가상화 기술과 도커

해당 포스팅은 개발자를 위한 쉬운 도커 를 수강하고 작성한 포스팅입니다.
차례
- 도입
- 서버란?
- 가상화 기술
- 하이퍼바이저와 컨테이너 기술
- 도커
도입
여기서 본인은 도커를 잘 안다고 생각하는 사람은 손 들어보자

(일단 난 아ㅏ님)
일단 나로 말할거 같으면 내가 진행한 모든 프로젝트에서 배포 시 도커를 사용하였고 왜 도커를 사용하였느냐 라고 말하면
빠르고 쉽더라
정도...? blue,green 무중단 배포를 구현할때 Docker Compose의 장점을 좀 체감하였지만 설명 할 수는 없었다.
그래서 이번 강의를 수강하면서 넌 왜 도커를 사용했냐 라는 말에 자신있게 대답 할 수 있는 백엔드 개발자가 되기 위해 강의를 수강하게 되었다.
서버란?
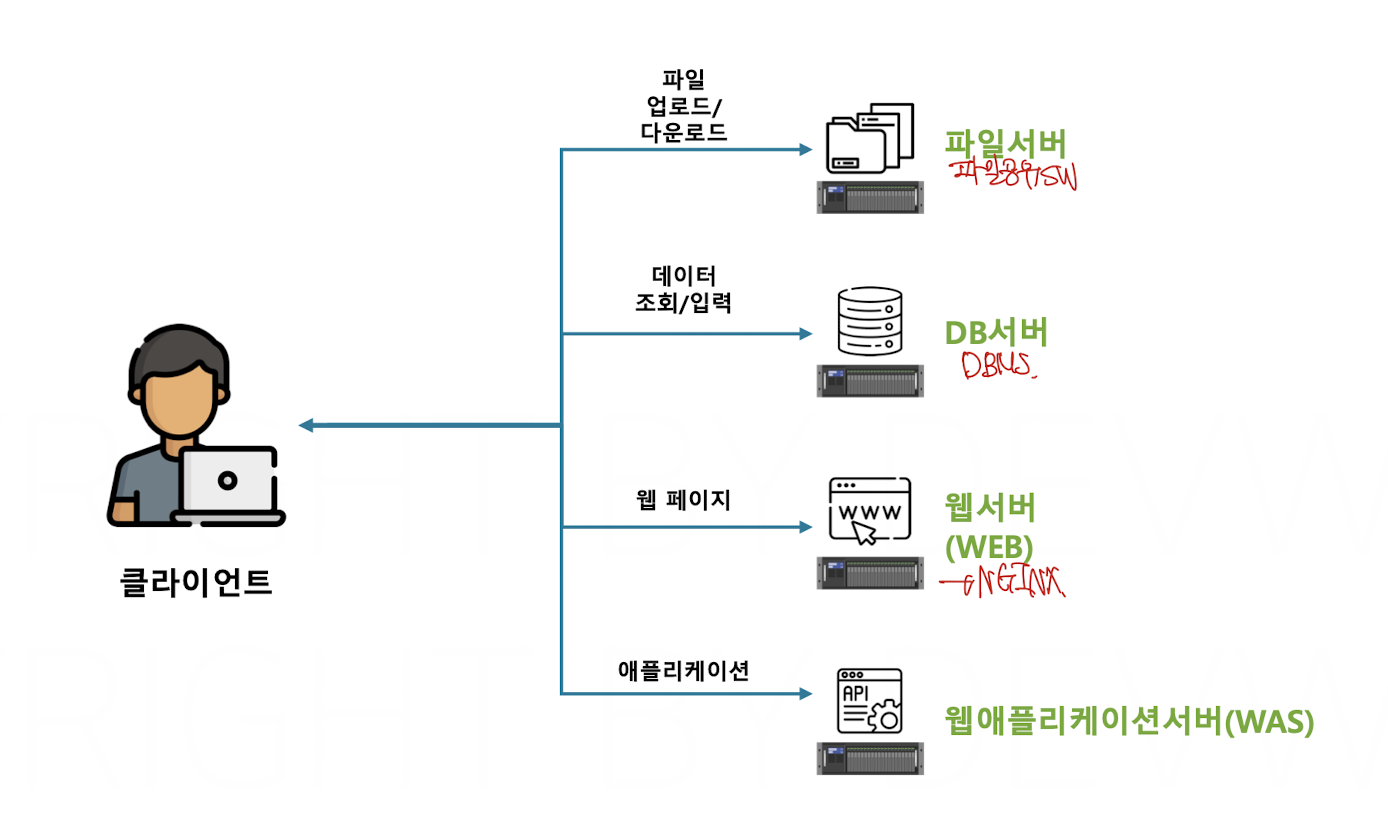
서버란 간단히 말해 클라이언트가 필요한 데이터를 serve 해주는 역할을 하는 것이다. 서버는 제공해야하는 데이터가 무엇이냐에 따라 위와 같이 분류 될 수 있다.
이렇게 생각하면 간단 할 수 있지만, 우리가 구현하는 서버는 저렇게 단순한 형태가 아니다.
아주 간단한 application 하나를 구성할때에도 데이터베이스 서버와 was 서버를 분리하여 구현하고 (물론 was에 포함시킬 수 있지만) 이러한 상황에서도 벌써 두 개의 서버를 사용하였다.
또한 하나의 was만 있을때의 다양한 문제 상황 (부하문제, 도메인 문제 등)을 해결하기 위해 여러개의 서버를 가동 하는 아키텍쳐도 존재한다.
이러한 상황에서 우리는 두가지의 선택지 중에서 좋은 방법을 고를 수 있다
- 저렴한 여러개의 서버
- 비싼 하나의 서버
최근에는 하드웨어의 성능이 증가하고 소프트웨어의 요구사항이 줄어듦에 따라 후자를 선택하고 그 위에서 여러개의 서버를 구동하는 가상화 방식를 통해 서버를 주로 구현을 한다.
가상화란?
가상화란 하나의 컴퓨터에서 여러 대의 컴퓨터를 운영하는 것과 같도록 아키텍쳐를 구성하는 것을 의미한다.

이는 하나의 컴퓨터가 1 Core에 8GB의 RAM을 이용하는 네 개의 컴퓨터가 있다고 가정하면,
실제 하드웨어의 4Core와 32GB의 RAM을 이용하는 것과 같다.
이를 구현하기 위해서
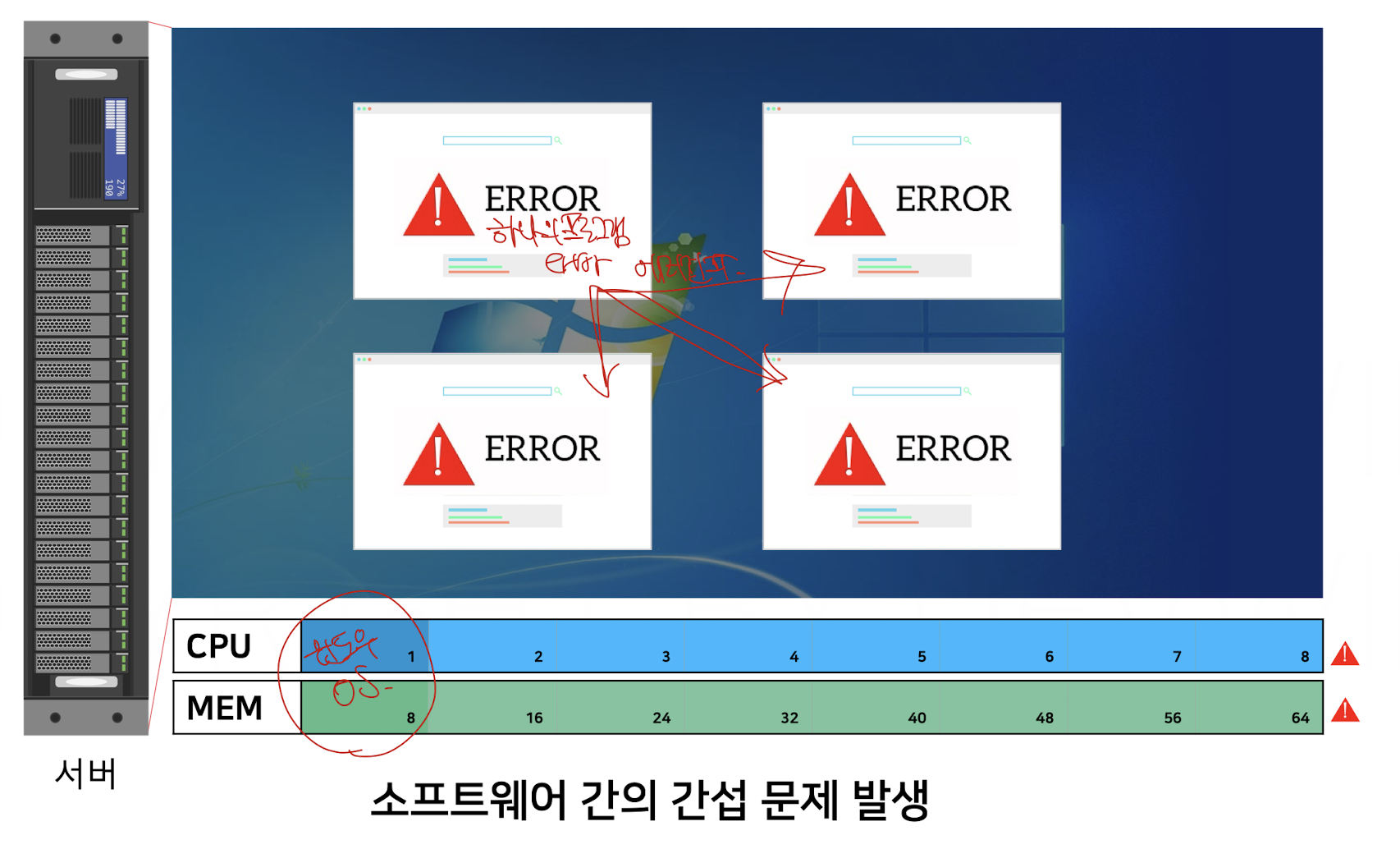
단순히 네 개의 서버를 바로 띄워버릴 수도 있지만
이는 논리적으로 분리되어 있지 않은 형태이기 때문에, 하나의 SW에서 에러가 발생하면 CPU와 메모리 등 다양한 서버자원을 독점하게 되고
그러면 나머지 SW까지 에러가 전파되는 구조라 유지보수의 관점에서 매우 불리하다.
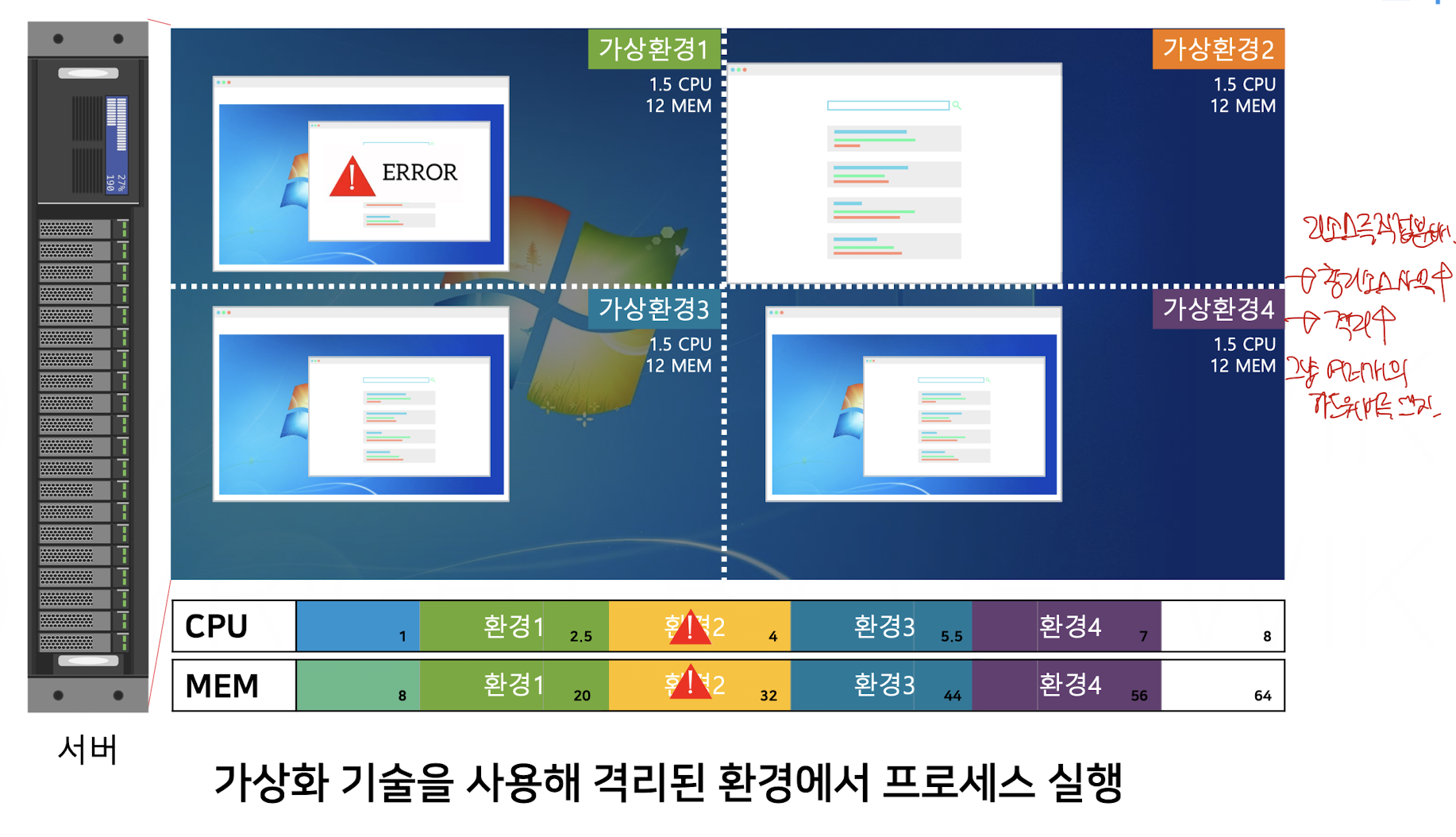
그렇기 때문에 우리는 가상화 기술을 이용해서 각 SW의 자원과 용량을 제한하고 하나의 환경에서 문제가 발생하면 해당 환경에서만 에러가 발생하도록 제한 할 수 있다.
이러한 가상화 환경의 구축 방법에는
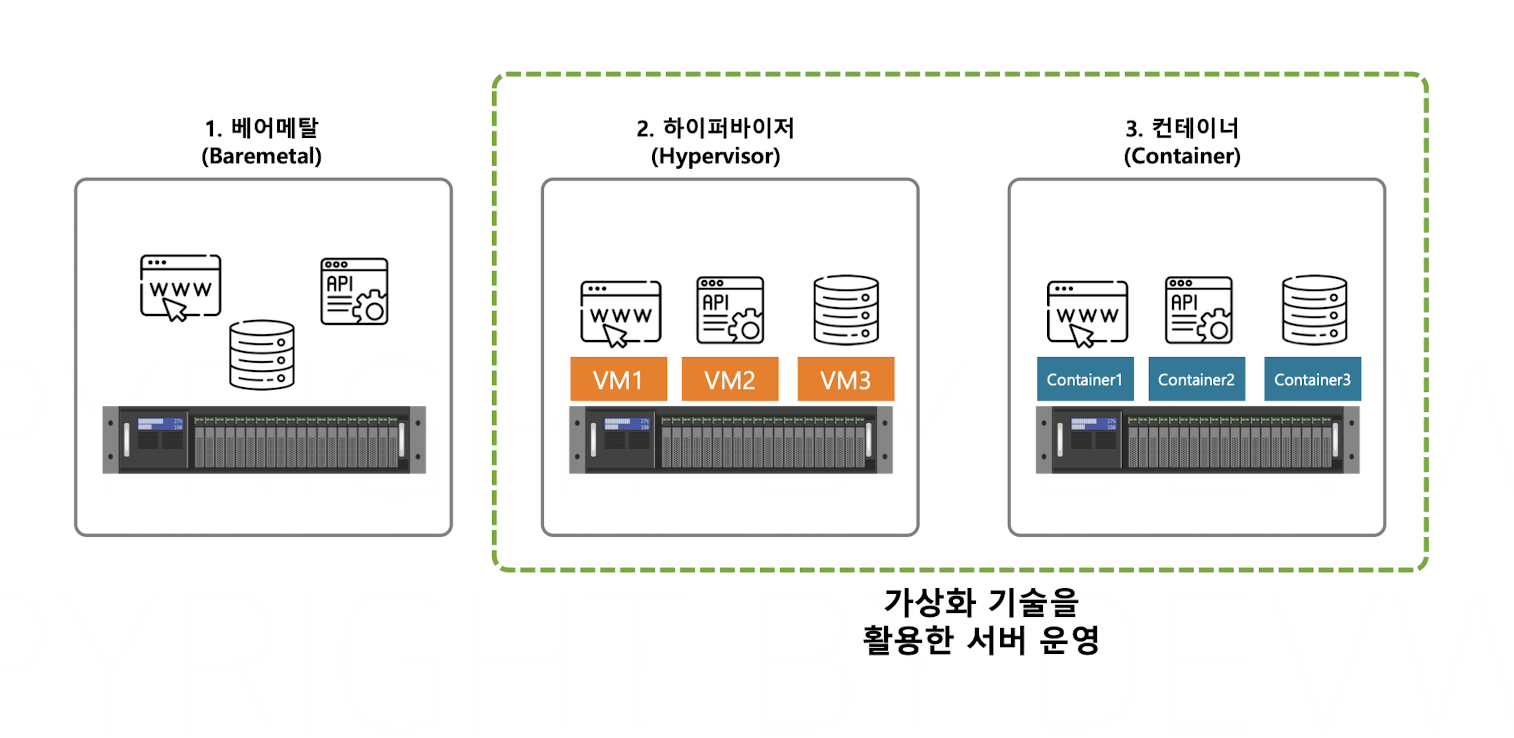
이렇게 세 가지가 존재한다
- 베어메탈
‘베어메탈(Bare Metal)’이란 용어는 원래 하드웨어 상에 어떤 소프트웨어도 설치되어 있지 않은 상태를 뜻한다. - 하이퍼바이저
- 컨테이너
베어메탈은 깊게 들어가지 않고 하이퍼 바이저부터 보도록하자
하이퍼바이저
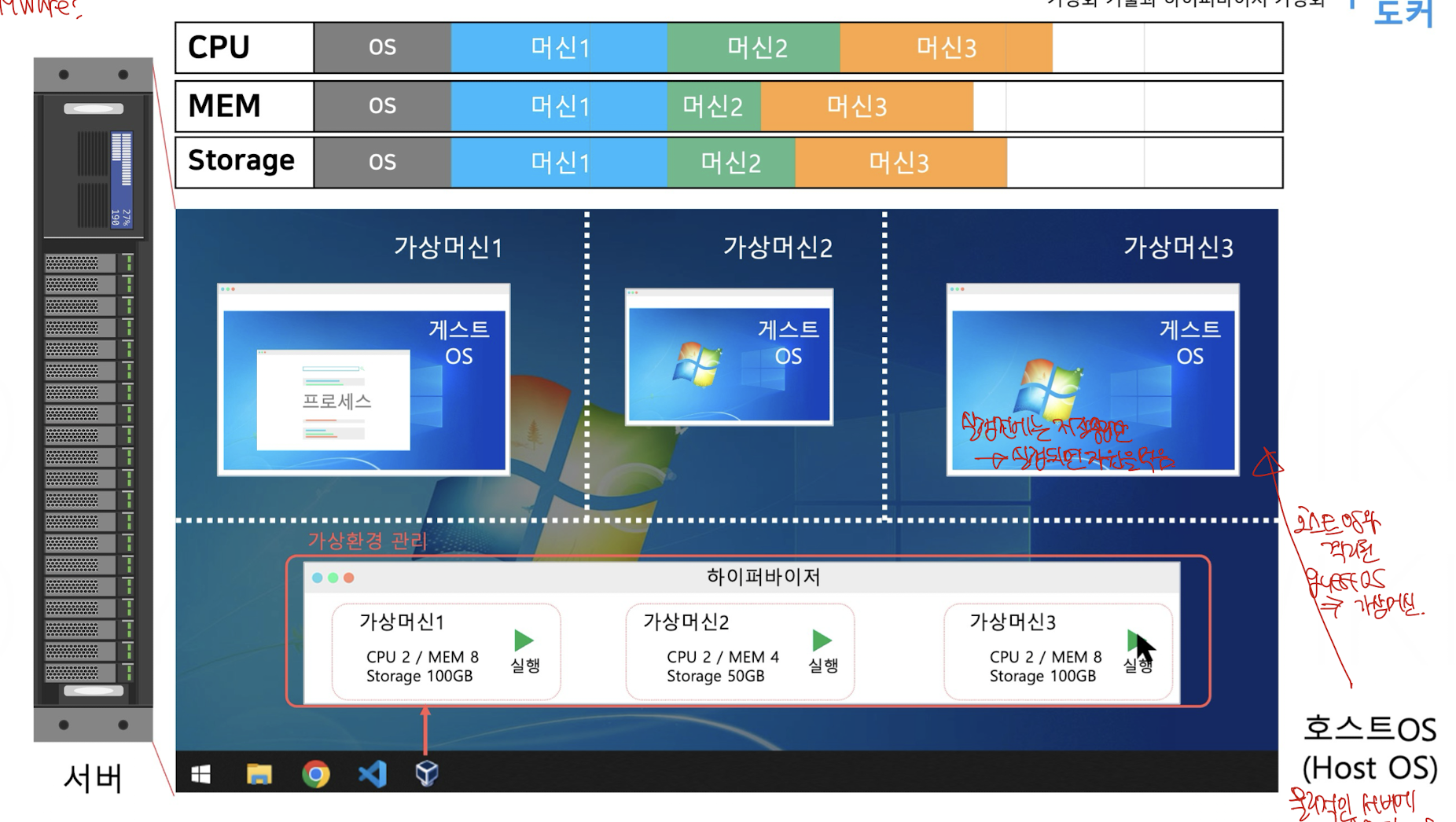
하이퍼바이저는 가상화를 위한 SW를 두고 해당 SW가 다양한 가상머신을 관리 할 수 있도록 구현한 아키텍쳐이다.
이때 가상환경의 주인인 하드웨어를 HOST OS라고 하고 가상환경들을 GUEST OS라고 한다.
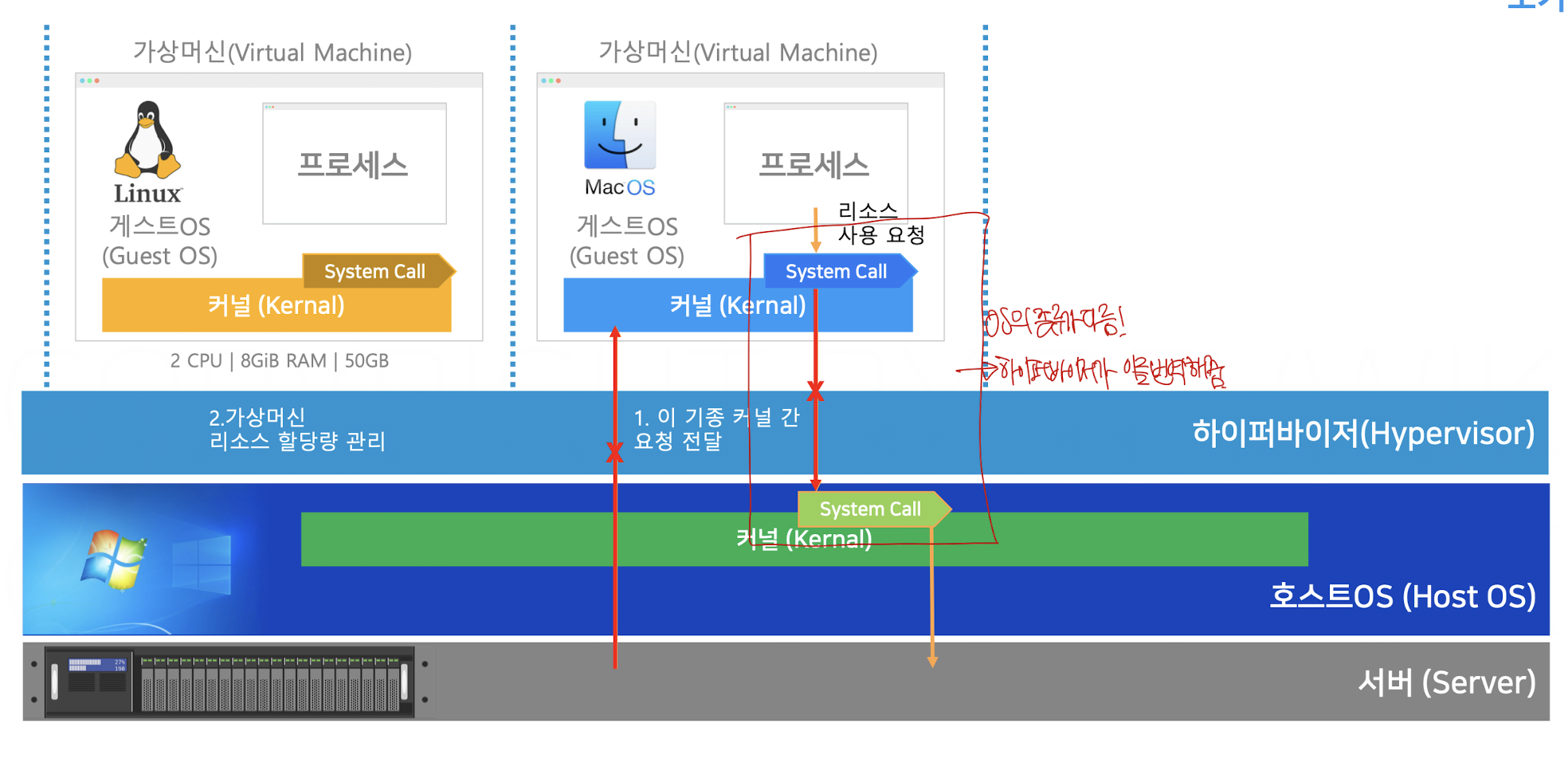
하이퍼 바이저는 HOST OS의 커널과 다른 가상머신 내의 커널을 이용하여 작업을 수행한다. 그러면 자연스럽게 OS간의 불일치가 일어나는데 이를 잡아주는게 하이퍼 바이저이다.
이 밖에도 자원을 관리해주는 다양한 기능을 하이퍼바이저가 수행한다.
그리고 이거 공부하면서, 내가 쓰고 있는 VMWare나 UTM이 하이퍼바이저려나 생각하고 있었는데 맞다고 한다.
컨테이너 가상화
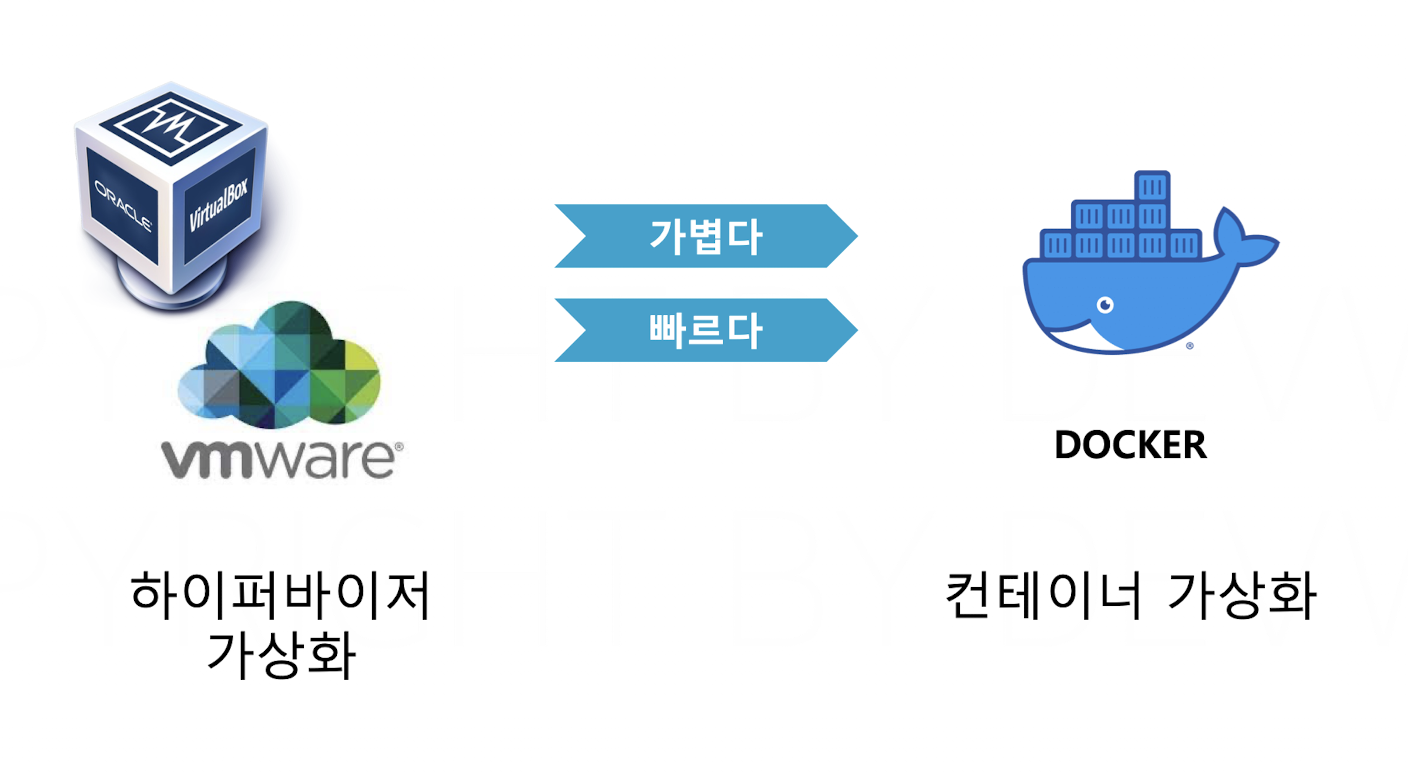
하이퍼 바이저는 OS간의 불일치를 해결하는 등 다양한 로직이 포함되어 있는 SW를 설치해야하기에, 무겁고 그러다보니 느리다는 단점이 있다.
컨테이너 가상화 기술은 이를 해결할 수 있는데, 어떻게 해결할까?
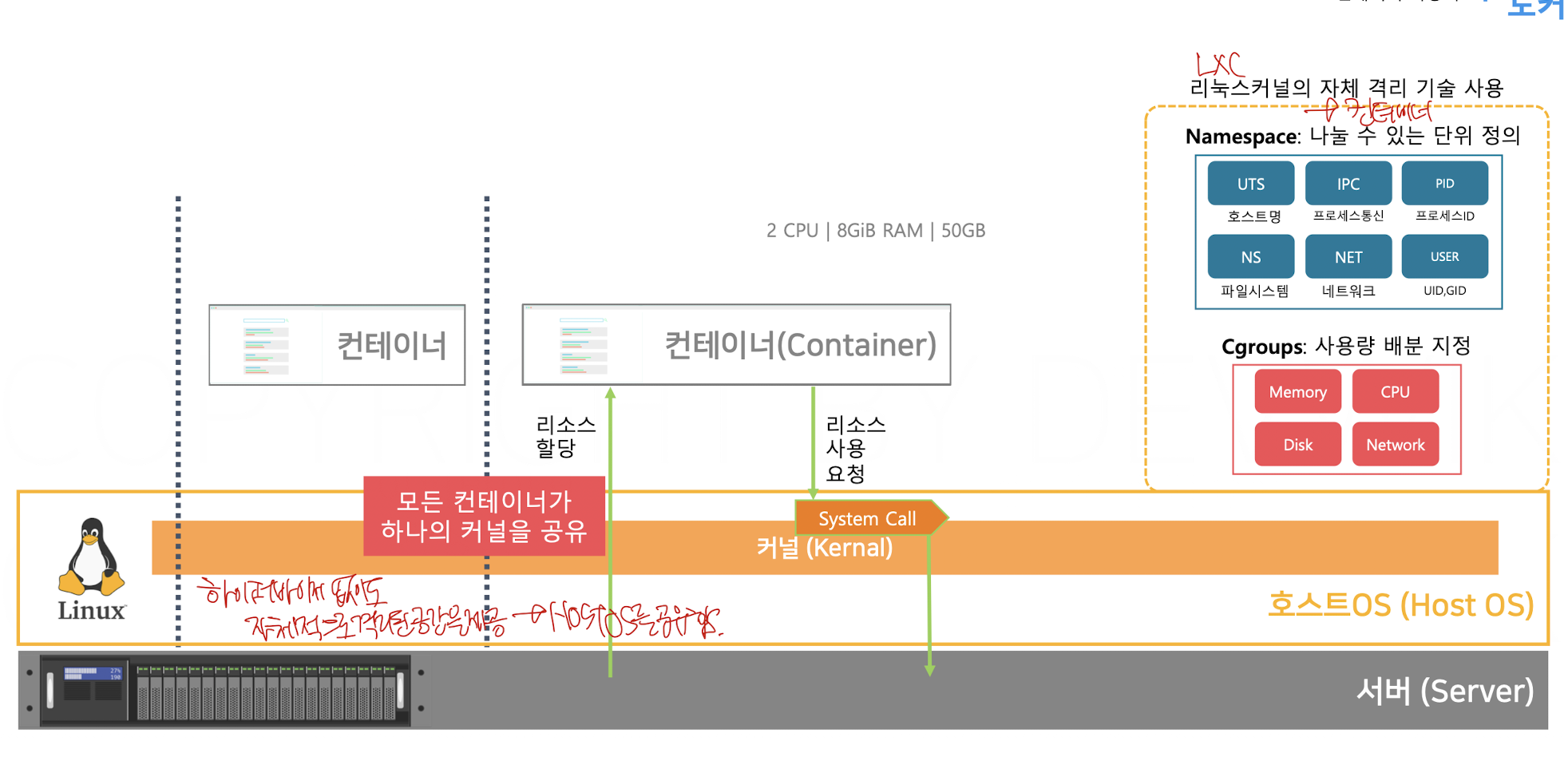
컨테이너 기술은 LXC라는 기술을 이용하여 Namespace와 Cgroups를 이용하여 컨테이너라는 단위로 가상환경을 분리한다.
그리고 이렇게 생성한 컨테이너에서 작업을 수행할때 HOST OS의 커널을 이용한다.
이 부분이 굉장히 포인트인데, 같은 커널을 이용하기 때문에 하이퍼바이저라는 SW를 통해서 구현될 필요가 없다는 점에서 하이퍼바이저보다 가볍고 빠르다는 장점이 존재하는 것이다.
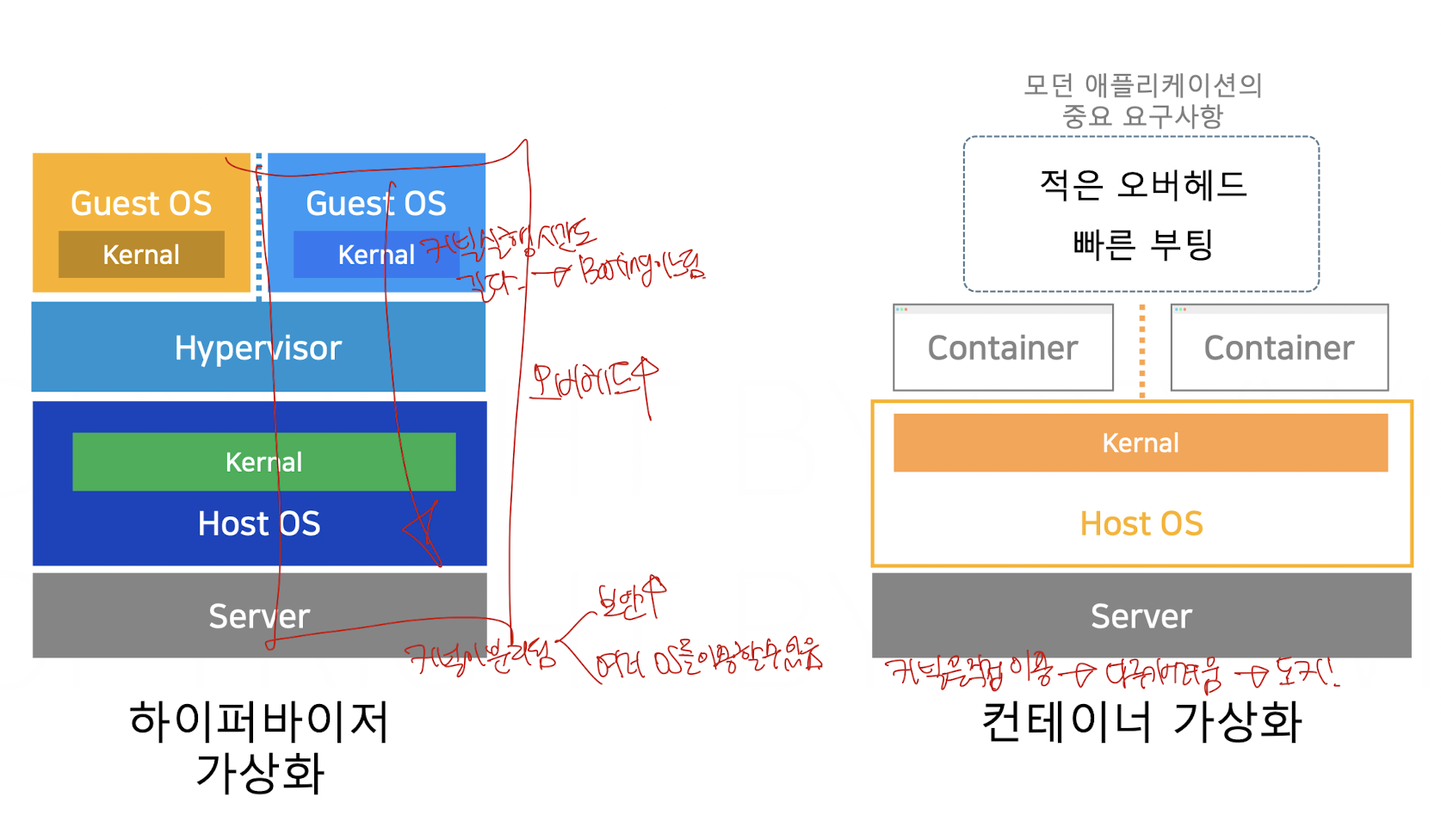
하지만 그러함 때문에 컨테이너는 HOST와 다른 OS를 사용 할 수 없다는 단점이 존재한다.
또한 아예 가상환경을 격리해버리는 하이퍼바이저에 비해 보안에 취약하다는 단점 또한 존재한다.
이러한 가상화 기술은 굉장히 유용하지만 커널을 직접 이용해야 한다는 점에 있어서 구현이 비교적 어렵다는 단점이 존재한다.
그리고 이러한 단점을 해결해주는 방법이 컨테이너 기술을 추상화하는 것이고 그것이 도커!!!!!!!
도커
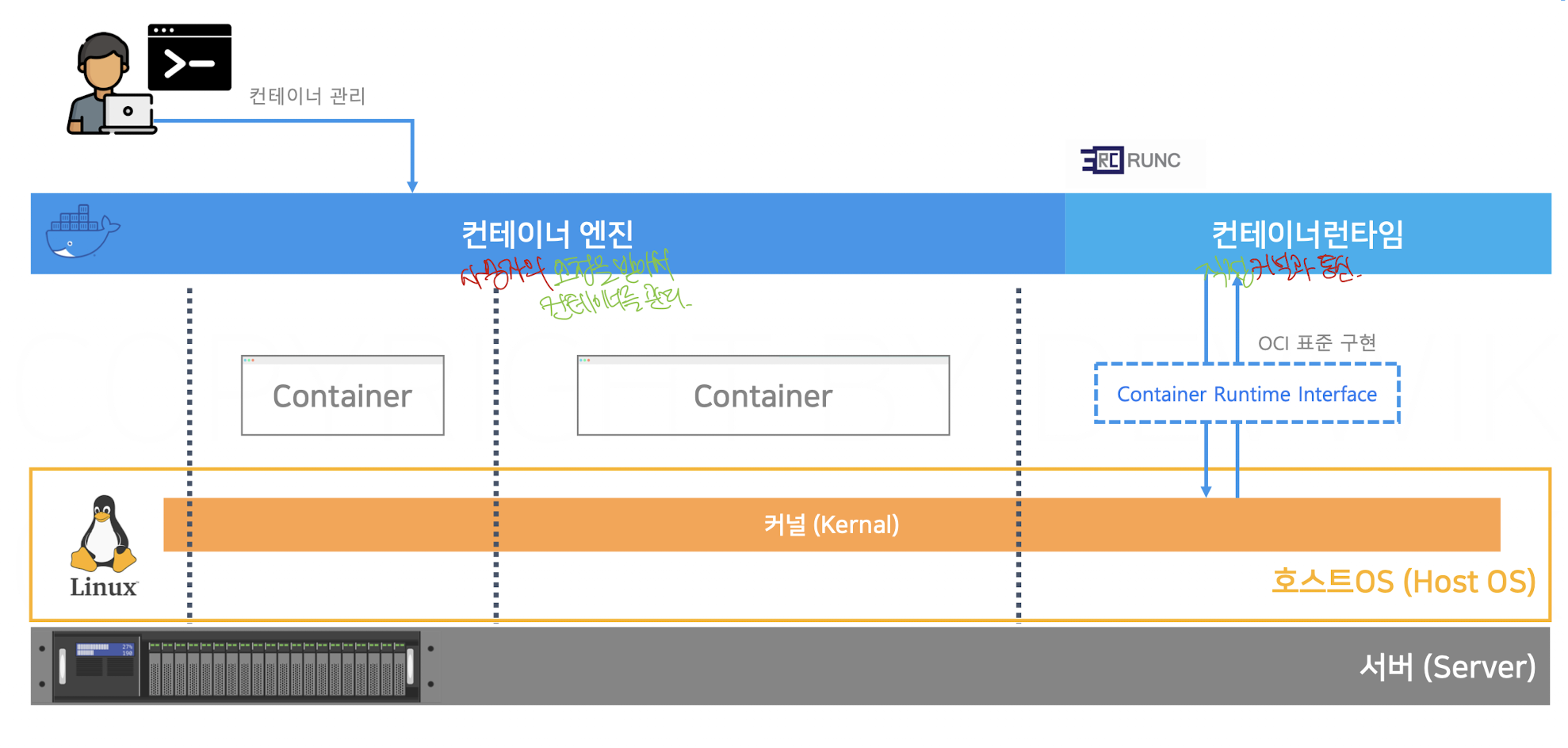
도커는 컨테이너 엔진과 컨테이너 런타임으로 나뉘어진다.
컨테이너 엔진은 사용자의 요청을 받아서 컨테이너를 관리하는 역할을 하고, 컨테이너 런타임은 직접 커널과 통신하며 실제적인 로직을 실행한다고 볼 수 있다.
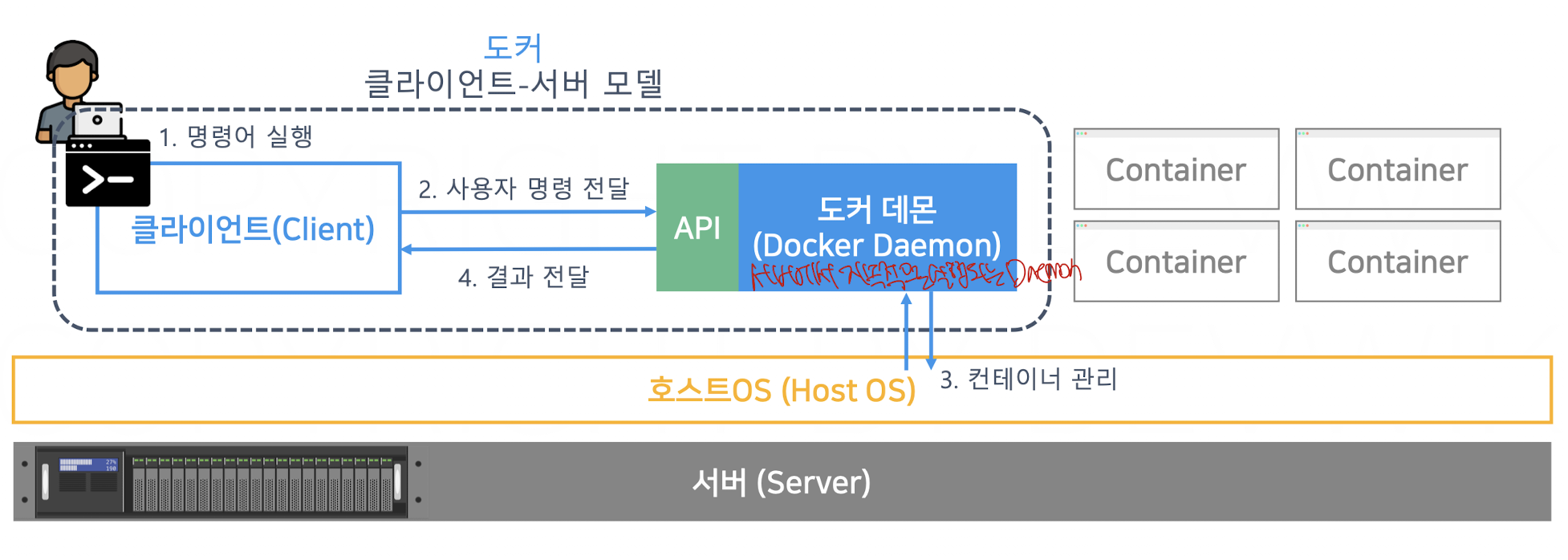
이러한 도커는 서버-클라이언트 방식으로 구현된다. 도커를 사용하는 우리가 클라이언트가 되어 명령을 전달하면 도커라는 서버가 응답을 준다.
이때 도커라는 서버에서 항시 가동되는 프로세스를 도커 데몬 프로세스라고 한다. 그리고 이를 적절하게 이용하기 위해 API를 제공한다
이 부분도 되게 신기했다. 도커도 HTTP 통신을 통한 API를 이용하여 실행되는 것이었다니,
하지만 이러한 도커의 API는 다양한 API의 공통된 문제점일 수 있지만, 사용하기가 어렵다.
이미 역사도 너무 오래되었고 구현 로직도 매우 복잡하기 때문에 API이지만, 그 활용난이도가 너무 높다는 것이다.
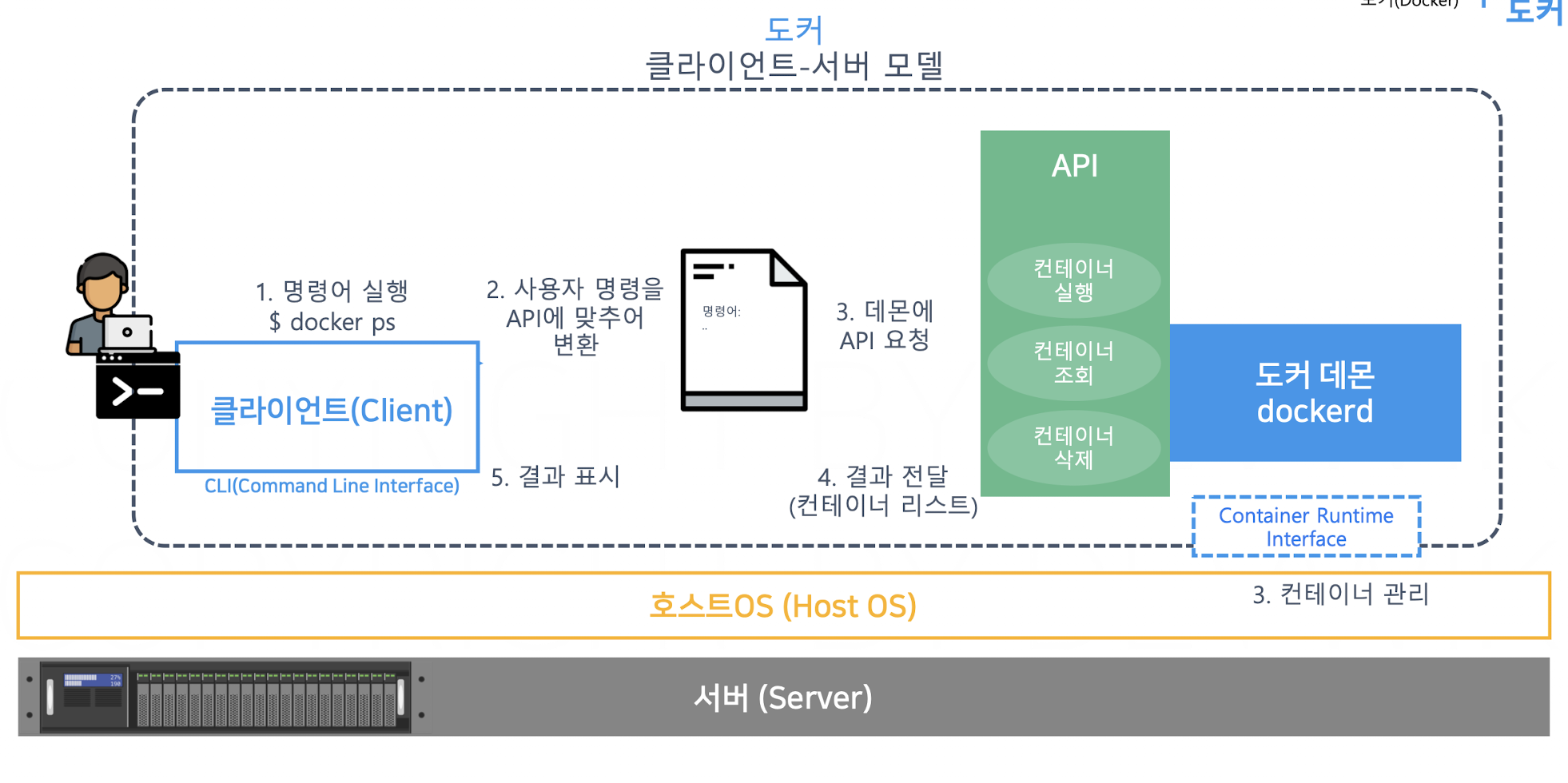
그래서 우리는 도커를 직접적으로 사용하지 않고, Docker CLI를 통해서 도커를 사용한다.
이를 사용하는 예시를 docker run 을 통해 알아보자
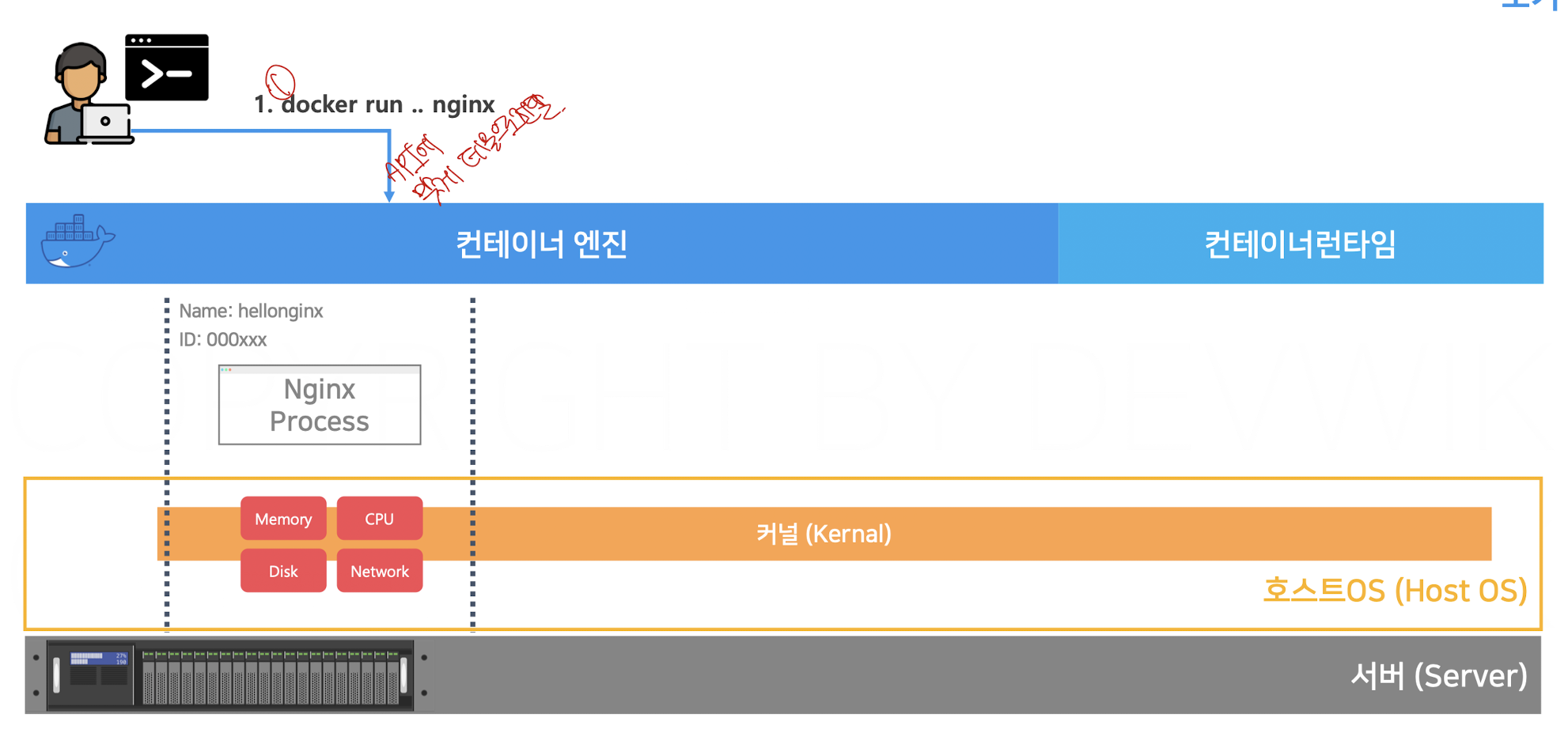
docker run -p 80:80 --name hellonginx nginx이라는 명령어를 실행하면 nginx라는 이미지가 새로운 컨테이너에서 실행된다.
즉, 해당 명령어가 Docker CLI를 통해 API로 전환되어 컨테이너 엔진에게 전달되고
컨테이너 엔진은 컨테이너 런타임을 이용하여 명령을 수행하게 되는 것이다.
