
데이콘 게시글 중에 서포터즈의 일환으로 직접 쓴 게시글을 정리하기 위해 쓰인 글입니다. PDF 파일의 경우 다음 링크에 들어가시면 다운받을 수 있습니다.
[데이썬☀️_6편] 🤖 모델 검증(validation) 사용 설명서
안녕하세요! 데이크루 2기 데이썬☀️ 셔휘입니다.
'Python으로 시작하는 데이터 분석 사용 설명서'의 여섯 번째 포스팅 주제는 🤖 모델 검증(validation) 사용 설명서입니다.
이번에는 모델링 사용설명서에 이어 🤖 모델 검증(validation) 사용 설명서에 대해서 소개하겠습니다!
📣 설계한 모델이 잘 돌아가는지 확인하는 필수적인 과정으로, 과최적화 상태를 방지해주는 모델 검증(validation)에 대해 함께 공부해 볼까요?
📥 PDF파일에 오늘 공부할 내용이 요약되어 있으니 참고 부탁드립니다!
* 본 포스팅은 데이콘 서포터즈 "데이크루" 2기 활동의 일환입니다.
✍️ 데이썬의 모든 시리즈 바로가기!
[데이썬☀️_0편] Python으로 시작하는 데이터 분석 사용 설명서
[데이썬☀️_2편] 📖 기초 라이브러리 사용 설명서 (1) - Numpy
[데이썬☀️_2편] 📖 기초 라이브러리 사용 설명서 (2) - Pandas
[데이썬☀️_2편] 📖 기초 라이브러리 사용 설명서 (3) - Scikit-learn
[데이썬☀️_3편] 🔍 EDA (탐색적 데이터 분석) 사용 설명서 (1) - EDA & 통계치 분석
[데이썬☀️_3편] 🔍 EDA (탐색적 데이터 분석) 사용 설명서 (2) - Matplotlib
[데이썬☀️_3편] 🔍 EDA (탐색적 데이터 분석) 사용 설명서 (3) - Seaborn
[데이썬☀️_3편] 🔍 EDA (탐색적 데이터 분석) 사용 설명서 (4) - Plotly
[데이썬☀️_3편] 🔍 EDA (탐색적 데이터 분석) 사용 설명서 (5) - Cufflinks
[데이썬☀️_5편] 🔧 모델링 사용 설명서 (1) - 선형 회귀(Linear Regression)
[데이썬☀️_5편] 🔧 모델링 사용 설명서 (2) - 결정 트리(Decision Tree)
[데이썬☀️_5편] 🔧 모델링 사용 설명서 (3) - 앙상블(Ensemble)
🤖모델 검증(validation) 사용 설명서
-
모델 검증의 필요성
1) 모델 검증이란?
2) 표본내 성능 검증 & 표본외 성능 검증(교차검증)
-
Train test split
1) Train test split이란?
-
교차검증
1) 교차검증이란?
2) K-fold교차검증
3) K-fold 교차검증의 장단점
-
Metrics
1) Metrics란?
1. 모델 검증의 필요성
1) 모델 검증이란?
모델 검증이란 말 그대로 모델을 설계한 후 모델을 검증하는 단계를 말합니다.
모델 검증이 필요한 이유는 모델을 적합하게 잘 설계했는지, 즉 예측을 잘하는지 알기 위해서 입니다.
2) 표본내 성능 검증 & 표본외 성능 검증(교차검증)
기본적으로 훈련 데이터를 기반으로 모델링하고, 테스트 데이터로 해당 모델의 성능을 측정합니다.
- 표본내 성능 검증 : 훈련 데이터의 종속 변수값을 잘 예측하는지 보는 과정
- 표본외 성능(교차검증) : 테스트 데이터의 종속 변수값을 잘 예측하는지 보는 과정
👉 표본외 성능 검증(교차검증)은 예측을 잘하는지 알기 위해서는 학습에 사용하지 않는 표본을 활용해 모델이 잘 돌아가는지 확인합니다.
👨🏼⚕ 표본외 성능 검증(교차검증)을 하는 이유는
표본내 성능이 좋으면 표본외 성능이 상대적으로 많이 떨어지는 과최적화 상태가 나타날 수 있습니다.
이런 경우 새로운 데이터를 주었을 때 전혀 예측하지 못해, 예측을 할 수 있는 모형을 만들기 위해 과최적화를 방지하는 정규화 과정이 필요합니다.
2. Train test split
1) Train test split이란?
교차검증을 하기 위해 두 종류의 데이터 집합이 필요합니다.
- Training data set : 교차검증을 하려면 모델 학습을 위한 데이터 집합
- Test data set : 모델 성능 검증을 위한 데이터 집합
👉 Train data에는 예측해야 하는 변수가 포함되어 있지만 test data에는 포함되어 있지 않는 것이 특징입니다.
두 데이터 집합 모두 종속 변수값이 있어야 해서 보통 가지고 있는 데이터 집합으로 나누어 사용하며,
Train test split(학습/검증 데이터 분리) 메소드를 사용해 학습용 데이터와 검증용 데이터로 분리합니다.
3. 교차검증
1) 교차검증이란?
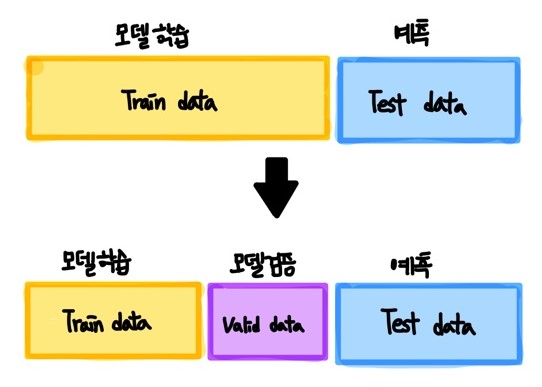
교차검증은 모델을 평가하는 방법 중 하나로, 보통 데이터 셋을 그림과 같이 나누게 됩니다.
Valid data를 모델의 과적합을 방지하기 위해 사용되는데,
Train data에서 파생된 데이터로 Train data로 모델을 학습시키는 과정에 Valid data로 중간중간 학습된 모델을 평가합니다.
🧐 만약 Valid data로 검증을 했을 때 평가지표가 좋지 않은 수치로 나타난다면 과적합을 의심해야 합니다.
그림과 같은 데이터 분리 후, 모델 검증을 하면 모델 예측에 있어 과적합을 방지할 수 있습니다.
보통 Train : Test 데이터 분리 비율은 8:2 ~ 7:3 사이 입니다.
2) K-fold 교차검증이란?
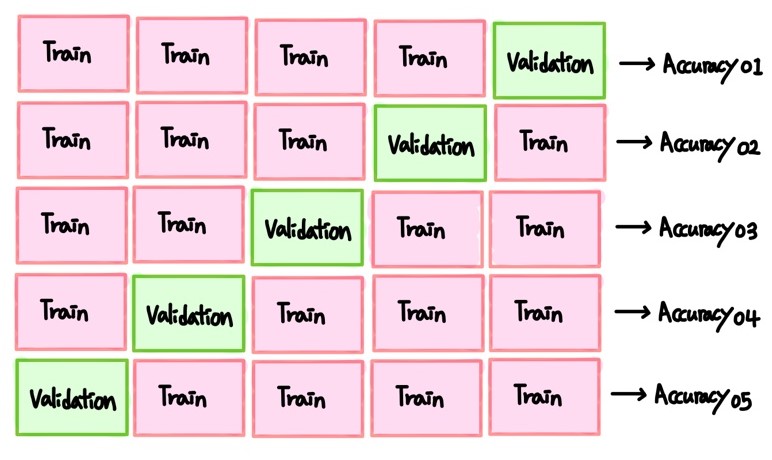
일반적으로 많이 사용되는 교차검증 방법인 K-fold 교차검증에 대해 설명해보겠습니다.
👉 K-fold 교차검증은 Train data set 전체를 K개의 학습세트와 검증세트로 나누어,
K만큼의 폴트세트에 K번의 모델 학습과 검증를 수행합니다.
그림과 같이 K번의 교차검증 성능을 평균내어 최종 교차검증 성능으로 계산합니다.
K-fold의 경우 데이터의 수가 적은 경우 사용하기 좋은 방법입니다.
3) K-fold 교차검증의 장단점
다음으로 교차검증의 장단점에 대해 설명해드리도록 하겠습니다.
👍 교차검증의 장점
1. 모든 데이터 셋을 평가에 반영할 수 있어 데이터의 편중을 막을 수 있음
2. 더욱더 일반적인 모델을 생성 가능하여 과적합을 방지
3. 반복적인 교차검증을 통해 모델의 정확도를 향상 시킬 수 있음
4. 데이터가 부족하여 train과 test로 나누기에 아까운 경우에 활용하기 좋음
👎 교차검증의 단점
1. k번의 모델을 생성해야 하므로, 모델 생성 및 평가하는 과정에서 많이 시간이 소요됨
K-fold에 대한 실습은 데이썬의 다른 게시글에 이미 한 적이 있어, 이 글에서는 생략하도록 하겠습니다!
K-fold를 활용한 실습이 궁금하신 분들은 다음 게시글을 참고해주세요.
🦾 [데이썬☀️_5편] 🔧 모델링 사용 설명서 (1) - 선형 회귀(Linear Regression)
3. 교차검증
1) Metrics란?
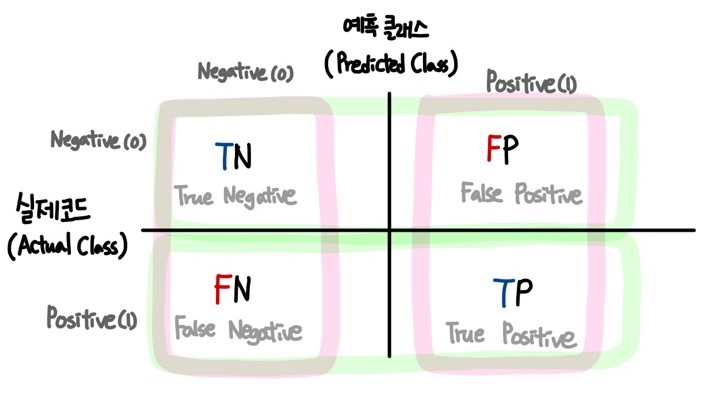
Scikit-learn의 metrics 서브패키지에는 Confusion matrix라는 훈련된 모델의 성능을 측정하기 위한 Matrix가 있습니다.
그림은 Confusion matrix(이진 분류결과표)입니다.
- TP(True Positive): True를 True로 잘 예측한 것
- TN(True Negative): False를 False로 잘 예측한 것
- FP(False Positive) : False를 True로 잘 못 예측한 것
- FN(False Negative) : True를 False로 잘 못 예측한 것
👉 Confusion matrix를 활용해 정확도, 정밀도, 재현율 등을 측정할 수 있습니다.
그림에서 positive와 negative는 예측값이 긍정이냐 부정이냐를 의미하고,
true/false는 예측값과 실제값이 같은지 다른지를 나타냅니다.
2) 평가점수
Scikit-learn의 metrics 서브패키지에서는 예측 성능을 평가하기 위한 다양한 함수를 제공합니다.
그 중 회귀분석에 유용한 함수는 다음과 같습니다.
- R2_score : 결정계수
- Mean_squared_error : 평균 제곱 오차
- Median_absolute_error : 절대 오차 중앙값
그외에도 많이 사용하여 알아두면 좋은 다양한 평가점수에 대해 설명해보겠습니다.
📐 정확도(accuracy)
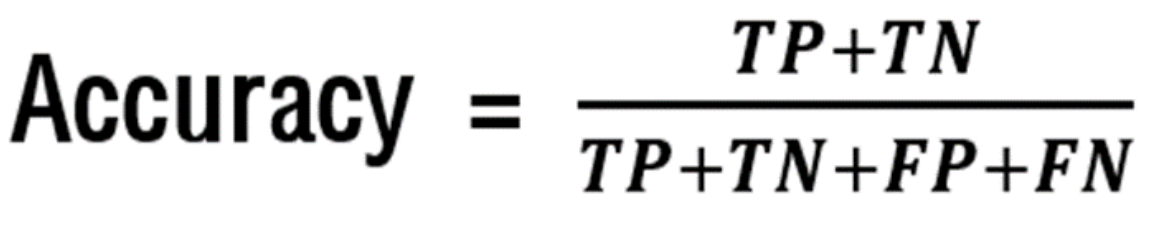
정확도는 전체 샘플 중 맞게 예측한 샘플 수의 비율로, 정확도가 높을 수록 좋은 모형입니다.
일반적으로 학습에 최적화 목적함수로 사용됩니다.
🧪 정밀도(precision)
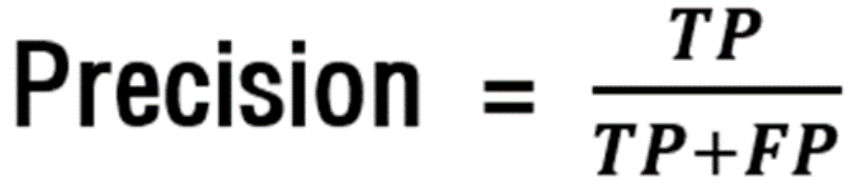
정밀도는 positive 클래스에 속한다고 예측한 샘플 중 실제로도 positive 클래스에 속하는 샘플 수의 비율로,
이것 또한 높을 수록 좋은 모형입니다.
🔍 재현율(recall)
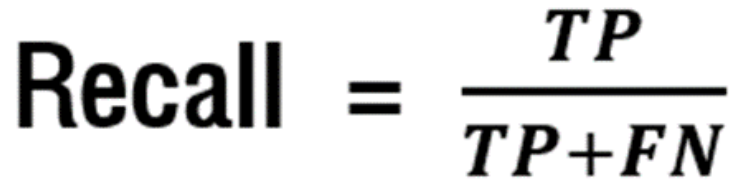
재현율은 실제 positive 클래스에 속한 표본 중에 positive 클래스에 속한다고 예측한 표본의 수의 비율로,
이것도 높을 수록 좋은 모형입니다. 또한 재현율을 TPR(true positive rate) or 민감도라고 말하기도 합니다.
💥 위양성율(fall-out)
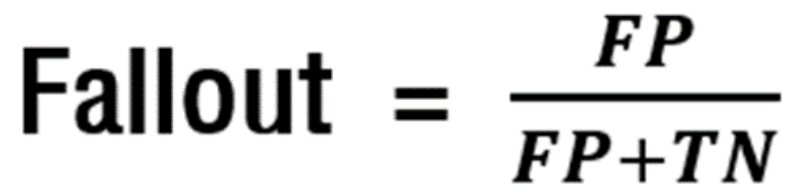
위양성율은 실제 negative에 속하지 않는 표본 중에 negative에 속한다고 출력한 표본의 비율로,
FPR(false positive rate) or 1에서 위양성율의 값을 뺀 값을 특이도라고 합니다.
지금까지 모델 검증과 교차검증에 대해 같이 공부해보았는데요!
모델 검증은 모델이 예측한대로 돌아가는지 확인하는 과정으로, 모델을 잘 설계하기 위한 필수적인 과정이니 잘 알아두시면 좋을 것 같습니다🙌
다음은 모델 최적화 사용 설명서로, 모델을 좀 더 최적하는데 도와주는 방법을 다룬 게시글을 업로드할 예정입니다.
다음 게시글에도 많은 관심과 애정 부탁드려요! 감사합니다💛
