
운영체제 수업 + Operating System
Concepts 10E 정리 내용
Operating System Ch10 : Virtual memory
Virtual Memory
1. Overview
- Physical Memory는 resource의 한계가 존재한다.
- physical memory가 꽉 차서 못쓰는 상황 -> 디스크에서 frame 사이즈와 같은 크기로 만든 자료구조를 이용
- physical memory와 디스크의 swap을 통해 공간을 만들어 physical memory크기보다 더 큰 공간을 사용할 수 있게 해준다.
2. Demand Paging
- logical 영역 : 프로그램이 실행하는데 필요한 영역이 한번에 다 생성된다.
- demand paging : run time에 disk에 있는 것 중에서 필요한 것만 올리는 방식
- 필요한 것을 필요할 때에 가져오기
- 메모리를 아낄 수 있고 효율적이다. (locality를 잘 이용할 수 있다)
- 순서
- TLB miss -> page table 보기 -> invalid -> exception -> OS의 개입
1) page fault : disk에서 필요한 것을 가져와서 실행
2) protection fault : trap
- TLB miss -> page table 보기 -> invalid -> exception -> OS의 개입
- cf) process에서 swap in/out : 전체 프로세스를 모두 올리고 내리는 것을 결정하기
- long, mid term scheduling이 사라진 이유
- locality 특성으로 인해 더욱 효율적으로 동작한다.
- caching이 locality의 특성을 극대화
- locality in a memory-reference pattern을 보면..
- 가로축으로 연속된 형태 : temporal locality
- 세로축으로 연속된 형태 : spatial locality
3. Memory Protection in Paging
- virtual memory 없는 경우 : page table의 valid bit에 invalid가 체크되어있을때 접근한다면 무조건 protection fault이므로 trap이 발생한다.
- virtual memory가 있는 경우 : page table의 valid bit가 invalid인 경우 protection fault와 page fault 두 가지 경우가 존재한다.
- protection fault : trap
- page fault : 디스크에 접근해서 swap
- 실행 이후 한 번도 access가 되지 않은 page는 invalid 이다.
4. Page fault
- page fault 발생 시 처리
- hardware : 매우 복잡하게 구현
- OS : 대체로 사용하는 방식 (hardware의 기능/발전 덕분에 계산을 쉽게 할 수 있게 되었다)
- Steps in Handling a Page Fault
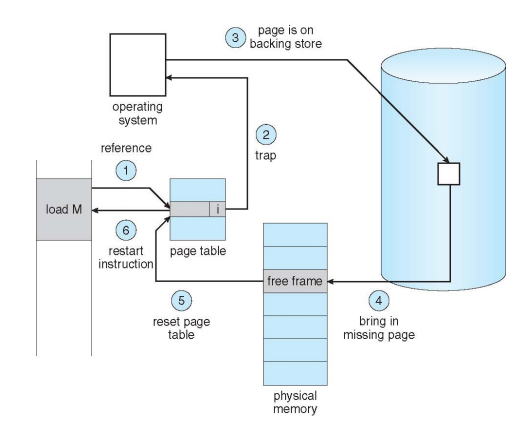
5. Memory Reference
- Memory reference 종류
1) TLB hit : 바로 memory 접근 (이전에 한번 써서 caching이 된 경우 - 99% 차지)
2) TLB miss : page table 참조 -> 원하는 정보를 찾아서 TLB로 업데이트
3) TLB miss 후 page table에도 정보가 없는 경우 : page fault or protection fault로 처리 - 순서
1) CPU가 메모리를 참조할 때 TLB를 먼저 참조
2) 맨 처음에 TLB를 참조한 순간 page table은 모두 invalid로 체크되어있어 cache miss가 발생 (처음 실행 시 느림)
3) 실행하다 보면 TLB와 page table이 채워진다. (TLB hitting range가 99%를 넘게 된다) - 위의 과정을 통해 실제로 physical memory를 넘어서는 작업을 하더라도 유저 입장에서 느려지는 것을 잘 느끼지 못한다. (cache의 기능)
- cache hit 증가 : hot cache / cache hit 감소 : cold cache
- TLB miss 상황
- page table 자체가 out된 경우
- 거의 일어나지 않는 상황
- cache miss가 일어나서 page table을 보려고 하니 page table이 없는 경우
- swap out 한 것이 page table인 경우
- OS 처리 : 잘 사용하지 않는다.
- hardware 처리 : 대체로 사용하는 방식
- page faults
- page fault가 발생하면 io가 많아지면 느려질까? -> 아니다.
- 올라가 있지 않은 영역을 CPU가 찾으러 가는 상황
- TLB miss
- page table invalid
- OS가 처리
6. Copy-on-Write
- fork() 상황
- physical memory는 같다. -> physical memory영역을 공유하기
- 한 프로세스가 업데이트 되어 업데이트 한 page가 있다면 새로운 frame을 받아와서 처리한다.
- exec() 상황
- 성능 향상
- demanding paging으로 필요한 것을 필요할 때 하나씩 올린다.
No free Frame issue
1. Overview
- physical memory가 꽉 찬 경우 physical memory 중 하나를 골라서 디스크로 swap out 시키기
- 어떤 physical memory를 swap out 할 것인지를 결정하는 문제
2. Page replacement
- 어떤 memory를 내릴 것인지 결정해서 내리는 작업
- OS가 담당
- 여러 알고리즘 존재
- 동작 과정
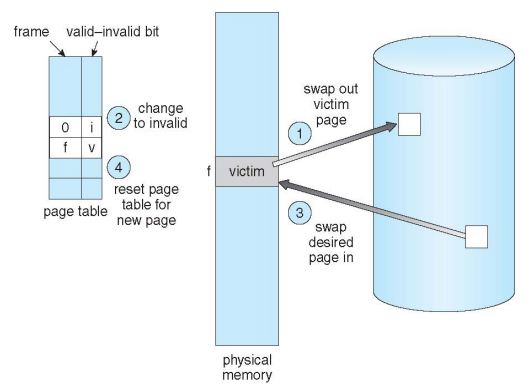
3. Performance of Demand Paging
- Effective Access Time (EAT)
- page fault rate :
- EAT = memory access (page fault overhead + [swap page out] + swap page in + restart overhead)
4. Page replacement Algorithms
- page replacement의 목적 : 다시 참조되지 않을 법한 것을 내려야 page fault의 비율을 줄일 수 있다.
- example
- A 방식 : frame을 작게 할당
- B 방식 : frame을 크게 할당
- A의 page fault가 더 많이 발생한다.
- but 특정 process의 frame 갯수가 5~6개가 되면 이후로 page fault의 수가 비슷하게 유지된다. (locality 특성)
- 5~6개보다 많이 frame을 할당할 필요가 없다.
Page replacement Algorithms
- 한 프로그램에서 많이 사용하는 frame을 예측해서 많이 사용되는 것은 유지하고 많이 쓰지 않는 것을 내리는 것이 좋은 방식이다.
1. FIFO
- 먼저 들어온 frame이 먼저 나가는 방식
- swap in 하고 가장 오래된 것을 먼저 빼기
- 효율성 x
- example
- frame 수가 많아졌는데 page fault가 더 많아지는 case도 존재한다.
- 비효율적이다.
- 도착 시간만을 생각하는 알고리즘은 page replacement의 목적에 부합하지 않는다.
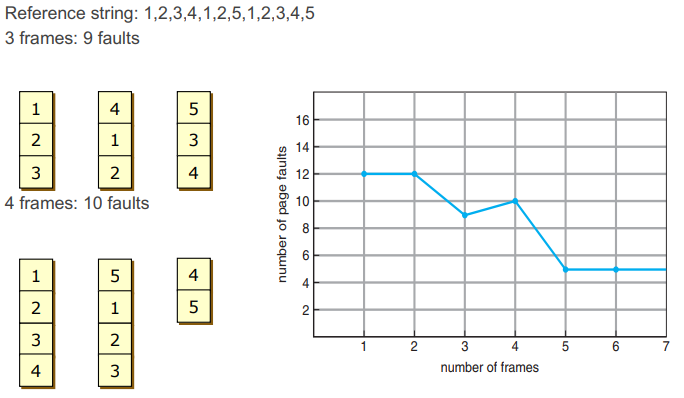
2. Optimal Algorithm
- 과거를 보고 현재 상태를 예측하는 방식
- locality 특성을 활용
- LRU, NRU, LFU
3. LRU Algorithm
- Least Recently Used (LRU) Algorithm
- 최근에 가장 사용되지 않은 것을 내리는 방식 -> 거의 optimal 하다
- time stamp를 통해 특정 시점의 시간 정보르 표시해야 한다.
- time stamp 찍기 : 참조될 때 마다 참조되는 page에 대해서 time stamp를 찍는 방식
- 단점
- 시간 정보를 남기려면 4~8bit 정도의 크기가 필요 (메모리 차지)
- 매번 참조할 때 마다 시간 정보를 가져와야 하므로 overhead가 크다
- time stamp 방식 해결 방안
- stamp를 찍지 말고 stack을 이용해서 오래된 순으로 쌓아두면 정확한 시간 정보를 몰라도 오래된 것이 무엇인지 알 수 있다.
- stack 방식의 문제점 : 마찬가지로 stack을 OS가 관리해야 하므로 overhead가 크다.
- stack 방식 해결 방안
- time stamp의 bit를 1bit로 줄여서 가지고 있으며 대략적으로 시간 정보를 관리
- 처음에는 0 저장되고 사용되면 1로 저장
- timer interrupt가 발생하면 모든 bit를 0으로 초기화 해줘야 한다.
- 간소화된 time stamp 방식의 문제점
- 특정 주기 안에서 해당 page가 참조된 것인지 아닌지만 확인
- reference bit가 1인 경우가 다수 존재하면 누가 먼저 들어온 것인지 확인 불가능하다.
- 간소화된 time stamp 방식 해결 방안
- LRU clock사용
- LRU clock
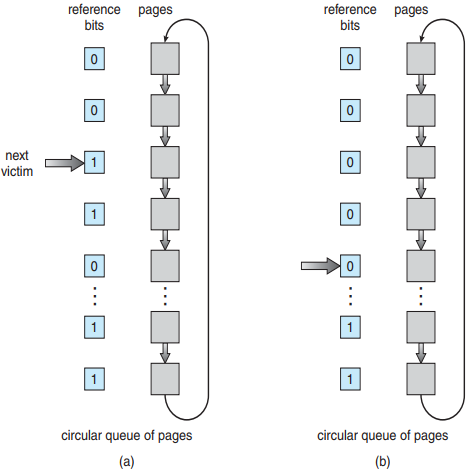
- 참조가 되면 refernce bit가 0에서 1이 된다.
- next victim이 가리키는 것을 보면서 1인 경우 (최근에 참조됨) 0으로 바꾸고 해당 bit의 아래 bit를 확인하여 처음으로 0을 발견하면 해당 bit를 victim으로 선정하여 다음에 초기화를 해야 할 때 먼저 초기화시킬 bit를 가리키기
-> 다음 timer interrupt가 발생 이전에 page fault가 일어나면 먼저 내려야 할 것을 미리 정해두는 작업! - NRU 알고리즘보다 성능이 좋지 않아서 사용하지 않는 방식이다.
4. NRU algorithm
- Not Recently Used (NRU)
- 정보를 read만 한 것인지 write까지 한 것인지 확인 (modify bit 사용)
- page table entry에 modified bit를 추가
- page table에 reference bit와 modify bit 두개가 존재
- 동작 방식
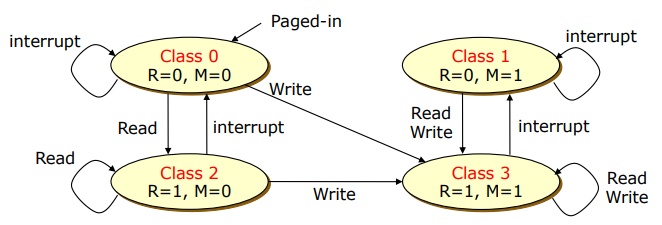
- class 0 에서 시작 -> interrupt가 들어옴
- reference bit 초기화
- read만 한 경우 reference bit를 1로 설정 -> class 2
- write 한 경우 modify bit 1로 설정 -> class 3
- modify bit가 한번 1로 설정되면 다시 0으로 설정되는 경우가 없다.
- class number가 낮은 것이 먼저 replacement된다.
- class 1 vs class 2
- reference bit가 1인 것은 이전 timer interrupt 이후 최근에 한번 참조가 된 것 (modify bit가 1인 것은 언제 참조된건지 알 방법이 없기 때문)
- class 1이 class 2 보다 먼저 replacement 된다.
- 특징
- 구현하기 쉽다. Optimization 쉽다.
- hardware 제조사에서 결정한 동작 방식
- PTE

- reference bit : LRU, NRU
- modift bit : NRU
- CPU hardware에 의해서 결정된 모습
5. LFU algorithm
- Least Frequently Used (LFU)
- count 횟수가 가장 적은 것을 victim으로 선정하기
- count 횟수를 저장해야 할 공간이 필요하다 -> overhead
- overhead는 approximation으로 해결한다. (1 bit로 처리) -> LRU와 같아짐
- Aging
- shift register로 구현
- 한 프로세스가 6개의 page를 사용, 참조되는 page와 참조 되지 않은 page를 남겨두기
- 한 page당 8bit를 더 사용해야 하는 구조 -> overhead
Allocation of Frames
1. Overview
- Logical memory : page
- Physical memory : frame
- Allocation algorithms : 운영체제 위에서 여러 개의 process가 동작할 때 frame을 골고루 나눠주는 방식
- Allocation algorithm 종류
- equal allocation : 동등하게 분배
- proportional allocation : process 사이즈에 따라 분배
- priority-based allocation : process의 우선순위에 따라 분배
- Page replacement
- Global replacement
- NRU 알고리즘 page table에서 사용하는 방식
- 모든 page의 모든 page table을 검색해야 한다.
- Local replacement
- 자신의 process 안에서만 생각하는 방식
- page fault가 일어나야 replacement가 일어날 수 있다.
- 현재 사용하는 방식
- Global replacement
2. Page-Fault Frequency Scheme
- x축 frame 갯수 / y축 page fault 비율
- 시스템 전체를 관점으로 했을 때
- page fault rate가 lower bound 보다 아래에 있으면 frame을 과하게 분배한 경우 -> frame 뺏기
- page fault rate가 upper bound 보다 위에 있으면 동작하는 것에 비해서 frame이 적다. -> frame 더 주기
- 이러한 시스템에 process의 우선순위까지 고려하는 방식이 현재 OS의 동작 방식이다.
Thrashing
1. Overview
- Thrashing : page fault의 비율이 높은 현상 / CPU utilization이 최고점을 가지 못했는데 떨어지는 상황
- 상황
- 멀티 프로그래밍 환경에서 process가 많아질수록 CPU utilization이 좋아진다.
- 특정 순간 이후로 CPU utilization이 떨어진다. -> physical memory가 꽉 찬 상황 -> swap이 많이 필요
- page replacement (io)를 수행해야 한다.
- io처리를 하면 CPU는 일을 못하므로 성능이 안 좋아지는 것
- 현재 시스템의 process의 locality 총 합이 전체 메모리 크기보다 클 때 발생 -> swap이 계속 일어나야 하는 상황
- 해결 방식 : degree of multiprogramming 수를 줄이기
2. Working-Set Model
- 성능 측정을 위한 모델
- delta 시간 동안에 필요한 frame의 갯수
- delta를 움직이면서 peak가 언제인지 측정
- working set이 적당한 것을 찾기
Other Considerations
1. Preparing
- 하드웨어를 볼 때 부분만 보고 돌아오면 arm seak time등으로 overhead가 발생하기 때문에 한번 볼 때 끝까지 다 보고 돌아오는 것
2. Page Size Selection
- 다양한 size의 page를 사용한다. 아래 네가지를 통해 결정
1) fragmentation : page가 작을수록 internal fragmentation 감소
2) page table size : page가 클수록 page entry 갯수가 감소, page table size 감소
3) io overhead : page가 크면 overhead 감소
4) locality : 적당한 사이즈 찾기 (trade off 개념)
3. TLB Reach
- TLB : MMU안에 존재하는 cache 메모리
- TLB Reach : page hit이 발생 시 실제로 접근 가능한 메모리의 총량, 높을수록 성능이 좋다.
- TLB Reach = TLB size * page size
- TLB size를 늘리거나 page size를 늘려야 TLB Reach가 증가한다.
4. Program Considerations (중요)
- 설정
- 하나의 row당 4kb의 크기 (한 row가 page table 하나의 크기)
- page table이 1k만큼 존재
- 프로그램을 짤 때 바깥 for문이 행, 안쪽 for문이 열로 구성
- 예시

- 위의 program
- j=0일 때 처음 page의 0번째 접근, 두번째 page의 0번째 접근 ...(i가 증가함에 따라 다른 page 접근)
-> 1024번의 page fault 발생 - j가 증가함에 따라 page fault가 1024번 발생
- 총 page fault = 1024 1024 -> 성능 안좋다
- j=0일 때 처음 page의 0번째 접근, 두번째 page의 0번째 접근 ...(i가 증가함에 따라 다른 page 접근)
- 아래 program
- i=0일때 안쪽 for문 돌 동안 page 하나로 처리 가능
-> page fault 한번 - 총 page fault = 1 1024 -> 위의 program보다 성능 좋다.
- i=0일때 안쪽 for문 돌 동안 page 하나로 처리 가능
- 위의 program
5. DMA 처리
- IO Interlock : disk가 메모리에 직접 접근할 때 buffer 관리 방식
- OS가 DMA 전용의 메모리 buffer를 준다 (IO interlock)
- OS만 사용하는 방식
