RandomForest 기법을 활용하여 MNIST 손글씨 데이터를 학습하고 예측하는 분류기 만들기
필요한 라이브러리 목록 :
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from joblib import dump, load
import seaborn as sns데이터 불러오기
online일 경우 데이터를 인터넷에서 받고 그렇지 않다면 path를 지정해서 받아온다.
불러온 데이터를 확인하기 위해 show_image, show_all_image, show_data_values 함수를 만들었다.
# Data load ###
def load_dataset(online=False):
if online:
(tr_data, tr_label), (te_data, te_label) = tf.keras.datasets.mnist.load_data()
else:
path = "mnist.npz"
(tr_data, tr_label), (te_data, te_label) = tf.keras.datasets.mnist.load_data(path)
return (tr_data, tr_label), (te_data, te_label)
# image show
def show_image(dataset, index):
# plt.imshow(dataset[index])
# coloring : 255-dataset[i] - black -> white
plt.imshow(255-dataset[index], cmap="gray")
plt.show()
def show_all_image(dataset):
for i in range(len(dataset)):
show_image(dataset, i)
# def show_all_image(dataset):
# user_input = True
# data_num = 0
#
# while user_input:
# show_image(dataset, data_num)
# data_num += 1
#
# user_input = plt.waitforbuttonpress()
# Bar graph for data
def show_data_values(label):
count_value = np.bincount(label)
print(count_value)
plt.bar(np.arange(0, 10), count_value)
plt.xticks(np.arange(0, 10))
plt.grid()
plt.show()RandomForestClassifier()
학습은 sklearn의 RandomForestClassifier() 사용
def train(x, y):
clf = RandomForestClassifier()
clf.fit(x, y)
print(clf.score(x, y))
dump(clf, "RandomForest_MNIST.pkl")score 함수
학습 결과를 확인하기 위해 만든 score 함수
def score(result):
good, bad = 0, 0
for i in range(len(result)):
# print(result[i], test_label[i])
if result[i] == test_label[i]:
good += 1
else:
bad += 1
# print(f"{result[i]}와 {test_data[i]} 는 다릅니다.")
return good+bad, good, badmain
# ## run ##
if __name__ == "__main__":
(train_data, train_label), (test_data, test_label) = load_dataset()
# print(train_data[0])
# ### show_image Check ###
# show_image(train_data, 0)
# show_image(train_data, 100)
# show_image(train_data, 50000)
# ## Call show_all_image - Only when you wan to see images
# print(train_label[:10])
# show_all_image(train_data)
# print(test_label[:10])
# show_all_image(test_data)
# # Show Data Values
# show_data_values(train_label)
# show_data_values(test_label)
# ### TRAIN ###
# print(len(train_data))
# 28*28 = 784 --> 1차원 배열로
train_data = train_data.reshape(len(train_data), 784)
# train(train_data, train_label)
# ### TEST ###
test_data = test_data.reshape(len(test_data), 784)
model = load("RandomForest_MNIST.pkl")
result = model.predict(test_data)
# print(result)
# print(test_label[:10])
# Check Score
total, good, bad = score(result)
print(f'정확도 {good}/{total}({round((good / total) * 100, 2)}%)')
resultList = [[0]*10 for i in range(10)]
# print(resultList)
for i in range(len(result)):
resultList[result[i]][test_label[i]] += 1
for i in range(len(result)):
resultList[result[i]][test_label[i]] = (resultList[result[i]][test_label[i]]/sum(resultList[result[i]]))*100
# print(sum(resultList[result[0]]))
# print(sum(resultList[0]+resultList[1]+resultList[2]+resultList[3]+resultList[4]+resultList[5]+resultList[6]+resultList[7]+resultList[8]+resultList[9]))
# print(resultList)학습결과
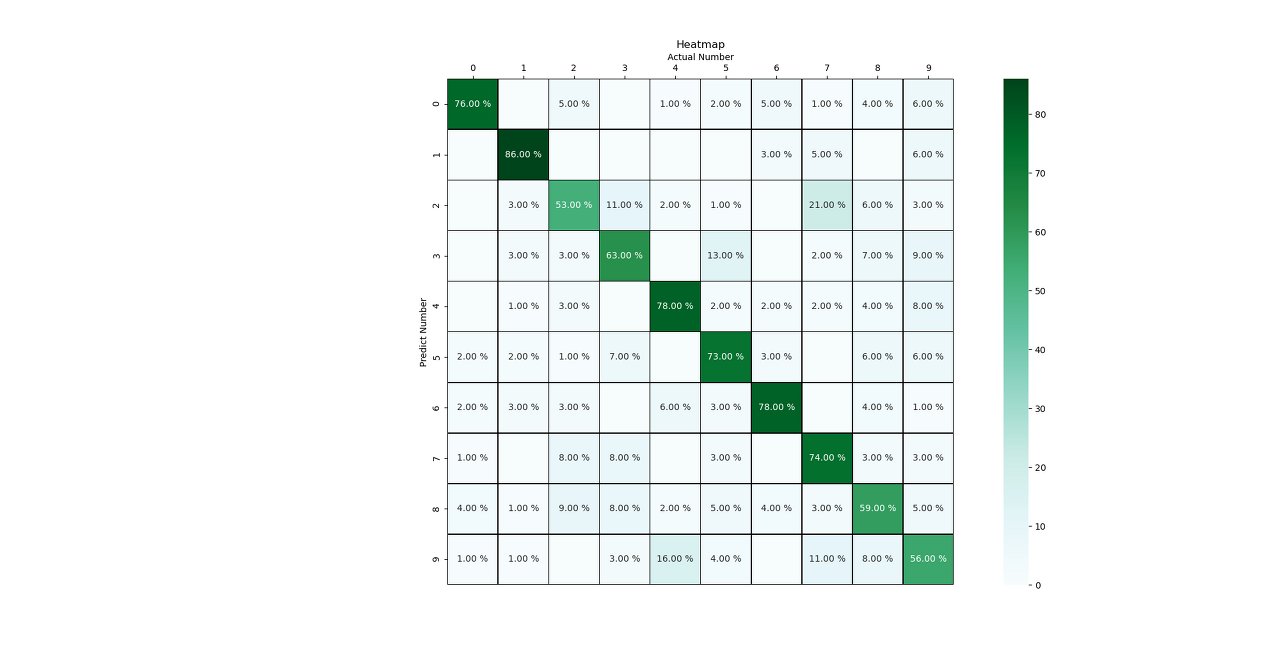
# ### Plotting ###
# resultList2[resultList == 0] = np.nan
plt.subplots(figsize=(20, 15))
plot = sns.heatmap(resultList, annot=True, fmt='.2f', cbar=True, cmap='BuGn', linewidths='0.5', linecolor='black', square=True)
plot.xaxis.set_label_position('top')
plot.xaxis.tick_top()
plt.xlabel("Actual Number")
plt.ylabel("Predict Number")
plt.title("Heatmap")
for t in plot.texts:
if t.get_text() == "0.00":
t.set_text("")
else:
t.set_text(t.get_text() + " %")
plt.show()
내 지식의 외장하드