안녕하세요! 노는게 제일 좋은 GCOCO입니다!

반갑습니다! 분명 저번 문제풀이에서 BFS와 DFS 포스팅으로 다시 찾아뵙겠다고 했지만
중간고사를 물리치고 13일만에 5월 5일 어린이날이 되어서야 포스팅을 하게되었군요...
13일동안 먼저 취업하신 선배님들의 직무특강도 듣고 일본계 취업도 알아보고 제게 부족한것이 무엇인지 고민도 많이 해보고 의미있는 시간을 보냈던 것 같습니다.
제가 느꼈던 점들은 추후의 포스팅들에서 간단하게 쿠키를 먹는것처럼, 조금씩 서술해보도록 하겠습니다.
그럼, 시작하겠습니다!
DFS(Depth First Search)
깊이 우선 탐색(DFS)은, 그래프 또는 트리 데이터 구조를 순회하는 데 사용되는 그래프 순회 알고리즘입니다. 루트 노드(또는 임의의 노드)에서 시작하여 역추적하기 전에 각 분기를 따라 가능한 멀리 탐색합니다.
DFS알고리즘을 사용할 때는 다음과 같은 단계를 따릅니다.
- 시작 정점을 선택하고 방문한 것으로 표시한다.
- 방문하지 않은 각 인접 정점을 현재 정점의 인접성 목록에 나타나는 순서대로 탐색한다.
- 방문을 표시하고 동일한 절차를 재귀적으로 적용합니다.
- 모든 인접 정점을 방문했거나 인접 정점이 없는 경우 이전 정점으로 역추적하고 방문하지 않은 인접 정점에 대해 절차를 반복합니다.
한 마디로 전부 뒤져서 찾아보겠다! 이런 경우에 사용하는 것이죠. 그림으로 한번 보도록 하곘습니다.
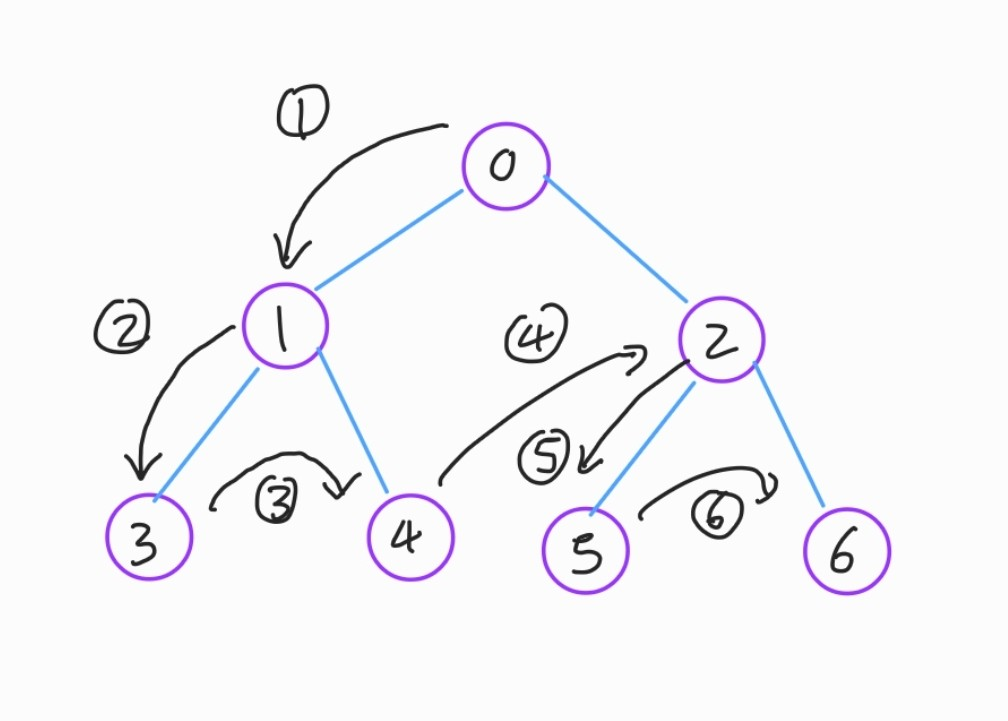
위의 그림과 같은 구조의 노드가 있다고 가정할 때 DFS를 이용한 방문 순서는
0번노드 -> 1번노드 -> 3번노드 -> 4번노드 -> 2번노드 -> 5번노드 -> 6번노드 의 순서가 됩니다.
하지만 그림만 보면 좀 어색하게도 느껴질 수 있다고 생각합니다. 4번과정에서 말이죠.
마치 레벨이 서로 다른 두 노드에서 점프하는 것처럼 보인다고 생각합니다.
과정을 좀 더 풀어서 이야기 해보도록 하겠습니다.
- 기본적으로 왼쪽 우선 방문이며, 각 노드를 방문하였을때 방문표시를 해 줍니다.
- 1번과 2번 과정은 좀 더 깊은 곳으로 탐색을 위해 진입하는 과정입니다.
- 이후 가장 깊은 레벨의 노드인 3번 노드에 도착하고 3번 과정으로 같은 부모노드를 가진 4번 노드를 향해 탐색을 실시합니다.
- 4번 노드의 탐색을 마친 뒤 더 이상 해당 노드에서 나아갈 경로가 없기 때문에 1번노드로 되돌아갑니다.
- 1번 노드는 이미 방문하였기에, 아직 방문하지 않은 2번 노드를 방문합니다.
- 이후 가장 깊은 노드인 5번 노드를 향해 방문하고
- 6번 노드를 방문하며 탐색을 마칩니다.
이러한 과정을 통해 DFS가 실행됨을 알 수 있습니다. 이해를 돕기 위한 다른 예제도 봐 보도록 하겠습니다.
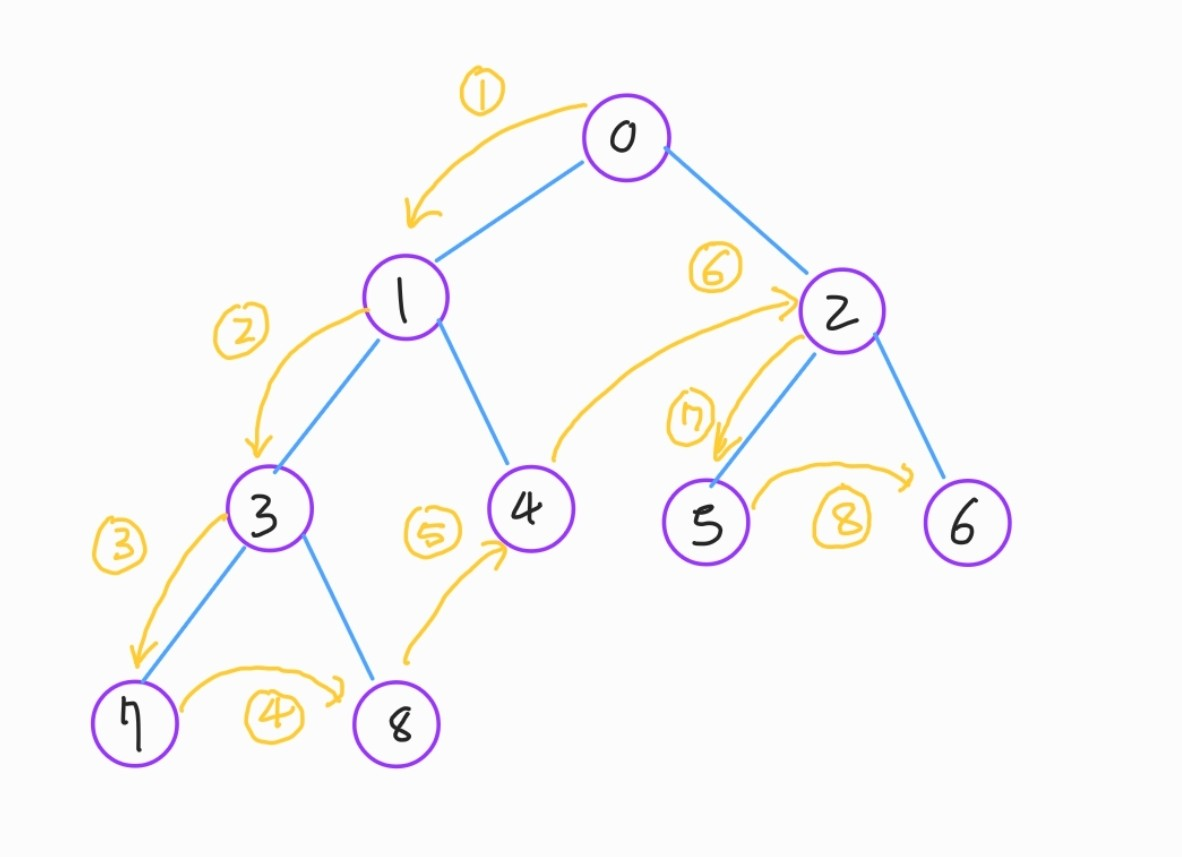
위 그림에선 어떨까요? 첫번째 그림의 예시를 잘 이해하신분이라면 순서를 잘 맞히셨을것이라고 생각합니다. 다만 부연설명을 해 보자면, 5번 과정에선 8번노드에서 4번 노드로 바로 점프하는것처럼 보이지만, 그 안에선 3번노드를 다시 돌아가고 이미 방문하였기에, 다시 1번노드로 돌아가고 이미 방문하였기에 4번노드로 향하는 것입니다. 4번 노드의 탐색을 마치고 1번노드로 돌아가고 이미 방문하였기에 2번노드로 향하는 과정입니다.
또 하나의 예시입니다.
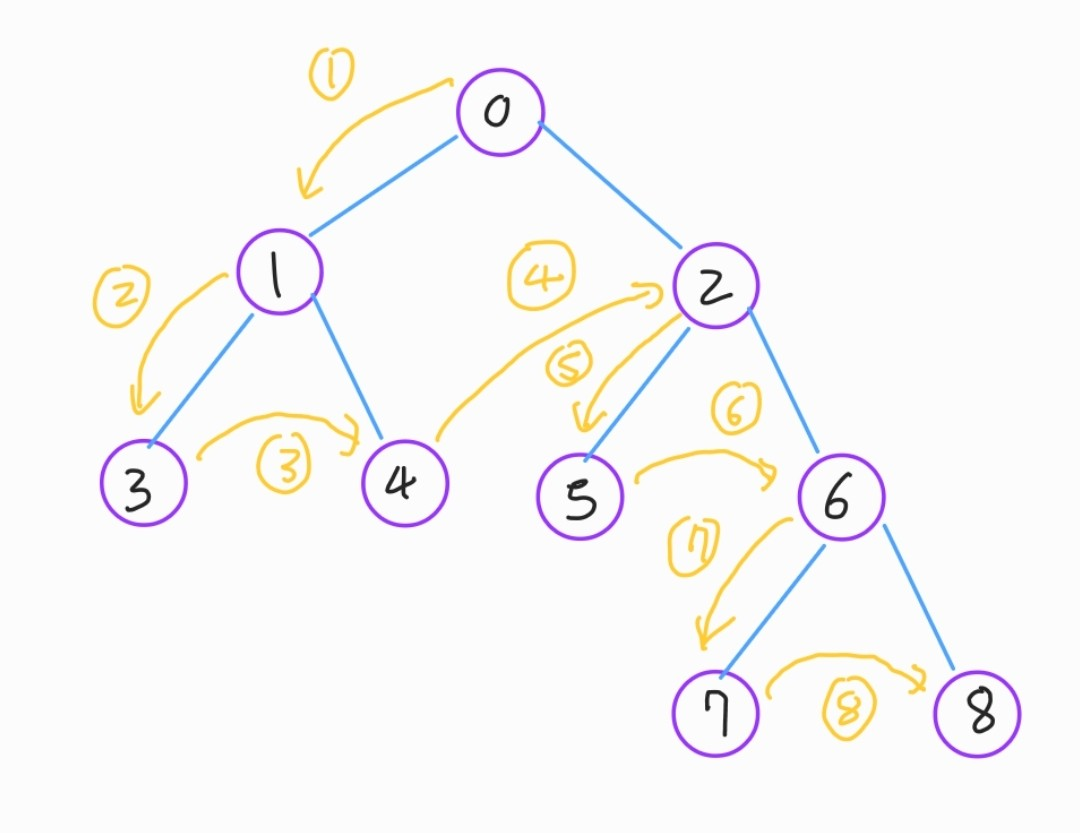
위 그림에서도 4번 과정이 어떻게 진행될지 생각해주시면 좋을것 같습니다.
참고로 위 그림의 트리구조는 나중에 트리구조를 다룬 포스팅을 보시고 나면, 굉장히 어색하게 느껴지실거라고 생각합니다.
그래서 이거 어케써요 ?
제가 처음 DFS를 배우고 나서 든 생각은 '음...이거...그래서 어케 코드로 짜고 쓰는거지?' 였습니다.
활용을 해 보아야 좀 감이 잡힐것 같았단 말이죠. 또한 이런 생각도 들었습니다.
'DFS를 이용하여 문제에서 원하는 정답을 중간에 찾았다면 어떻게 끝내야하지?'
제가 위에서 그린 그림들은, 모든 경우를 탐색하지만 만약 문제에서 모든 경우의 탐색을 요구하며 중간에 답을 찾았다면 어떻게 탈출해야 할까요?
한번 문제를 통해 같이 코드를 보며 이야기해보겠습니다!
[프로그래머스] 모음 사전
알고계셨나요? 단어사전은 완전탐색의 훌륭한 표본이라는것을!
생각해보면 그렇습니다. GCOCO라는 단어가 만약 영어사전에 등재되었고 이 단어의 순서 인덱스를 찾고자 한다면 앞에서부터 한 글자씩 알파벳순서에 따라 순번을 매기며 진행해 Target 단어인 GCOCO에 도달할때까지 진행할 것입니다. 이러한 업무는 컴퓨터가 하기에 아주 적합하고, 이런 경우 DFS를 사용하면 편리한 것이죠!
문제 설명을 읽어 보면 해당 사전은 알파벳 모음 'A', 'E', 'I', 'O', 'U'만을 사용하여 구성되어 있고 "A", 그다음은 "AA",그다음은 "AAA", 마지막 단어는 "UUUUU"와 같은 규칙을 갖고있습니다.
어...이거..! DFS로 풀면 편하겠다!
그림으로 한번 볼까요?
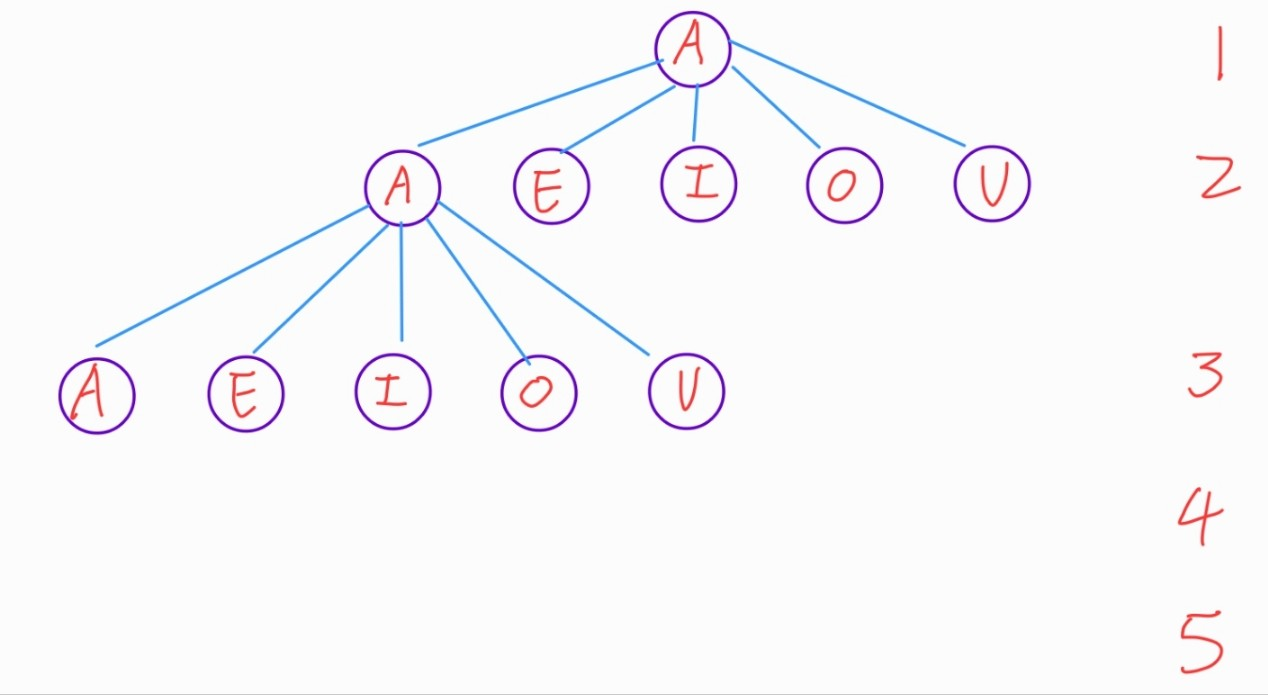
어떻게 진행하면 좋을까요?
처음 단어는 A, 두번째 단어는 AA, 세번째는 AAA....해서 마지막 UUUUU까지.
아하. Target으로 주어지는 단어를 찾을때까지 탐색을 실시하고 찾는다면 탐색을 종료하면 되겠구나.
이를 코드를 통해 보겠습니다!
#include <string>
#include <vector>
using namespace std;
bool dfs(string target, const char moum[], int& answer, string word) {
//찾으면 탈출!
if (word == target)
return true;
//사전은 5글자까지기에, target이 아니고 길이가 5라면 다음 글자로
if(word.length()==5)
return false;;
//탐색을 위한 for문
for (int i = 0; i < 5; i++) {
string tmp = word+moum[i];
answer++;
//정답을 찾으면 탐색을 종료하기 위한 bool ret
bool ret = dfs(target,moum,answer, tmp);
if(ret)
return true;
}
//해당 경로에서 찾지 못했음을 알리는 false return
return false;
}
int solution(string word) {
int answer = 0;
char moum[] = { 'A', 'E', 'I', 'O', 'U' };
dfs(word, moum, answer, "");
return answer;
}solution은 간단합니다. DFS함수를 만들어 호출하는 것이지요.
DFS함수는 bool형을 사용했습니다. 이는 TARGET을 찾았을 시 더 이상 탐색을 실행하지 않고 함수를 종료하기 위해서입니다. 마치 '저 여깄어요!' 하고 손을 들게 하는 효과와 같다고 생각하시면 됩니다.
for문을 통해 A단어부터 시작하며 재귀적으로 DFS함수를 호출하고 순번이 증가할수록 정답으로 반환할 reference 형태로 받은 answer의 값을 증가시켜줍니다.
간단하게 DFS와 예시 문제를 통해 개념와 적용을 알아보았습니다. 물론 이것만으로 DFS를 정복했다라고 절대로 말할수 없을 뿐더러, 꾸준한 연습이 필요하다고 생각합니다. (저에게 하는 이야기입니다.)
도움이 되셨다면 좋겠습니다!
