기 때문에 이 기록들은 제거하기로 하였다. 그리고 예약한 여행사의 코드가 결측치인 기록은 총 11,729개이고 호텔을 예약하거나 비용을 지불할 책임이 있는 회사의 코드가 결측치인 기록은 총 85,461개였다. 그런데 여행사 또는 회사 코드가 NaN인 것은 기록이 누락되었다기보다는 개인이 여행사를 거치지 않고 직접 예약한 경우처럼 여행사 또는 회사와 관련이 없는 예약 건이라 입력될 여행사와 회사 코드가 없어서 NaN이라고 기재된 것일 가능성이 높다. 따라서 여행사 코드나 회사 코드가 NaN인 기록은 제거하지 않고 NaN을 'N/A'로 변경하였다.
2) 이상치 처리
- 총 숙박 일수가 1박 미만인 기록: 삭제
- 하루 평균 숙박 비용이 0원인 기록: 삭제
lead_time,babies,adr이 최댓값인 기록: 삭제
보통 호텔의 예약 단위는 '일'이기 때문에 최소 1박 이상 할 수 밖에 없다. 따라서 총 숙박 일수가 1박 미만인 기록은 이상치로 보고 제거하였다. 또한 하루 평균 숙박 비용(adr)이 0인 기록들이 있었다. 그런데 하루 평균 숙박 비용이 0이라는 건 호텔을 무료로 이용했다는 뜻이다. 이러한 경우는 기록이 누락되어 발생한 결측치이거나, 아니면 이벤트나 보상과 같은 특별한 사유 때문에 실제로 발생한 기록일 수도 있다. 그러나 어떠한 경우이든 하루 평균 숙박 비용이 0원인 건 일반적인 일은 아니므로 이상치로 보고 제거하기로 하였다.
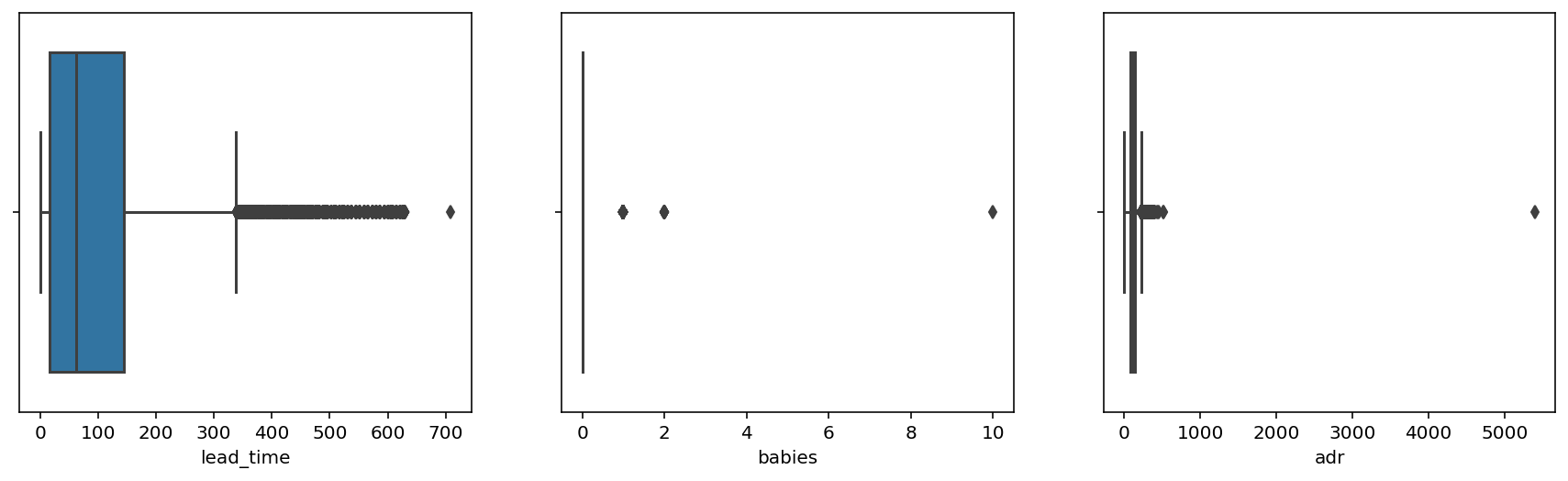
위 그림은 예약일과 숙박일 사이의 기간(lead_time), 투숙객 중 아기의 인원수(babies), 그리고 하루 평균 숙박 비용(adr)에 대한 box plot이다. 그림을 보면 세 항목 모두 가장 오른쪽 검은 점 하나가 홀로 동떨어져 위치하고 있다. 이렇게 이 세 항목은 최댓값과 다른 값들의 차이가 매우 컸다. 따라서 세 항목의 최댓값을 이상치로 보고 해당하는 기록을 삭제하였다.
3) 정보 누수 제거
reservation_status(마지막 예약 상태: Check-Out, Canceled, No-Show)reservation_status_date(마지막 예약 상태가 입력된 날짜)assigned_room_type(각 예약에 배정된 객실 정보)
정확한 모델을 만들기 위해서는 정보가 누수된 특성을 꼭 제거해야 한다. 정보 누수가 발생한 채로 학습을 하는 건 답을 미리 알려주고 시험을 보게 하는 것과 같기 때문이다. 답을 미리 알고 시험을 본다면 해당 시험은 잘 봐도 문제가 바뀌면 답을 하나도 맞추지 못한다. 데이터셋에는 reservation_status라는 항목이 있었다. 마지막 예약 상태에 대한 정보를 담고 있는 항목으로, 값에는 Check-Out, Canceled, No-Show가 있다. 값을 보면 알 수 있듯이, 이 항목을 통해서 예약이 취소 되었는지 아닌지 알 수 있다. 즉, 정보가 누수된 항목이다. 따라서 이 항목을 제거하였다. 그리고 마지막 예약 상태가 입력된 날짜(reservation_status)를 통해서도 예약이 취소되었는지 아닌지 유추할 수 있으므로 이 항목 또한 제거하였다. 또 각 예약에 배정된 객실 정보(assigned_room_type)는 숙박 당일에 초과 예약 때문에 예약했던 객실과 다른 객실이 배정되는 경우가 있으므로 정보 누수가 일부 있을 수 있다고 판단하여 제거하기로 하였다.
이 외에도 feature engineering을 통해서 특성을 만들고 불필요한 특성은 제거하는 작업을 수행하였다. 전처리 결과 최종적으로 생성된 데이터셋은 아래와 같은 컬럼을 가지고 있다. 컬럼은 총 30개로, 1개의 타겟과 29개의 특성이 있다.
사용한 데이터 프레임의 컬럼 목록
| 컬럼명 | 설명 | 데이터 유형 | 특이사항 |
|---|---|---|---|
| hotel | 호텔의 종류 | object | |
| is_canceled | 예약의 취소 여부 | binary | target |
| lead_time | 예약일과 숙박일 사이의 기간 | int | |
| arrival_date_month | 호텔 숙박 시작일 중 월(MM) | int | |
| arrival_date_day_of_month | 호텔 숙박 시작일 중 일(DD) | int | |
| stays_in_weekend_nights | 주말 숙박 일수 | int | |
| stays_in_week_nights | 평일 숙박 일수 | int | |
| adults | 투숙객 중 성인의 인원수 | int | |
| children | 투숙객 중 아동의 인원수 | int | |
| babies | 투숙객 중 아기의 인원수 | int | |
| meal | 고객이 예약한 식사 유형 | object | |
| country | 고객의 국적 | object | |
| market_segment | 마켓 세그먼트 | object | |
| distribution_channel | 유통 경로 | object | |
| is_repeated_guest | 재방문 여부 | binary | |
| previous_cancellations | 이전 예약 건 중에 취소된 예약 건의 수 | int | |
| previous_bookings_not_canceled | 이전 예약 건 중에 취소되지 않은 예약 건의 수 | int | |
| reserved_room_type | 예약한 객실 유형 | object | |
| booking_changes | 예약일 이후로 예약 내용이 수정된 횟수 | int | |
| deposit_type | 보증금 유형 | object | |
| agent | 예약한 여행사 | object | |
| company | 예약을 하거나 비융 지불 책임이 있는 회사 | object | |
| days_in_waiting_list | 예약일과 고객 확인일 사이의 기간 | int | |
| adr | 하루 평균 숙박 비용 | float | |
| required_car_parking_spaces | 요청한 주차공간의 수 | int | |
| total_of_special_requests | 특별 요청의 수 | int | |
| total_number_of_staying_nights | 총 숙박 일수 | int | |
| arrival_day | 호텔 숙박 시작 요일 | object | 새로 생성 |
| is_special_requests | 특별 요청의 유무 | binary | 새로 생성 |
| is_previous_cancellations | 이전 예약의 취소 유무 | binary | 새로 생성 |
3. EDA
모델을 만들기 전에 간단하게 EDA를 해보았다. 만약 어떤 특성에서 취소된 예약 건과 취소되지 않은 예약 건의 분포에 차이가 있다면, 해당 특성은 각 예약이 취소될지 취소가 되지 않을지 예측하는데 데 도움이 되므로 분류 모델에서도 중요도가 높을 것이다. 따라서 각 특성과 타겟의 관계에 대해서 시각화하며 특성들의 특징을 파악하였다.
총 29개의 특성 중에서 분류 모델에서 중요하게 사용될 수 있을 것 같은 특성 2개와 중요하지 않을 것 같은 특성 2개의 EDA 결과만 소개하려고 한다. 모든 그림에서 취소된 예약은 주황색으로, 취소되지 않은 예약은 파란색으로 표현되었다.
- 예약일과 숙박일 사이의 기간(
lead_time)
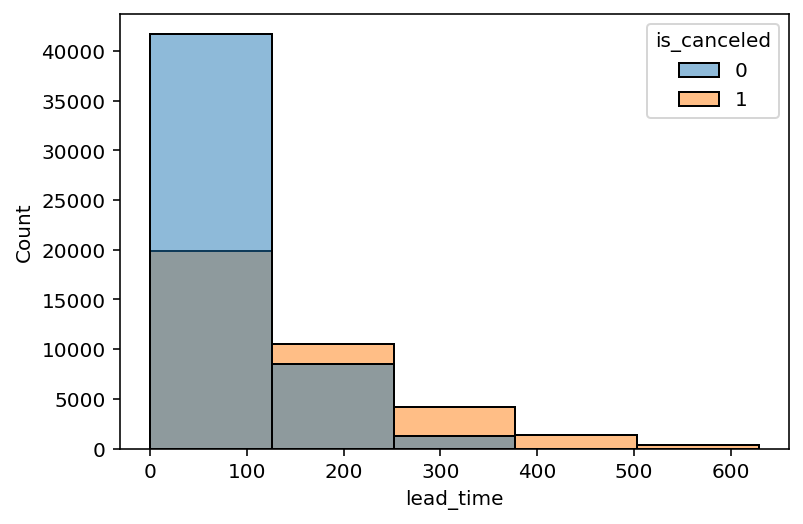
위 그림은 취소된 예약과 취소되지 않은 예약의 예약일과 숙박일 사이의 기간(lead_time)에 대한 히스토그램이다. 그림을 보면 알 수 있듯이, 파란색과 주황색의 분포에 차이가 있다. 예약일과 숙박일 사이의 기간이 길수록 주황색, 즉 예약을 취소한 경우가 많았다.
- 요청한 주차공간의 수(
required_car_parking_spaces)
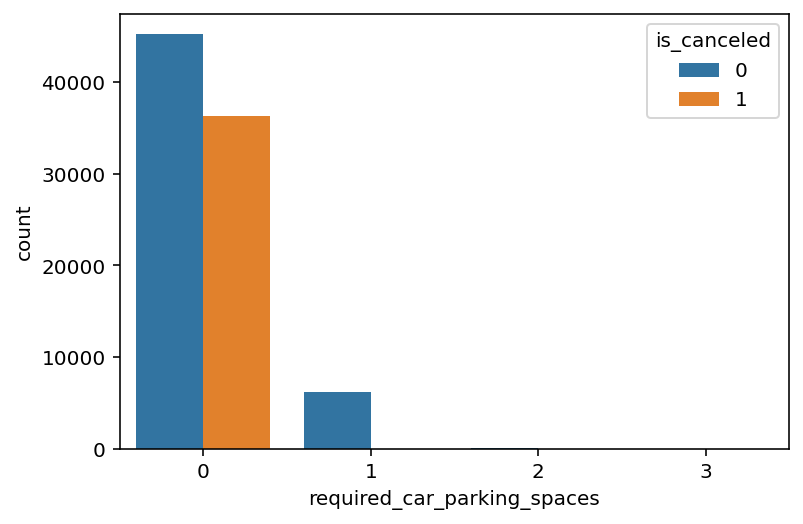
위와 같이 요청한 주차공간의 수와 예약의 취소 여부를 시각화했더니, 요청한 주차공간이 0개일 때만 취소된 예약 건이 있음을 알 수 있었다.
위 두 특성은 취소된 예약과 취소되지 않은 예약의 분포에 확연한 차이가 있었다. 따라서 이 두 특성을 사용하면 각 예약이 취소될지 취소되지 않을지 분류할 수 있으므로 모델에서도 중요도가 높을 것이라고 추측할 수 있다.
- 예약한 객실 유형(
reserved_room_type)
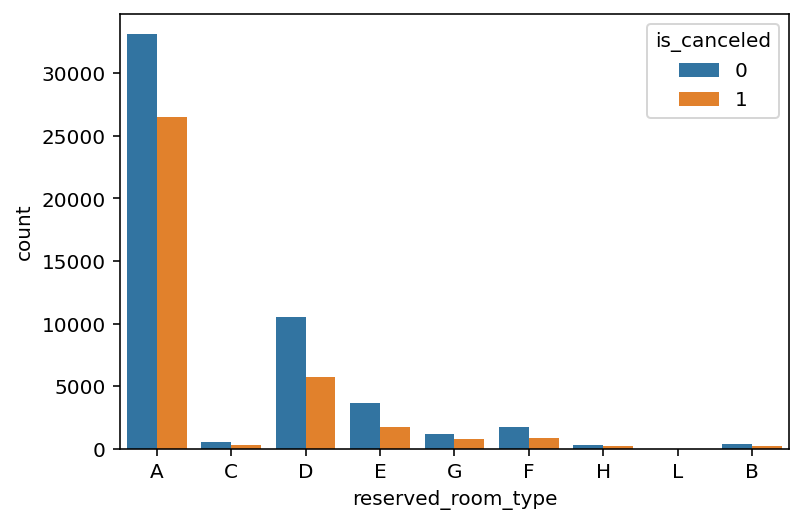
위 그림은 예약한 객실 유형과 예약의 취소 여부를 시각화한 것이다. 익명화 때문에 객실 유형이 A, C와 같은 코드로 제공되었으므로 각 코드가 정확히 어떤 유형의 객실인지는 알 수 없다. 그러나 위 그림을 통해서 예약의 취소 여부와 관계 없이 A, D, E 순으로 예약이 많이 이뤄졌음을 알 수 있다. 즉, 예약한 객실 유형은 예약이 취소된 경우와 취소되지 않은 경우의 분포가 비슷하다.
- 예약한 식사 유형(
meal)
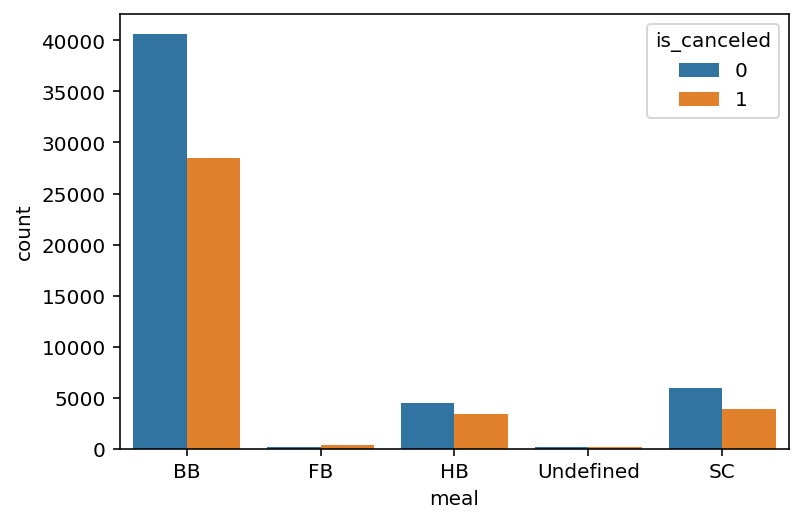
위 그림은 예약한 식사 유형과 예약의 취소 여부를 시각화한 것이다. 예약이 취소된 경우와 취소되지 않은 경우 모두 BB(Bed & Breakfast)가 가장 많고, Undefined(식사를 선택하지 않음)와 FB(Full Board)가 가장 적었다. 예약한 식사 유형도 예약이 취소된 경우와 취소되지 않은 경우의 분포가 비슷하다.
위 두 특성은 취소된 예약과 취소되지 않은 예약의 분포에 차이가 없었다. 따라서 이 특성으로는 각 예약의 취소 여부를 예측할 수 없다. 그렇기 때문에 이 두 특성은 모델에서 그다지 중요하지 않은 특성일 것이라고 추측할 수 있다.
모델을 생성한 후에 이 네 가지 특성이 모델 내에서 얼마나 큰 영향을 주고 있는지 살펴보기로 하자.
4. 분류 모델 생성
모델 생성은 크게 3가지 단계로 나누어서 진행하였다. 이 데이터는 시계열 데이터가 아니기 때문에 train, validation, test 데이터셋은 각각 60%, 20%, 20%의 비율로 무작위 추출하여 생성하였다.
1) 모델 탐색
먼저 다양한 모델을 최소한의 하이퍼 파라미터만 설정해서 학습하며 정확도와 작업 속도를 비교하였다. 총 7가지 모델을 사용하였으며, 각 모델의 validation 데이터셋에 대한 정확도는 아래와 같다. 정확도는 소수점 셋째자리까지만 기재하였다.
- Logistic Regression: 0.818
- Decision Tree: 0.812
- Ensemble
- Random Forest: 0.846
- XGBoost: 0.859
- LightGBM: 0.852
- CatBoost: 0.858
- GradientBoostingClassifier: 0.860
모든 모델의 정확도가 기준 모델의 정확도인 약 0.59보다 높았다. 따라서 이 모델들은 학습이 잘 된 모델이라고 말할 수 있다. 그리고 전체적으로 앙상블 모델의 정확도가 단일 모델의 정확도보다 높았다. 앙상블 모델들은 성능은 비슷하게 나왔으나, 작업 속도에서 차이가 있었다. LightGBM은 속도가 굉장히 빨랐고, CatBoost와 GradientBoostingClassifier는 속도가 매우 느렸다.
2) 성능 개선
다음으로, 위에서 사용한 모델 중 일부를 선택해서 하이퍼 파라미터를 튜닝하며 성능을 개선하였다. 여기서 사용한 모델은 다음과 같다.
- Random Forest
- XGBoost
- LightGBM
앙상블 모델의 정확도가 단일 모델보다 높았으므로 앙상블 모델 위주로 선택하였다. 정확도를 기준으로 한다면 정확도가 가장 높은 GradientBoostingClassifier와 XGBoost를 사용해야 하지만, 위에서 만든 모델은 하이퍼 파라미터를 임의의 값으로 설정한 후 만들었기 때문에 현재로서는 0.001 정도의 작은 차이는 의미가 없다고 판단했다. 그리고 정확도는 0.001 정도밖에 차이가 나지 않는데 모델의 생성 속도는 몇십 분씩 차이가 났다. 그래서 배깅 방식의 대표로 Random Forest를, 부스팅 방식의 대표로 XGBoost와 LightGBM을 선택하였다.
하이퍼 파라미터는 모델의 성능을 높이고 과적합을 막을 수 있는 것 위주로 튜닝하였으며, 주로 RandomizedSearchCV를 사용하였다. 다만, 부스팅 방식인 XGBoost와 LightGBM은 Random Forest보다 하이퍼 파라미터의 영향을 많이 받기 때문에 RandomizedSearchCV로 각 하이퍼 파라미터의 대략적인 범위를 찾은 후 GridSearchCV를 사용해서 한 번 더 확인하였다. 각 모델의 튜닝한 하이퍼 파라미터와 정확도는 아래와 같다.
-
Random Forest
- max_depth, min_samples_leaf, n_estimators, max_features
- 정확도: 약 0.8626
-
XGBoost
- max_depth, min_child_weight, gamma, learning_rate, n_estimators
- 정확도: 약 0.8632
-
LightGBM
- num_leaves, max_depth, learning_rate, n_estimators
- 정확도: 약 0.8601
세 모델 모두 정확도가 약 0.86 이상으로, 하이퍼 파라미터 튜닝 전과 비교했을 때 성능이 많이 개선되었다. 세 모델 중에서 가장 정확도가 높은 것은 XGBoost를 사용해서 만든 모델이다.
3) 최종 모델 생성
위 모델 중 가장 성능이 좋았던 XGBoost를 사용한 모델을 최종 모델로 선택하였다. 최종 모델의 학습에는 train 데이터셋과 함께 validation 데이터셋이 사용되었다. 최종 모델의 test 데이터셋에 대한 정확도, f1 score, auc score는 아래와 같다.
- 정확도: 약 0.8651
- f1 score: 약 0.8339
- AUC score: 약 0.9433
기준 모델의 정확도가 약 0.59였던 걸 생각해보면, 최종 모델은 학습이 잘 된 모델이라고 말할 수 있다. 그리고 f1 score, AUC score를 통해서도 최종 모델이 타겟의 분류를 잘 하는 성능 좋은 모델임을 확인할 수 있었다.
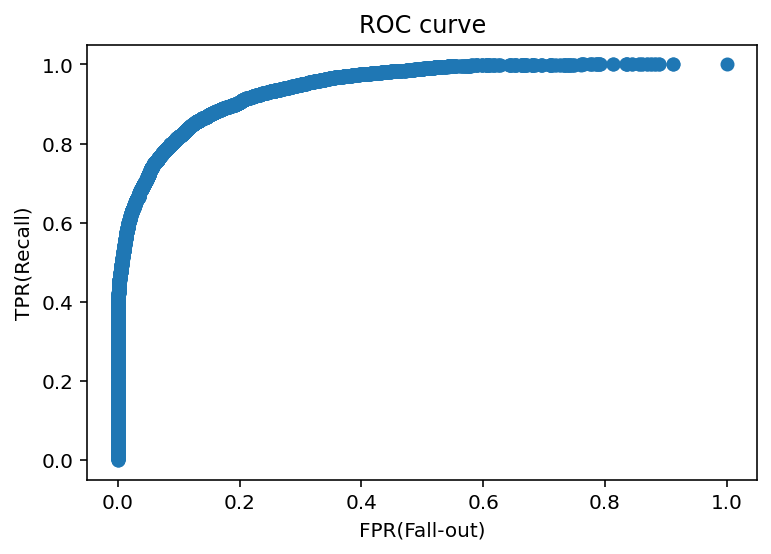
위 그림은 최종 모델의 ROC curve이다. 분류를 잘 하는 모델일수록 ROC curve는 모서리가 둥근 사각형 모양으로 그려진다. 최종 모델의 ROC curve도 모서리가 둥근 사각형 모양이므로, 최종 모델이 분류를 잘 하는 모델이라는 것을 알 수 있다.
5. 모델 해석
1) Permutation importance
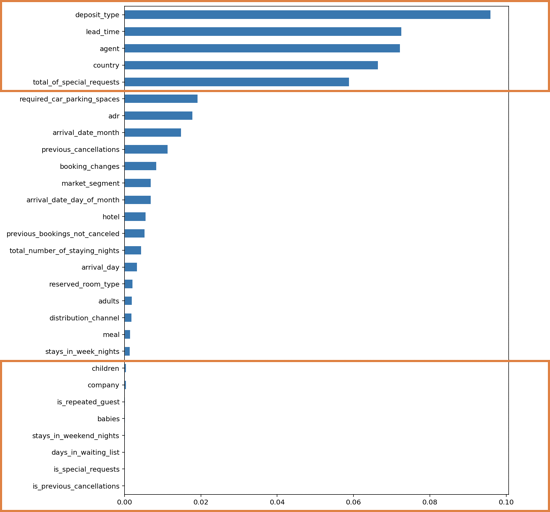
호텔 예약의 취소 여부를 판단하는데 중요한 특성에는 무엇이 있는지 확인하기 위해서 Permutation importance를 구해보았다. 그랬더니 총 29개의 특성 중에서 상위 5개의 특성의 영향력이 압도적으로 컸으며, 하위 8개의 영향력은 매우 작았다. 그리고 EDA때 중요할 것이라고 말했던 특성인 lead_time과 required_car_parking_spaces는 각각 2위와 6위로 상위권에 있었다. 반대로 중요하지 않을 것이라고 말했던 특성인 reserved_room_type과 meal은 각각 17위와 20위로 하위권에 속해있었다.
2) PDP
특성이 모델 내에서 어떻게 작동하고 있는지 자세히 알아보기 위해서 Permutation importance의 상위 3개 특성에 대해서 PDP를 그려보았다.
- 보증금 유형(
deposit_type)
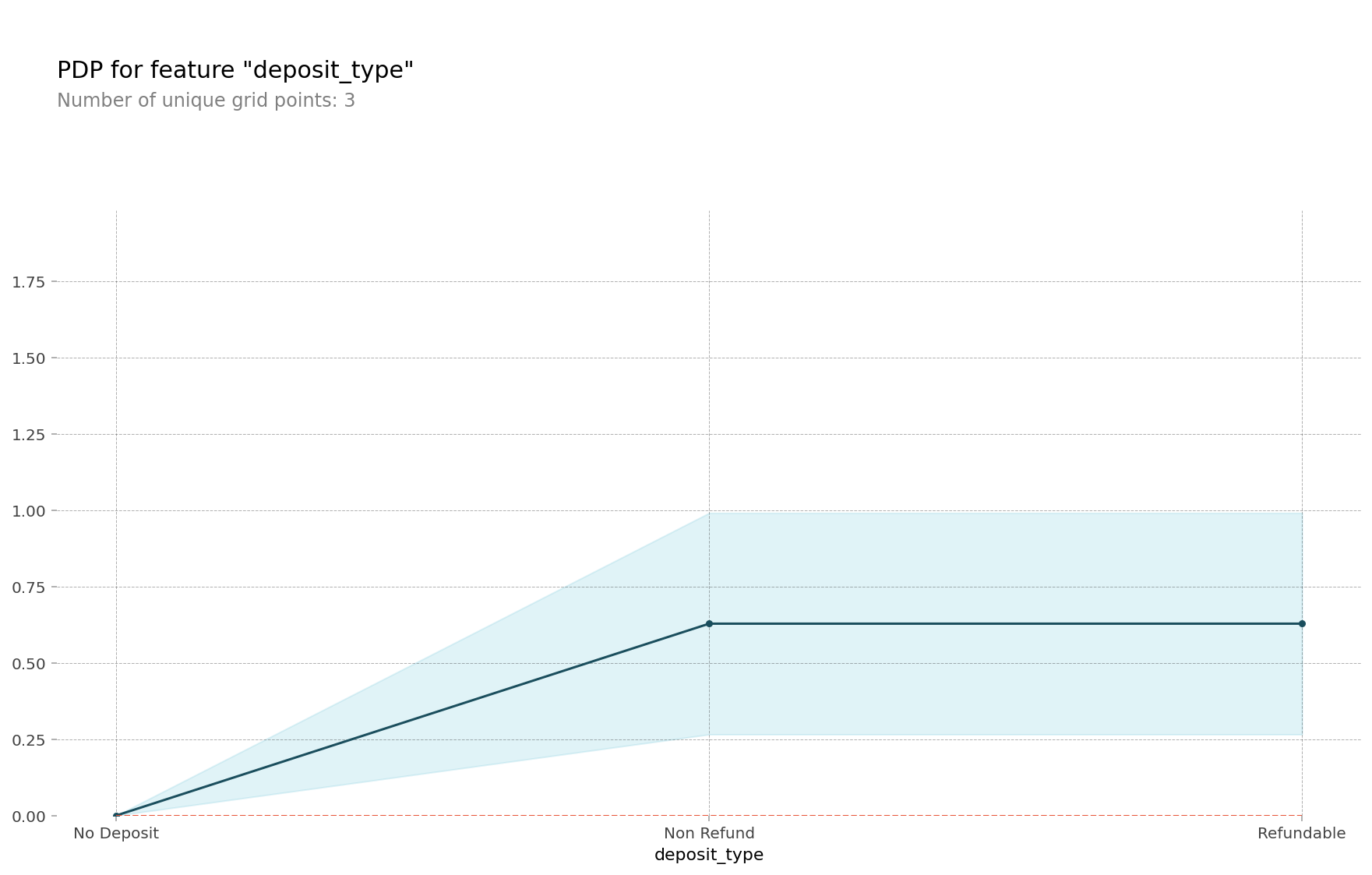
permutation importance에 의하면, 보증금 유형은 호텔 예약의 취소 여부를 예측하는데 가장 중요한 특성이다. permutation importance에서 보증금 유형이 가장 위에 있는 것을 보고 '보증금이 없으면 취소율도 높겠지'하고 생각했다. 그런데 PDP를 확인해보니 예상과 달리 보증금이 있는 경우가 보증금이 없는 경우보다 예약이 취소될 확률이 높았다. PDP를 확인해보지 않았다면 잘못된 인사이트를 도출할 뻔 했다.
- 예약일과 숙박일 사이의 기간(
lead_time)
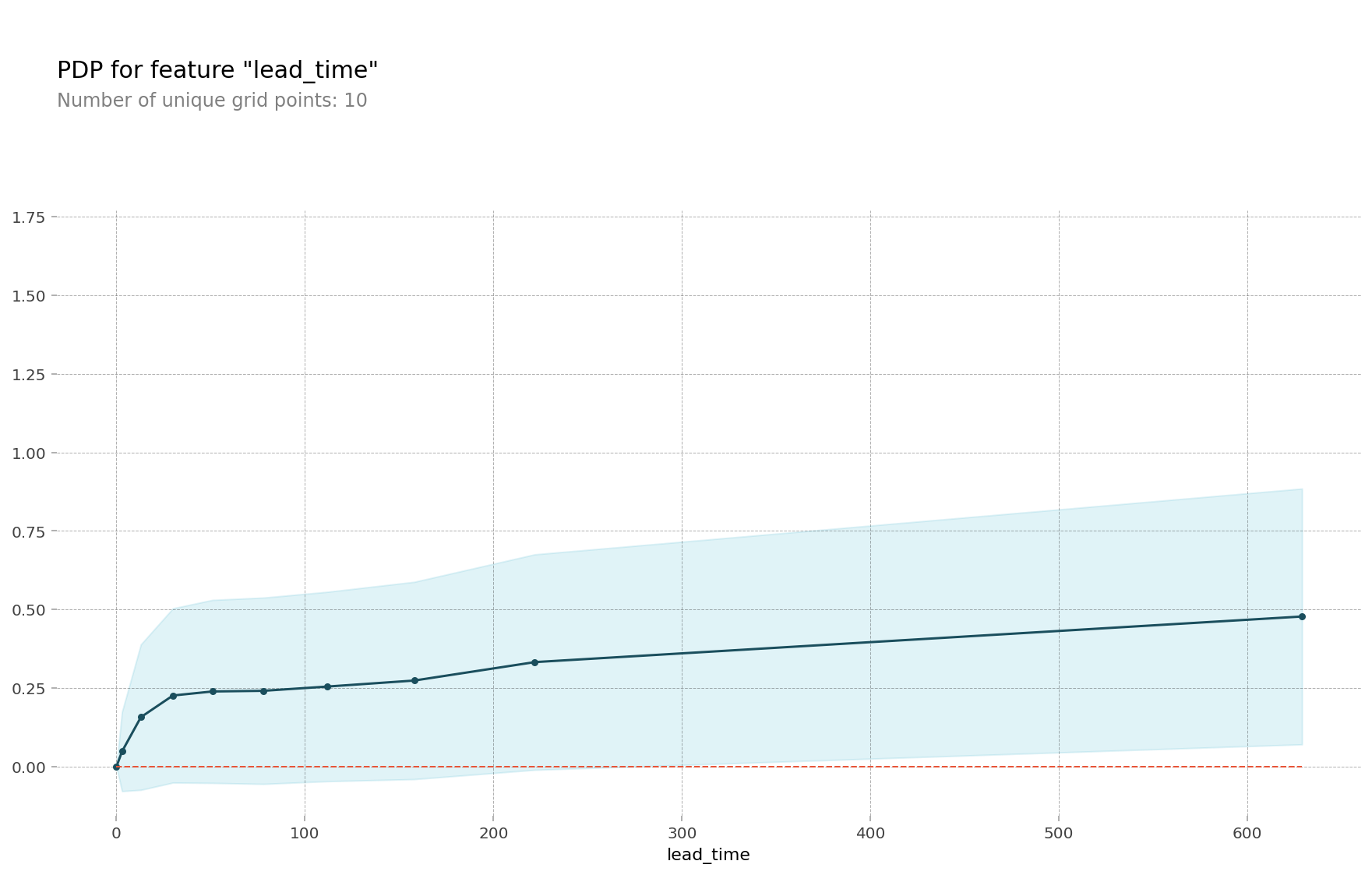
예약일과 숙박일 사이의 기간은 이 모델에서 두 번째로 중요한 특성이다. 예약일과 숙박일 사이의 기간이 길수록, 즉 예약을 오래전에 했을 수록 예약이 취소될 확률이 높았다. 아무래도 예약을 오래전에 하면 일정이 변동될 가능성이 높아지기 때문에 호텔 예약을 취소할 확률 역시 높아지는 게 아닌가 한다.
- 예약한 여행사(
agent)
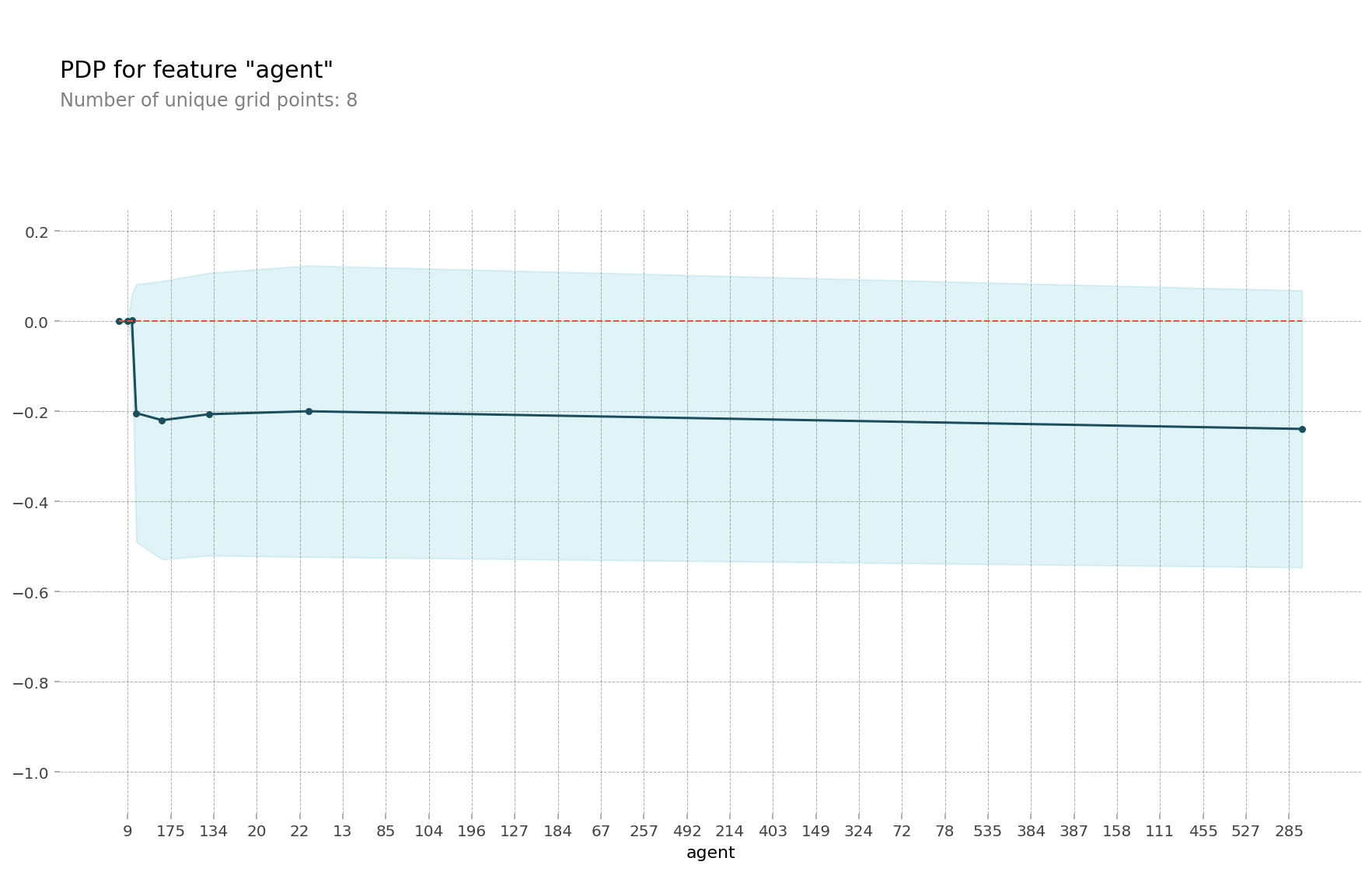
예약한 여행사는 세 번째로 중요한 특성이다. 이 호텔을 예약한 여행사는 총 290개였다. 그래서인지 그래프에서 변화가 있는 부분이 잘 보이지 않아서 아래와 같이 앞 부분을 확대해보았다.
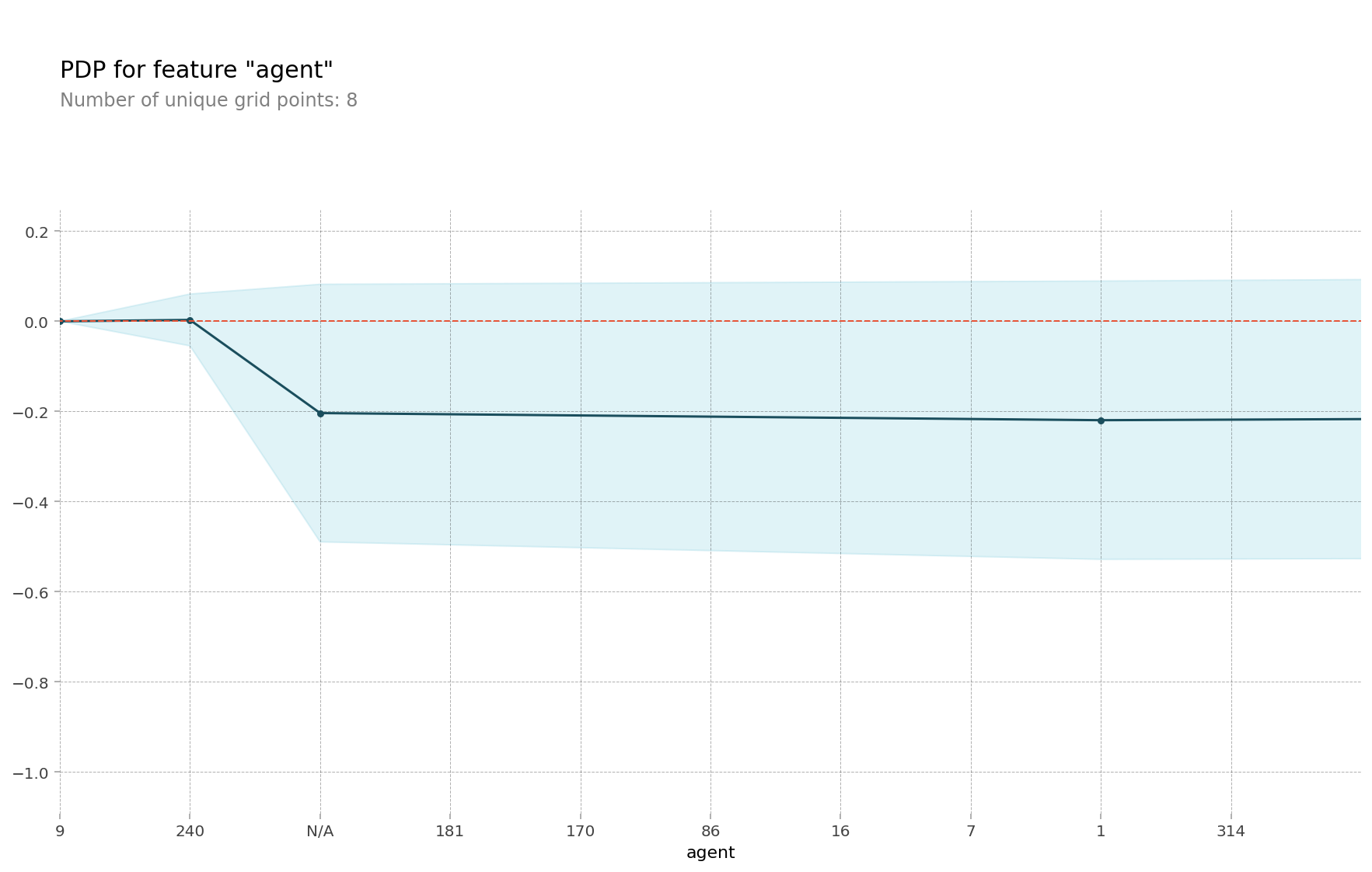
그림을 보면 알 수 있듯이, 9번, 240번 여행사가 예약한 경우에는 다른 여행사가 예약한 경우나 여행사와 관련 없이 예약한 경우보다 예약을 취소할 확률이 조금 더 높았다. 익명화 때문에 여행사가 회사명이 아니라 숫자 형식의 코드로 주어져서 해당 여행사가 정확히 어떤 여행사인지는 알 수 없었다.
- 예약일과 숙박일 사이의 기간(
lead_time) & 특별 요청의 수(total_of_special_requests)
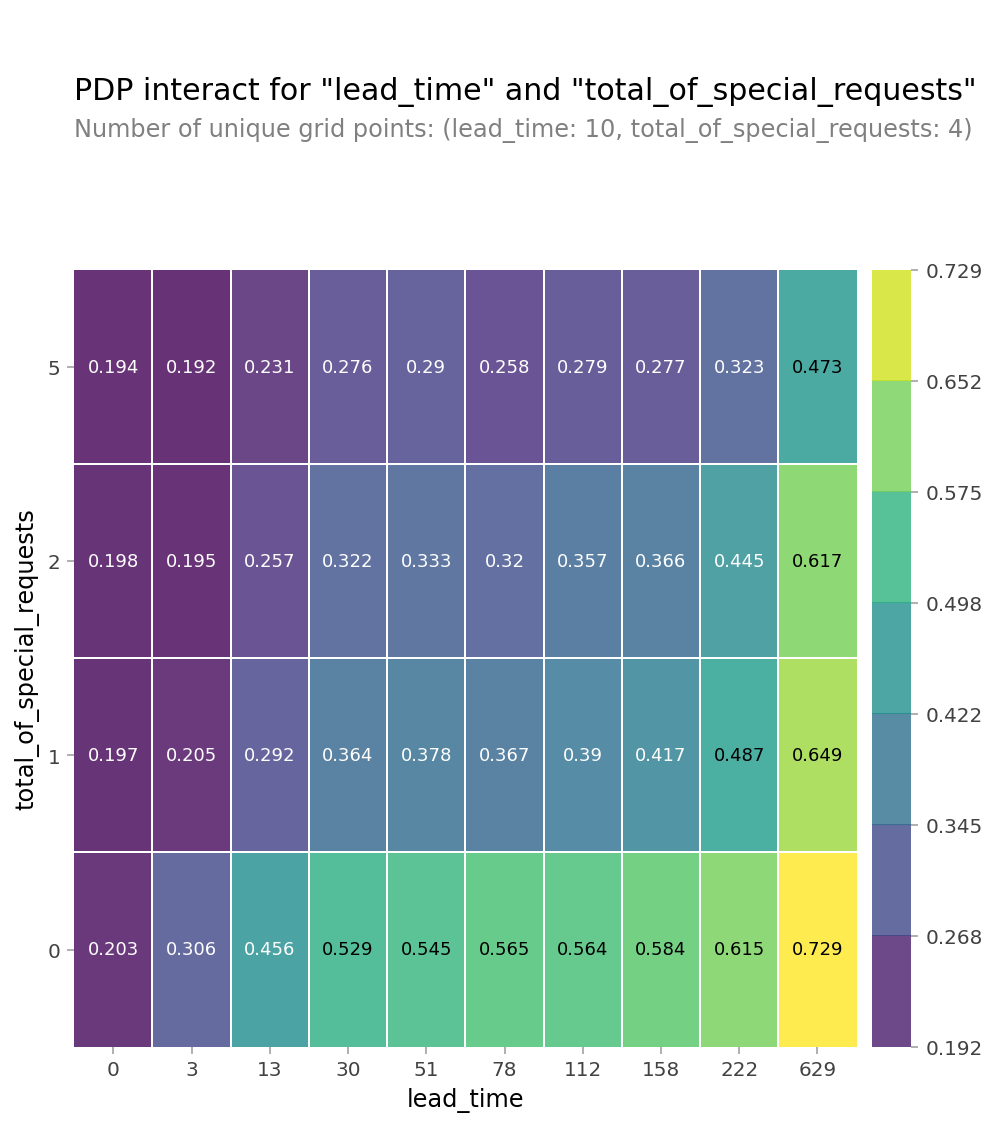
마지막으로 예약일과 숙박일 사이의 기간과 특별 요청의 수에 대해서 PDP를 그려보았다. 그림을 통해서 예약일과 숙박일 사이의 기간이 길수록, 특별 요청의 수가 적을수록 예약이 취소될 확률이 높다는 것을 알 수 있었다. 그리고 예약일과 숙박일 사이의 기간이 3~30일이고 특별 요청의 수가 1개 이상일 때는 예약이 취소될 확률이 특별 요청의 수보다 예약일과 숙박일 사이의 기간에 더 많은 영향을 받는 경향이 있었다.
모델 해석을 통해서 보증금을 받은 경우, 예약일과 숙박일 사이의 기간이 긴 경우, 특정 여행사가 예약을 한 경우, 그리고 특별 요청의 수가 적은 경우에는 호텔 예약을 취소할 확률이 높다는 것을 알 수 있었다. 우리가 만든 모델을 사용한다면 취소될 가능성이 높은 예약을 미리 파악할 수 있다. 하지만 모델만 사용하는 게 아니라 모델의 해석 결과를 바탕으로 호텔 운영 정책을 수정한다면 취소될 예약의 건수를 줄일 수 있을 것이다. 예를 들어, 호텔 매출에 타격이 가지 않는 선에서 호텔 예약 시 보증금을 받지 않는 경우는 줄이고, 각 숙박일에 대해서 예약을 받는 기간을 단축하는 것이다. 그리고 예약 취소율이 높은 여행사는 왜 취소율이 높은 것인지 분석하여 그 이유가 호텔 내부에 있다면 이를 개선하여 더 나은 서비스를 제공할 수도 있을 것이다.
6. 결과 정리
지금까지 A사 호텔 사업부의 오랜 고민을 해결하겠다는 가상의 시나리오 하에 캐글 데이터셋을 사용하여 단기 고객의 호텔 예약 취소 여부를 예측하는 모델을 만들고 이를 해석해보았다. 최종 모델은 총 29개의 특성과 XGBoost를 활용해서 만들었으며, 모델의 정확도는 약 0.8651로 기준 모델의 정확도인 약 0.59보다 높았다. 정확도 외에도 f1 score, AUC score, ROC curve를 통해서 이 모델이 분류를 잘 하는 좋은 모델임을 확인할 수 있었다. 이 모델에서 가장 중요한 특성은 보증금 유형(deposit_type)과 예약일과 숙박일 사이의 기간(lead_time)이었다. 보증금을 받는 경우가 보증금을 받지 않은 경우보다 예약이 취소될 확률이 높았으며, 예약일과 숙박일 사이의 기간이 길수록 예약이 취소될 확률이 높았다.
이 모델은 호텔이 객실을 효율적으로 운영하는 데 도움이 될 것이다. 취소될 확률이 높은 예약 건에 대해서는 미리 확인 전화를 함으로써 노쇼(No-Show)를 줄일 수 있으며, 취소될 확률이 높은 예약 건수만큼만 초과 예약을 받을 수도 있다. 그리고 모델을 해석한 내용을 바탕으로 호텔 예약 시 보증금을 받지 않는다거나, 예약이 가능한 기간을 지금보다 단축하는 등 운영 방식에 변화를 줌으로써 예약 취소를 줄일 수 있다.
하지만 이 모델은 모든 호텔에서 그대로 사용할 수 없다는 한계가 있다. 특정 호텔의 데이터셋을 바탕으로 만들어진 모델이기 때문에 다른 호텔에서도 동일한 성능을 보인다는 보장이 없다. 프로젝트를 위한 가상의 시나리오를 만들 당시에 고객의 국적, 예약한 여행사처럼 다른 나라, 다른 호텔에서는 다른 특징을 보일 특성들을 제거하고 최대한 일반화 시킨 모델을 만들까 고민했었다. 하지만 일반적이지 않은 성격을 지닌 특성을 제거한다고 해도 다른 특성에서도 나라마다, 호텔마다 조금씩 분포가 다르게 나타날 것이기 때문에 현재 데이터 상으로는 완벽한 일반화는 불가능하다고 판단했다. 대신 특정 호텔에서 사용할 모델이라고 범위를 한정지어 사용 가능한 특성을 모두 활용함으로써 해당 호텔 데이터셋에서만큼은 확실한 성능을 보이는 모델을 만들기로 하고 A사의 호텔 사업부에서 사용할 모델이라는 가상의 시나리오를 작성하였다. 그러나 다른 나라, 다른 호텔에서 이러한 모델을 사용하고자 할 경우에는 데이터셋만 달라질 뿐 동일한 방법을 거쳐 각 호텔에 맞는 모델을 만들 수 있다고 생각한다.
