
운영체제 수업 + Operating System Concepts 10E 정리 내용
Operating System Ch09 : Main memory
Memory Management
1. Goals
- os가 관리하는 것들 중에서 abstraction이 가장 잘 된 것이 memory 관리에 대한 부분이다.
- 편의성을 제공하기 위해 abstraction을 한 것
2. Batch programming
- program은 physical memory에 직접적으로 접근하여 사용한다.
- memory management 필요 없다.
3. Multiprogramming
- 각각의 process가 쓰는 메모리를 격리 시킨다.
- 비어있는 메모리 공간을 찾아서 사용하도록 한다.
- Requirements
- Protection: 각각의 메모리 공간을 격리해서 보호하기
- Fast Translation: 로직을 잘 구성하여 변환이 빨라야 한다.
- Context switching: 메모리 하드웨어를 업데이트 (이전의 context switching과 다르다.)
4. Issues
- multiprocess 보호
- 각각의 프로세스는 논리적으로 연속된 공간을 가지고 있어야 한다.
- 각 공간의 크기는 가변적이다.
- 프로세스에 할당된 메모리 양보다 큰 프로세스를 사용
- 모든 메모리 공간을 동시에 사용하는 것 아니다.
- 메모리 참조는 공간 및 시간적 인접성이 존재한다.
- protection and sharing
- support for multiple regions per process
- 비어있는 공간이 없이 쪼개서 잘 사용해야 한다.
- performance
5. Solution: Virtual Memory
- VM (Virtaul Memory)
- secondary storage의 공간을 메모리처럼 사용하는 것
- 이론적으로는 무한대의 메모리를 사용할 수 있다.
- 다음 chapter에서 자세하게 배운다.
Binding of Instructions and Data to Memory
1. Overview
- Logical memory
- 우리가 이전까지 생각하는 메모리
- code segment, stack, heap 등으로 구성된 메모리 구조로 그리던 구조
- 우리는 logical memory를 생각하고 코딩하지만 실제로 OS는 logical memory를 physical memory로 변환시켜서 사용한다.
2. Address binding time
- Compile time
- Compile 시간에 logical memory를 physical memory로 집어넣는 것을 결정한다.
- 성능이 좋지 않다.
- Load time
- 프로그램을 실행 시 binary code를 code segment에 올릴 때 어떤 physical memory에 넣을지 결정하기
- execution time
- 실행 시간에 결정
3. Binding of Memory Address
-
왼쪽에 그려진 메모리 구조가 logical memory, 오른쪽에 그려진 메모리 구조가 physical memory이다.
-
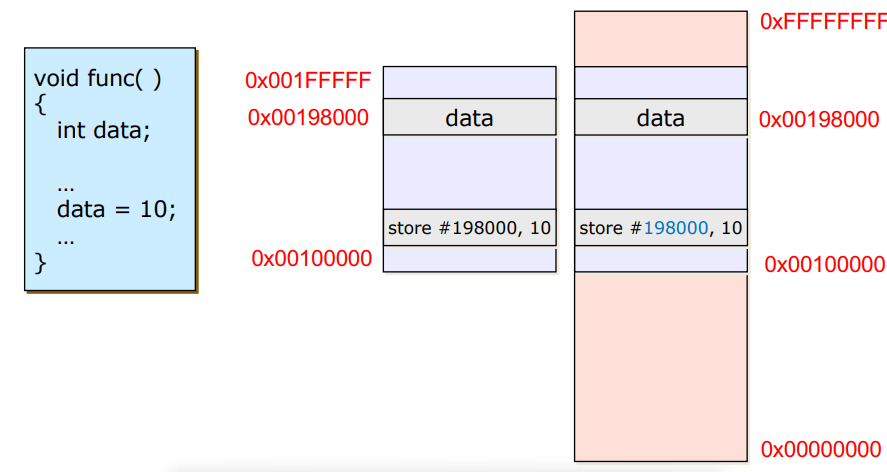
Compile time
- logical memory와 같은 physical memory를 찾아서 넣어주는 방식
- 가장 빠르지만, physical memory주소를 다 알아야 한다는 단점이 존재한다.
- logical memory와 같은 주소인 physical memory 공간에 다른 data가 올라와서 사용중이라면 문제가 발생한다.
-
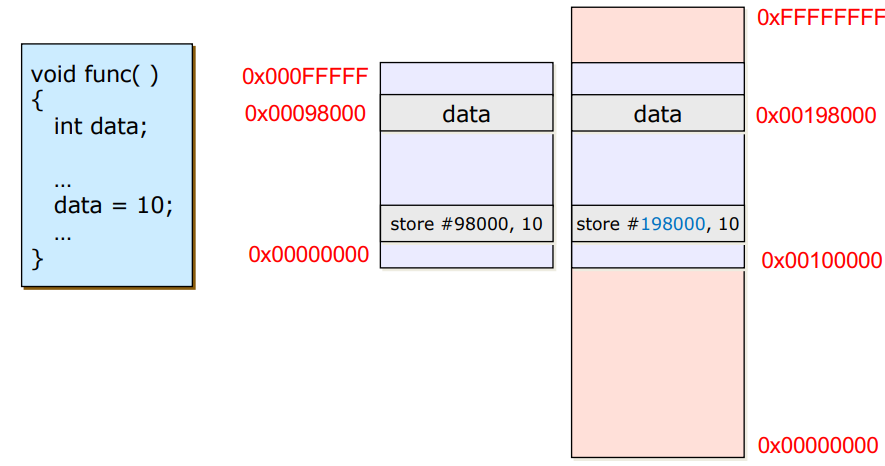
Load time
- logical memory의 공간의 주소에 특정 offset값을 부여하여 physical memory에 넣어주는 방식 (OS가 offset을 부여)
- compile time의 문제는 해결하지만 프로그램이 큰 경우 load time이 매우 길어지는 문제가 발생한다.
-
Execution time
- logical memory를 physical memory의 빈 공간 아무곳에나 넣어준 다음 해당 memory의 offset값을 가져와서 더해주는 방식
- 실행을 할 때 offset을 더하는 연산이 필요해서 실행 시 overhead가 크다 -> execution time이 늘어난다.
- overhead는 있지만 실제로 사용하는 방식이다.
-> hardware logic (MMU)를 통해 overhead로 느려지는 문제점을 해결한다.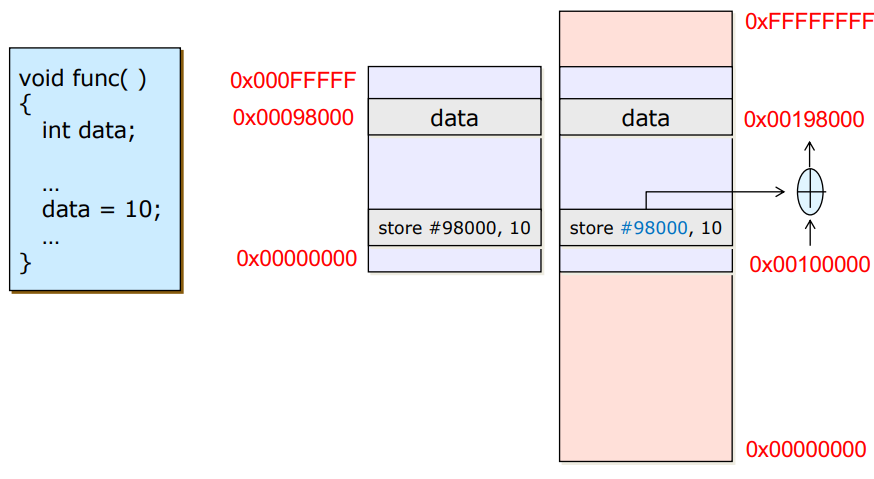
-
Address mapping
- 메모리가 부족하면 secondary storage에서 넣었다 뺏다를 반복하면서 메모리 부족을 해결하는 방식
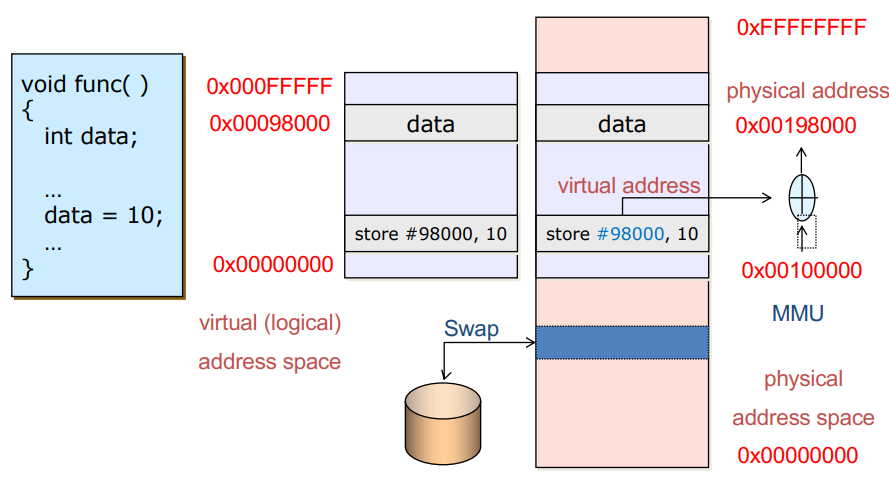
- 메모리가 부족하면 secondary storage에서 넣었다 뺏다를 반복하면서 메모리 부족을 해결하는 방식
Memory-Management Unit
1. Overview
- MMU는 CPU안에 존재한다. (x86 기준)
- compile time에 바인딩을 하는 경우는 embedded system으로 많이 사용한다.
-> embedded전용 CPU는 MMU가 없다.
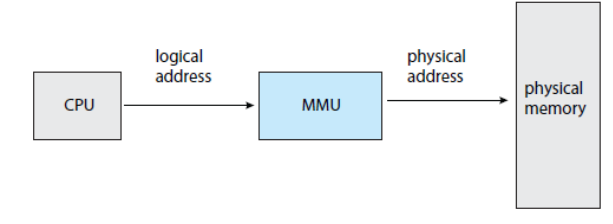
- logical memory는 여러 번 실행시켜도 같은 주소값이 출력된다.
-> 우리가 알고 쓰는 것은 logical memory이고 앞으로의 이야기는 logical memory를 어떤 방식으로 physical memory로 넘겨줄 것인지에 대한 내용이다.
2. Contiguous Allocation
- 메모리를 쪼개지 않고 빈 공간에 그대로 올리는 것, relocation만 진행한다. MMU의 relocation register가 수행.
- CPU에서 보낸 logical memory를 받아오면 limit register를 넘는지 확인하고 넘으면 trap, 넘지 않으면 relocation을 진행(offset 적용)하여 physical address 로 메모리에 저장
- 문제점
- Contiguous allocation 방식을 반복하면 hole이 생기는 문제가 발생한다.
- hole에는 다른 process를 실행시킬 수는 있지만, 반복 될수록 작은 hole이 계속 생성되고 이러한 hole이 많아지면 메모리의 낭비가 발생한다.
- 해결방안
- First-fit: 0번지에서부터 들어갈 공간을 찾다가 첫번째로 찾은 공간에 넣기
- Best-fit: 할당 받아야 하는 메모리의 크기와 가장 유사한(같거나 약간 큰) 공간에 넣기
- Worst-fit: 가장 큰 hole을 찾아서 넣기
- worst의 효율이 가장 좋지 않고, first와 best의 효율은 비슷하다.
3. Fragmentation
- Fragmentation: 흩어져 있는 hole이 계속해서 많아지는 문제
- External Fragmentation
- process와 process 사이에서 발생하는 fragmentation
- Contiguous allocation 에서 발생하는 문제
- 비어있는 메모리의 합은 충분히 다른 메모리를 할당할 수 있을 만큼의 크기이지만, 연속적으로 존재하지 않는 경우
- Internal Fragmentation
- process 안에서 발생하는 fragmentation
- page 기법에서 발생한다.
4. Fragmentation Solutions
- Compaction(조각 모음)
- memory 조각들을 다 돌면서 연속적으로 존재할 수 있도록 모아주는 과정
- OS가 담당해서 해결하지만 overhead가 매우 크다.
- io input이 많이 들어오는 경우 특히 느려진다.
- 이것 이외의 좋은 해결방안이 없기에 Contiguous allocation은 사용하지 않는다.
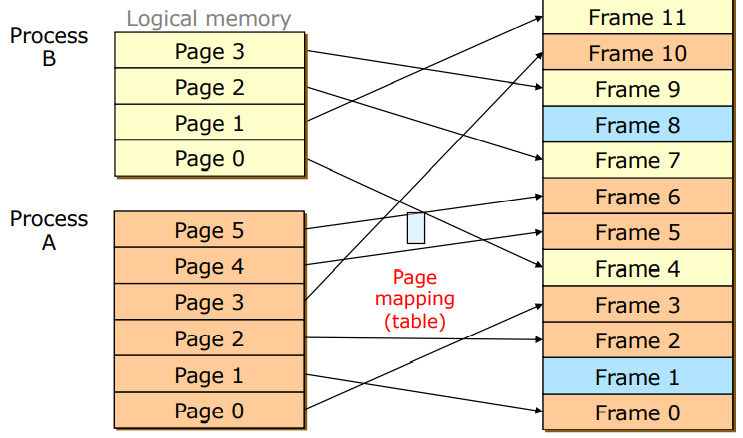
- Paging
- logical과 physical memory를 모두 동일한 크기로 자르기
- page table을 거쳐서 특정 page가 어떤 frame으로 가야하는지 mapping 해준다.
- Address Translation
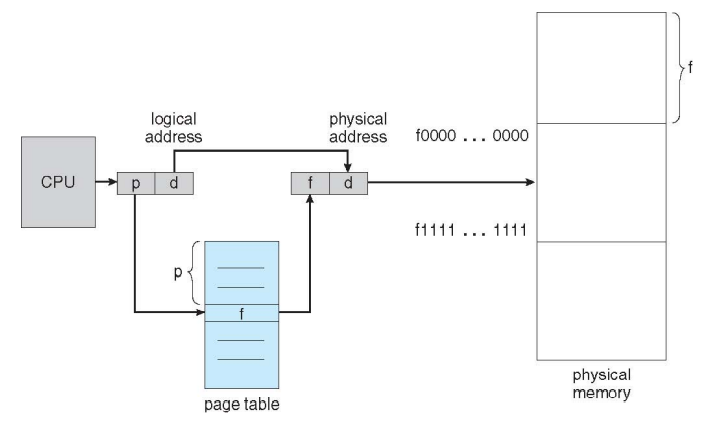
- 각각의 page는 각각의 base주소를 가지고 page들로 이루어진 process의 base 주소가 존재한다.
- page number를 page table에 넣으면 frame number를 얻게된다.
- frame number에서 offset을 얻어서 physical address를 얻는다.
- page table
- OS가 관리해준다.
- 문제점
- 특정 프로세스가 동일한 크기로 작은 page의 한 조각을 다 쓰지 못한 경우 낭비가 발생 -> internal fragmentation
- external fragmentation보다 나은 낭비이기 때문에 낭비를 감수하고 사용한다.
Paging
1. Paging Example
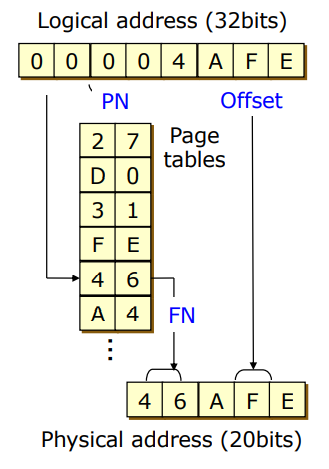
- logical memory : 32 bits
- page table : 4kb(4096 byte) -> -> offset : 12 bits
- physical memory : 32 - 12 = 20 bits
- page table entries: * 4byte -> 4mb
2. Free Frames
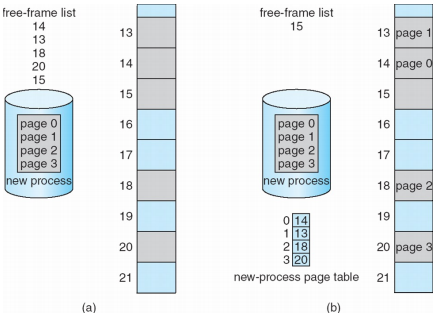
- 안쓰는 frame은 free-frame list를 통해서 관리
- 안쓰는 frame과 page table을 연결해서 메모리 할당 해주기
(a->b) - 높은 우선순위를 분석해서 넣어주는 과정
cf) VM: 할당 받아서 사용된지 오래된 것을 내리고 새로 할당해야 할 것을 올려주는 역할도 수행
3. Implementation of Page Table
- 프로세스마다 각자의 데이터 영역이 존재하기 때문에 page table은 프로세스 마다 따로 존재
-> 프로세스가 많아지면 page table도 함께 많아지기 때문에 메모리 소모가 매우 크다. - page table
- 크기가 크고, 메모리에 올린 후 사용해야 하므로 성능 저하의 원인이 된다.
-> Page-table base register와 Page-table length rigister가 main memory를 차지 - page table을 메모리에 올린 후 사용해야 하므로 구조적으로 두 번 access하는 과정이 필요하다.
-> page table을 위한 access + data와 instruction을 위한 access
- 크기가 크고, 메모리에 올린 후 사용해야 하므로 성능 저하의 원인이 된다.
- Solutions
- MMU 안에 특별한 cache 메모리를 두어 buffer로 사용한다.
- page table의 일부를 caching 하는 방식
4. Page Table Solutions
- Associative Memory
- parallel 하게 접근가능한 메모리 -> MMU 안에 TLB를 구현한다.
- TLB를 이용한 page table 동작 방식
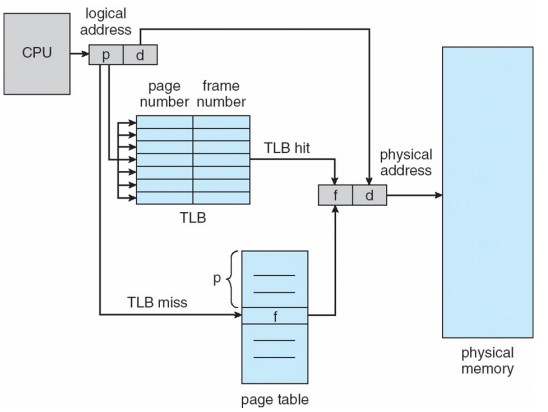
1) 처음 메모리에 들어오는 경우 associative memory의 table을 초기화
2) MMU가 체크해보니 cache hit이 발생하지 않음
3) page table에 접근해서 메모리에 두 번 access하는 방식 이용
4) 이후 사용한 인근의 데이터를 associative memory에 넣어두고 cache hit을 이용 - issue
- cache hit을 높이는 것이 중요한 논점
- 결과적으로 해당 방식의 hitting range가 99% 이상
- TLB
- Temporal locality
- 한번 사용이 되면 조만간 다시 사용될 확률이 높다.
- Spatial locality
- 사용된 부분의 인근의 영역도 사용될 확률이 높다.
- 순차적, loop로 동작하기 때문에 많이 사용된다.
- Handling TLB misses
- software: OS가 처리하는 방식은 느려서 사용하지 않는다.
- hardware: Intel x86 이 지원하는 방식
cf) 모든 분야에서 결국 bottleneck을 줄이는 것의 방향성은 hardware의 발전이다.
- managing TLBs
- context switching이 발생한 경우 (interrupt / trap)
- TLB 정보를 초기화 -> 프로세스마다 page table이 다르기 때문
- Temporal locality
Effective Access Time
1. Effective Access Time
- EAT =
- 숫자 : access 횟수
- : TLB에 접근할 때 걸리는 시간
- : cache hit 비율
- cache hit :
- cache miss :
- 메모리 한번 access할 때 평균 시간: 121ns ( = 20ns, = 99%)
Main Memory Protection
- page table은 너무 크기 때문에 실제로 사용하는 page는 v로 표시, 사용하지 않는 page는 i로 표시한다.
- process가 v로 표시된 page table에는 접근하지 못한다.
- cf) 초기화 코드같은 경우 맨 처음 코드 실행 후 v로 표시되고 사용하지 않는다 -> VM은 이러한 안쓰는 v로 표시된 page table을 i로 바꿔준다.
Page Table
1. Page Table Entries
- page table 한 줄에 들어있는 정보 (1mb)
- Valid Bit
- Reference Bit
- Modify Bit
- Protection Bit
- Frame Number
2. Page Table Structure
- process가 증가할 수록 page table이 많아진다 -> 느려진다(성능 이슈)
- page table을 줄이는 방식을 고안 (아래 3가지 방식)
- Managing Page Table
- Hierarchical paging
- Hashed page table
- Inverted page table
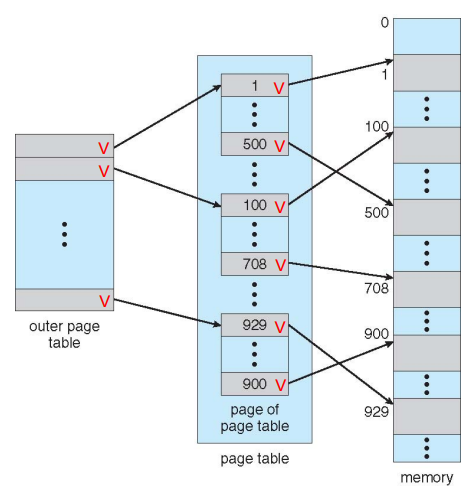
3. Hierarchical Page Tables
-
page table의 하나의 크기가 큰 것이 문제
-
logical address 공간을 두개의 page table로 쪼개서 page table이 차지하는 메모리 크기를 절약
-
cf) single level paging의 경우
page table = 4mb -
hierarchical paging 예시
case1) 모든 page가 사용될 때
outer page table = 4byte = 4kb
page table = 4byte = 4mb
-> single level paging 보다 4kb 더 많이 사용된다.
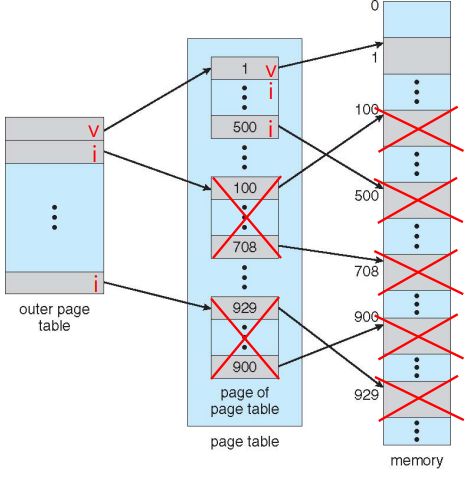
case2) 하나의 page만 사용될 때
outer page table = 4byte = 4kb
page table = 4byte = 4kb
-> single level paging 보다 적은 메모리 사용된다.
-> (4mb - 8kb) 만큼 절약
4. Hashed Page Tables
- hashing 기술 이용
5. Invented Page Tables
- frame table을 만들어서 사용 -> 중복해서 page table을 여러 번 만들지 않는다.
- 하드웨어적으로 구현하기 어려운 구조여서 실제로 사용하지 않는다.
Shared Pages
1. Shared Pages Example
- paging을 사용하지 않을 경우 fork를 사용하면 똑같은 모습의 메모리 구조가 복사되고 page table 또한 하나 더 생기게 되어 메모리 낭비가 심해진다.
- paging을 사용하는 경우 frame number를 공유해서 사용할 수 있다.
2. Advantages of Paging
- Easy to allocate physical memory
- No external fragmentation
- Easy to "page out" chunks of a program
- Easy to protect pages
- Easy to share pages
- dynamic linking을 할 때 쓰는 shared library를 physical memory에 넣어두고 공유해서 사용할 수 있다.
3. Disadvantages of Paging
- Internal fragmentation
- Memory reference overhead
- 메모리에 두 번 access 해야하는 과정이 생길 수 있다.
- TLB를 통해 해결
- Memory required to hold page tables can be large
- page table을 위한 공간이 필요해서 메모리 차지가 많아진다.
- hierarchical paging, hashed paging 등을 통해서 줄이는 방식 사용한다.
Segmentation
1. Overview
- 각 메모리들을 의미있는 조각들로 쪼개는 방식
- 해당 메모리가 나타내는 내용이 무엇인지 알 수 있어 protection이 쉽다.
- 문제점: Segmentation은 쪼갠 조각들의 크기가 달라서 external fragmentation이 발생한다.
- 해결: 의미있는 단위로 쪼갠 Segmentation의 내부를 paging 하는 방식
2. Segmentation Hardware
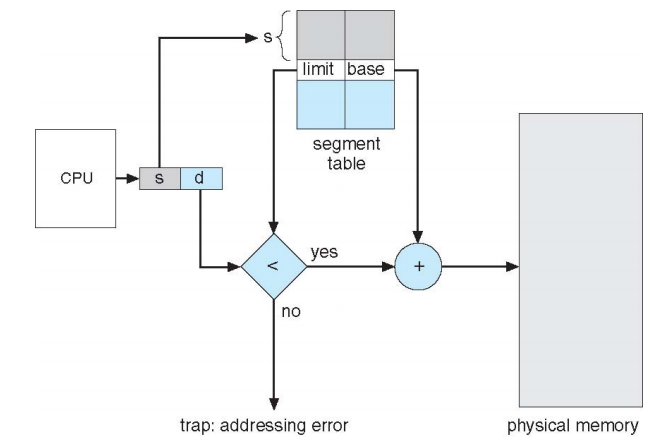
- page table 보다 segment table의 크기가 유의미하게 작아지지는 않는다.
-> 메모리 절약 기능은 없음 - 의미있는 단위로 쪼개기 때문에 code segment등을 공유해서 사용하기 용이하다.
-> page table 보다 좋은 점 - limit 값을 이용해서 protection 실행
- paging과 contiguous allocation을 합친 것과 유사한 동작
3. Advantages of Segmentation
- Simplifies the handling of data structures that are growing or shrinking
- Easy to protect segments
- Easy to share segments
- No internal fragmentation
4. Disadvantages of Segmentation
- Cross-segment address
- Large segment tables
- External fragmentation
Paging vs Segmentaion
1. Hybrid approaches
- Paged segments : segments 들을 각각 다른 page size로 paging 하기
- multiple page sizes : internal fragmentation을 줄이기 위해서 각각의 segments 마다 다른 page size를 사용하기
2. Segmentaion with Paging
3. Segmentation with Paging in Pentium
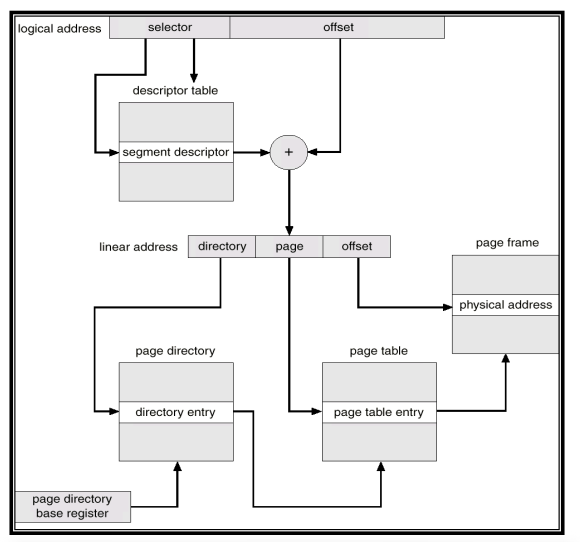
- sector = segment
- page table이 계층구조를 가지며 각자 다른 동작을 수행한다.
- 계층 구조를 가지기 때문에 메모리를 좀 더 차지하여 overhead가 발생하지만 overhead를 감수하고 얻는 이득이 더 크기에 사용하는 방식
4. Examples
- IA-32 segmentation
- IA-32 paging
- two-level paging
- multiple page size
- IA-32 PAE
- Two-level Paging in ARM
- segmentation 사용하지 않고 계층 page table(2 level)을 사용한다.
- ARMv8 : 4 level hierarchical paging
5. x86 -> x64

- 64 bit system으로 커진 만큼 해당 bit를 다 사용하는 것 보다 48bits만 사용하고 나머지는 안쓴다.
- 커진 만큼 다 사용하는 것이 의미가 없다. (너무 커서 공간이 남는다.)
- 적게 사용한 만큼 page table의 크기가 작아지기 때문에 trade off를 고려해서 사용하기
