배열(Array)
- 같은 타입의 데이터를 여러개 나열한 선형 자료구조 이며 연속적인 메모리 공간에 순차적으로 데이터를 저장한다.
- 배열은 선언할 때 크기를 정하면 해당 크기로 고정되며 다시 선언하기 전까지 변경할 수 없다.
- 배열의 주소 각 칸마다 자료형의 크기를 가지고 있다. int라면 배열 한 칸의 크기는 int(4byte)가 되는 것이며 각 칸은 인덱스를 통해서 접근할 수 있다.
- 배열의 크기는 고정적 이기 때문에 중간의 원소 삽입 및 삭제 과정은 기존의 배열의 크기보다 크거나 작은 배열을 새로 선언한 뒤 기존의 값에 추가하거나 삭제할 값을 적용하여 복사해주어야 하기 때문에 시간복잡도O(n)을 가진다.
- 인덱스 연산자를 사용할 수 있기 때문에 특정 위치의 원소에 대한 탐색 및 수정의 시간복잡도는 O(1)이다.
List
ArrayList
-
저장공간의 크기가 가변적이지만 ArrayList도 내부적으로 elementData 배열 필드를 통해 데이터를 저장하기 때문에 저장공간을 늘릴 때 번거로운 배열의 확장 및 복사 과정을 거치며 배열과 같이 시간복잡도O(n)을 가진다.
-
get 메서드를 통해 특정 인덱스 위치에 저장된 원소에 접근하는 시간복잡도가 O(1) 이다.
-
set 메서드를 통해 특정 인덱스 위치에 저장된 원소 수정의 시간복잡도가 O(1) 이다.
-
add 메서드를 통해 데이터를 삽입할 경우 elementData.length 와 size 필드의 크기가 같다면 배열을 확장하는 로직이 실행된다. elementData.length 길이가 0 일 경우 첫 배열의 크기는 10으로 설정되고 다음부터는 기존 크기에 1.5배 만큼 확장된다. 10 -> 15 -> 22
-
add 메서드를 통해 특정 인덱스 위치에 저장하는 경우가 아니면 elementData 필드 마지막 인덱스 +1 위치에 저장되어 시간복잡도는 O(1) 이다.
특정 인덱스 위치에 저장하는 경우 우선 인덱스가 size 필드 보다 크고 작음을 검증하여 크다면 예외가 발생시키고 아니라면 System.arraycopy() 메소드를 통해 elementData 필드의 대입할 위치의 인덱스 위치부터 마지막까지 한칸 뒤로 미루고 해당 위치에 새로 넣을 값을 대입하기 때문에 배열과 같이 시간복잡도O(n)을 가진다. -
remove 메소드를 호출하여 특정 요소를 삭제하는 경우 elementData 필드에 특정 값이 존재하지 하는지 첫 인덱스 부터 탐색하여 없다면 false를 반환하고 존재할 경우 해당 인덱스 번호를 알아내어 System.arraycopy() 메소드를 통해 elementData 필드에 제거할 인덱스 +1 위치 부터 마지막 인덱스 까지 요소의 크기만큼 제거할 인덱스 위치로 한칸 앞당겨 제거할 인덱스 위치의 요소를 제거하고 마지막 인덱스에 중복되는 값도 제거하기 때문에 시간복잡도O(n)을 가진다.
특정 인덱스의 요소를 삭제할 경우 인덱스를 찾는 과정만 생략되고 나머지는 동일하기 때문에 시간복잡도O(n)을 가진다. -
contains 메소드를 호출하여 특정 요소가 elementData 필드에 존재여부를 판별하는 경우 elementData 필드의 첫번째 인덱스 부터 순차탐색을 하기 때문에 시간복잡도O(n)을 가진다.
-
elementData 필드는 빈공간을 허용하지 않기 때문에 배열에 비해 메모리 공간의 낭비가 없다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
//데이터가 저장되는 필드
transient Object[] elementData;
//elementData 필드에 저장된 요소의 크기를 저장하는 필드, 실제 저장된 요소만 카운팅함
private int size;
...
...
}LinkedList
-
LinkedList 아래 필드를 보면 정적 멤버 클래스인 Node가 존재하는데, Node는 데이터를 저장할 필드와 다음,이전 Node를 저장하는 필드로 가지고 있다. 따라서 데이터들이 배열처럼 연속적으로 메모리에 저장되어 있지 않고 서로 떨어져 있어도 선형구조로 데이터를 저장할 수 있다는 장점이 있다. 이 장점은 곧 크기의 제한이 걸리지 않는다는 점이 되고 이 때문에 데이터 추가, 삭제가 굉장히 자유로워진다.
-
add 메소드를 호출해 데이터를 추가하는 경우 last 필드를 지역 변수 l에 대입한 후 저장할 데이터와 함께 Node 생성자의 인자로 보내어 Node의 prev 필드와 item 필드에 저장한다. 새로 생성한 Node에 이전 위치의 Node가 저장된 것이다. 다음 인스턴스화 한 Node를 last 필드에 저장한다. 만약 지역변수 l이 null인 경우 즉 LinkedList 에 처음 데이터를 추가하는 경우 first 필드에도 인스턴스화 한 Node를 대입한다. first, last 필드 모두에 대입되는 것이다.
다음 null이 아닌 경우 LinkedList 에 1개 이상의 데이터를 이미 추가한 경우 지역변수 l의 next 필드에 인스턴스화한 Node 를 대입한다. 이전 노드는 다음 노드의 위치를 알게 된 것이다.
size++ 를 호출하고 메소드가 종료된다. 시간복잡도 O(1) 가진다. -
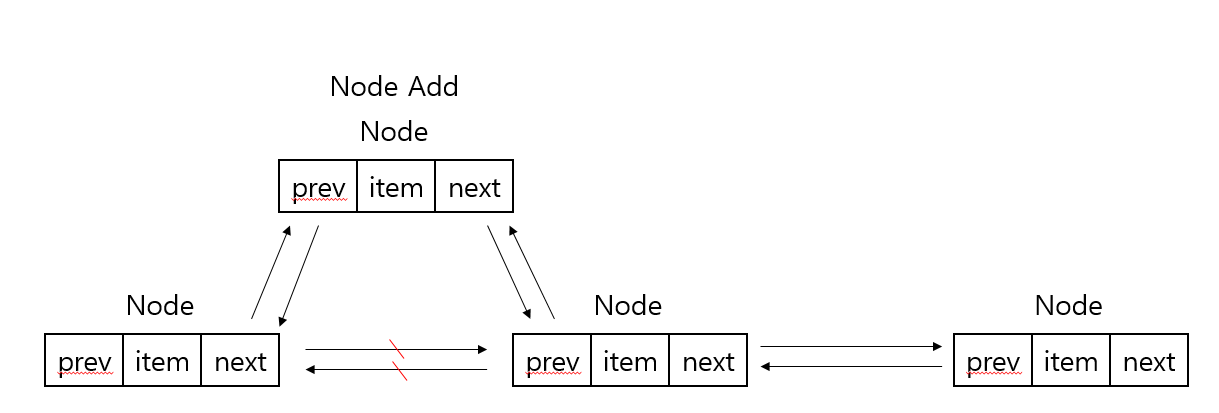
add 메소드를 호출해 특정 인덱스 위치에 데이터를 추가하는 경우 node 메소드를 호출하는데 로직을 보면 해당 인덱스에 위치하는 Node를 찾기 위해 index의 값이 size 필드의 절반 보다 작다면 first 필드에서 부터 탐색을 시작하고 크다면 last 필드에서 부터 탐색을 시작하여 인덱스에 위치한 Node를 가져온 뒤 아래 그림과 같은 로직이 실행된다. 시간복잡도 search time + O(1) 가진다.
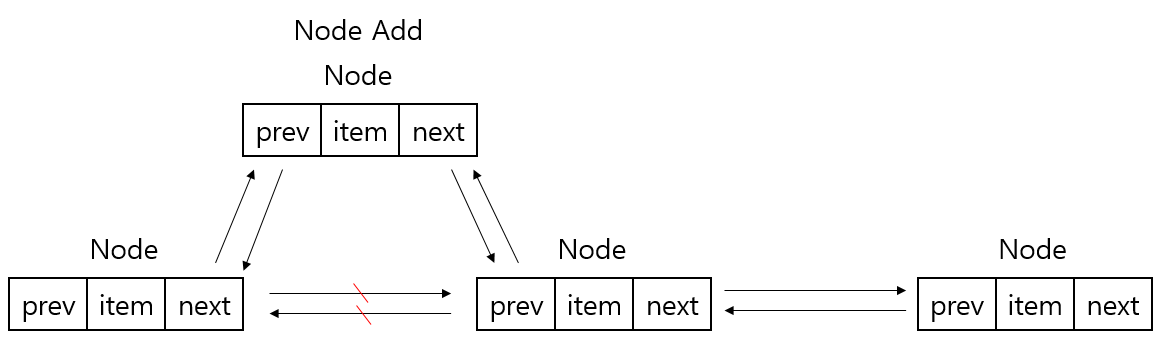
-
remove 메소드를 호출해 특정 인덱스를 제거하는 경우 add 메소드와 같은 알고리즘으로 Node를 가져오고 특정값으로 제거하는 경우 first 필드에서 부터 순차적으로 특정값과 같은 item 필드를 가진 Node를 찾는다. Node를 찾은 후에는 아래 그림과 같은 알고리즘 으로 Node를 제거한다. 시간복잡도 search time + O(1) 가진다.
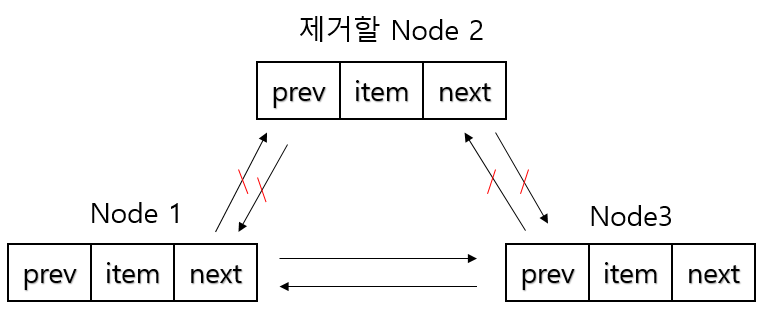
-
get 메소드의 경우 node 메소드를 호출하여 Node를 찾은 뒤 해당 Node의 item 필드를 반환한다. set 메소드의 경우도 node 메소드를 호출하여 Node를 찾은 뒤 item 필드에 저장할 값을 대입시킨다. 둘다 시간복잡도 search time + O(1) 가진다.
-
데이터를 추가하는 행위 자체의 시간복잡도는 O(1)이다. 노드가 가지고 있는 메모리 주소 값만 갈아 끼워주면 되기 때문이다. 다만, 추가하려는 데이터의 위치가 맨 처음이 아니고 그 이후라면 순차적으로 탐색하면서 해당 위치까지 가야한다.
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
...
...
//add 메소드를 호출하여 마지막에 Node를 추가할 경우 실행되는 로직
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
//add 메소드를 호출하여 특정 인덱스에 Node를 추가할 경우 실행되는 로직
void linkBefore(E e, Node<E> succ) {
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
//인덱스 위치의 Node를 탐색하는 메소드
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
}
else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
좋은 글 감사합니다. 자주 올게요 :)