머신 러닝_2
ML 기본 프로세스
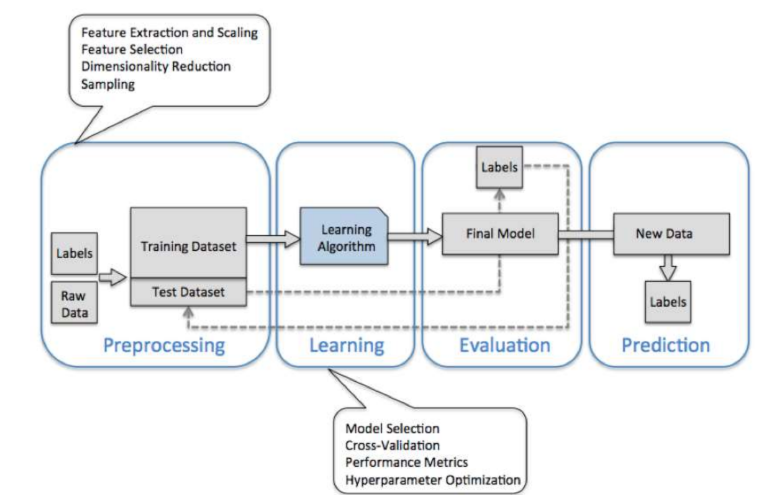
Scikit - Learn Package
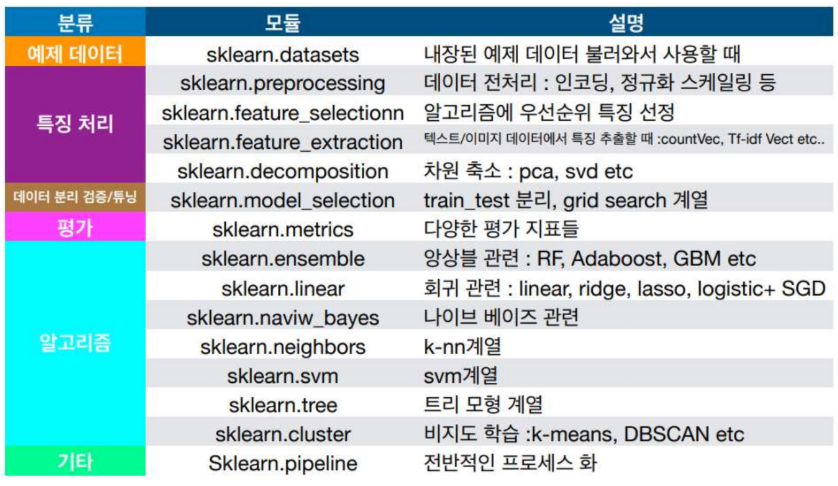
-
수집한 Sample 데이터
from sklearn.datasets import fetch_openml -
주어진 데이터 분리 : train_test_split
from sklearn.model_selection import train_test_split

-
내가 사용할 / 피팅할 f 의 스타일 : 어떤 모델을 사용할지?
knn, xgboost 같은 외부의 f 스타일을 가져와서 사용
참고) 파이썬/scikit-learn : 분류 => Classfier, 회귀 => Regressor
==> 사용할 알고리즘 + 목적성(분류/회귀)
from sklearn.neighbors import KNeighborsClassifier
* 매뉴얼 : https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html
- 평가 : 여러가지 평가지표로 성능 판단. 분류에서 가장 간단한 acc, etc.. scikit-learn에 없는 지표는 직접 만들어서 해야 함.
from sklearn.metrics import accuracy_score
** 큰 데이터를 다룰 때 컴퓨터 성능이 딸릴 경우
구글 클라우드에서 유료로 컴퓨터를 대여(?) 해서 사용할 수 있음
-
autoML로 feature 변환+처리+도메인지식..
-
학습 수행: 주어진 데이터에 맞춰서 내가 세팅한 F에 대한 파라미터 최적화
= Learning
시간이 오래 걸림. k-fold까지 하면 시간 * k배
knn.fit(train_x, train_y) -
실제 수행
knn.predict(text_x) -> 모델이 예측한 값들을 반환해줌
test_y -> 정답. 위 예측값과 비교를 통해 모델의 정확도를 알 수 있음 -
채점
기준은 accuracy라고 하면
accuracy_score( test_y, knn.predict(test_x) )
-> 여기서 얻은 accuracy를 baseline으로 하고,
더 높은 accuracy를 얻을 수 있도록 knn의 구체적인 세팅을 조절하자!
ex / 파라미터 n_neighbors 변화시키기
주로 대회의 경우 이런 과정을 많이 거침,,,,
우연히 1번 잘 나올수 있기 때문에 k-fold CV 사용
1) 직접 조합하기 : gridsearchCV
2) 랜덤하게 샘플링 : random
3)
f를 다양하게 적용하며 실험한다.
근본 모델은 사실 요즘 잘 사용을 안한다. (KNN, SVM, DT의 경우..)
요즘은 여러 모델을 합친 모델을 사용한다.
Bagging : RandomForest
Boosting : xgboost, lightGBM, catBoost etc..
모델
KNN
Decision Tree
기준에 따라서 split하는 과정을 점진적으로 반복하여 최종 의사결정. -> 이 과정을 알고리즘화 함.
기준에 우선순위 알 수 있다? -> Feature의 중요도를 알 수 있따?
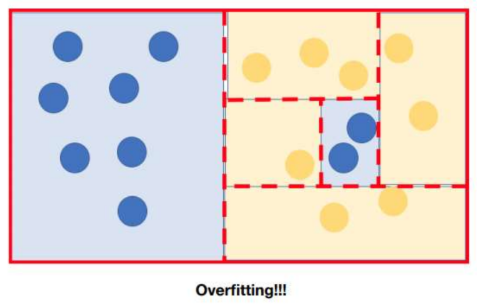
perfect한 split으로 진짜 1개까지 다 분류할 수 있음 -> overfit 문제로 적절한 depth를 조절하여 general한 model 이 되도록 함.
계량화(Classification)
잘 분류가 되는지 기준이 필요함.
- 엔트로피
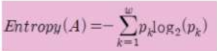
- 지니 계수
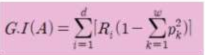
: 확률적인 방법
0이면 이상적인 값 (완벽하게 분류)
1/2이면 반/반으로 분류된 것이기 때문에 안 좋음
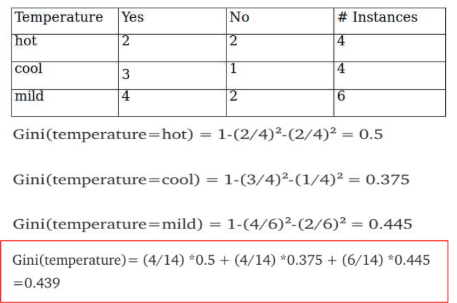
ex / 날씨에 따라 외출(Yes/No)
wind, temperature 등의 변수가 존재함. 위 사진은 Temperature의 지니계수를 계산한 것. 1 - (yes/(yes+no))^2 - (no/(yes+no))^2 .
각 변수에 대한 지니계수를 비교하여 0에 가장 가까운 변수가 중요도가 높아 1번째 기준으로 선별! -> 다시 앞 과정과 동일하게 반복해서 다음 기준 선별
Tree base의 모델은 정규성/분포에 대해 영향을 크게 받지 않음.
Ensemble
Many + Diversity
- Voting
- Boosting
- Bagging (시간)
overfit 방지
RandomForest
: Bagging을 가장 심플하게 구현한 것


XgBoost
: 가중치 부여
error를 줄이는 방향으로 학습 -> overfit
