
학습용 데이터 다루기_ iris
- .head() : 데이터의 앞부분의 일정부분을 볼 수 있음, 보통 5개
- .tail() : 데이터의 뒷부분의 일정부분을 볼 수 있음, 보통 5개
- .info() : 데이터의 기본정보
- .shape() : 행,열
- .type() : 타입
- .describe() : 요약통계량, .describe(include = 'all')하면 모든 기본적인 통계정보 제공
- 데이터셋['원하는 칼럼명'].value_counts(), 데이터셋.원하는 칼럼명.value_counts() :
원하는 칼럼명에 해당하는 각 항목들에 해당하는 개수를 알려줌
import warnings
warnings.filterwarnings('ignore') # 불필요한 경고 메시지 무시import pandas as pd
import seaborn as sns
iris = sns.load_dataset('iris')
iris.head()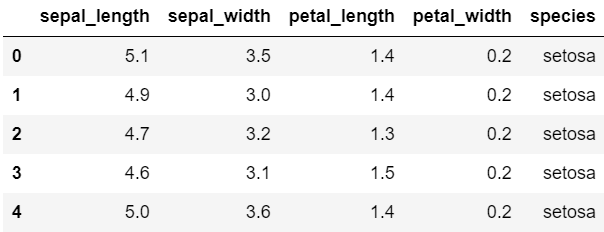
iris.head(10)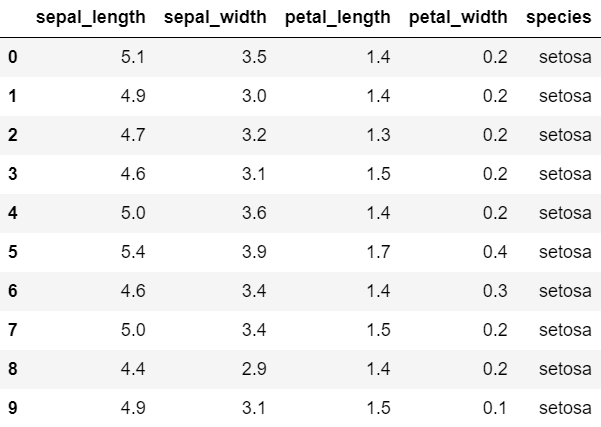
iris.tail()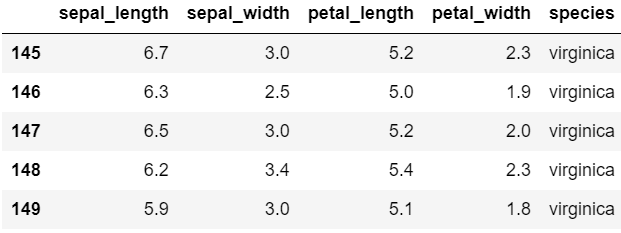
type(iris)
> pandas.core.frame.DataFrameiris.info() # 150행, 5열
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length 150 non-null float64
1 sepal_width 150 non-null float64
2 petal_length 150 non-null float64
3 petal_width 150 non-null float64
4 species 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KBiris.shape
> (150, 5)iris.describe() # 문자열은 빠져있음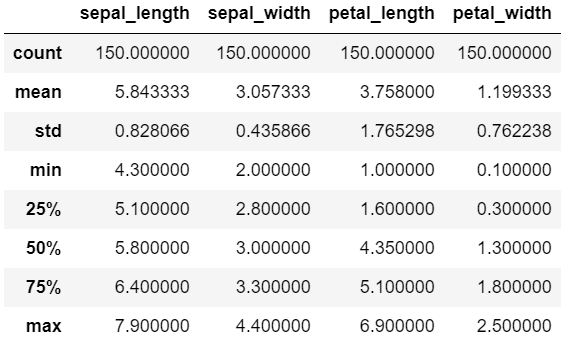
iris.describe(include = 'all')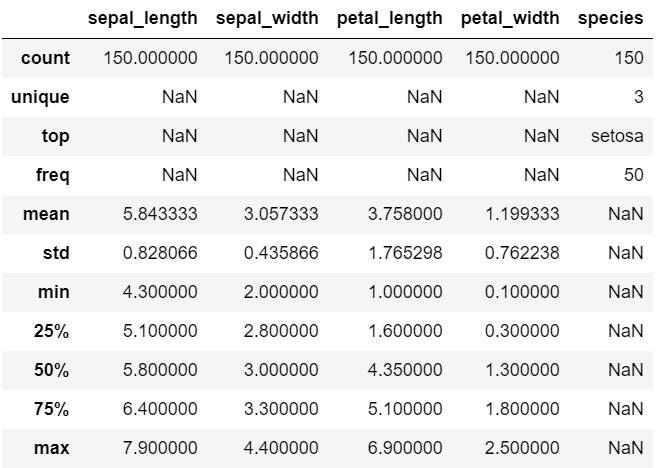
iris['species'].value_counts()
> setosa 50
versicolor 50
virginica 50
Name: species, dtype: int64iris.species.value_counts()
> setosa 50
versicolor 50
virginica 50
Name: species, dtype: int64iris.mean() # 따로 궁금한걸 빼서 볼수도 있고,
> sepal_length 5.843333
sepal_width 3.057333
petal_length 3.758000
petal_width 1.199333
dtype: float64iris['sepal_length'].mean() # 특정컬럼도 가능
> 5.843333333333335iris.sepal_length.mean() # 위에와 동일한 방법
> 5.843333333333335iris.median() # 중앙값
> sepal_length 5.80
sepal_width 3.00
petal_length 4.35
petal_width 1.30
dtype: float64iris['sepal_length'].median()
> 5.8iris.max() # 최댓값
> sepal_length 7.9
sepal_width 4.4
petal_length 6.9
petal_width 2.5
species virginica
dtype: objectiris.min() # 최솟값
> sepal_length 4.3
sepal_width 2.0
petal_length 1.0
petal_width 0.1
species setosa
dtype: objectiris.corr() # 상관계수 -1 ~ 1 사이, 1에 가까울 수록 정비례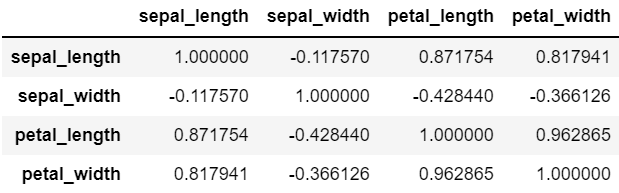
iris[['sepal_length','petal_length','petal_width']].corr() # 원하는 것만 상관계수 정보 보기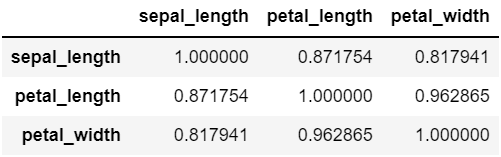
sns.get_dataset_names() #seaborn에 있는 데이터셋 이름 출력, 학습용 데이터 리스트
> ['anagrams',
'anscombe',
'attention',
'brain_networks',
'car_crashes',
'diamonds',
'dots',
'exercise',
'flights',
'fmri',
'gammas',
'geyser',
'iris',
'mpg',
'penguins',
'planets',
'taxis',
'tips',
'titanic']학습용 데이터 다루기_ tips
tips = sns.load_dataset('tips')
tips.head()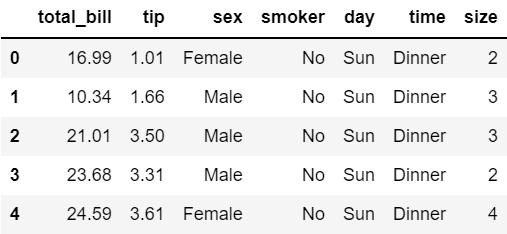
tips.tail()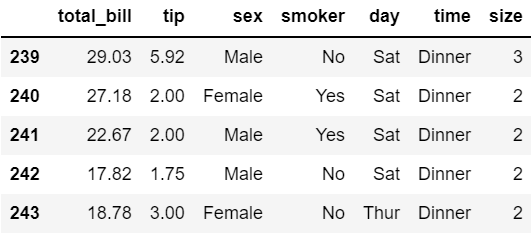
tips.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 244 entries, 0 to 243
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 total_bill 244 non-null float64
1 tip 244 non-null float64
2 sex 244 non-null category
3 smoker 244 non-null category
4 day 244 non-null category
5 time 244 non-null category
6 size 244 non-null int64
dtypes: category(4), float64(2), int64(1)
memory usage: 7.4 KBtips.describe()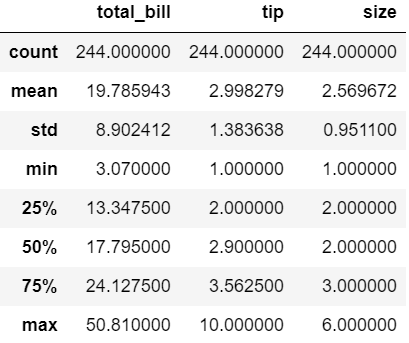
tips.describe(include='all') # 요일은 4개, 타임은 2개, max 6명, min 1명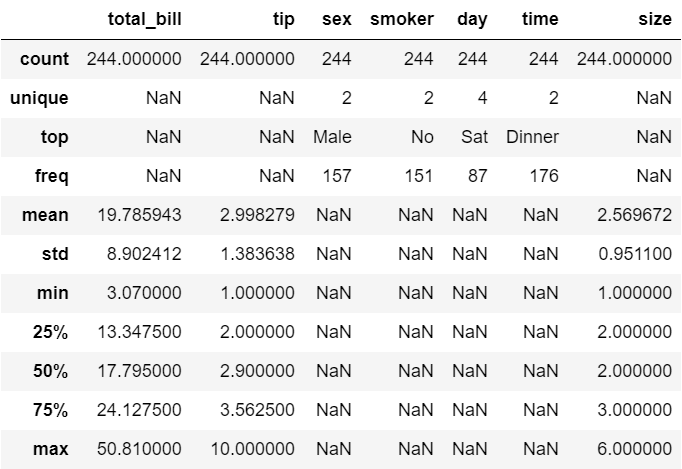
tips['tip'].value_counts()
> 2.00 33
3.00 23
4.00 12
5.00 10
2.50 10
..
4.34 1
1.56 1
5.20 1
2.60 1
1.75 1
Name: tip, Length: 123, dtype: int64tips.corr()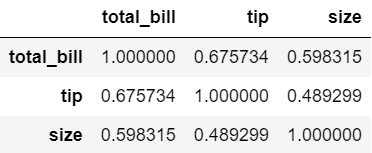
tips[['total_bill', 'tip']].corr()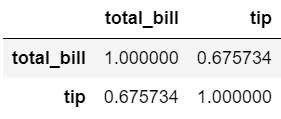
학습용 데이터 다루기_ titanic
tt = sns.load_dataset('titanic') # 결측치가 있음
tt.head()
tt.tail()
tt.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 714 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KBtt.describe()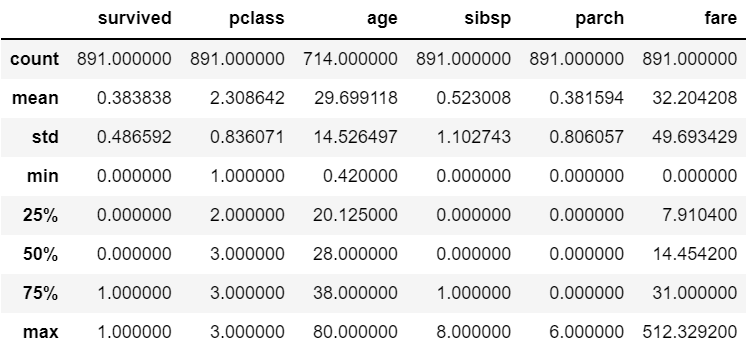
tt['age'].mean()
29.69911764705882tt['age'].median()
28.0m = tt['age'].median() # 결측치는 평균이나 중위수로 대체를 많이 함, 기본적이나 상황에 따라 다름
tt['age'] = tt['age'].fillna(m) # 결측치를 중위수로 대체
tt.describe() # age 개수가 다 채워짐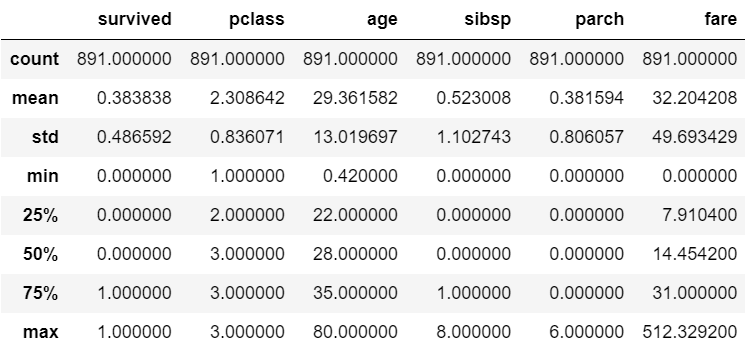
tt.info()
> <class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 survived 891 non-null int64
1 pclass 891 non-null int64
2 sex 891 non-null object
3 age 891 non-null float64
4 sibsp 891 non-null int64
5 parch 891 non-null int64
6 fare 891 non-null float64
7 embarked 889 non-null object
8 class 891 non-null category
9 who 891 non-null object
10 adult_male 891 non-null bool
11 deck 203 non-null category
12 embark_town 889 non-null object
13 alive 891 non-null object
14 alone 891 non-null bool
dtypes: bool(2), category(2), float64(2), int64(4), object(5)
memory usage: 80.7+ KB
느리지만 확실하게