
이번 글에서는 최근에 개발하고 있는 기능에서 경험한 쿼리 최적화를 정리해보겠습니다. 해당 기능은 최근 한달 게시글 중 좋아요 수가 높은 순으로 상위 100개의 게시글을 가져오는 기능입니다. 기존 구현 방식은 서브쿼리를 활용한 방식이었습니다.
각 테이블의 컬럼 및 인덱스는 다음과 같습니다.
게시글 : 게시글 ID, 회원 ID(idx), 내용, 이미지 경로, 생성일, 마지막 수정일
좋아요 : 좋아요 ID, 게시글 ID(idx), 유저 ID(idx), 생성일, 마지막 수정일
서브쿼리 VS 쿼리 2개
서브 쿼리 방식
select *
from post p
join member m on m.member_id=p.member_id
where p.created_date>='한달 전 날짜'
order by (select count(1)
from likes l
where p.post_id=l.post_id) desc
limit 100;쿼리 2개 방식
select l.post_id, count(l.like_id)
from likes l
group by l.post_id
order by count(l.like_id) desc
limit 100;
select *
from post p
join member m on m.member_id=p.member_id
where p.post_id in('위 쿼리 결과의 post_id');
and p.created_date>='한달 전 날짜'두 가지 방식을 고민했던 이유는 다음과 같습니다.
서브 쿼리 방식 장점 : 하나의 쿼리로 복잡한 데이터 조작이 가능하여 관리가 용이합니다.
서브 쿼리 방식 단점 : 서브쿼리가 복잡하거나 중첩될 경우 성능이 저하될 수 있습니다.
쿼리 2개 방식 장점 : 각각의 쿼리를 독립적으로 최적화할 수 있어 성능이 향상될 수 있습니다.
쿼리 2개 방식 단점 : 결과를 결합하거나 후처리를 해야 하는 경우가 있어 추가적인 작업이 필요합니다.
실행시간
우선 각 방식의 실행시간을 확인해보았습니다. 실행시간은 MySQL profiles으로 확인하였습니다.

서브 쿼리 방식은 3.6998s, 쿼리 2개 방식은 0.3021(0.3010+0.0011)s로 쿼리 두개 방식의 실행 시간이 12배 빠른 것을 확인할 수 있습니다. 어느 정도의 성능 차이는 날거라 생각했지만 이렇게 크게 차이가 있을 줄은 몰랐습니다.
실행계획
다음으로는 MySQL EXPLAIN 키워드를 활용하여 해당 쿼리의 실행계획을 분석해보았습니다.
서브 쿼리 방식

서브 쿼리의 방식의 실행계획입니다. type에 ALL이 사용된 것을 확인할 수 있었습니다. ALL 방식은 풀 테이블 스캔을 의미하는 접근 방식으로 가장 비효율적인 방식입니다. 현재 게시글 테이블에 30만건의 데이터가 있지만 그 수가 늘어난다면 성능이 더 안 좋아질 것 입니다.
쿼리 2개 방식
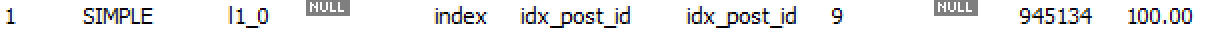
쿼리 2개 방식의 첫 번째 쿼리의 실행계획입니다. type에 index가 사용된 것을 확인할 수 있었습니다. index 방식은 인덱스를 처음부터 끝까지 읽는 인덱스 풀 스캔을 의미하는 방식으로 반드시 효율적이지는 않은 방식입니다. ALL 방식보다는 빠르지만 최적화의 필요성이 느껴집니다.

쿼리 2개 방식의 두 번째 쿼리의 실행계획입니다. type에 range가 사용된 것을 확인할 수 있었습니다. range 방식은 인덱스 레인지 스캔 형태의 접근 방식으로 최적의 성능이 보장된다고 볼 수 있는 방식입니다.
실행계획 분석을 통해 두 가지 방식의 성능 차이 원인을 알 수 있었습니다. 쿼리 2개 방식도 빠르지만 개선의 여지가 남아 있어 새로운 방식을 도입해 보았습니다.
테이블 구조 변경
현재 게시글 테이블에서는 좋아요 수를 알 수 없습니다. 그렇기 때문에 서브 쿼리 또는 별개의 쿼리를 통해 좋아요 수를 가져오고 있습니다. 그렇다면 처음부터 게시글 테이블에 좋아요 수를 저장한다면 어떨까 생각이 들었습니다.
먼저 좋아요 수 컬럼을 게시글 테이블에 추가한다면 생기는 변화에 대해서 정리해보았습니다.
장점 : 게시글 테이블만 활용해서 최근 한달 게시글 중 좋아요 수가 높은 순으로 상위 100개의 게시글을 가져오는 기능을 구현할 수 있다.
단점 : 좋아요 수 컬럼에 대한 동시성 처리를 해야한다.
동시성 처리를 해야하지만 원하는 결과를 하나의 쿼리로 얻을 수 있는 이점이 크기 때문에 게시글 테이블에 좋아요 수 컬럼을 추가하였고 해당 컬럼을 인덱스로 설정하였습니다.
동시성 처리
가장 먼저 동시성 처리에 대한 추가적인 작업을 진행하였습니다. 먼저 최근 한달 게시글 중 좋아요 수가 높은 순으로 상위 100개의 게시글을 가져오는 기능을 구현하는 이유부터 설명을 해보겠습니다.
서비스가 구현하고자 하는 기능은 인기 게시글 N개를 상위에 고정하는 것 입니다. 그래서 데이터베이스에서 일차적으로 필터링하는 작업이 필요하였고 그 작업이 위 기능입니다. 100개를 가져온 후에는 어플리케이션 단에서 댓글 수, 좋아요 수, 작성 날짜 등 여러가지 점수를 합산하여 N개를 반환할 계획입니다.
좋아요 수가 핵심이 아니기 때문에 어느정도의 동시성 처리는 필요하지만 엄격하게는 필요하지 않다고 판단하였습니다. 그래서 어플리케이션 단에서 처리할 수 있는 낙관적 락을 적용하여 동시성을 처리하였습니다.
변경된 쿼리
변경된 쿼리는 다음과 같습니다. POST 테이블만 사용해서 원하는 결과를 가져올 수 있었습니다.
select *
from post p
join member m on m.member_id=p.member_id
where p.created_date>='한달 전 날짜'
order by p.like_count desc
limit 100;
하지만 실행계획을 확인해보니 type에 index가 사용된 것을 확인할 수 있었습니다. index 방식은 반드시 효율적이지 않은 방식이므로 개선할 필요성이 느껴졌습니다.
아마 정렬하는 과정에서 모든 데이터를 확인해야 하므로 type에 index가 사용되었다고 판단하였습니다. 그래서 정렬하는 과정을 최적화하는 방안을 찾아보다가 좋은 방식을 알게되었습니다.
바로 인덱스를 활용하는 방법입니다. 인덱스 테이블은 데이터를 빠르게 찾기 위해 정렬된 상태로 유지되어 있습니다. 이 인덱스를 활용하면 정렬한 효과를 나타낼 수 있습니다.
현재 좋아요 수가 높은 순으로 가져와야 하기 때문에 인덱스 정렬 방식을 내림차순으로 설정하고 해당 인덱스를 사용하기 위한 조건을 다음과 같이 추가해주었습니다.
select *
from post p
join member m on m.member_id=p.member_id
where p.created_date>='한달 전 날짜'
and p.like_count >= 0
limit 100;
해당 쿼리에 대한 실행계획을 확인해보니 type에 index를 사용하지 않고 range로 변경된 것을 확인할 수 있었습니다.

위 두 개의 쿼리 실행시간은 각각 0.0011ms, 0.0010ms로 차이가 크게 나지않은 것으로 생각할 수 있지만 데이터의 수가 증가하면 할수록 차이는 더욱 날 것입니다.
이것을 끝으로 쿼리 최적화를 마무리하였습니다. 3.6998s에서 0.0010s로 시간을 단축하였으며 이는 데이터가 많아지면 질수록 더 크게 차이가 날 것입니다.
이번 쿼리 최적화 경험을 통해 MySQL EXPLAIN을 통해 실행계획을 분석해보는 좋은 기회가 되었습니다.
참고 문서 및 링크
