시작하며
3단계 때 팀 빌딩은 랜덤하게 매칭되었다. 프론트 3명, 백엔드 4명으로 총 7명의 팀으로 구성되었다. 1, 2단계 때 팀원들과 분위기가 좋았어서 그대로 쭉 이어지지 않아서 아쉬웠다.
프로젝트를 시작하기 전 각자 역할을 정하게 되었는데, 나는 주도적으로 기술적 고민을 해보고 싶어서 테크 리드 역할을 맡게 되었다.
기획 단계
아이디어 톤과 1~3주차는 프로젝트 기획 단계였다. 우리 팀은 셀럽을 서포트하는 모금의 투명성을 보장해주는 플랫폼에 대한 아이디어를 구체화 해나갔다.
아래는 실제로 배포했을 때 화면 이미지이다.(GIF 파일로 저장해두었으면 더 좋았을텐데..)
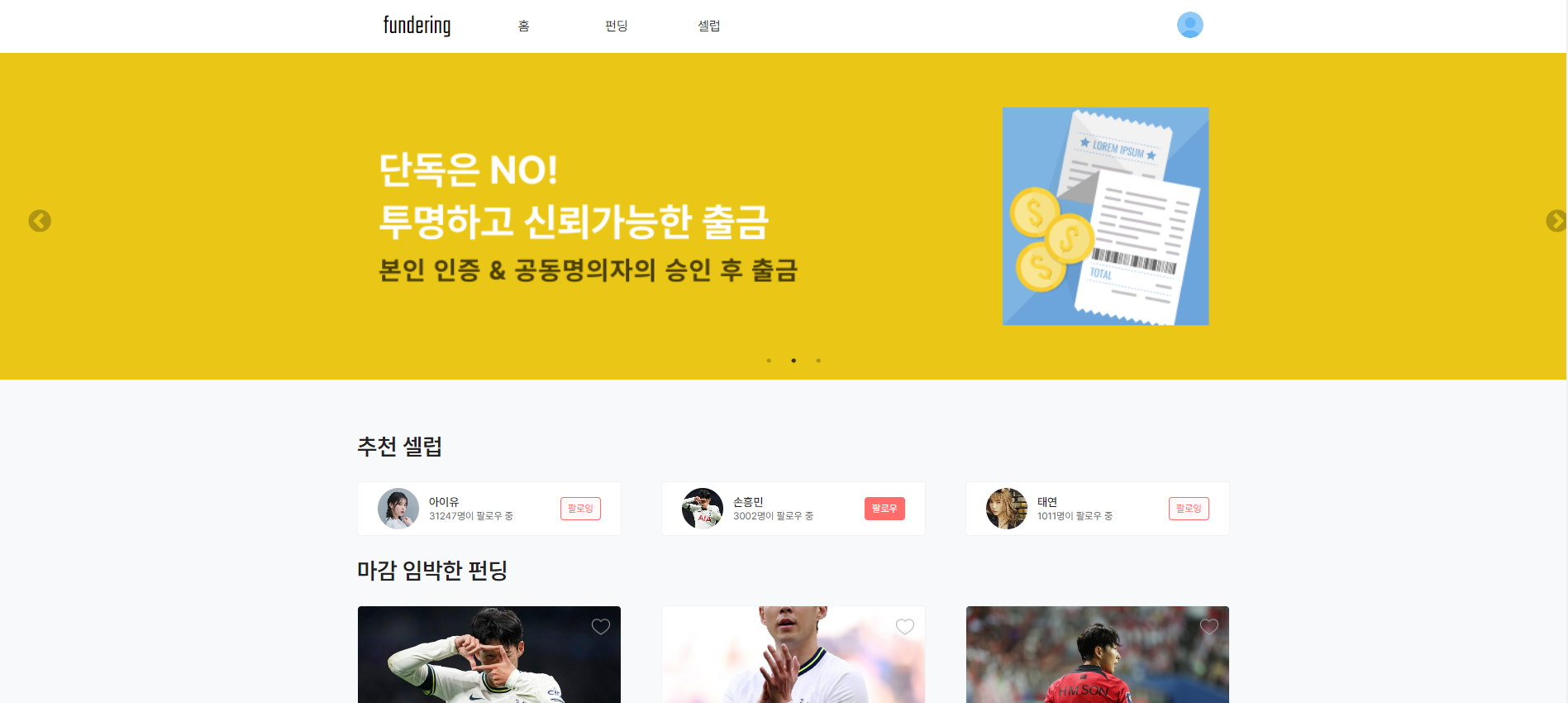
- 메인 화면
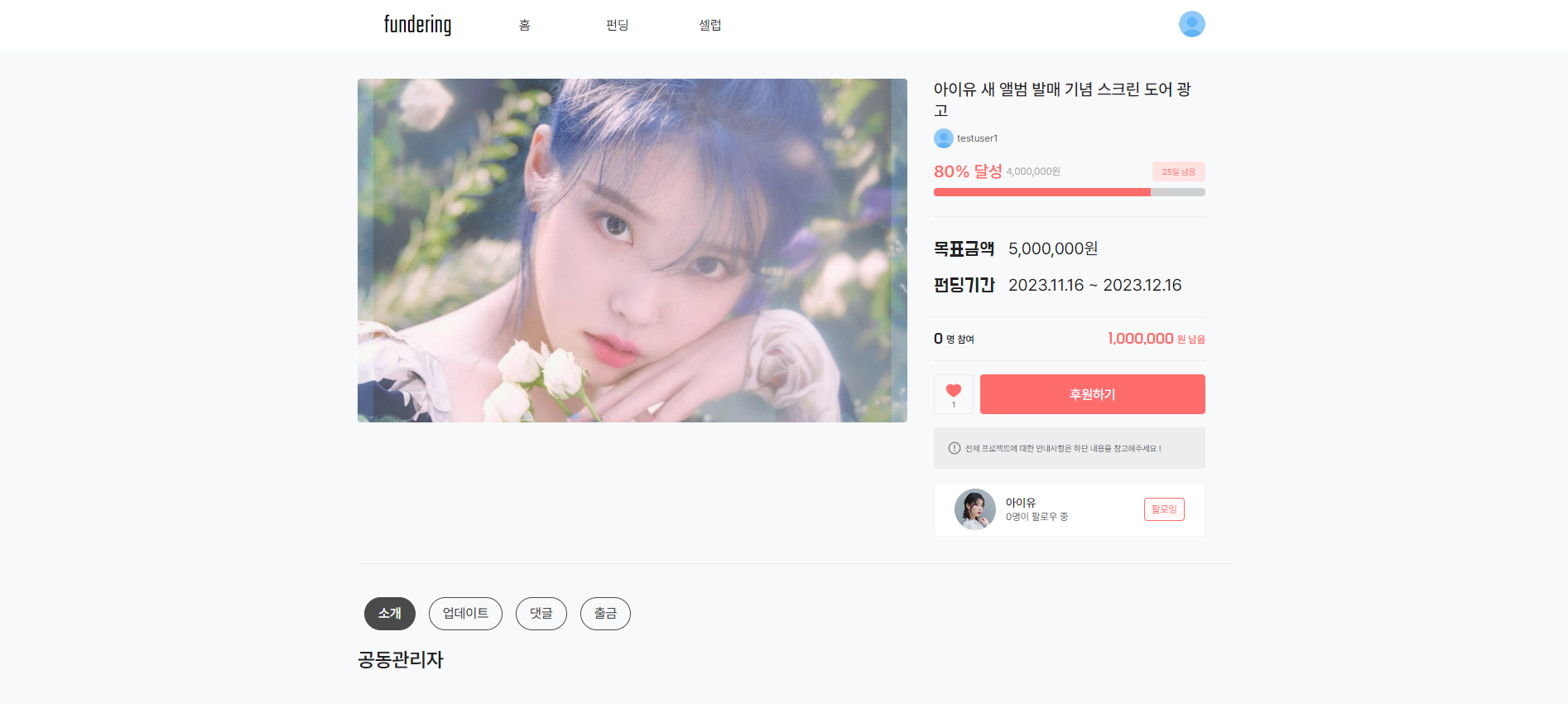
- 셀럽 펀딩 화면
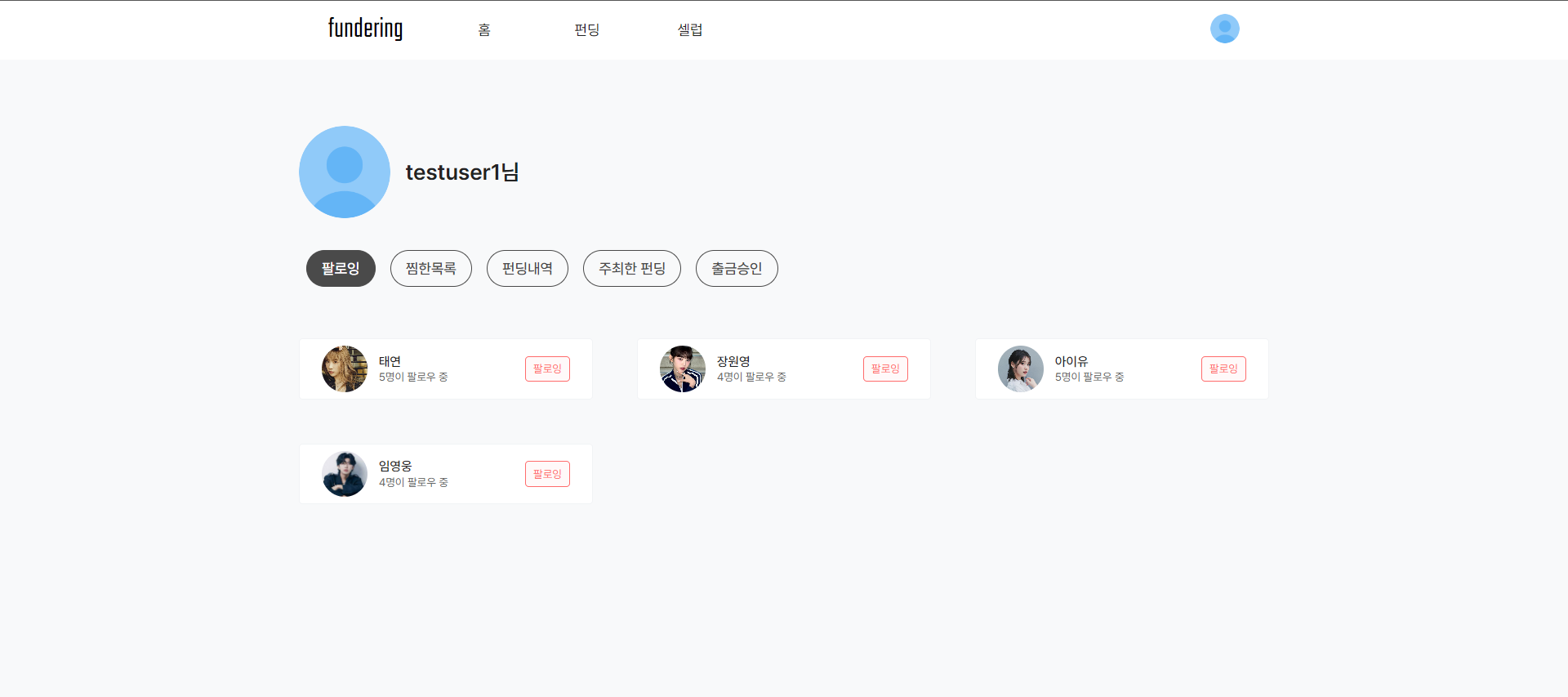
- 내 팔로잉 정보 화면
우리 팀은 매 주 화요일마다 비대면으로 팀 회의를 진행했었다. 일정 관리의 경우 매 주마다 각자 할 일을 정하거나 할당해주고 구현하는 방식으로 진행했었다.
그런데 프로젝트가 끝나고 다른 팀의 발표를 보면서 알게 되었는데, 생각보다 다양한 방식으로 일정을 관리할 수 있었다. 예를 들어서 우수상을 받은 팀의 경우 매일 매일 자신이 한 업무를 테이블에 공유하는 방식으로 각자 어떤 일을 하고 있는지 한 눈에 알 수 있었다.
우리 팀의 경우에도 API 문서를 작성하거나 github의 이슈로 대략적인 업무 진행 상태를 알 수 있긴 했지만, 디테일한 부분까지는 어떻게 진행되고 있는지 알 수 없어서 조금 아쉬웠던 것 같다.
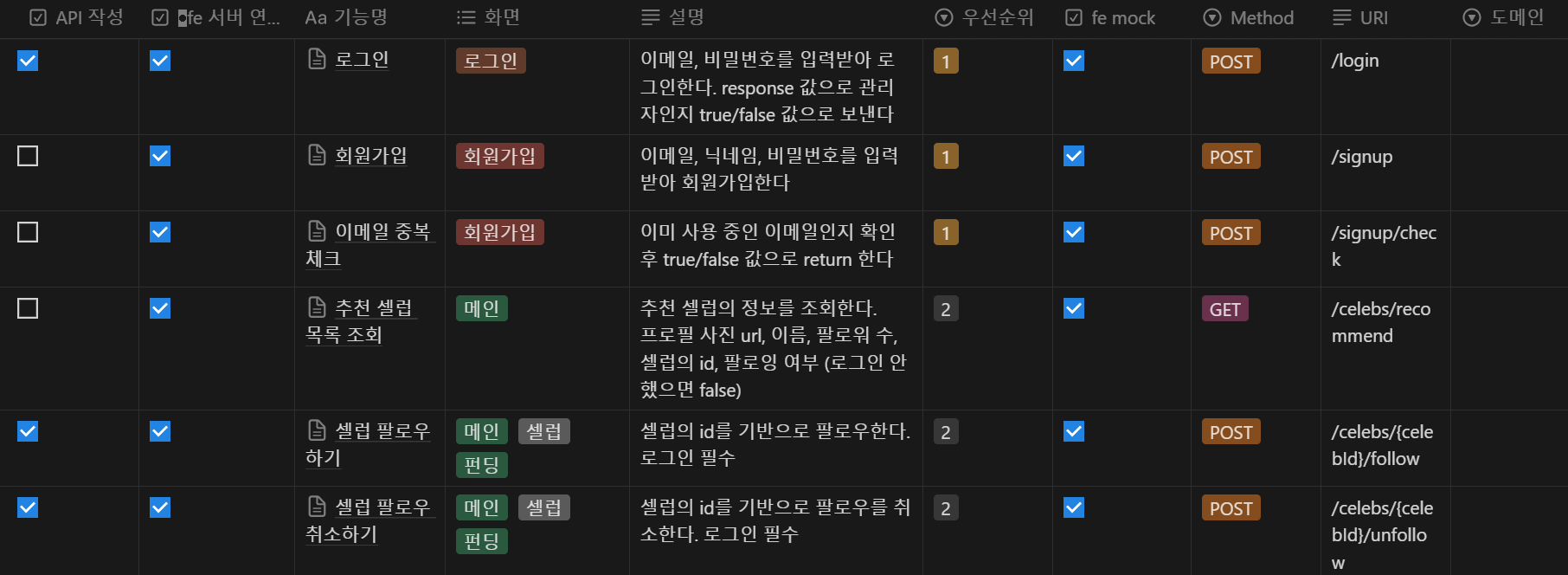
그리고 다 끝나고 나서 알게 되었는데, API 요구사항이 다른 팀에 비해 거의 2배 가까이 많았다고 한다. 그래도 어떻게든 최대한 기능들을 구현하긴 했지만, 테스트나 리팩토링 등 다른 것을 시도해볼 시간이 부족해서 요구 사항 범위를 잘 정해야 한다는 것을 알게 되었다.
개발 초기 단계
개발 초기 단계에서는 기술 스택과 프로젝트 구조, 패키지 구조, 테이블 구조 등을 고민했다.
기술 스택
이 프로젝트에서 사용했던 기술 스택은 다음과 같다.
- Language
- Java 17
- Framework
- Spring Boot 3.1.4
- Spring Data JPA 3.1.4
- QueryDSL 5.0.0
- Spring Security 6.1.4
- Build Tool
- Gradle 8.2,1
- Database
- H2 2.1.214
- Maria DB 10.6.12
- Infra
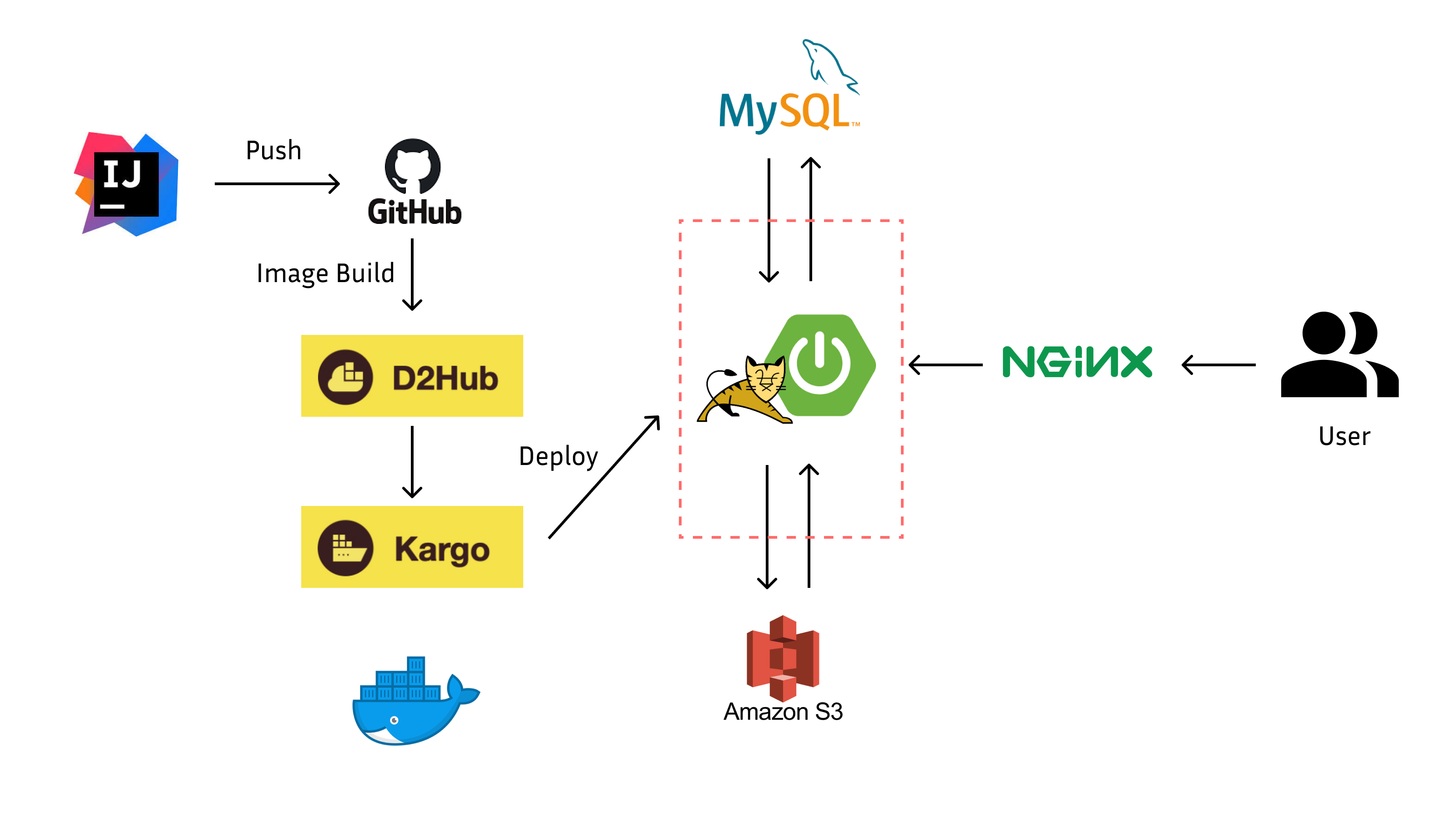
- Kubernetes
- D2Hub
- Kargo
- DKOS
자바는 크게 11 버전이랑 17 버전 사이에서 고민 했었는데, 간단하게 각각 버전을 사용하려고 했던 이유는 다음과 같다.
자바 11 버전은 자바 8 버전부터 추가된 람다식이나 Optional 클래스, LocalDateTime 과 같은 시간, 날짜 API를 사용하기 위해서였다. 또 변수 타입 추론이 가능한 var 키워드 등을 사용할 수 있기 때문이었다.(자바 11 버전을 놔두고 굳이 8 버전을 쓸 이유는 없었다.)
자바 17 버전의 경우 성능 개선 등 이점도 있지만 가장 큰 이유는 Record Data 타입을 사용할 수 있다는 점 때문이었다. DTO에 Record Data 타입을 사용해서 Lombok 의존성을 줄여서 더 깔끔한 코드를 작성할 수 있을 거 같다는 생각이 들었다.
결과적으로 자바 17을 선택했다. 그런데 정작 프로젝트에서 Record 타입은 도입하지 못했다. 팀원들이 Record 타입을 한번도 사용해보지 않았고, 기존에 익숙한 Lombok을 사용하기를 원했다. 그래서 프로젝트 마무리 시점에 Record 타입으로 리팩토링하는 방향으로 합의했지만, 결국 기능들을 구현하기도 시간이 빠듯했어서 DTO에 Record 타입을 사용하진 못했다.
스프링 부트 버전은 그때 가장 최신의 안정된 버전인 3.1.4 버전을 선택했다. JPA의 경우 JPA 대신 JDBC, MyBatis 이라는 옵션이 있었다. 하지만 일단 팀원들 전부 1, 2단계 때 JPA를 중심으로 학습했었고, JPA를 사용하면 소모적인 SQL 코드가 훨씬 줄어들기 때문에 당연히 JPA를 선택했다. 검색 쿼리 같은 동적 쿼리를 위해서 QueryDSL을 사용하게 되었다. 스프링 시큐리티의 경우 JWT로 인증과 인가를 처리하려고 선택하게 되었다.
인프라의 경우 카카오에서 Krampoline이라는 배포 환경을 제공해줘서 자연스럽게 쿠버네티스를 경험하게 되었다. 이전까지 도커랑 쿠버네티스를 한번도 안 사용해봐서 조금 걱정했었는데, 삽질도 많이 하긴 했지만 그래도 결국 배포까지 잘 마무리하게 되었다.
프로젝트 구조, 패키지 구조, 테이블 구조
└── src
├── main
│ ├── java
│ │ └── com
│ │ └── theocean
│ │ └── fundering
│ │ ├── domain
│ │ │ ├── post
│ │ │ │ ├── controller
│ │ │ │ ├── domain
│ │ │ │ ├── dto
│ │ │ │ ├── service
│ │ │ │ └── repository
│ │ │ ├── celebrity
│ │ │ │ ├── application
│ │ │ │ ├── domain
│ │ │ │ ├── dto
│ │ │ │ ├── service
│ │ │ │ └── repository
│ │ │ ....
│ │ │
│ │ └── global
│ │ ├── config
│ │ │ ├── SwaggerConfig.java
│ │ │ ├── AWSS3Config.java
│ │ │ ├── JpaAuditingConfiguration.java
│ │ │ └── security
│ │ ├── error
│ │ │ ├── ErrorResponse.java
│ │ │ ├── GlobalExceptionHandler.java
│ │ │ ├── GlobalValidationHandler.java
│ │ │ └── exception
│ │ ├── jwt
│ │ │ ├── dto
│ │ │ ├── filter
│ │ │ ├── service
│ │ │ ├── handler
│ │ │ └── JwtProvider.java
│ │ └── util
│ └── resources
│ ├── application-local.yml
│ ├── application-prod.yml
│ ├── application-cloud.yml
│ └── application.yml패키지 구조의 경우 처음에는 테이블 당 패키지를 하나씩 만드는 방식으로 정하게 되었다. 사실 이렇게 진행했던 이유가 있긴 했었지만, DB에 종속적이라서 패키지가 너무 잘게 나눠진 느낌을 지울 수 없었다. 그래서 멘토님께 다음과 같이 질문하게 되었다.
- Q. 현재 프로젝트 구조가 테이블당 도메인 패키지 하나씩 생성되어 있는 상황입니다. 이후 기능 개발을 진행하면서 쓰임이 유사한 도메인 패키지는 리팩토링을 진행하려고 합니다. 이렇게 도메인 패키지 구조를 설계한 이유는 테이블마다 도메인 패키지를 만들면 기능 개발을 진행할 때 팀원 간 역할 분배에 더 좋을 거라고 생각했기 때문입니다. 여기서 도메인 패키지 구조를 어떻게 설계하면 좋을지 피드백을 받고 싶습니다!
- A.
Celebrity는Post와Follow컬렉션을 가지고 있는데, 패키지는 수직 분할되어 있습니다. 어색하다는 느낌이 들지 않나요? 나중에 DDD를 공부하게 되면 Aggregate 라는 개념이 나옵니다. 도메인 모델링을 할 때 하나의 객체 그래프를 이루는 클래스들은 보통 하나의 패키지에 있습니다. 다른 패키지에 있다면 식별자만을 가집니다(이를테면Comment가Member를 가지지 않고memberId만을 가집니다). 패키지를 어떻게 나눌지는 사실 Use Case가 명확하게 나와야 알 수 있습니다(혹시 사용자 시나리오가 이미 있는데 제가 못 찾은 걸까요?). 제가 볼 때는 너무 미리 잘게 나눈 것 같습니다. ^^
일단 DDD에 대한 이해도 있어야 하고 너무 패키지 구조에만 시간을 쓸 수는 없어서, 일단 기능 구현을 진행하면서 이후에 서비스 로직을 작성하면서 한 트랜잭션에서 처리되어야 하는 로직을 가진 경우 패키지를 합치는 방향으로 정하게 되었다. 이후에 다른 팀들도 패키지 구조 때문에 꽤 애를 먹었다는 이야기를 들을 수 있었다.
그리고 테이블 구조에 대해서도 할 말이 많은데, 예전에 혼자서 프로젝트를 진행할 때는 기능을 구현하면서 필요한 테이블이 있으면 하나씩 추가하는 방식으로 진행했었다. 그런데 2단계 때 교육을 받으면서 repository → service → controller 이런 순서로 진행 했어서 비슷한 방식으로 ERD부터 작성하는 방식으로 접근했다. 그런데 이렇게 진행하니까 꼭 필요한 테이블만 추가 하는 게 아니라 필요 없는 정보들도 테이블에 추가하고 있다는 느낌이 받게 되었다. 멘토님도 아래처럼 이 부분에 대한 피드백을 남겨주셨다.
- A. 아직 API(web adapter, spring controller)가 하나도 없는데, 사전 설계를 통해 ERD를 먼저 그리고, 그것을 기반으로 JPA 엔터티를 생성하고 있는 중인 것 같아요. 그 과정에서 아직 ORM에 대해 깊게 알지 못할테니, ORM 설정하는 것에 공을 들이고 있을 것 같고요. :) 그런데 접근 이런 방식(inside-out 이라고 부르겠습니다)에는 큰 단점이 있는데, 우리 백엔드개발자의 사고를 딱딱한 DB 테이블에 고정시킨다는 점입니다. 이 프로젝트에는 테이블 구조를 기반으로 패키지까지 나눠뒀기 때문에, 결국 DB 테이블이 프로젝트를 지배하는 모양새가 됩니다. 쓸데없는 걸 미리 만들기도 좋고요. 평범한 layered architecture라면 아마 앞으로 이런 순서대로 개발될 것 같습니다.
-
entity -> repository -> service -> controller
저는 반대로 이런 순서를 추천드립니다.
-
controller -> service -> repository + entity
처음엔 컨트롤러에서 가짜 응답값을 만들어 보내고, 하나씩 실제 구현으로 바꿔가면 됩니다(api first approach, outside-in). 기존의 습관이 있기 때문에, 당연히 처음부터 잘 하기는 어렵습니다. 당장 바꾸는 것이 어렵다면 사고 방식이라도 db-table-first에서 벗어나야 합니다. 이 주제에 대해선 멘토링 시간에 더 이야기해보록 합시다. :)
-
이후에 멘토님의 피드백처럼 테이블에 집중하기보단 controller -> service -> repository + entity 방식으로 접근하자 구현하는데 훨씬 시간이 단축되었을 뿐만 아니라 필요한 값들에 기반해서 테이블을 추가할 수 있게 되었다.
기능 구현
내가 구현한 기능은 1. 로그인 기능, 2. 셀럽 등록/수정/삭제/조회(무한 스크롤), 3. 회원 정보 수정/탈퇴, 4. 팔로우 기능, 5. 관리자 게시글 승인/거부, 6. 내가 주최한 펀딩/참여한 펀딩 조회, 7. 펀딩 출금 내역 조회 등이 있다.
물론 이렇게 많은 기능들을 담당할 생각은 없었는데, 일정에 맞춰서 어떻게든 필요한 기능들을 구현하려고 하다 보니까 이렇게 많은 기능들을 담당하게 되었다. 나중에 배포 과정에서 통합 테스트에서 이곳저곳 에러가 발생하면서 정신없이 바빠지자 조금 후회가 되긴 했긴 했다(...) 그래도 그때로 다시 돌아가도 똑같은 선택을 할 것 같다.
구현한 기능들은 크게 3가지로 나눠서 회고를 해보려고 한다.
로그인 기능
내가 처음 담당하게 된 기능은 로그인 기능이다. JWT 방식으로 구현하게 되었는데, 세션 방식 대신 JWT 방식으로 정하게 된 이유는 일단 프론트 팀에서 JWT로 로그인하는 방식을 원했었고, JWT 방식으로 하면 세션 방식보다 서버 부담도 적고, 서버의 확장성 측면에서도 JWT가 더 유리하다고 생각했기 때문이다.
물론 나는 JWT 방식으로 로그인을 구현하는 건 처음이었고, 스프링 시큐리티를 사용해보는 것도 처음이라서 스프링 시큐리티 설정(Spring Security 6부터 설정도 기존과 많이 바뀌었다)이나 원리에 대해 이해하느라 조금 고생 했었다.
멘토님이 프로젝트 거의 마무리 되어갈 때 말씀해주시길 우리 조가 첫 주에는 프로젝트 테이블 구조에서 헤매고, 다음 주에는 핵심 기능 대신 스프링 시큐리티 설정이랑 로그인 기능처럼 부가적인 기능에 집중하는 것 같아서 걱정 했는데, 그래도 잘 마무리 되는 것 같아서 다행이라고 말씀 해주셨다.
로그인 기능의 경우 JWT 방식에서 추가적으로 보안을 고려해서 Access Token이랑 Refresh Token을 사용하는 방향으로 바뀌게 되었다. 그런데 프로젝트 기한이 끝나갈 때 알게 되었는데 Refresh Token 방식으로 로그인을 갱신 해주려면 에러 메시지를 통일해서 프론트에게 보내줘야 한다는 것을 알게 되었다. 스프링 시큐리티로 인증 관련 에러들을 공통적으로 처리할 수 있는 방법은 있었지만, 결국 시간이 부족해서 Access Token만을 사용하는 방향으로 마무리하게 되었다.
에러 처리와 관련해서 프로젝트가 끝나갈 때 통일된 에러 메시지를 에러 코드 방식으로 제공하는 게 좋다는 피드백을 받았는데, 일단 핵심 기능 구현이 중요하다고 생각해서 우선 순위를 뒤로 밀어서 나중에 에러 메시지와 관련된 이슈를 처리하게 되었다. 처음에는 노션에 에러 메시지와 에러 코드를 정해두는 방식으로 String으로 간단하게 적자는 의견이 나왔지만, 나는 그런 방식보단 HttpStatus.java 방식처럼 통일된 파일로 정의해두는 게 나을 거라는 의견을 제시해서 아래처럼 바뀌게 되었다.
public class ErrorCode {
// 사용자 조회 오류(찾을 수 없음)
public static final String ER01 = "ER01";
//셀럽 조회 오류(찾을 수 없음)
public static final String ER02 = "ER02";
// 게시물 조회 오류(찾을 수 없음)
public static final String ER03 = "ER03";
// 파일 업로드 오류(AWS S3에 업로드 할 수 없음)
public static final String ER04 = "ER04";
// 공동 관리자 선임 오류
public static final String ER05 = "ER05";추가로 이 방식보단 더 큰 분류를 정해서 에러 메시지들을 묶는 방식으로 좀더 개선할 수 있을 것 같다.
무한 스크롤 기능
페이지 기능을 구현하는 데는 크게 두 가지 방법이 있는데, Offset 방식이랑 Cursor 방식이 있다. Offset 방식의 경우 계속 조회를 누적하는 방식으로 데이터 양이 많아지면 서버에 부담을 줄 수도 있고, 조회 과정에서 새로운 게시글이 추가되면 중복 조회의 문제도 있기 때문에 Cursor 방식으로 구현하게 되었다.
사실 무한 스크롤 기능을 구현하는 것도 처음이라서 구현하면서 ‘맞게 구현하고 있는건가??’ 라는 생각이 계속 들었다. 처음 구현한 결과는 다음과 같았다.
처음 조회: 1페이지, 2페이지, 3페이지
다음 조회: 1페이지, 2페이지, 3페이지, 4페이지, 5페이지, 6페이지나중에 프론트랑 통합 테스트를 진행하면서 다음과 같은 결과를 원한다는 것을 알게 되었다.
처음 조회: 1페이지, 2페이지, 3페이지
다음 조회: 4페이지, 5페이지, 6페이지알고 보니까 기존의 조회한 데이터는 브라우저에 캐시로 저장해두기 때문에 내가 처음 구현한 방식은 중복 조회된 데이터가 쌓이게 된다는 문제가 생기는 방식이었다.
무한 스크롤을 구현하면서 처음에는 Slice 인터페이스를 그대로 사용하려다가 아래처럼 PageResponse 클래스로 모듈화 해서 필요한 정보만 노출하는 동시에 반복되는 코드도 줄이고 재사용성을 높일 수 있도록 개선하였다.
@Getter
public class PageResponse<T> {
private final List<T> content;
private final int currentPage;
private final boolean isLastPage;
public PageResponse(final Slice<T> sliceContent) {
content = sliceContent.getContent();
currentPage = sliceContent.getNumber() + 1;
isLastPage = !sliceContent.hasNext();
}
public static Slice<?> of(final List<?> content, final Pageable pageable, final boolean hasNext) {
return new SliceImpl<>(content, pageable, hasNext);
}
}프로젝트를 진행하기 전에 QueryDSL에 대해 공부하면서 자세히 이해하지 못했는데, 무한 스크롤을 구현하면서 QueryDSL 실제로 사용해보면서 더 자세히 이해하게 되었다.
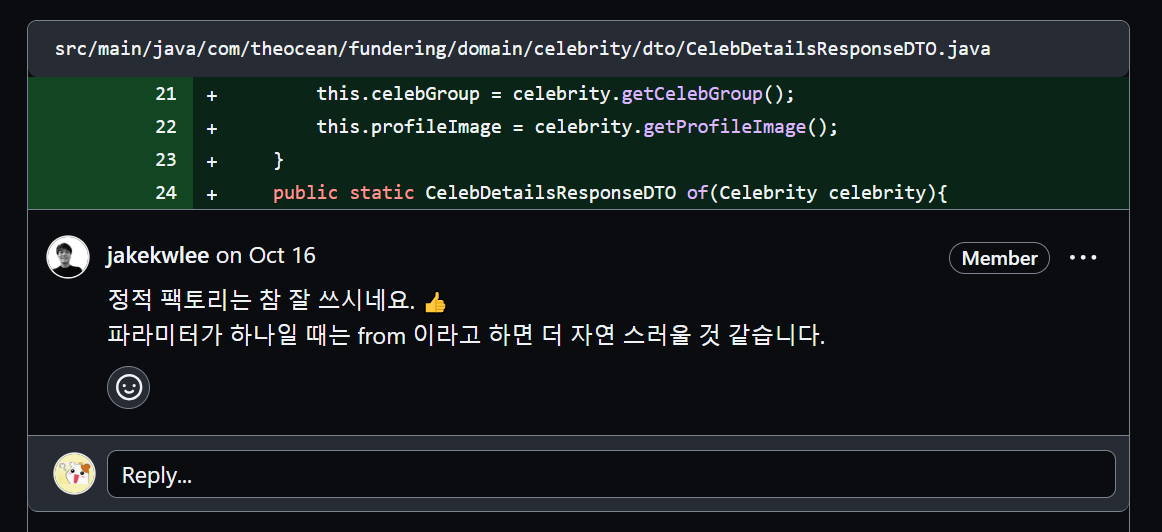
또 프로젝트를 진행하기 전에 이펙티브 자바를 공부하면서 정적 팩토리 메서드 패턴을 알게 되었지만 마찬가지로 정적 팩토리 메서드 패턴을 제대로 이해하지 못했었다. 프로젝트를 진행하면서 구현 과정에서 실제로 적용해보면서 생성자 대신 의미를 전달하기 위해 사용한다는 게 어떤 뜻인지 더 잘 이해하게 되었다.(아래는 내가 정적 팩토리 메서드 이름의 의미를 잘못 사용해서 멘토님께 피드백을 받은 케이스다.)
아쉬웠던 점은 전체적으로 기능들을 구현하면서 단위 테스트나 Mock 테스트 등 테스트를 제대로 해보지 못했다는 점이다. 구현하기에도 시간이 부족해서 기능을 구현한 후 Postman으로 로컬 서버로 빠르게 통합 테스트만 진행해보고 넘어 갔었다. 아니나 다를까 실제로 프론트와 통합 테스트를 진행하면서 이것 저것 에러가 많이 발생했었다. 이후 새 프로젝트를 하게 된다면 테스트에도 많이 신경 쓰면서 진행하면 좋을 것 같다.
팔로우 기능
팔로우 기능의 경우 처음에 엔티티를 어떻게 설계해야 할지 고민했었다. 셀럽 ↔ 팔로우 ↔ 유저와의 관계에서 ‘각각을 객체로 두고 접근하는게 맞을까’라는 의문이 들었다. 팔로우는 ORM 관점보다는 RDBMS 관점에서 접근하는 게 더 적합해 보였다. 실제로 나와 비슷한 고민을 한 블로그 글도 찾아볼 수 있었다. 사실 처음에는 그냥 팔로우를 관계만을 저장하는 테이블로 만들려고 했지만 위 블로그 글을 참고해서 복합 키를 사용하는 방향으로 아래와 같이 구현하게 되었다.
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(
name = "follow",
uniqueConstraints = @UniqueConstraint(columnNames = {"celebrity_id", "member_id"}))
@IdClass(Follow.PK.class)
@Entity
public class Follow {
@Id
@Column(name="celebrity_id", insertable = false, updatable = false)
private Long celebId;
@Id
@Column(name = "member_id", insertable = false, updatable = false)
private Long memberId;
//Follow 관계의 유일성을 위한 복합키 설정
public static class PK implements Serializable {
Long celebId;
Long memberId;
}
}이렇게 일단 MariaDB를 통해 RDBMS 방식으로 팔로우 정보를 저장하는 방식으로 구현했다. 하지만 이 팔로우 기능도 추가적으로 개선할 부분을 가지고 있다. 예를 들어서 팔로우 정보를 한 테이블에서 저장하고 있기 때문에 셀럽이 많은 팔로우를 가지고 있다면 다음과 같은 문제가 발생할 수 있다.
| 1 | 2 |
|---|---|
| 1 | 3 |
| 1 | 4 |
| 1 | 5 |
| … | … |
이렇게 셀럽(1)과 유저(2, 3, 4, 5)의 팔로우 관계를 조회하기 위해 전체 테이블을 조회해야 한다. 복합 키를 설정해서 인덱스로 접근하더라도 팔로우 관계를 조회하기에도, 저장하기에도 RDBMS가 효율적인 저장 구조는 아니라는 것을 알 수 있다.
따라서 추가적으로 트래픽이 늘어나는 경우를 고려해야 한다면 NoSQL인 Redis 등의 Key, Value 저장 구조를 고려해볼 수 있다. 이렇게 개선한다면 시간 복잡도도 O(N) → O(1)로 크게 줄어들 것이다. 물론 {”7” : [”5”, “2”, “11”, “1”, “9”, …], “4”:[”6”]} 경우처럼 Value가 O(N)처럼 늘어날 수 있지만, 이 경우 Redis의 캐시 기능을 사용한다면 훨씬 효율적일 것이다.
또 팔로우 기능에서 동시성 문제도 발생할 수 있다. 사실 팔로우 기능을 만들면서 동시성 문제가 발생할 것 같다는 생각이 들었지만 이때 구현 안된 기능들이 많아서 일단 넘어갔다..
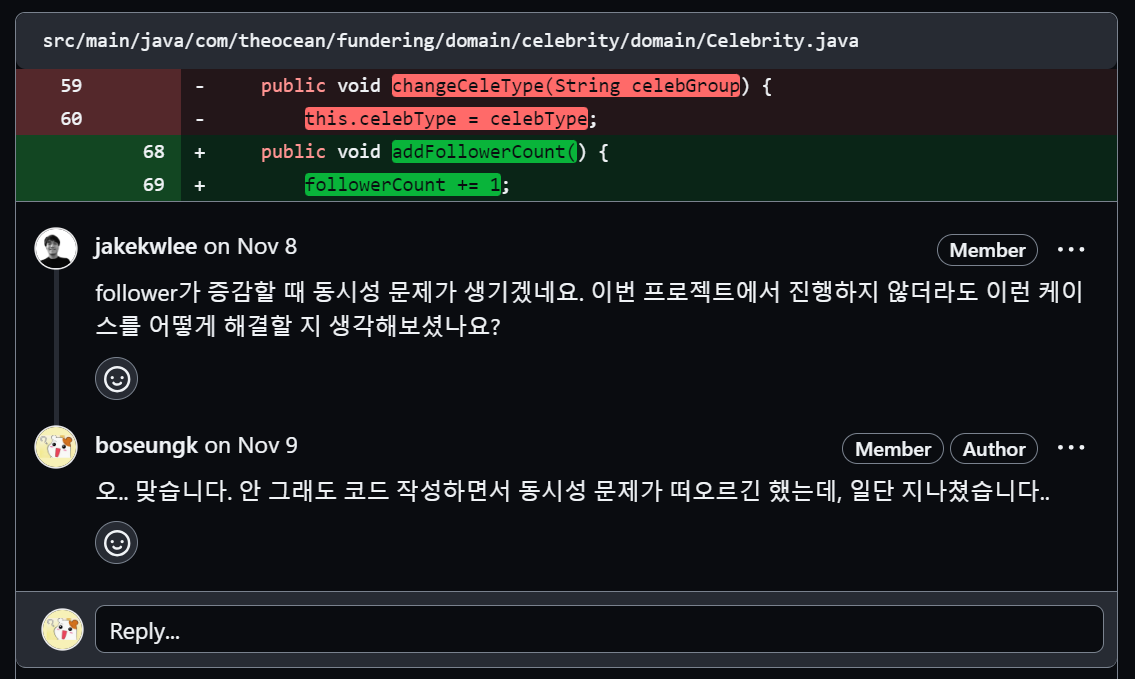
멘토링을 받기 전에 나름대로 스스로 해결해보려고 아래와 같이 ThreadLocal을 사용해보았다.
@RequiredArgsConstructor
@Transactional(readOnly = true)
@Service
public class FollowService {
private final FollowRepository followRepository;
private final CelebRepository celebRepository;
private final ThreadLocal<Celebrity> threadLocal = new ThreadLocal<>();
@Transactional
public void followCelebs(final Long celebId, final Long memberId) {
final Celebrity celebrity = celebRepository.findById(celebId).orElseThrow(
() -> new Exception400("해당 셀럽을 찾을 수 없습니다.")
);
followRepository.saveFollow(celebrity.getCelebId(), memberId);
threadLocal.set(celebrity.addFollowerCount());
celebRepository.save(threadLocal.get());
threadLocal.remove();
}멘토링 때 멘토님께 여쭤보니 실무에서는 동시성 문제를 해결하기 위해 Redis의 Redisson으로 동시성 문제를 다룬다는 것을 알게 되었다. 이후 추가로 Redis에 대해 공부해보고 다시 한번 동시성 문제를 고민해봐야 할 것 같다.
끝으로
이렇게 프로젝트를 회고 해보니까 프로젝트를 진행하면서 좋았던 점들과 아쉬웠던 점들이 정리되는 것 같다.
프로젝트를 진행하면서 가장 좋았던 것은 멘토링 시간이었다. 멘토링 과정에서 멘토님께 내가 많이 질문할수록 많이 배울 수 있을 거라는 생각이 들어서 최대한 많이 질문 했었다. 실제로도 멘토님께서도 이것저것 많이 알려주려고 하셔서 너무 감사했었다.. 물론 실력이 많이 부족해서 멘토님께서 말씀해주신 부분 중 제대로 이해하지 못한 부분도 있었다. DDD 같은 부분은 관련 개념이 아예 없어서 잘 이해되지 않아서 슬펐다.😢
프로젝트를 진행하면서 가장 아쉬웠던 점은 시간이 부족해서 기능 구현만 해보고 테스트나 리팩토링을 고민할 시간이 부족했다는 점이었다. 사실 어떻게든 기능은 구현하면서도, 성능이나 유지보수성이 좋은 코드인지 의문이 계속 들었다. 그래서 이펙티브 자바와 리팩토링, 클린 코드, 단위 테스트, TDD, 좋은 코드 나쁜 코드 등 테스트와 리팩토링에 관한 책들을 읽어보면서 어떤 식으로 코드를 개선할 수 있을 지 고민해봐야 할 것 같다. 배포 과정에서도 리눅스랑 네트워크, 인프라에 대해 좀더 공부해야겠다는 생각이 많이 들었다. 공부를 위해 볼만한 책으로는 AWS 교과서, HTTP 완벽 가이드 등이 있을 것 같다.
카카오 테크 캠퍼스 3단계 프로젝트 진행하면서 실제로 많은 것을 배울 수 있었고, 앞으로 어떤 것을 배워야 할지 알게 되는 기회가 되었다. 방학 때 해당 부분들도 공부하고, 알고리즘도 공부하고, 할 일이 많을 것 같다.
