
들어보기만 했습니다. pandas...
슬쩍 봤는데, 뭔가 엑셀이랄까? 아 뭔가 그런 느낌적인 느낌이에오 !
우선, Pandas를 쓰려면 ? Python이 설치되어 있어야 합니닷 !
- 일단, 맥(Mac OS)은 파이썬3가 내장되어 있어염(오늘 기준: 23.08.01)
- 그래도 의심스러우니깐 파이썬이 설치되어 있는지 확인해 보자구요 !

- 터미널(terminal)에서 python3 --version을 쓰고 엔터 ! 그러면 설치되어 있는 파이썬 버전을 확인할 수 있습니다 !
- 설치된게 확인 되었다면 ? pandas 설치해야 되니까 터미널 닫지마효 !
pandas를 설치해야 합니닷 !
- 터미널에 pip3 install pandas jupyter를 입력하고 엔터 !
주의사항) 파이썬3가 아니면, pip install pandas jupyter를 입력하세오 !
참고사항) jupyter는 뭐 사용하기에 편안한 그런 도구니까 설치하는 김에 같이 합니다.
준비완료 !
본격, Pandas는 뭐얏?
판다스(Pandas)는 파이썬 프로그래밍 언어를 위한 데이터 조작과 분석을 위한 라이브러리
주요기능
-
데이터 읽기와 쓰기
CSV, Excel, SQL, JSON 등 다양한 데이터 형식의 파일을 읽고 쓰기 -
데이터 선택과 조작
열 선택, 행 선택, 조건에 따른 데이터 필터링, 계산 등을 수행 -
데이터 그룹화와 집계
데이터를 그룹화하여 통계적인 연산을 수행 -
결측치 처리
누락된 데이터를 처리하는 기능을 제공 -
시계열 데이터 지원
시간과 관련된 데이터를 처리하는 기능을 지원 -
데이터 시각화
Matplotlib와 함께 사용하여 데이터를 시각화
😯 오늘의 나는 pandas를 이용해서 csv파일을 불러와서 데이터를 선택하고 조작하는 부분만 보여줄 것이다. 더 많은 것은 보여줄 수 없다. 아는게 없기 때무니다ㅠ_ㅠ
🖥 실습 IDE는 VSCODE, 파일확장명: '.ipynb'
확장명은 jupyter를 사용해야 하기 때문인거 같음 ! (일반 파이썬의 확장명은 .py 임)
⭐ 1단계: pandas 임포트 하기 !
import pandas as pd
# pd는 판다스의 약칭 alias 임⭐ 2단계: 데이터 파일(.csv) 불러와서 데이터 프레임(DataFrame)으로 저장
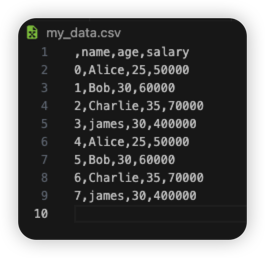
read_csv() 함수를 사용해서 csv 파일을 불러오기
csv_data = 'my_data.csv'
## pandas 라이브러리의 read_csv() 함수를 이용해서 파일을 불러오기
df = pd.read_csv('../my_data.csv') # 경로 설정 주의
print(df) 데이터 프레임(df) 출력값

파일 불러오기 완료 !
💡[데이터 조작] 첫번째. 칼럼명 바꾸기: df.columns / df.rename
- 원본 데이터를 보면 첫번째 열의 칼럼명은 비어있음(NaN 값임)
- 불러온 데이터를 출력했더니 해당 칼럼명이 Unnamed:0으로 출력됨
## 칼럼의 이름을 전체적으로 지정해주면서 수정함
df.columns = ['del', 'name', 'age', 'salary']
print(df)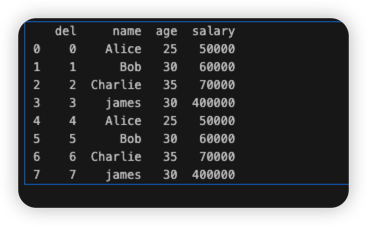
## 특정 칼럼 값만 바꿀 수 있음
rename_df = df.rename(columns= {'Unnamed: 0':'del'})
print(rename_df)
💡[데이터 조작] 두번째. 열 삭제하기: df.drop('칼럼명' or index, axis=열)
- df.drop() 메서드는 판다스에서 데이터프레임에서 행 또는 열을 제거하는 데 사용
- axis=0: 이는 행을 나타내며, axis=0로 설정하면 데이터프레임에서 행을 제거
- axis=1: 이는 열을 나타내며, axis=1로 설정하면 데이터프레임에서 열을 제거
## 칼럼명이 delete인 열을 제거 !
df=df.drop('delete', axis=1)
print(df)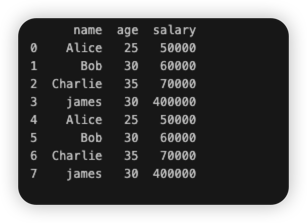
💡[데이터 조작] 세번째. 데이터 값 변경하기: .replace()
## 영어 이름과 한국어 이름을 매핑한 딕셔너리 생성
name_korean = {
'Alice' : '앨리스',
'Bob' : '밥',
'Charlie': '찰리',
'james': '제임스',
}
## 'name' 열의 값들을 'name_korean' 딕셔너리를 사용하여 한국어 이름으로 바꿈
df['name'] = df['name'].replace(name_korean)
print(df)
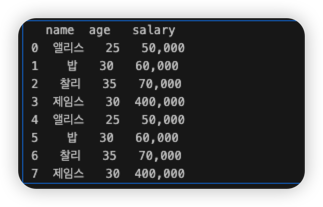
💡[데이터 조작] 네번째. salary의 값을 한국 원(₩) 단위로 변환: 함수 정의 & apply() 메서드
- apply() 메서드 : 데이터프레임이나 시리즈에 저장된 숫자 값을 원하는 형식으로 변환
# 한국 원 단위로 숫자를 변환하는 함수 정의
def korean_won(number):
return '{:,.0f}'.format(number)
# 천 단위마다 쉼표(,)가 추가, 소수점 이하는 버림
# 'salary' 열에 있는 모든 값에 'korean_won' 함수를 적용하여 한국 원 단위로 변환
df['salary'] = df['salary'].apply(korean_won)
# .apply(korean_won)은 korean_won을 df에 있는 salary 칼럼의 '모든 열 값에 적용'해라.
print(df)
💡[데이터 조작] 다섯번째. index 없이 출력하기: to_string() 메서드 + index=False
- to_string은 데이터프레임을 문자열로 변환
- 매개변수를 통해 index 출력을 제외시킴 (False)
df_string = df.to_string(index=False)
print(df_string)- df.to_string() 메서드를 사용하여 데이터프레임을 문자열로 변환하고, index=False 매개변수를 통해 인덱스를 출력에서 제외

🌟작업한 데이터 프레임을 내보내기🌟 !
## csv파일로 저장하기
df.to_csv('my_data_out.csv', index=False)그럼 해당 작업 폴더에 csv 파일이 뿅 ! 생긴다 !
끝이다 !
결론
음.........panda...s 낯설다. 너.😂

`나는 ${job} 개발자`