
pandas의 1차원 자료형 - Series
- 1차원적인 데이터 형식
- 파이썬의 딕셔너리와 유사함
import pandas as pd
a = {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e' : 50}
a
> {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}type(a)
> dictb = pd.Series(a)
b
> a 10
b 20
c 30
d 40
e 50
dtype: int64type(b)
> pandas.core.series.Seriesb.shape
> (5,)import numpy as np
aa = np.arange(3, 10)
aa
> array([3, 4, 5, 6, 7, 8, 9])bb = pd.Series(aa)
bb
> 0 3
1 4
2 5
3 6
4 7
5 8
6 9
dtype: int32type(bb)
> pandas.core.series.Seriesbb.shape
> (7,)a
> {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}a.keys()
> dict_keys(['a', 'b', 'c', 'd', 'e'])a.values()
> dict_values([10, 20, 30, 40, 50])b
> a 10
b 20
c 30
d 40
e 50
dtype: int64b.index # 이름을 차지하는 것들이 출력됨, object = 문자열
> Index(['a', 'b', 'c', 'd', 'e'], dtype='object')b.values
> array([10, 20, 30, 40, 50], dtype=int64)c = [10, 20, 30, 40, 50]
d = pd.Series(c)
d # 딕셔너리타입이 아니거나 따로 채워주지 않으면, 인덱스 부분은 0부터 시작
> 0 10
1 20
2 30
3 40
4 50
dtype: int64type(d)
> pandas.core.series.Seriesd.shape
> (5,)d.index
> RangeIndex(start=0, stop=5, step=1)d.values
> array([10, 20, 30, 40, 50], dtype=int64)e = ['a','b','c','d','e']
f = [10, 20, 30, 40, 50]
g = pd.Series(f, index = e) # 원하는 인덱스 설정
g
> a 10
b 20
c 30
d 40
e 50
dtype: int64g['a']
> 10g[0]
> 10g['a':'d'] # 위치정보가 아니라면 (마지막번째-1)이 아니라 마지막번째까지 나옴, 인덱스의 이름
> a 10
b 20
c 30
d 40
dtype: int64g[0:4]
> a 10
b 20
c 30
d 40
dtype: int64pandas의 2차원 자료형 - DataFrame (1)
- 2차원적인 데이터 형식
- 행렬 구조를 가짐
import pandas as pd
# 딕셔너리, 리스트로 만들기
a = {'a' : [1,2,3],'b' : [1,3,5],'c' : [2,4,6],'d' : [3,6,9]}
df1 = pd.DataFrame(a)
df1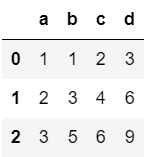
type(df1)
> pandas.core.frame.DataFramedf1.shape
> (3, 4)df1.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 a 3 non-null int64
1 b 3 non-null int64
2 c 3 non-null int64
3 d 3 non-null int64
dtypes: int64(4)
memory usage: 224.0 bytesimport numpy as np
# numpy로 만들기
b = np.arange(12).reshape(3,4)
b
> array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])df2 = pd.DataFrame(b)
df2 # 컬럼명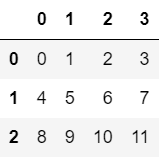
type(df2)
> pandas.core.frame.DataFramedf2.shape
> (3, 4)df2.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 0 3 non-null int32
1 1 3 non-null int32
2 2 3 non-null int32
3 3 3 non-null int32
dtypes: int32(4)
memory usage: 176.0 bytes# pandas로 바로 만들기, 컬럼명 지정 가능
df = pd.DataFrame([[1,20,'서울'],[2,25,'대전']],
index = ['짱구','철수'], # 행
columns = ['순서', '나이','지역']) # 열
df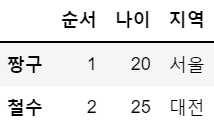
type(df)
> pandas.core.frame.DataFramedf.shape
> (2, 3)df.info()
> <class 'pandas.core.frame.DataFrame'>
Index: 2 entries, 짱구 to 철수
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 순서 2 non-null int64
1 나이 2 non-null int64
2 지역 2 non-null object
dtypes: int64(2), object(1)
memory usage: 64.0+ bytesdf.index
> Index(['짱구', '철수'], dtype='object')df.columns
> Index(['순서', '나이', '지역'], dtype='object')df.values
> array([[1, 20, '서울'],
[2, 25, '대전']], dtype=object)df.index = ['진구','이슬이'] # 인덱스명 바꾸기
df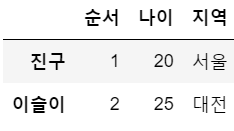
df.columns = ['번호', '연령', '고향']
df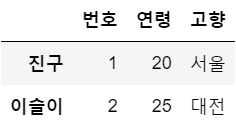
df = df.rename(index={'이슬이':'퉁퉁이'}) # 전체가 아닌 특정 인덱스/컬럼을 바꾸는 것도 가능, 가로 안에 딕셔너리 형태로
df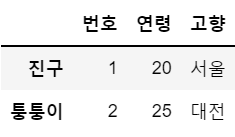
df = df.rename(columns={'번호':'순서', '연령':'나이'})
df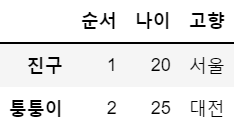
pandas의 2차원 자료형 - DataFrame(2)
- 행 추가 : df.loc['인덱스명'] = [넣고 싶은 값1, 넣고 싶은 값2,..]
- 열 추가 : df[ ] = [넣고 싶은 값1, 넣고 싶은 값2, ..]
- 값 변경 :
- df[ ] = '넣고 싶은 값'
- df.loc['인덱스명', '컬러명1'] = '컬럼명1에 들어갈 값'
- df.iloc[위치정보 행 인덱스, 열 인덱스] = '넣고 싶은 값'
- 여러 개일 경우 df.loc['인덱스명', ['컬러명1','컬럼명2',..] = '넣고 싶은 값1', '넣고 싶은 값2', df.iloc도 숫자만 바뀌고 동일
- 행 삭제 : df.drop('인덱스명', axis = 0)
- 열 삭제 : df.drop('컬럼명', axis = 1)
df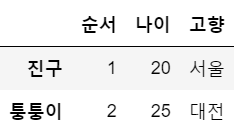
df.loc['비실이'] = [3, 22, '인천'] # 행 추가
df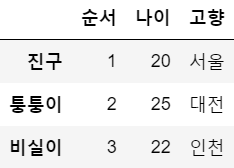
df.loc['이슬이'] = 0 # 모든 값에 0이 들어감
df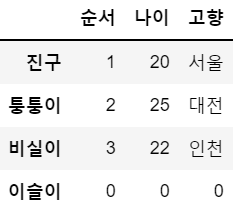
df.loc['도라에몽'] = df.loc['퉁퉁이'] # 퉁퉁이랑 똑같이 만들어라~
df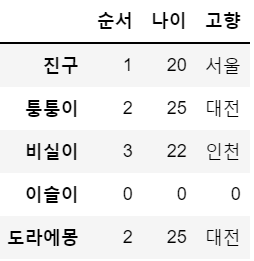
df['나이대'] = ['20대', '20대', '20대', '0대', '20대' ] # 열 추가
df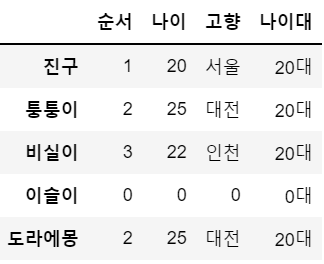
df['직업'] = '학생' # 똑같은 값으로 열 채우기
df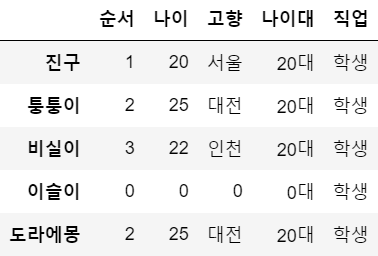
df.loc['이슬이','순서'] = 4 # 인덱스명 활용
df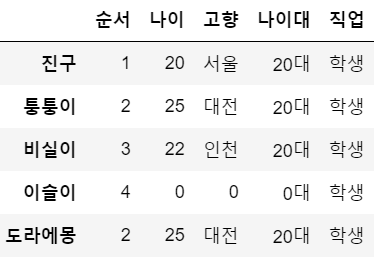
df.iloc[3, 1] = 20 # 세번째 행(진구부터), 첫번째 열, 위치정보 활용
df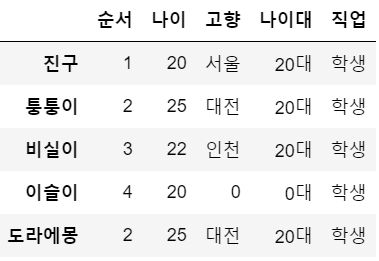
df.loc['이슬이',['고향','나이대']] = '부산', '20대'
df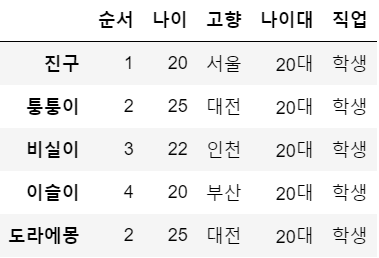
df.iloc[4,[1,3]] = 54, '50대'
df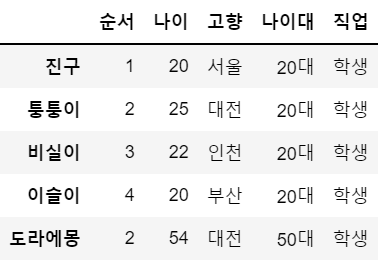
df = df.drop('퉁퉁이', axis = 0) # 행 삭제
df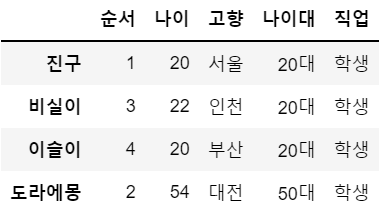
df = df.drop(['나이대','직업'], axis = 1) # 열 삭제, 여러 개일 경우는 리스트 형태로 입력
df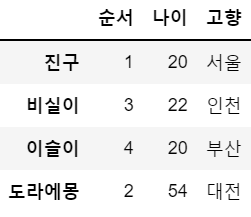
pandas의 2차원 자료형 - DataFrame(3)
- 전체 복사
- 부분 복사
df2 = df
df2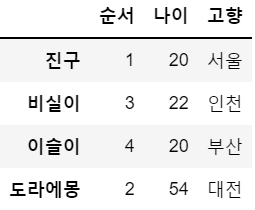
df2.loc['이슬이','순서'] = 3
df2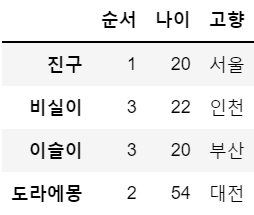
df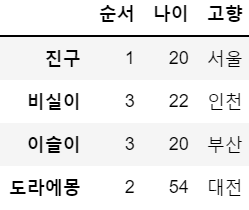
df3 = df.copy()
df3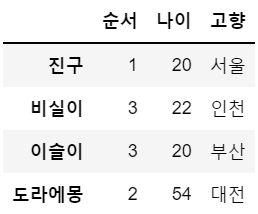
df3.loc['비실이','순서'] = 2
df3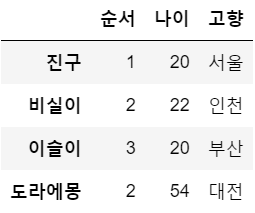
df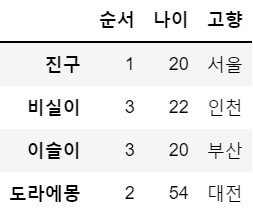
jin = df.loc['진구'] # 진구에 대한 정보만 저장
jin
> 순서 1
나이 20
고향 서울
Name: 진구, dtype: objecttype(jin)
> pandas.core.series.Seriesjin.shape
> (3,)dora = df.iloc[0]
dora
> 순서 1
나이 20
고향 서울
Name: 진구, dtype: objecttype(dora)
> pandas.core.series.Seriesdora.shape
> (3,)df4 = df.loc[['진구','이슬이']] # 2차원 형태로 가져오기
df4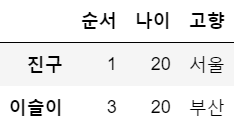
type(df4)
> pandas.core.frame.DataFramedf5 = df.iloc[[0,3]] # 0번째, 3번째를 가져오겠다~
df5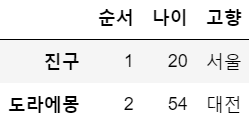
df6 = df.loc['진구':'이슬이']
df6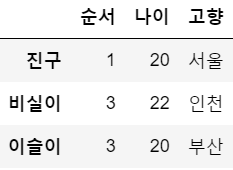
df7 = df.iloc[0:3]
df7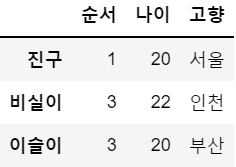
df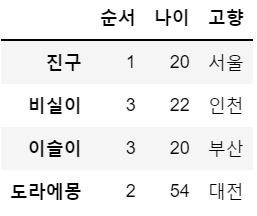
df8 = df[['고향']] # 대괄호가 2개여야 DataFrame이 유지됨
df8
df9 = df['나이'] # 시리즈 형태로 바뀜
df9
> 진구 20
비실이 22
이슬이 20
도라에몽 54
Name: 나이, dtype: int64type(df8)
> pandas.core.frame.DataFrametype(df9)
> pandas.core.series.Seriesdf10 = df[['나이', '고향']]
df10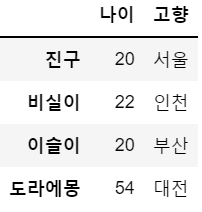
df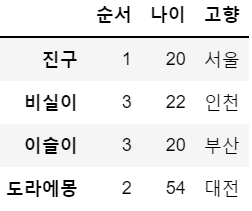
df11 = df.loc[['진구','도라에몽'],['나이','고향']] # 원하는 정보만 빼내고 싶을 때, 인덱스명, 컬럼명
df11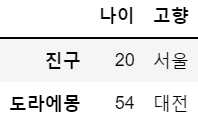
df12 = df.iloc[[0,3],[1,2]] # 행 인덱스, 열 인덱스
df12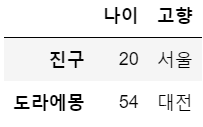
pandas의 2차원 자료형 - DataFrame(4)
- 인덱스
- 정렬
- 전치
- 치환
a = {'이름': ['짱구', '철수', '맹구'], '나이': [15, 30, 22], '고향': ['서울', '서울', '부산'] }
a
> {'이름': ['짱구', '철수', '맹구'], '나이': [15, 30, 22], '고향': ['서울', '서울', '부산']}df = pd.DataFrame(a)
df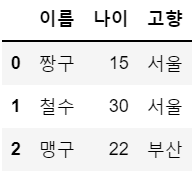
df2 = df.set_index(['이름']) # 이름이 인덱스명이 되도록 해주는
df2
df3 = df2.set_index(['고향']) # 원래 있던 인덱스는 사라지고 새로운 인덱스가 겹쳐짐
df3
df2
df3 = df2.reset_index() # 원래대로 돌아감
df3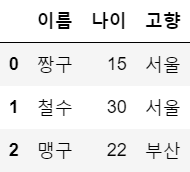
df3 = df3.set_index(['고향'])
df3
df2 = df2.sort_index(ascending = True) # 인덱스명을 기준으로 오름차순
df2
df2 = df2.sort_index(ascending = False)
df2
df2 = df2.sort_values(by = '나이') # 값에서 나이 컬럼명 기준으로 오름차순 정렬
df2
df2 = df2.sort_values(by = '나이', ascending = False) # 값에서 나이 컬럼명 기준으로 내림차순 정렬
df2
df2 = df2.T # 전치
df2
df2 = df2.T
df2
df2['나이대'] = ['30대','20대','10대']
df2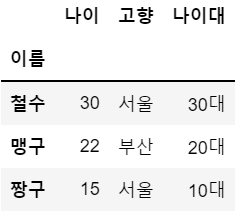
df2 = df2.reset_index()
df2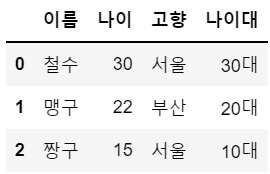
b = {'10대': 1, '20대': 2, '30대': 3}
df2['나이대'] = df2['나이대'].map(b) # map을 사용해서 규칙을 사용해 문자를 숫자형태로 바꾸고 싶다~
df2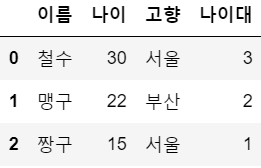
df2.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 3 entries, 0 to 2
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 3 non-null object
1 나이 3 non-null object
2 고향 3 non-null object
3 나이대 3 non-null int64
dtypes: int64(1), object(3)
memory usage: 224.0+ bytes
느리지만 확실하게