Graph
개요
graph는 노드(vertices)와 edge들로 이루어진 자료 구조이다.
edge들은 vertices 사이간 관계를 나타낸다.
G(V, E)
V(G): a finite, nonempty set of vertices
E(G): a set of edges (pair of vertices)
Undirected Graph
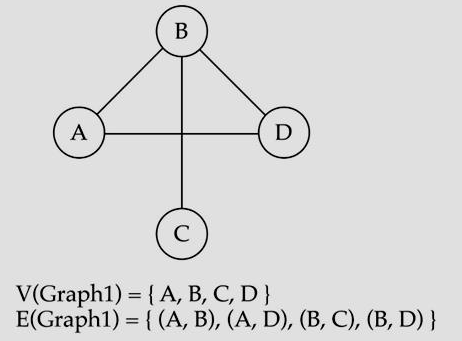
그래프의 edge들이 방향성이 없을 때 undirected라 부른다.
Directed Graph
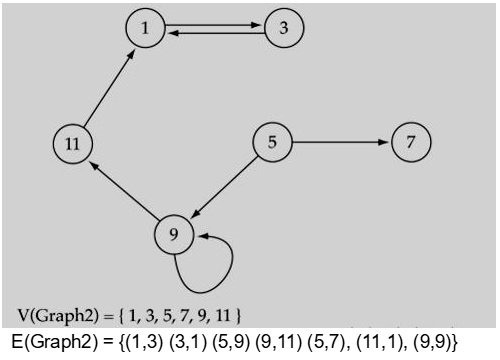
그래프의 edge들이 방향성이 있을 때 Directed라 부른다.
방향성이 있을 땐 vertices의 순서에 주의해야한다.
Tree
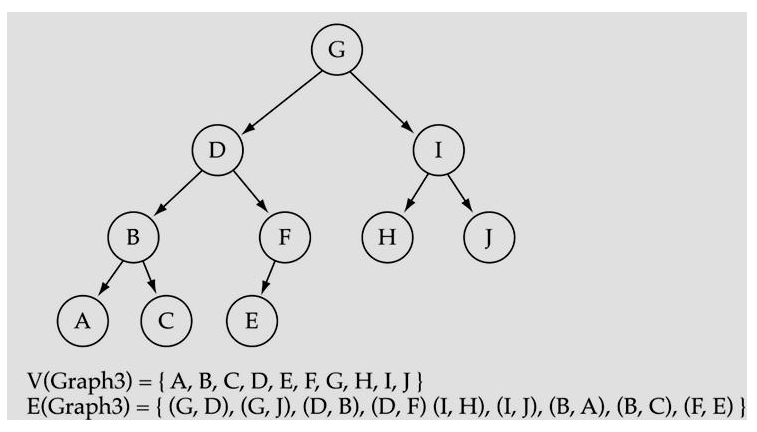
tree는 그래프의 특수 케이스이다.
Terms
Adjacent nodes: 두 개의 노드가 edge로 연결되어 있을때
Path: 그래프에서 두 개의 노드를 잇는 a sequence of vertices
Complete graph: 모든 vertex가 서로 연결되어있는 graph
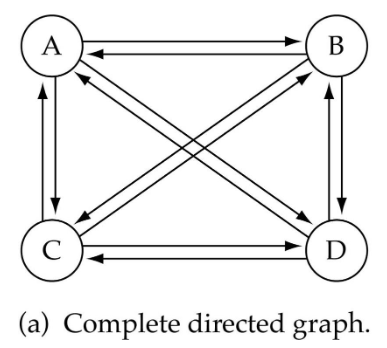
edge들의 개수
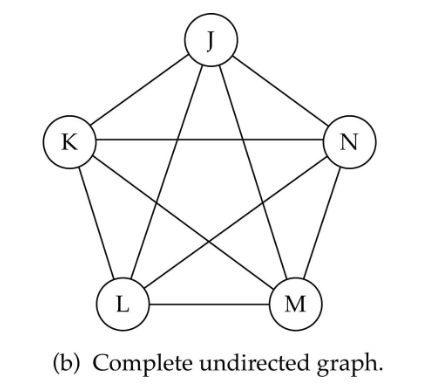
edge들의 개수
Weighted Graph
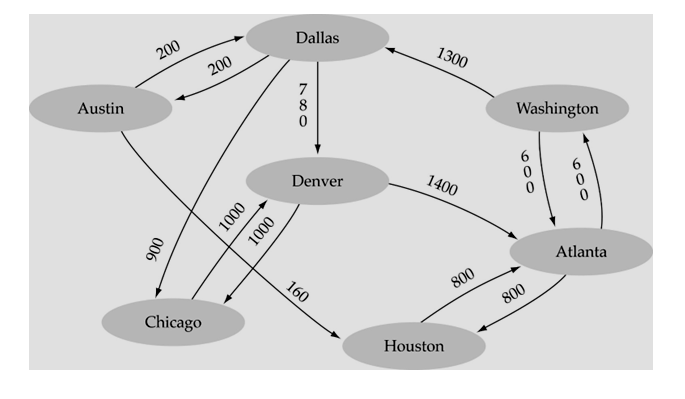
각 edge들이 값을 나르는 graph를 weigthed graph라 한다.
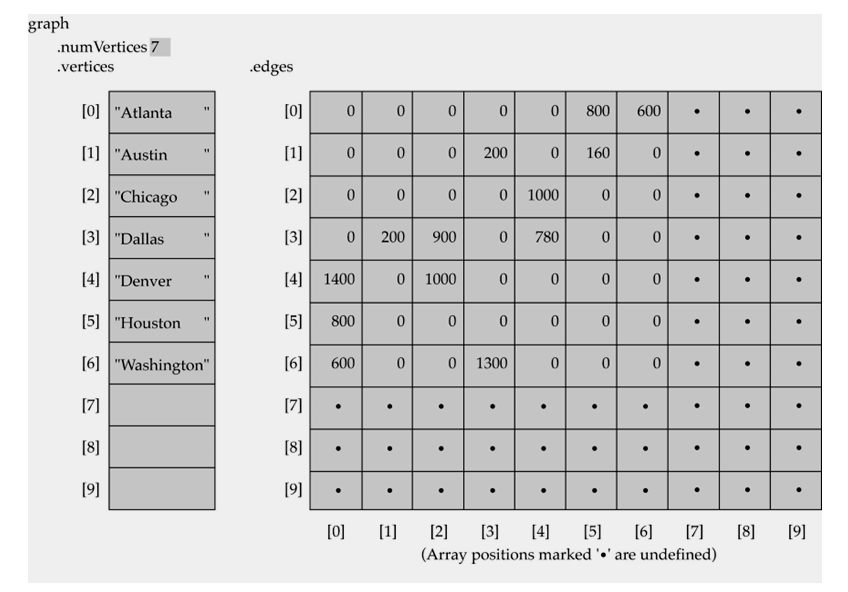
Adjacency Matrix
그래프를 표현하기 위해 matrix를 사용할수 있다.
A 1D array: vertice들을 나타냄
A 2D Array (adjacency matrix): edge들을 나타냄
edge 존재안하면 -> 0
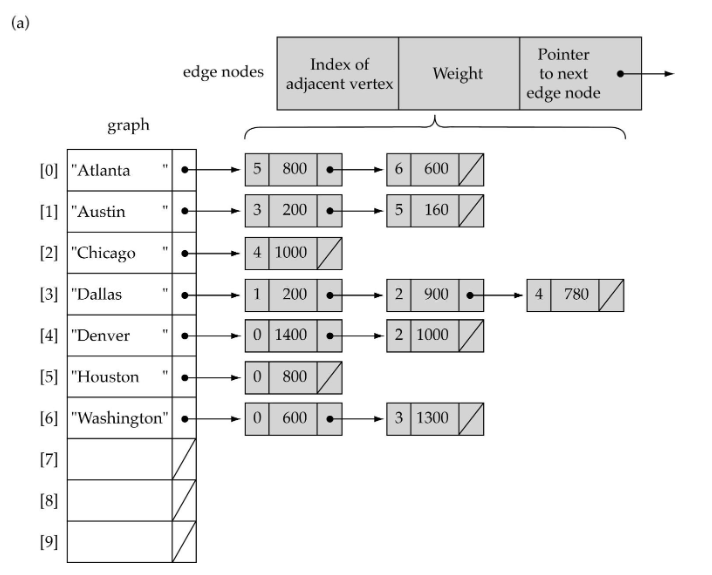
Adjacency List
Linked list로도 그래프를 나타낼 수 있다.
A 1D array: vertice들을 나타냄
A linked list (adjacency list): edge들을 나타냄
edge가 존재하는 만큼만 동적 할당을 한다.
Adjacency Matrix VS List
항상 뭐가 더 좋은건 아니고 상황마다 다르므로 적절히 선택해야한다.
Matrix
- edge가 많을 때 좋다. 0으로 낭비되는 공간이 줄어든다.
- memory requirements:
- 길찾기가 빠르다.
List
- edge가 많아지면 길어지므로 edge가 적을 때 좋다.
- memory requirements:
- 특정한 점에서 갈 수 있는 곳 빨리 찾는다. (edge가 있는 것만 갖고 있기 때문)
구현
정의
#define NULL_EDGE 0;
template<class VertexType>
class GraphType {
private:
int numVertices;
int maxVertices;
VertexType* vertices;
int** edges; // double pointer로 int pointer를 가리키는 pointer이다.
bool* marks;
public:
GraphType();
~GraphType();
GraphType(const GraphType<VertexType> &);
void operator=(const GraphType<ItemType> &);
void clear();
bool isFull() const;
bool isEmpty() const;
void addVertex(VertexType);
void addEdge(VertexType, VertexType, int);
int getVertexIndex(VertexType);
int getWeight(VertexType, VertexType);
void getAdjacents(VertexType, QueType<VertexType> &);
bool isMarked(VertexType) const;
void markVertex(VertexType);
void clearMarks();
};Constructor, Destructor
template<class VertexType>
GraphType<VertexType>::GraphType(int maxV){
numVertices = 0;
maxVertices = maxV;
vertices = new VertexType[maxVertices]; // vertices를 저장하는 1차원 배열
edges = new int* [maxVertices]; // edge를 저장하는 2차원 배열
for (int i = 0; i < maxV; i++){
edges[i] = new int[maxVertices];
}
marks = new bool[maxVertices];
}
template<class VertexType>
GraphType<VertexType>::~GraphType(){
delete[] vertices;
for (int i = 0; i < maxV; i++){
delete[] edges[i];
}
delete[] edges;
delete[] marks;
}나머지 함수들
template<class VertexType>
void GraphType<VertexType>::addVertex(VertexType vertex){
vertices[numVertices] = vertex;
for (int index = 0; index < numVertices; index++){
edges[numVertices][index] = NULL_EDGE;
edges[index][numVertices] = NULL_EDGE;
}
numVertices++;
}
template<class VertexType>
void GraphType<VertexType>::addEdge(VertexType fromVertex, VertexType toVertex, int weight){
int row = 0;
int column = 0;
row = getVertexIndex(fromVertex);
column = getVertexIndex(toVertex);
edges[row][column] = weight;
}
template<class VertexType>
int GraphType<VertexType>::getVertexIndex(VertexType vertex){
for (int i = 0; i < numVertices; i++){
if (vertices[i] == vertex) {
return i;
}
}
}
template<class VertexType>
void GraphType<VertexType>::getWeight(VertexType fromVertex, VertexType toVertex){
int row = 0;
int column = 0;
row = getVertexIndex(fromVertex);
column = getVertexIndex(toVertex);
return edges[row][column];
}Graph Searching은 DFS, BFS 두 가지 방식으로 구현할 수 있다.
Graph Searching
Depth-First Searching
Logical Level
깊이 우선 탐색방식으로 DFS라 부른다. 모든 노드를 방문하는데 노드의 끝까지 갔다가 오는 방식이다.
즉, 갈 수 있는 최대한 멀리까지 갔다 오는 방식이다.
Stack을 이용해서 구현한다.
- Pop from Stack
- Pop한 곳은 visit으로 mark
- pop한 곳과 인접한 노드 push
- 1-3 반복
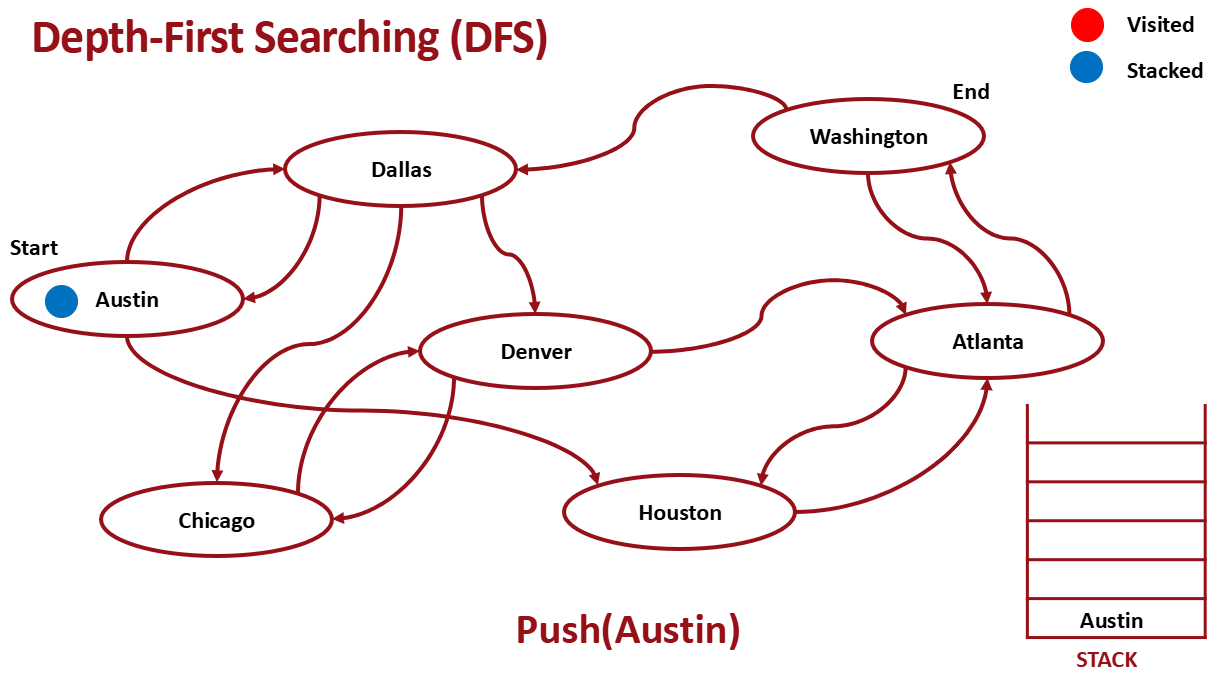
처음에 start 지점 노드를 push 해준다.
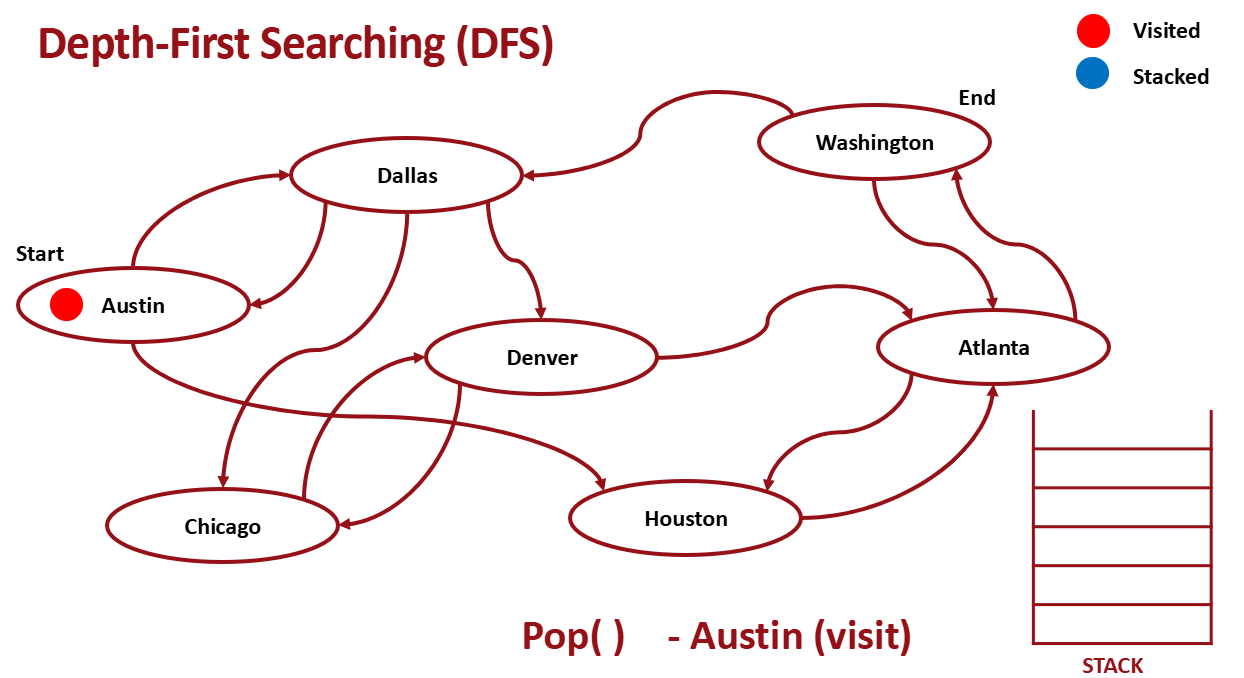
pop 한다.
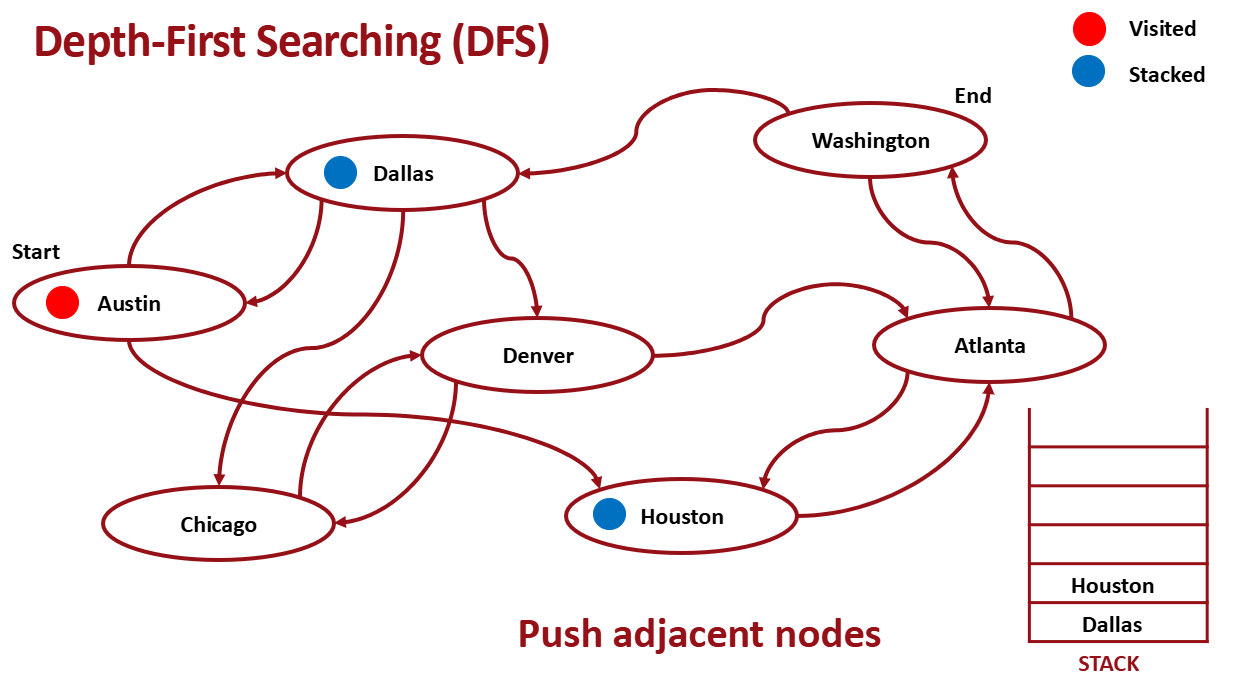
인접한 노드들을 push한다.
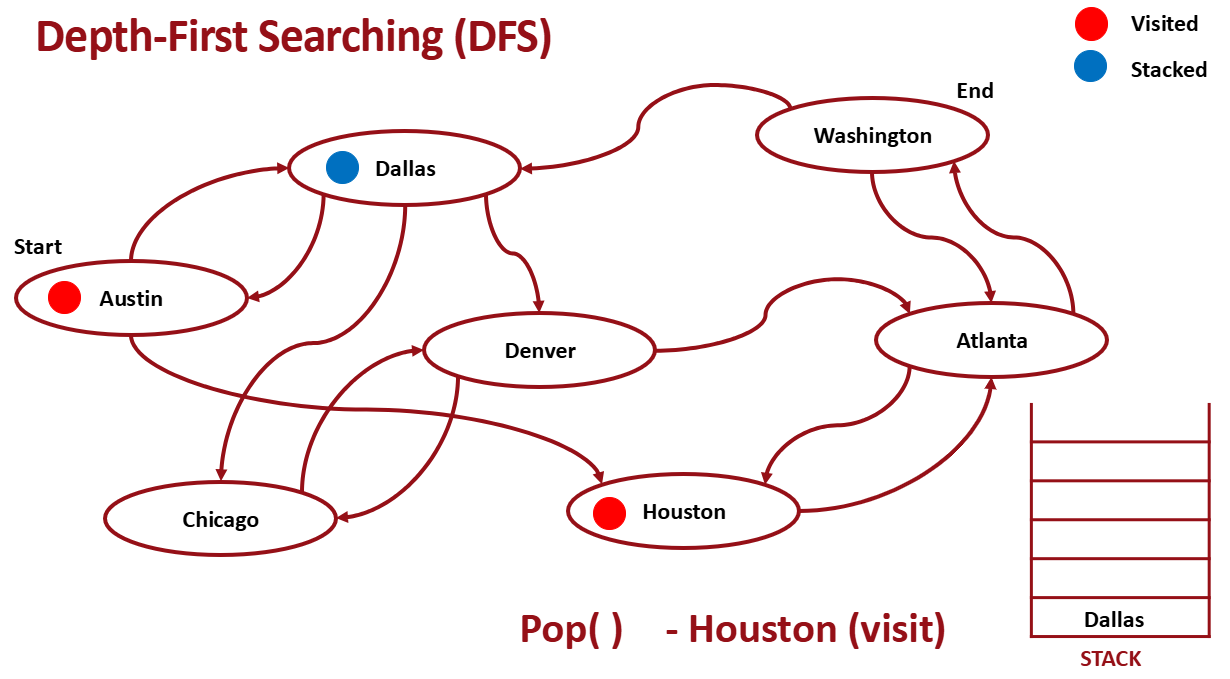
다시 pop한다.
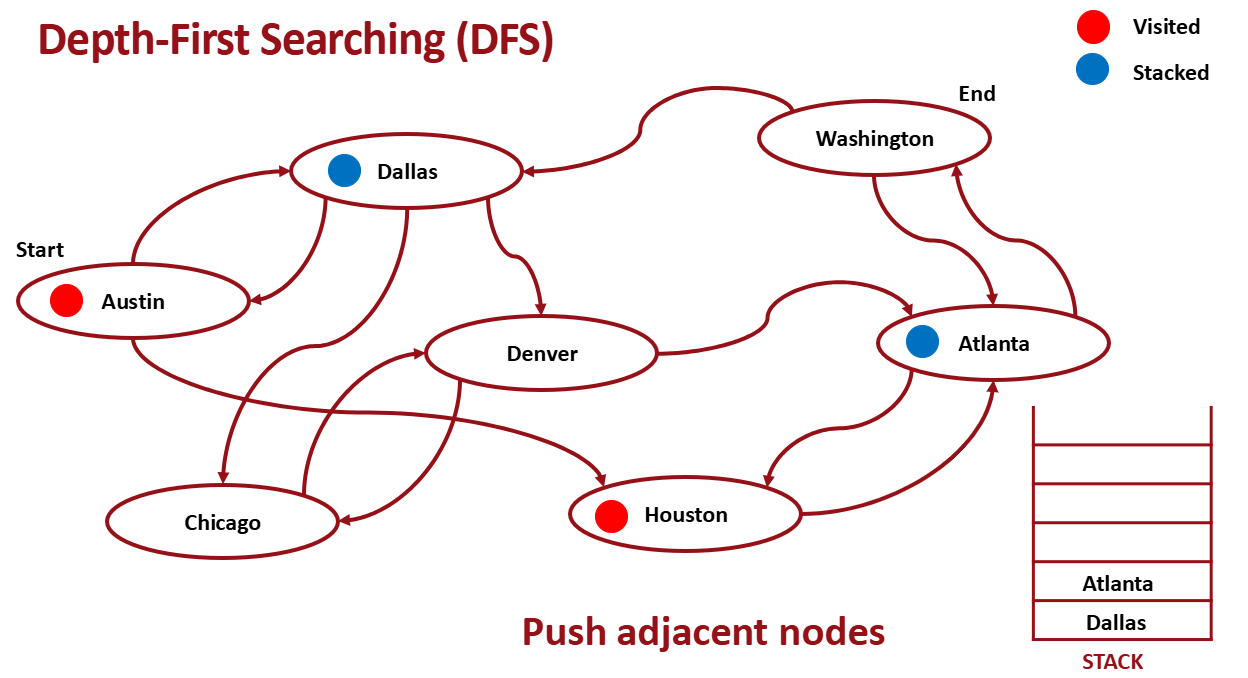
인접한 노드들을 push한다.
위 과정을 계속 반복하면 된다.
Implementation Level
template<class VertexType>
bool depthFirstSearch(GraphType<VertexType> graph, VertexType startVertex, VertexType endVertex){
StackType<VertexType> tempStack;
QueType<VertexType> adjacentsQue;
VertexType vertex, item;
graph.clearMarks();
tempStack.push(startVertex);
while (!tempStack.isEmpty()){
tempStack.pop(vertex);
if (vertex == endVertex) return true;
if (!graph.isMarked(vertex)){ // 방문하지 않았다면
graph.markVertex(vertex); // mark
graph.getAdjacents(vertex, adjacentsQue); // vertex와 인접한 노드들 찾기
while (!adjacentsQue.isEmpty()){ // 인접한 노드들에서 작업
adjacentsQue.dequeue(item);
if (!graph.isMarked(item)){
tempStack.push(item);
}
}
}
}
return false;
}
template<class VertexType>
int GraphType<VertexType>::getAdjacents(VertexType vertex, QueType<VertexType>& adjQue){
int fromIndex = getVertexIndex(vertex);
for (int toIndex = 0; toIndex < numVertices; toIndex++){
if (edges[fromIndex][toIndex] != NULL_EDGE){
adjQue.enqueue(vertices[toIndex]);
}
}
}Breadth-First Searching
Logical Level
너비우선 탐색 방식으로 BFS라 부른다. 다음 level로 가기전에 현재 level의 모든 노드를 살펴보는 방식이다.
같은 거리에 있는 갈 수 있는 모든 노드를 탐색한다.
Queue로 구현한다.
- dequeue from Queue
- dequeued한 곳은 visit으로 mark
- dequeue한 곳과 인접한 노드 enqueue
- 1-3 반복
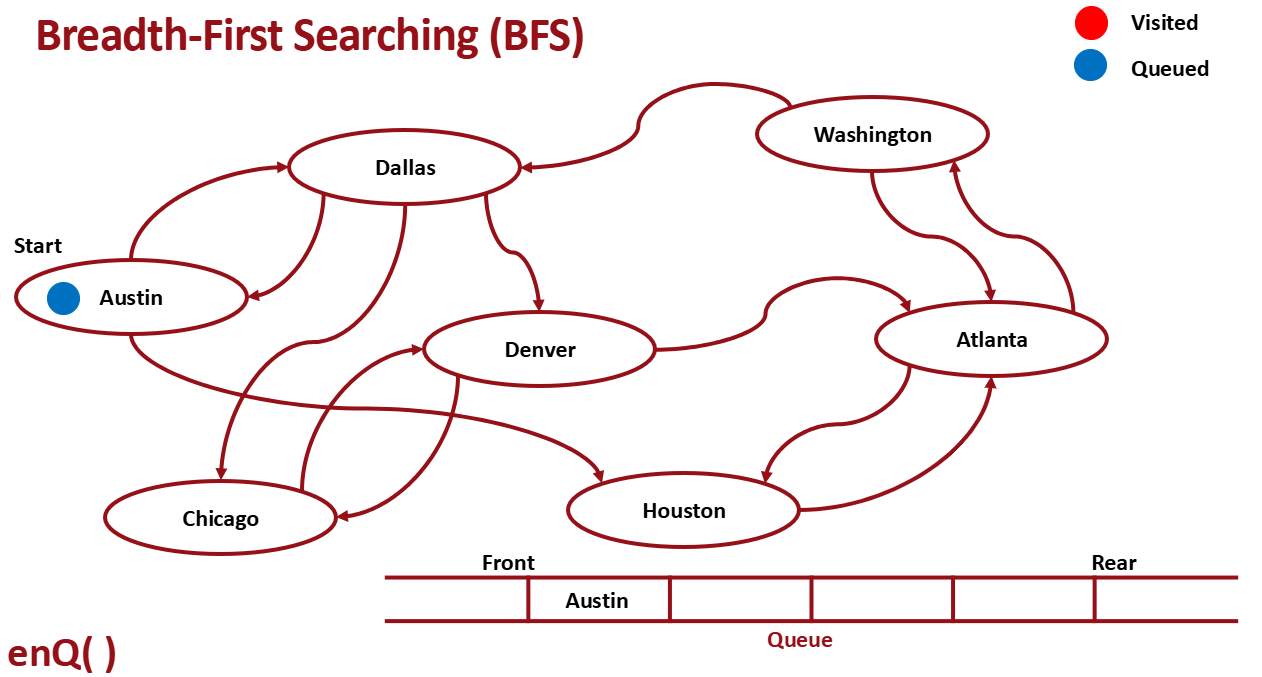
먼저 start지점 노드 enqueue
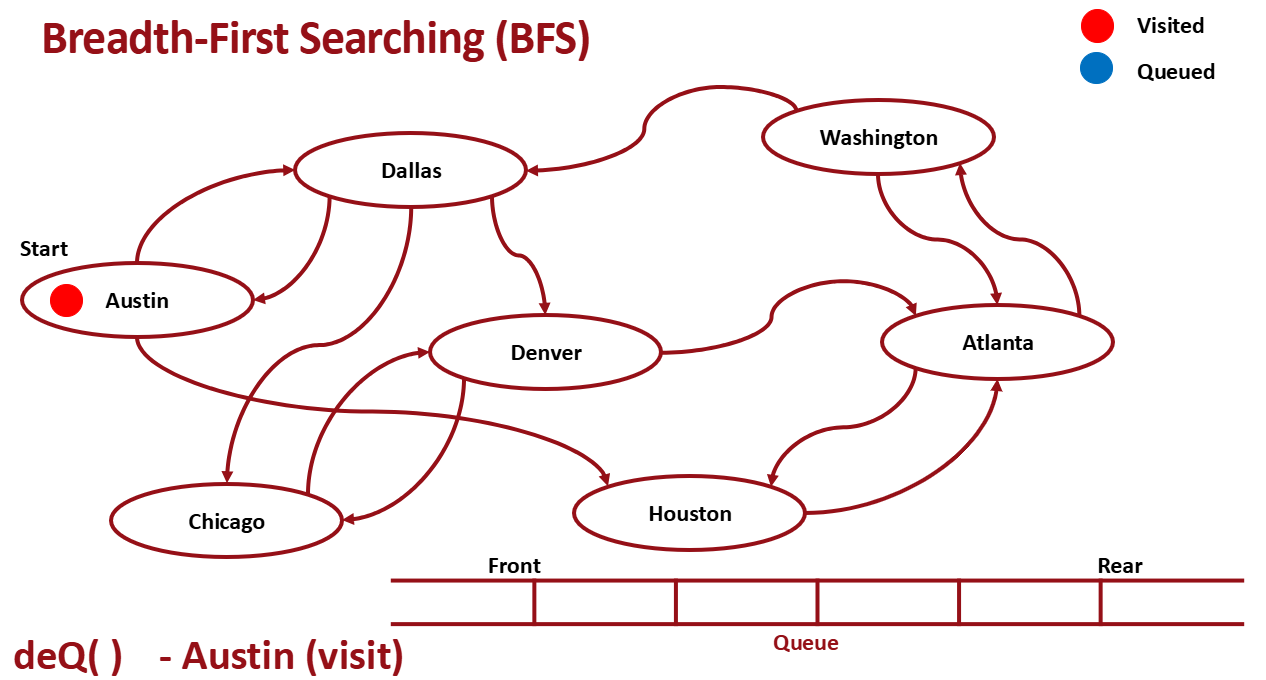
dequeue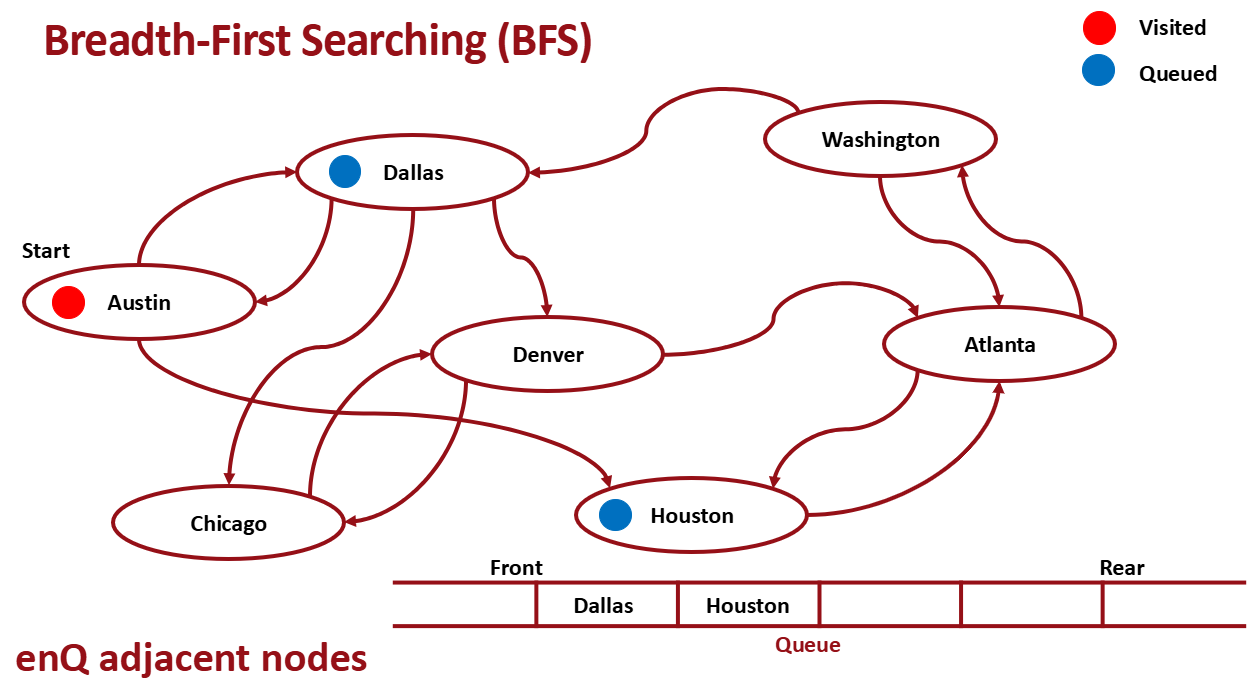
인접한 노드 enqueue
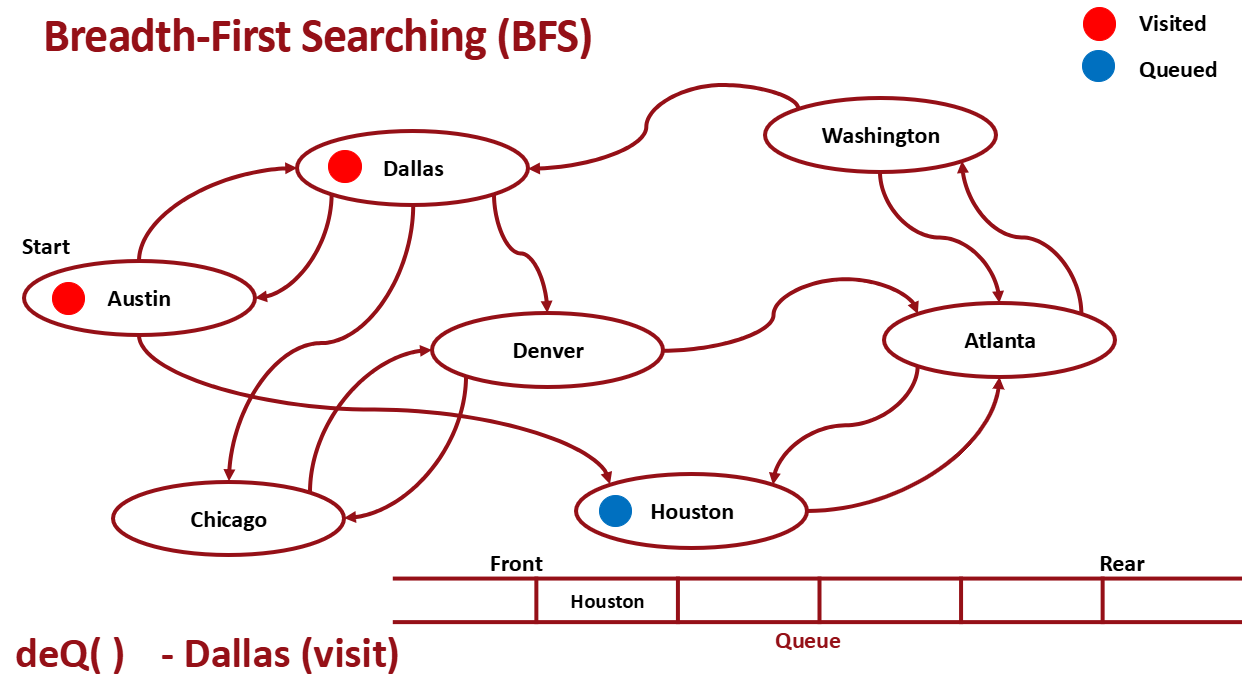
다시 dequeue
위 과정을 끝까지 반복한다.
이런식으로 진행하다보면 아래와 같이 같은 노드가 queue에 들어갈 수 있는데 이는 그냥 무시하고 enqueue하면 된다. 어차피 처리하는 과정에서 marked 되고 이후 것은 무시되기 때문이다.
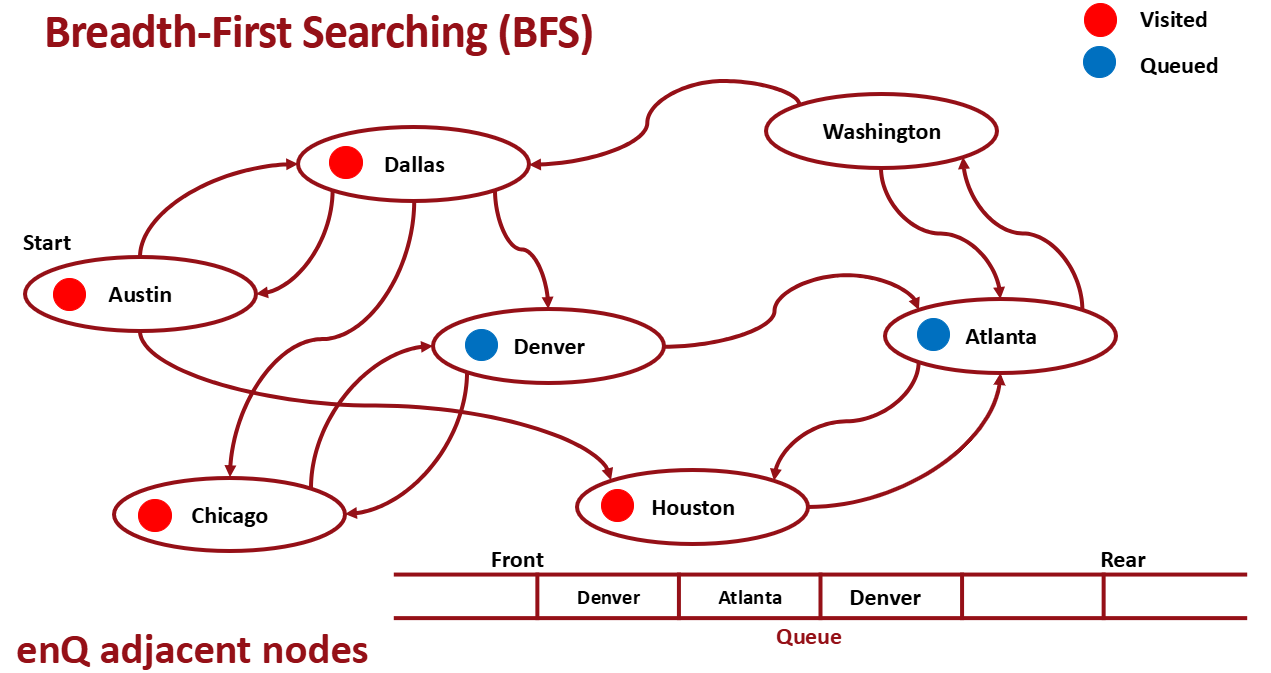
Implementation Level
template<class VertexType>
bool breadthFirstSearch(GraphType<VertexType> graph, VertexType startVertex, VertexType endVertex){
QueType<VertexType> tempQue;
QueType<VertexType> adjacentsQue;
VertexType vertex, item;
graph.clearMarks();
tempQue.enqueue(startVertex);
while (!tempQue.isEmpty()){
tempQue.dequeue(vertex);
if (vertex == endVertex) return true;
if (!graph.isMarked(vertex)){ // 방문하지 않았다면
graph.markVertex(vertex); // mark
graph.getAdjacents(vertex, adjacentsQue); // vertex와 인접한 노드들 찾기
while (!adjacentsQue.isEmpty()){ // 인접한 노드들에서 작업
adjacentsQue.dequeue(item);
if (!graph.isMarked(item)){
tempQue.enqueue(item);
}
}
}
}
return false;
}BFS VS DFS
DFS는 운에 많이 의존하는 경향이 있다.
경희대학교에서 영통역을 갈 때는 BFS를 사용하는 것이 맞다.
위치가 가깝기 때문에 갈 수 있는 모든 경로를 찾아서 최단의 경로로 가는 것이 좋기 때문이다. 만약 DFS로 한다면 학교에서 대전역 갔다가 영통역 갈 수도 있게 된다.
경희대에서 부산역을 갈 때는 DFS를 사용하는 것이 맞다.
만약에 BFS를 사용하면 경로 찾다 시간을 다 써버릴 수 있기 때문이다.
Shorted Path Problem
개요
Source vertex에서 Destination vertex로 가는 path는 여러가지 존재하는데 이때 total weight가 가장 낮은 path를 찾아야 한다.
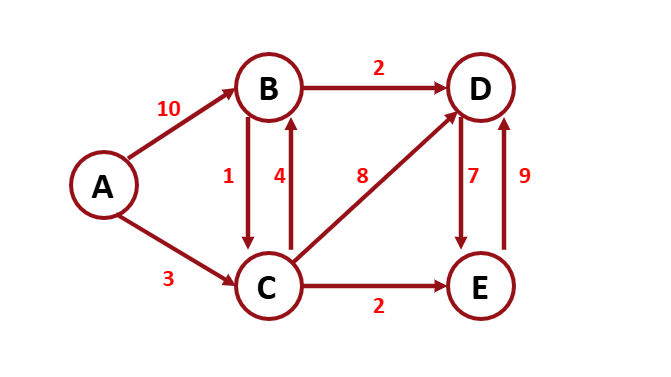
이때 Dijkstra 알고리즘을 사용한다.
Dijkstra Alrorithm

위의 문제를 이 알고리즘으로 해결해보자.
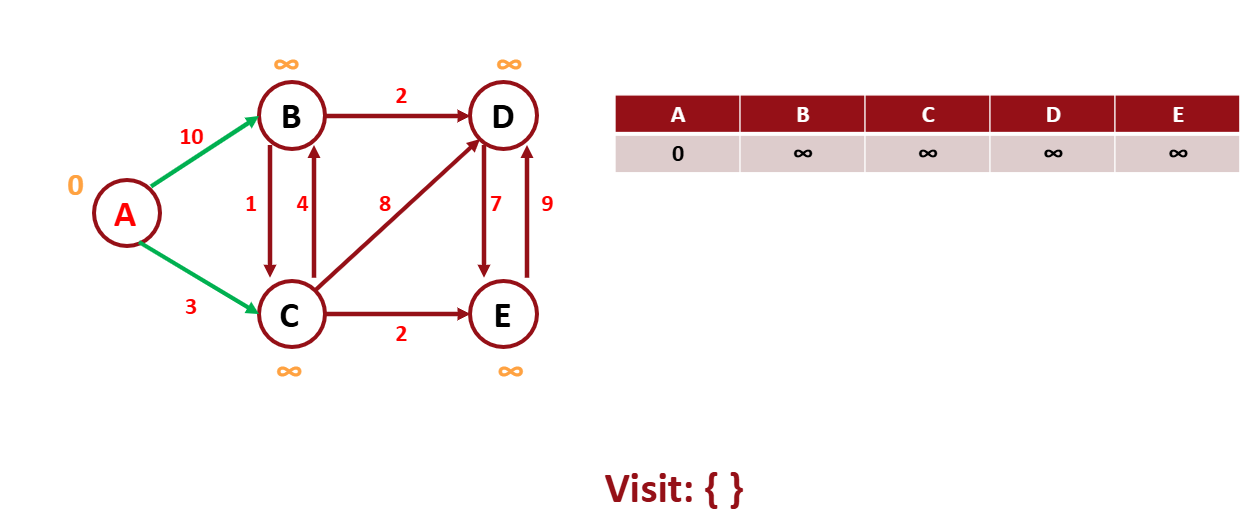
먼저 시작점은 0으로 표시하고 나머지 노드는 무한대 표시를 사용한다.
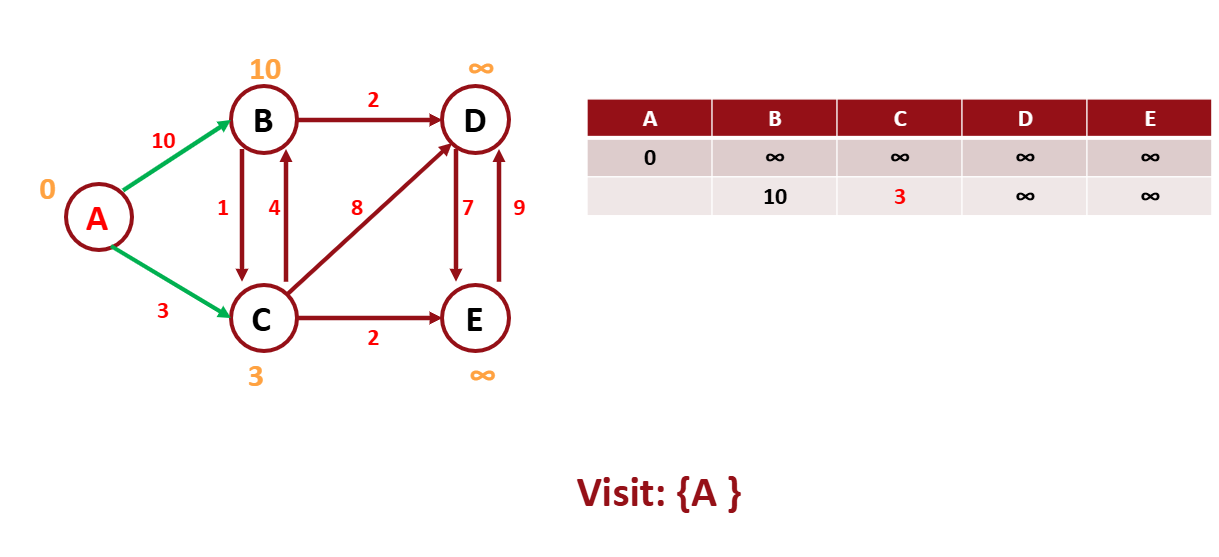
A에서 갈 수 있는 노드들의 weight를 작성한다.
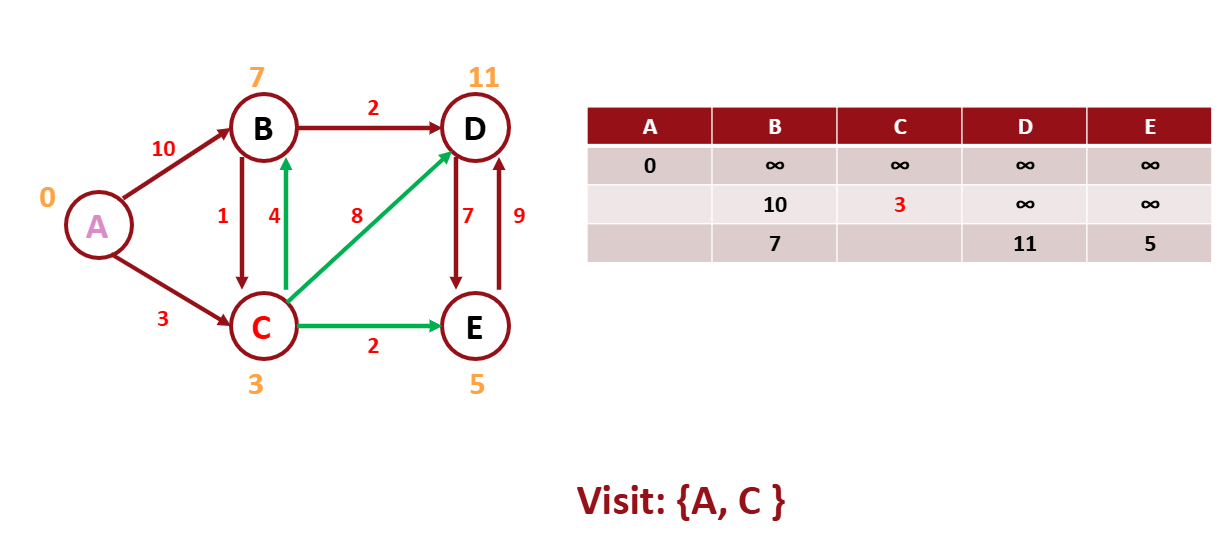
A에서 갈 수 있는 노드 중 C의 weight가 가장 적으므로
C를 방문하고 C에서 방문 할 수 있는 노드들의 weight를 작성한다.
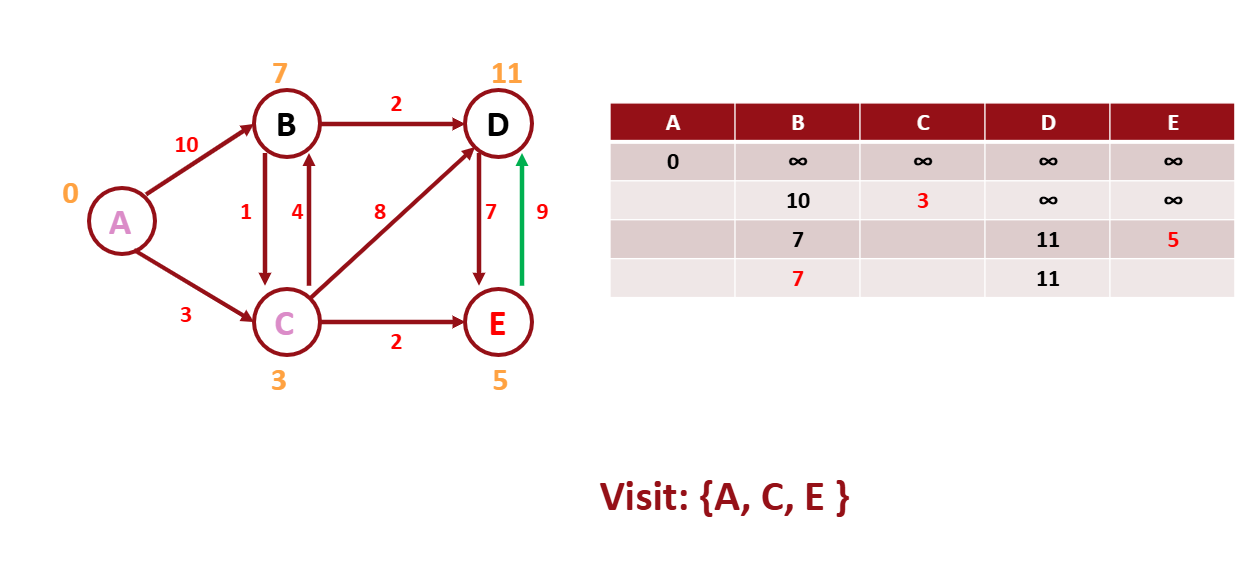
E를 방문해본다.
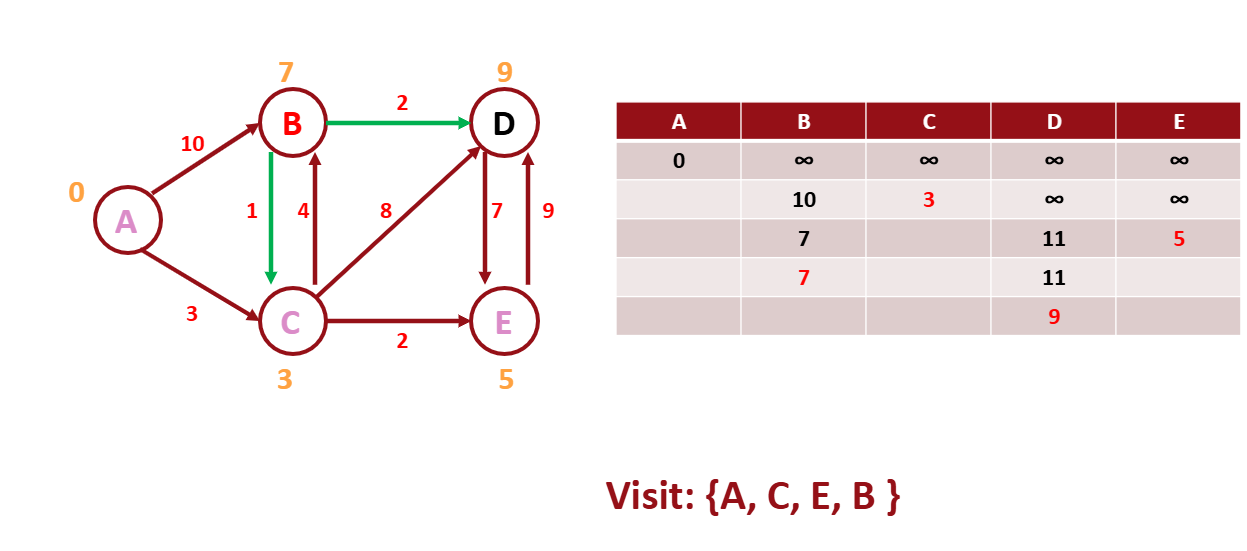
그 다음 B를 방문해본다.
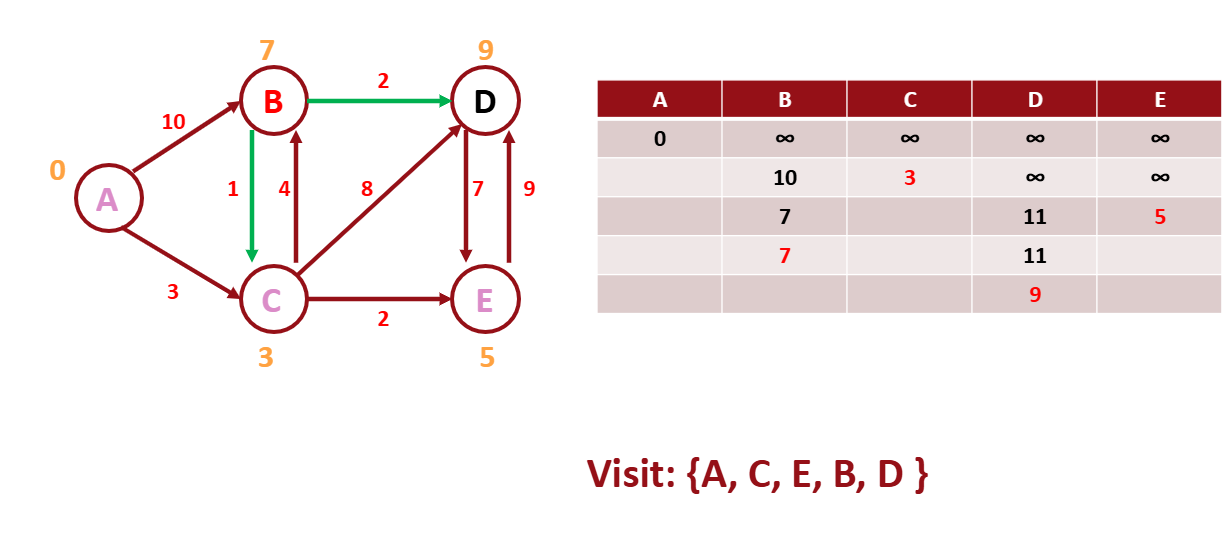
그리고 마지막 노드를 방문한다.
BFS는 weigth가 없거나 모든 weight가 같을 때 짧은 graph 문제에서 푸는 것이 좋다.
