해시(Hash)
임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것
해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.
ex)a나 apple은 길이가 다르지만, 문자열을 32bit의 16진수로 나타낸다고 하면 길이가 고정됨
- ? 왜 해시가 나왔을까?
-
arraylist는 빠른 검색 속도지만, 추가/삭제에서 비효율적이었고, linkedlist에서는 빠른 추가/삭제가 가능하지만, 순차검색으로 검색속도가 느렸다(자세한 건 여기 참고)
→ 이런 한계를 극복하기 위해 제시된 방법 = hash
⇒ 해시는 내부적으로 배열(array)을 만들어서 데이터가 저장되는 인덱스를 그 데이터만의 고유한 위치로 정해서 데이터 추가/삭제시 데이터의 이동이 없도록(like linkedlist) 만들어진 구조이다.
Hash가 내부적으로 사용하는 배열(array)을 Hash Table이라고 한다.
*hash table: key-value에서 key는 hash method로 게산해서 배열의 인덱스로 사용해서 저장하는 방식
*Hash Method에 의해 반환된 데이터의 고유 숫자값을 Hash Code라고 함
** hashing: Hash Method를 이용해서 데이터를 Hash Table에 저장하고 검색하는 기법
-
-
hashmap
-
MAP은 key-value로 데이터를 다를 수 있도록 하는 인터페이스
-
key는 중복이 되면 안된다→ 새로운 key가 들어오면 중복검사를 해야함 →HashMap에서 hash는 key를 hashcode로 고유의 값으로 만들어서 중복검사함
-
같은 key값이 들어오면 hashcode로 변환 후 같은 값을 찾아 덮어쓴다
ex) String클래스에서 값이 입력되면 object의 hashcode()를 오버라이딩해서 코드로 변환하기 때문에, 서로다른 string객체라도 입력된 값이 같다면 hashcode는 동일한 코드를 반환하는 원리와 유사하다.
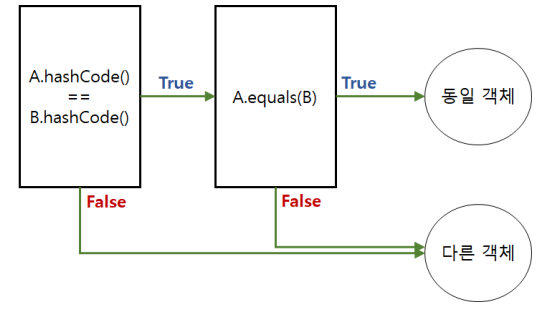
2개의 객체가 hashcode()와 equals()메소드에서 모두 true가 나오면 동일객체로 취급하기 때문에 원하는 객체를 찾거나 덮어쓸 수 있다
-
-
즉, 이에 맞게 객체의 hashcode, equals메소드를 오버로딩해주는 것이 중요하다
class Node {
int x;
int y;
@Override
public int hashCode() {
return x + y;
}
@Override
public boolean equals(Object obj) {
if (obj instanceof Node){
Node node = (Node) obj;
return node.x == this.x && node.y == this.y;
}
return false
}
}? Set에 hash를 쓰는 이유?
→ set은 매번 원소가 중복되는 원소인지 아닌지 검사하면 매우 비효율적, hash를 통해 고유의 index를 얻으면, 해당 인덱스에 있는 요소만 검사하면 되기 때문
