
pandas의 기본연산 - Series
import pandas as pd
a = {'a': 10,'b': 20,'c': 30,'d': 40,'e': 50}
a
> {'a': 10, 'b': 20, 'c': 30, 'd': 40, 'e': 50}type(a)
> dictb = pd.Series(a)
b
> a 10
b 20
c 30
d 40
e 50
dtype: int64type(b)
> pandas.core.series.Seriesc = b / 10
c
> a 1.0
b 2.0
c 3.0
d 4.0
e 5.0
dtype: float64c = b// 10
c
> a 1
b 2
c 3
d 4
e 5
dtype: int64type(c)
> pandas.core.series.Seriesd = b + c
d # 짝지어서 더해짐
> a 11
b 22
c 33
d 44
e 55
dtype: int64e = {'a': 10,'c': 20,'e': 30,'g': 40}
e
> {'a': 10, 'c': 20, 'e': 30, 'g': 40}f = pd.Series(e)
f
> a 10
c 20
e 30
g 40
dtype: int64d + f # 인덱스가 같은 것끼리 더해지고 다른 것은 x
> a 21.0
b NaN
c 53.0
d NaN
e 85.0
g NaN
dtype: float64d.add(f, fill_value = 0) # 한 쪽만 있는 값(결측치) 처리, 0으로 채워줌
> a 21.0
b 22.0
c 53.0
d 44.0
e 85.0
g 40.0
dtype: float64d.sub(f, fill_value = 0) # 뺄셈도 가능
> a 1.0
b 22.0
c 13.0
d 44.0
e 25.0
g -40.0
dtype: float64d.mul(f, fill_value = 1) # 곱셈도 가능, 곱셈은 1로 해주면 좋음
> a 110.0
b 22.0
c 660.0
d 44.0
e 1650.0
g 40.0
dtype: float64d.div(f, fill_value = 1) # 0은 무한대로 갈 수 있으므로, 1 이상 / 분석 목적에 맞게
> a 1.100000
b 22.000000
c 1.650000
d 44.000000
e 1.833333
g 0.025000
dtype: float64pandas의 기본 연산 - DataFrame 1
결측치
- A.add(B, fill_value = 0 ) : 더하기
- A.sub(B, fill_value = 0 ) : 빼기
- A.mul(B, fill_value = 1 ) : 곱셈
- A.div(B, fill_value = 1 ) : 나누기
a = { '국어':[10, 20, 30], '수학': [30, 40, 50]}
a
> {'국어': [10, 20, 30], '수학': [30, 40, 50]}df1 = pd.DataFrame(a)
df1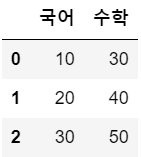
b = { '국어':[100, 200, 300], '영어': [200, 400, 600]}
df2 = pd.DataFrame(b)
df2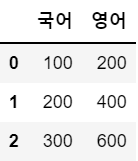
df3 = df1 + df2
df3 # 한쪽이라도 결측이 있으면 계산이 안된다.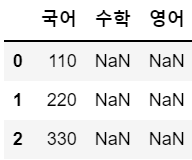
df1.add(df2, fill_value = 0 )
df4 = df1.add(df2, fill_value = 0 )
df4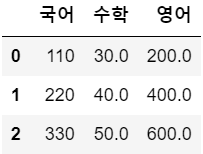
df4 = df1.sub(df2, fill_value = 0 )
df4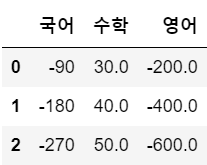
df4 = df1.mul(df2, fill_value = 1 )
df4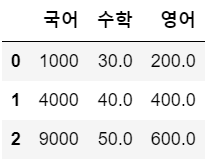
df4 = df1.div(df2, fill_value = 1 )
df4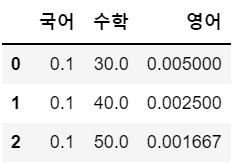
pandas의 기본연산 - DataFrame2
- 합치기 : pd.merge(left = A, right = B, how = 'left / right',
left_on = 기준 필드명, right_on = 기준 필드명)
a = { '이름': ['도라에몽', '도라미', '진구'], '나이': [20,30,24]}
df1 = pd.DataFrame(a)
df1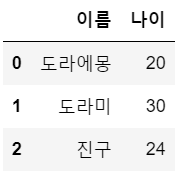
b = { '이름': ['도라에몽', '도라미', '진구'], '고향': ['서울', '부산', '천안']}
df2 = pd.DataFrame(b)
df2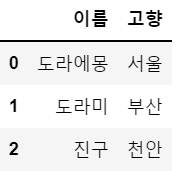
df = pd.merge(left = df1,
right = df2,
how = 'left',
left_on = '이름',
right_on = '이름')
df # 동일한 기준 외에 다른 정보들이 있을 때, 동일한 정보를 기준으로 합침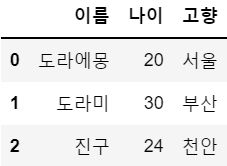
x1 = (df['고향'] == '서울') # 조건 생성
df[x1]
x2 = (df['고향'] != '서울') # 조건 생성
df[x2]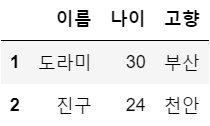
x3 = (df['나이'] < 30) # 조건 생성
df[x3]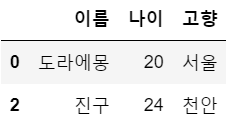
x4 = (df['고향'] == '서울') | (df['나이'] < 30) # 중복조건 생성 & |
df[x4]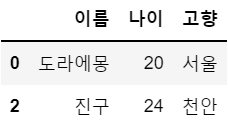

느리지만 확실하게