개요
알고리즘을 공부하기 전에 Sort와 search 알고리즘을 찍먹해보자.
Sort
array에서 item들을 오름차순 혹은 내림차순으로 정렬하는 알고리즘 6가지를 알아보자.
Selection Sort
Logical Level
우선 배열의 영역을 두 영역으로 나눈다. already sorted, not yet sorted
unsorted 영역에서 최솟값을 찾고 unsorted 영역의 첫번째 index와 swap 해주는 방식이다.
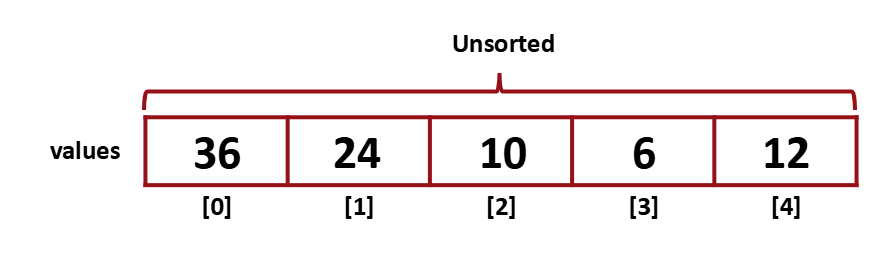
위 배열에서 최솟값을 찾는다 (6)
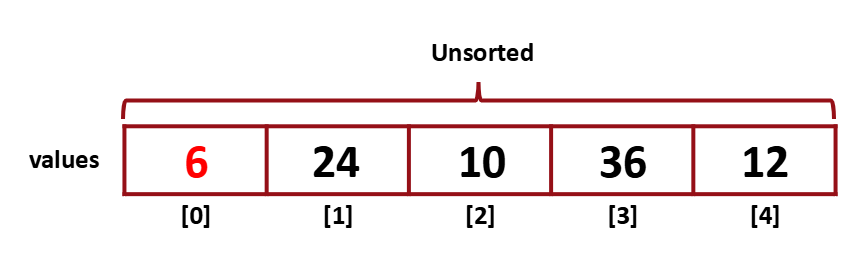
6을 첫 번째 index item과 swap 한다. (위치를 바꿔줌)
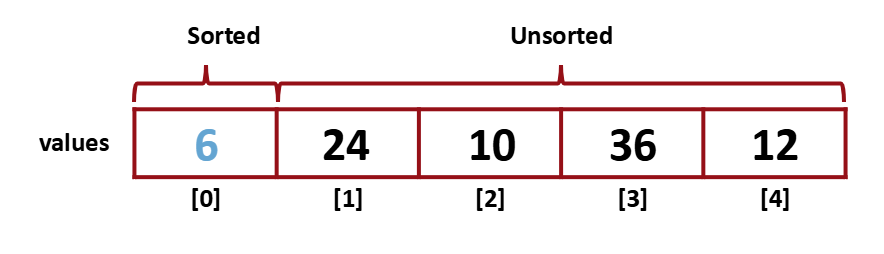
그 다음 Sorted 영역으로 바꿔준다.
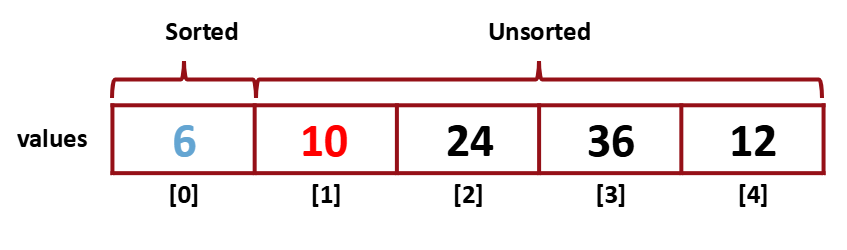
다시 최솟값을 찾고 unsorted의 첫 번째 index와 swap
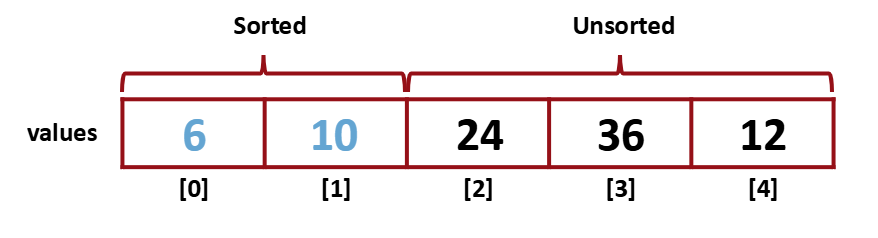
10도 Sorted에 포함시켜준다. 이러한 과정을 unsorted 영역의 item이 한 개만 남을 때까지 반복해준다.
Implementation Level
template<class ItemType>
void selectionSort(ItemType [] values, int numValues){
int endIndex = numValues - 1;
for (int current = 0; current < endIndex; current++){
swap(values[current], values[getMinItem(values, current, endIndex)];
}
}
template<class ItemType>
int getMinItem(ItemType [] values, int startIndex, int endIndex){
int minIndex = startIndex;
for (int index = start + 1; index <= endIndex; index++){
if(values[index] < values[minIndex]){
minIndex = index;
}
}
return minIndex;
}시간복잡도
처음 최솟값을 찾는 시간복잡도는 N - 1
두 번째는 N - 2
다음은 N - 3
.
.
마지막 1
1 + 2 + ... + N - 2 + N - 1 =
즉, 시간복잡도는
Bubble Sort
Logical Level
마찬가지로 Sorted 영역과 Unsorted 영역으로 array를 나눈다.
Unsorted 영역의 마지막 Index부터 바로 왼쪽의 아이템과 비교를 하며 Unsorted 영역의 첫 번째 Index까지 Swap을 해준다.
이러한 과정이 최솟값이 'bubble up'되는 것 같다하여 bubble sort라 한다.
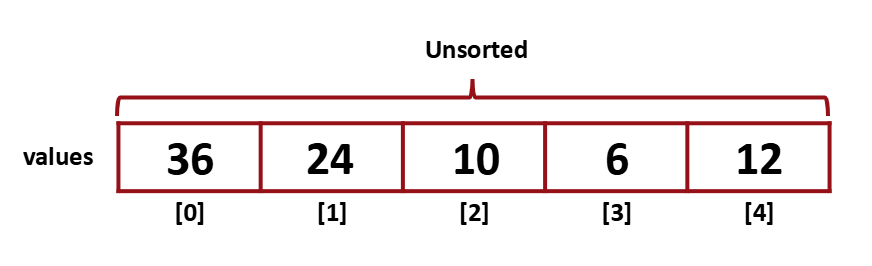
먼저 [3]과 [4]를 비교한다.
[4]가 더 크므로 swap하지 않는다.
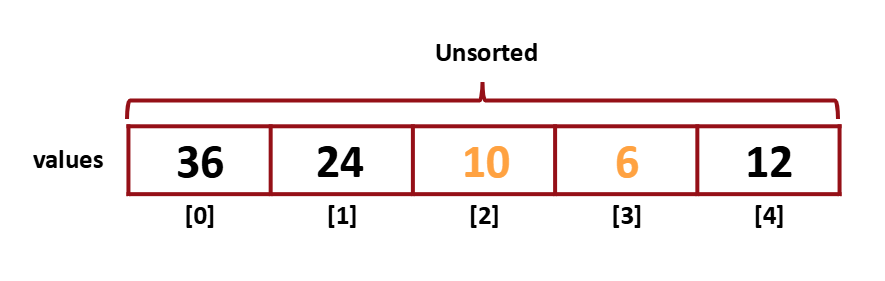
그 다음 [2]와 [3]을 비교한다. [3]이 더 작으므로 swap을 해준다.
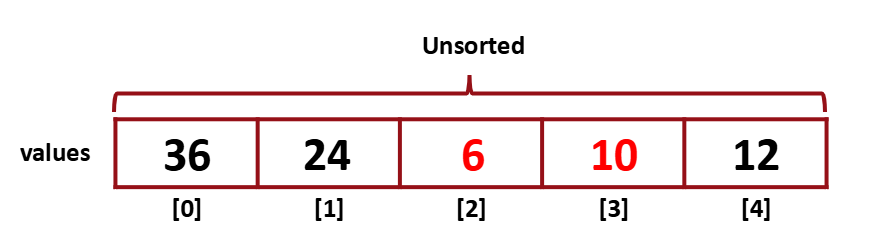
swap
그 다음 [1]보다 [2]가 더 작으므로 이도 swap을 해준다.
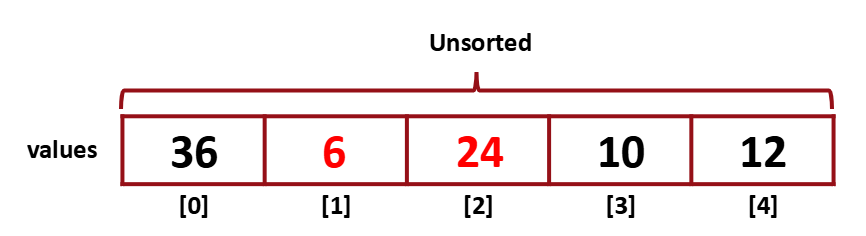
이런식으로 [0]과 [1]까지 비교하고 나면 아래와 같은 형태가 된다.
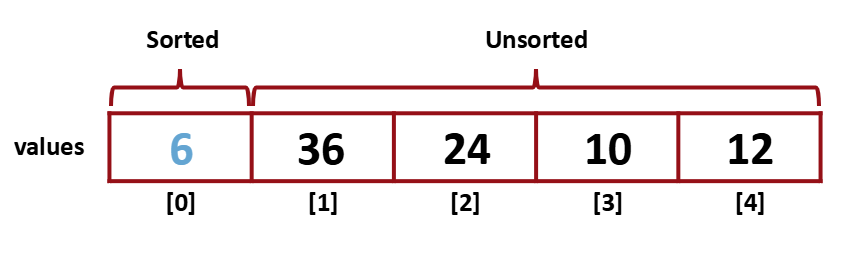
마지막까지 비교를 끝냈다면 6을 Sorted 영역에 넣어준다.
이런식으로 계속 반복하면 된다.
Implementation Level
template<class ItemType>
void bubbleSort(ItemType [] values, int numValues){
int current = 0;
while (current < numValuse - 1){
bubbleUp(values, current, numValues - 1);
current++;
}
}
template<class ItemType>
void bubbleUp(ItemType [] values, int startIndex, int endIndex){
for (int index = endIndex; index > startIndex; index--){
if(values[index] < values[index - 1]){
swap(values[index], values[index - 1]);
}
}
}시간복잡도
처음 bubble up이 일어나는데 N - 1
그 다음 N - 2
.
.
마지막 bubble up 1
이 또한 시간복잡도는 이다.
또한 의미없는 swap이 많을 수 있는 방식이다.
Insertion Sort
Logical Level
이것도 array를 Sorted 영역과 Unsorted 영역으로 나눈다.
하나씩 Unsorted array의 item을 random하게 key로 설정한 다음에 이 Key값을 인접한 요소와 비교하며 Sorted 영역의 적절한 위치에 넣어주는 방식이다.
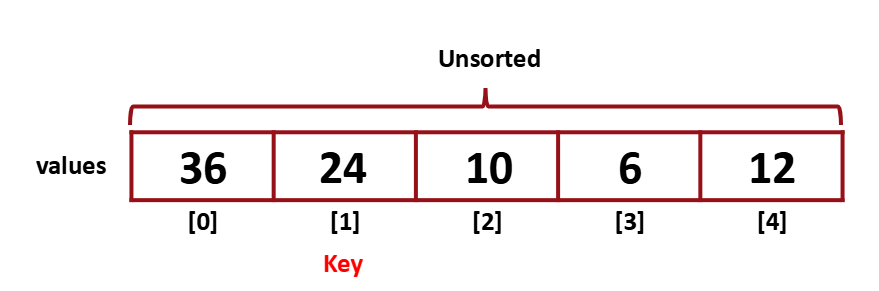
먼저 random하게 key를 선택한다. 이 경우 Unsorted의 두 번째 값을 key로 선택했다.
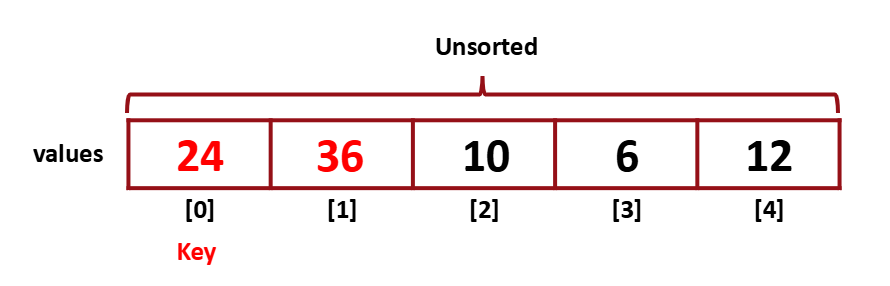
[1]이 더 작았었기 때문에 swap 해준다.
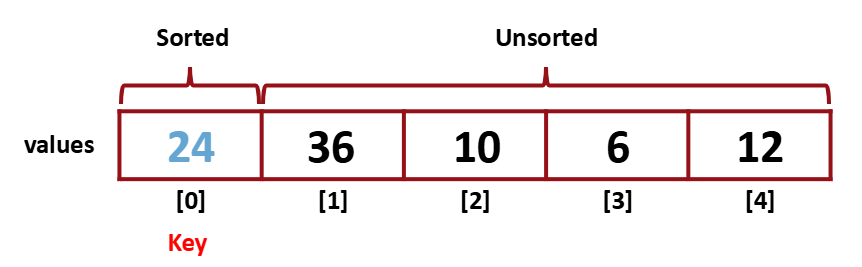
그 다음 Sorted 영역으로 바꾸어 준다.
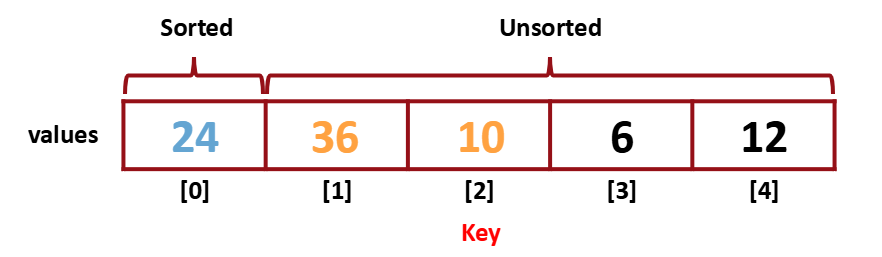
또 Unsorted의 두 번째 값을 key로 선택하여 비교해준다.
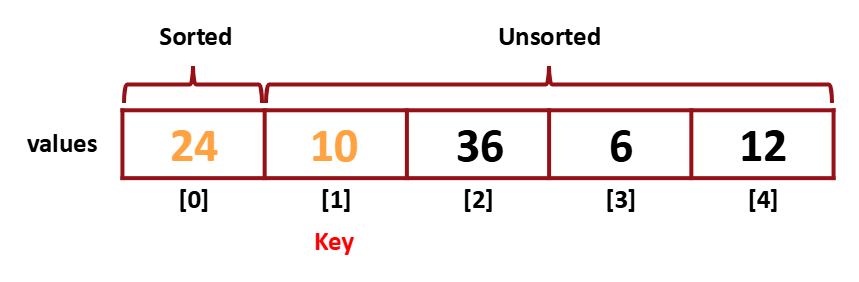
그리고 [0]과 [1]을 또 비교한다.
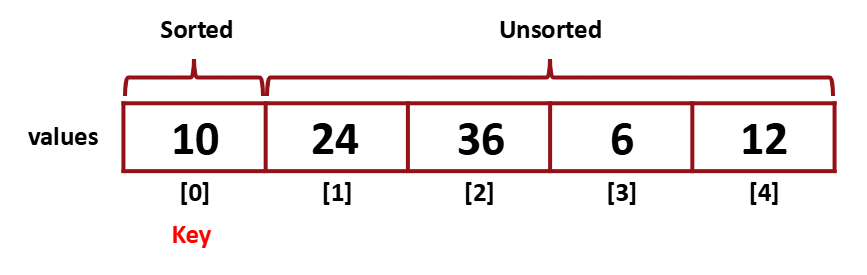
[1]이 더 작았었기 때문에 그 결과 위처럼 구성이 바뀌게 된다.
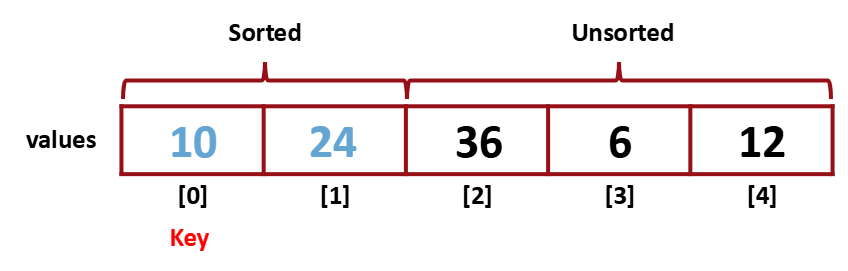
10이라는 값이 sorted 영역의 적절한 위치를 찾아갔다.
이런식으로 끝까지 반복해주면 된다.
Implementation Level
template<class ItemType>
void insertionSort(ItemType [] values, int numValues){
for (int count = 0; count < numValues; count++){
insertItem(values, o , count);
}
}
template<class ItemType>
void insertItem(ItemType [] values, int startIndex, int endIndex){
int current = endIndex;
while (current > startIndex){
if (values[index] < values[index - 1]{
swap(values[index], values[index - 1]);
current--;
}
else break;
}
}시간복잡도
이것도 이다.
의미없는 비교는 전보다 훨씬 적다.
Heap Sort
Logical Level
Make Heap
Heap은 complete binary tree의 shape를 갖고 parent가 child의 값보다 큰 order property를 갖고 있는 자료구조이다.
이러한 Heap을 이용하여 Sort를 해보자.
먼저 Unsorted array를 Heap으로 바꿔주는 과정이 필요하다.
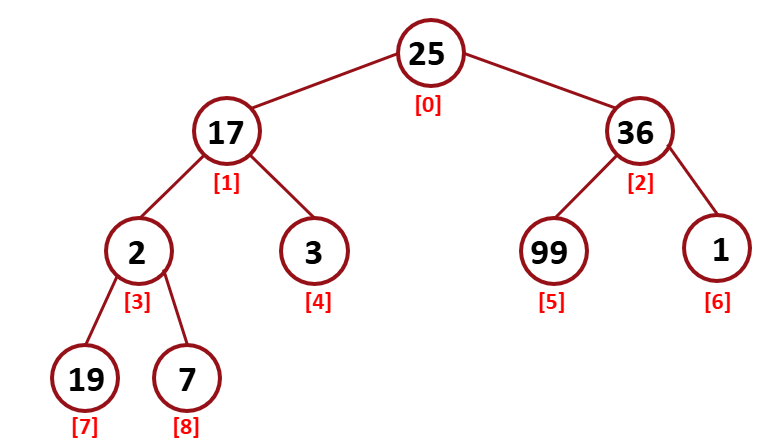
현재 위 tree는 heap이 아니다 이를 heap로 바꿔보자.
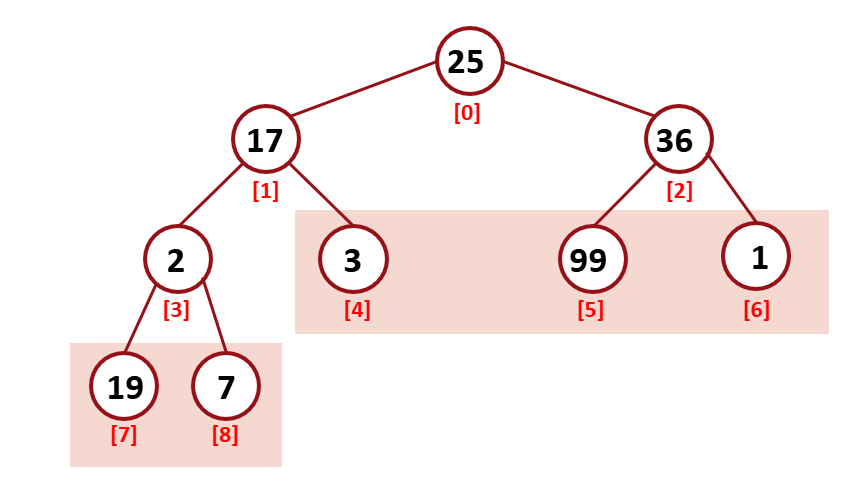
leaf 노드는 이미 heap이다. leaf 노드를 제외한 노드에서 reheap 과정을 거치면 될 것같다.
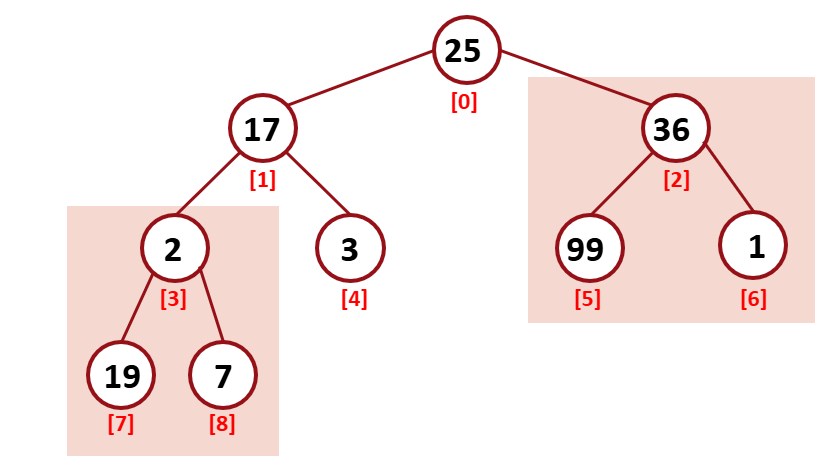
각각의 subtree에서 reHeapDown을 거친다.
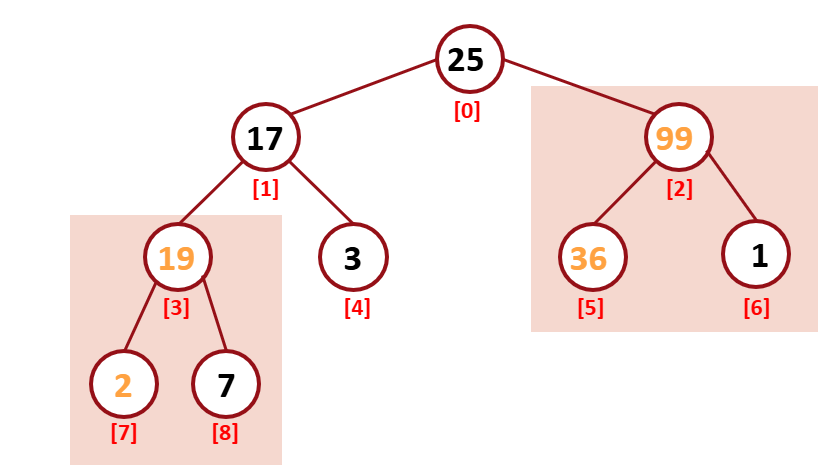
그 결과 위처럼 구성되고
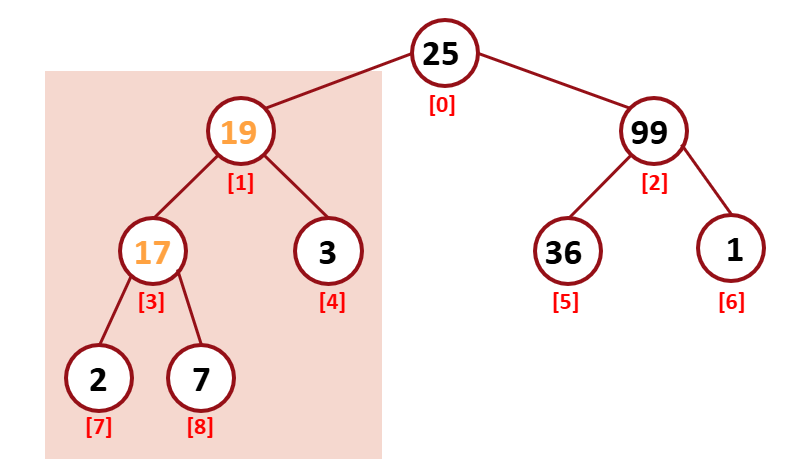
다시 reHeapDown을 거치면 위처럼 구성된다.
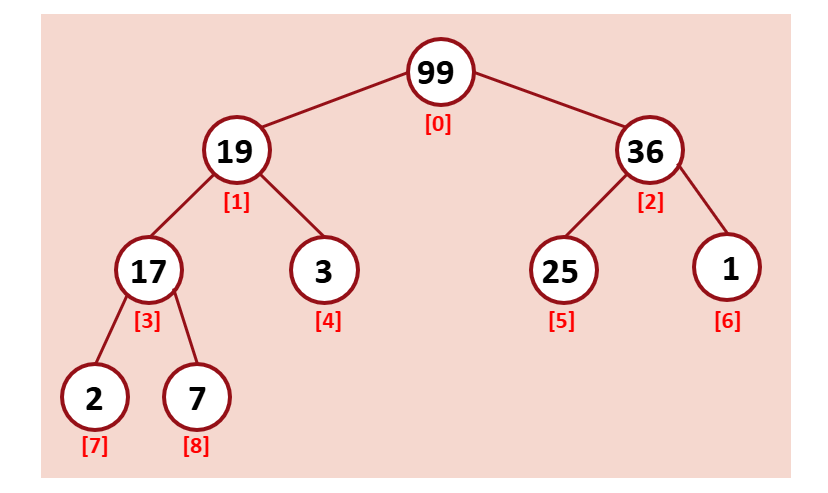
최종적으로 reHeapDown을 해주면 위처럼 Heap이 만들어진다.
총 몇번의 연산을 한걸까?
전체 노드에서 leaf 노드를 뺀 만큼 reHeapDown이 일어났다. 여기서 절반 정도가 leaf 노드이니 만큼 reHeapDown이 일어났다고 보면 된다.
reHeapDown은 tree의 높이 h만큼 일어나고 h = 이므로 전체 연산 수는 라 볼 수 있다.
즉, Heap을 만드는 시간복잡도는 이다.
Sort
이제 heap에서 sort를 해보자.
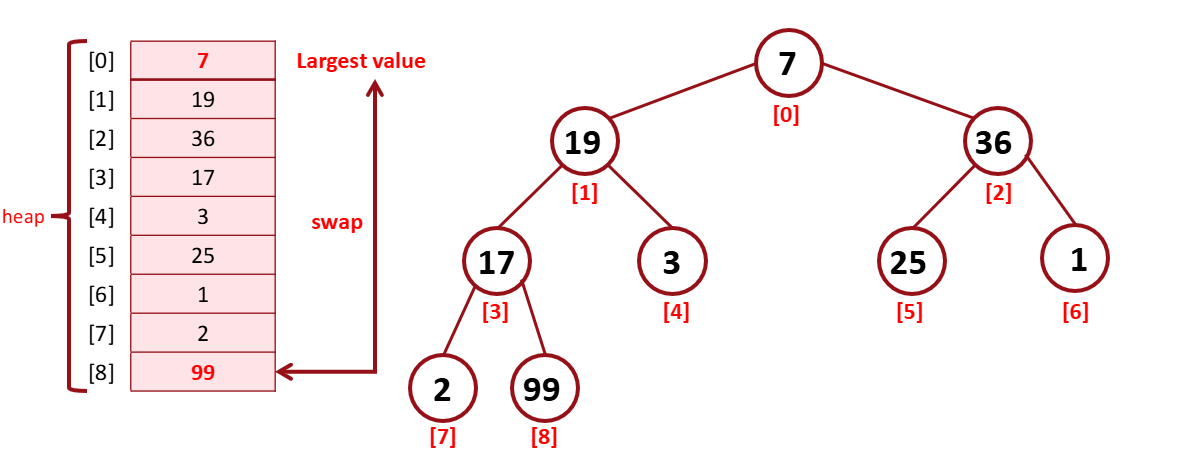
먼저 heap에서 최댓값을 array의 마지막 index로 옮겨준다.
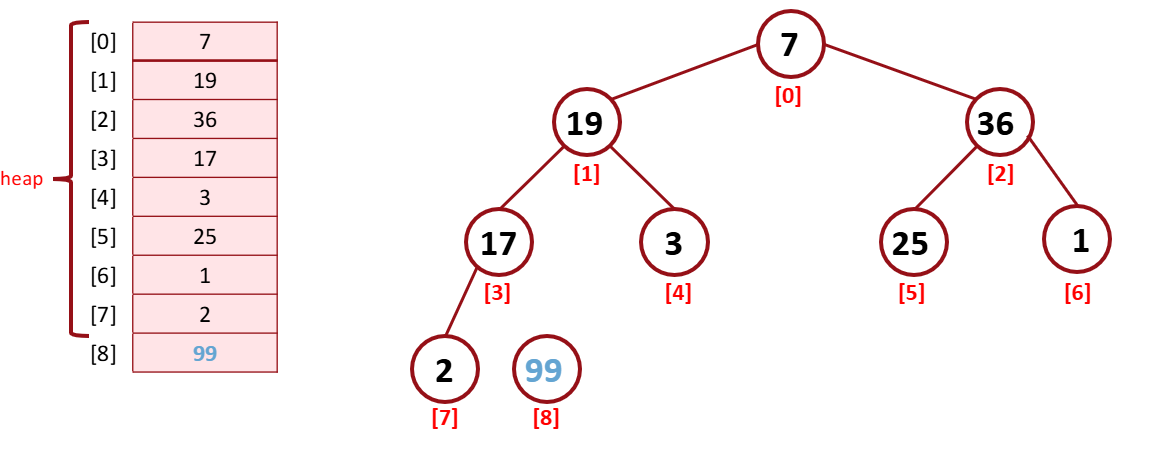
그 다음 이를 heap에서 제외시키고 다시 reHeapDown을 거쳐 36을 root로 만들어준다.
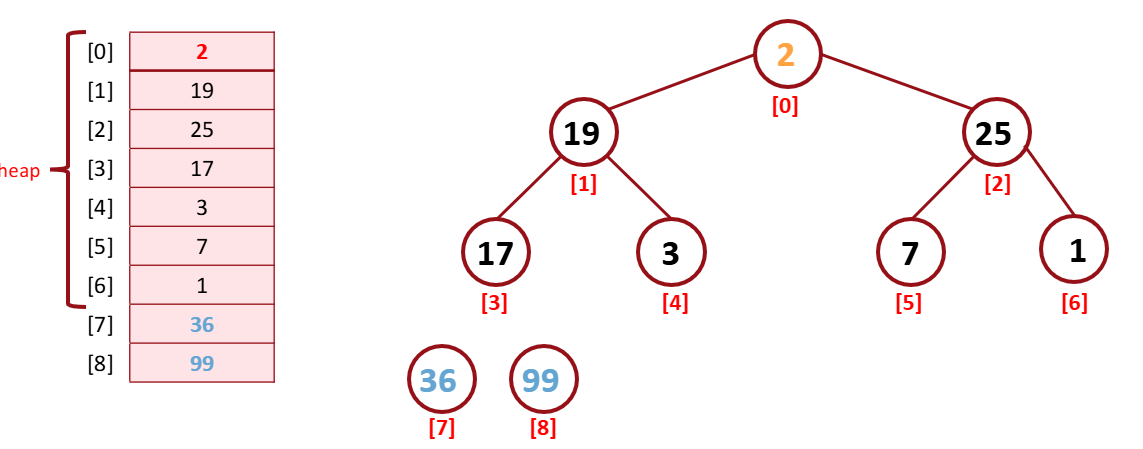
다시 최댓값을 array(heap 영역)의 마지막으로 옮겨준 뒤 heap에서 제외시킨다.
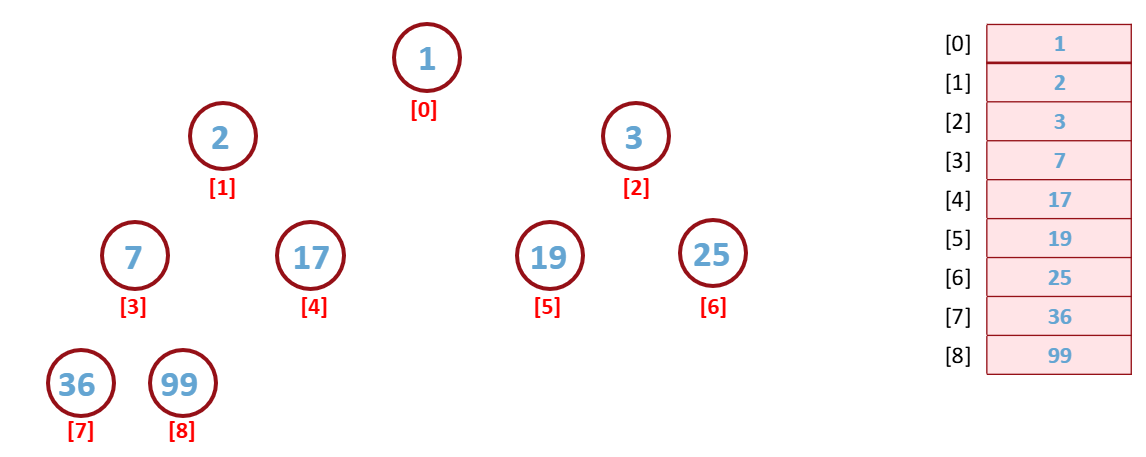
이러한 과정을 계속 반복하면 위와 같은 형태로 정렬된다.
총 N번 반복하기 때문에 시간복잡도는 이 된다.
Implementation Level
template<class ItemType>
void heapSort(ItemType [] values, int numValues){
int index = 0;
for (index = numValues / 2 - 1; index >= 0; index--){ // make Heap, numValues / 2 - 1하면 index 딱 맞음
reHeapDown(values, index, numValues - 1);
}
for (index = numValues - 1; index >= 1; index--){ /// Sort
swap(values[0], values[index]);
reHeapDown(values, 0 ,index - 1);
}
}시간복잡도
make heap과 sort 모두 이었으므로 둘을 더하면 시간복잡도는 이 된다.
Quick Sort
Logical Level
splitVal이라는 것을 array에서 random으로 선택하고 이 값을 기준으로 큰 것은 전부 오른쪽 작은 것은 전부 왼쪽으로 배치한다.
다시 왼쪽과 오른쪽에서 splitVal을 random으로 선택하고 정렬한다.
binary search와 비슷한 느낌이다.
이것을 끝까지 반복해준다.

splitVal random하게 선택

왼쪽 오른쪽 정렬

왼쪽, 오른쪽에서 splitVal 선택

각각의 왼쪽 오른쪽 정렬
이를 끝까지 반복한다.
Implementation Level
template<class ItemType>
void quickSort(ItemType [] values, int firstIndex, int lastIndex){
if (firstIndex < lastIndex){
int splitPoint = // 아무거나 random으로 선택
split(values, firstIndex, lastIndex, splitPoint);
quickSort(values, firstIndex, splitPoint - 1);
quickSort(values, splitPoint + 1, lastIndex);
}
}시간복잡도
처음 splitVal에서 연산 횟수는 N이다.
그 다음은 각각의 sub array에서 정도 될 것이다. -> 합치면 N
그 다음은 정도 될 것이고 합치면 또 N이 될 것이다.
만약 splitVal을 잘 설정하여 절반 정도로 나뉘어졌다면 의 split이 발생하고 시간복잡도는 이 될 것이다.
하지만 잘 나뉘어지지 않았다면 시간복잡도는 이 될 것이다.
Merge Sort
Logical Level
array를 정렬하기 편할때까지 계속 반으로 나눈다.
정렬하기 편할때까지 나눴으면 이들을 정렬하고 합치고 다시 정렬하고 합치고 다시 정렬하고.. 완전히 합쳐질때까지 이 과정을 반복한다.
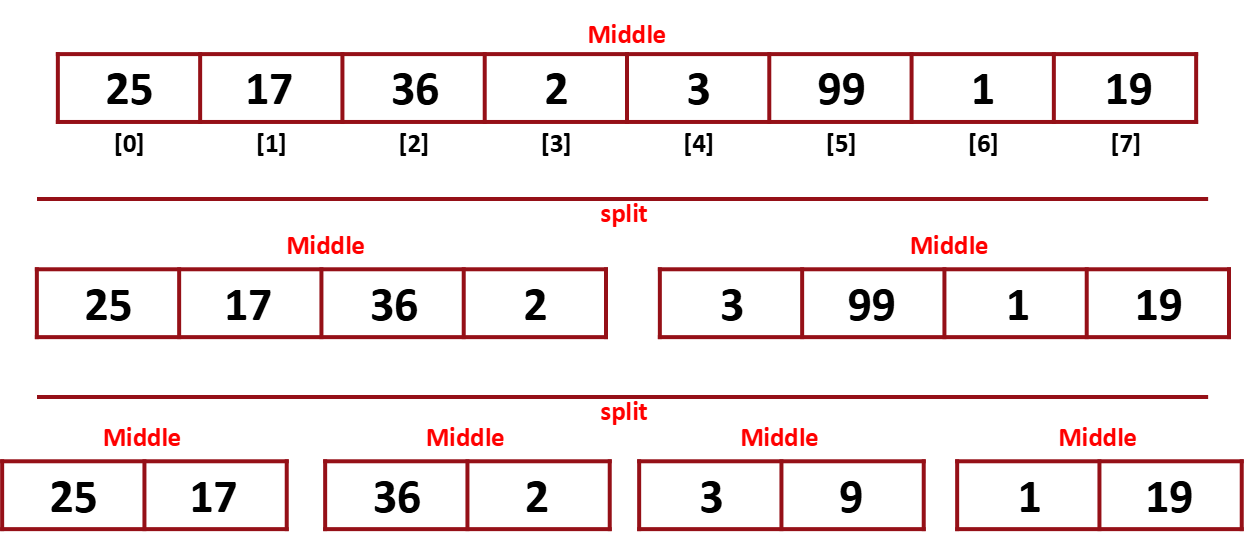
나누고
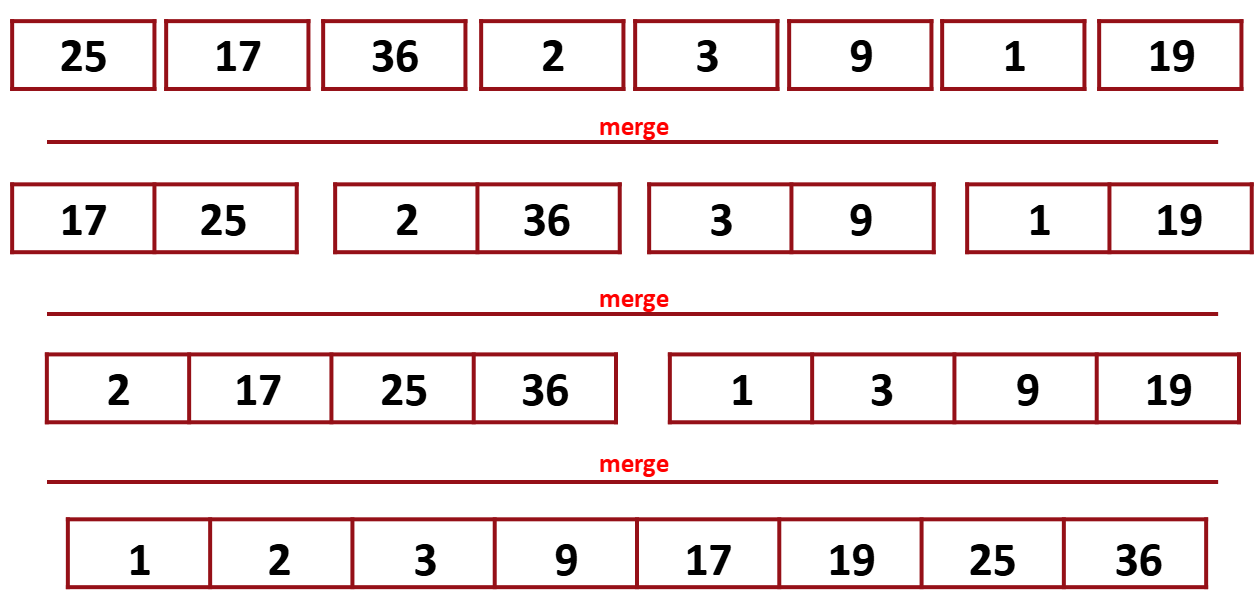
정렬하면서 합친다.
Implementation Level
template<class ItemType>
void mergeSort(ItemType [] values, int firstIndex, int lastIndex){
if (firstIndex < lastIndex){
int middle = (firstIndex + lastIndex) / 2;
mergeSort(values, firstIndex, middle);
mergeSort(values, middle + 1, lastIndex);
merge(values, firstIndex, middle, middle + 1, lastIndex);
}
}시간복잡도
반반씩 나누기 때문에 split의 시간복잡도는 이다.
merge 과정에선 각각 N번 이하의 비교로 합칠 수 있기 때문에 전체 시간복잡도는 이다.
시간복잡도 비교
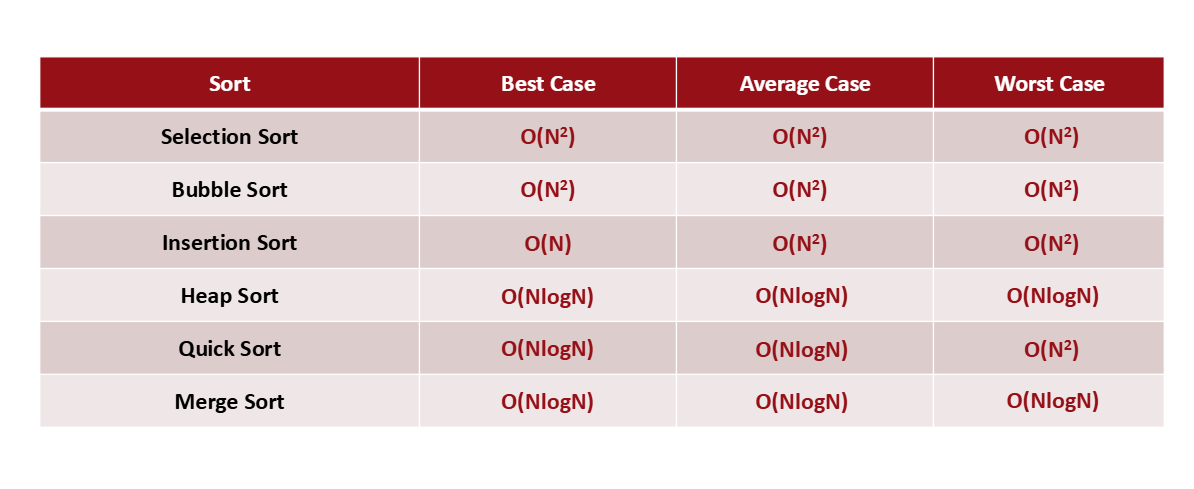
Searching
개요
Linear Searching
Searching하면 먼저 우리가 생각할 수 있는 것은 linear searching 방법일 것이다. 말 그대로 첫 번째 index부터 item을 찾을 때까지 linear하게 찾는 방식이다.
High Probability Ordering
linear search에서 발전된 방식인데 linear search를 하면 맨 앞에서부터 item을 찾으니까 자주 찾아야하는 값들을 앞에 두는 방식이다.
Binary Search
list가 sorted 되어있다면 binary search를 이용할 수 있다.
Hashing
개념
Hash Function이라는 것을 이용하여 의 시간복잡도로 item을 search하는 것이 목표이다.
다음의 예를 살펴보자.
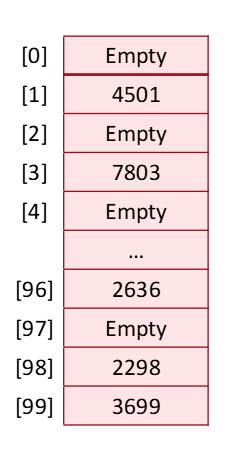
위와 같이 네 자리수를 저장하는 list가 있다고 가정하자.
Hash 함수는 아래와 같이 정의한다.
Hash(key) = partNum % 100
즉, 각 요소를 100으로 나눈 나머지 값에 따라서 list에 요소를 배치하는 것이다.
(추가로 그림에 오류가 있는데 96번 index의 값은 2696이다.)
4501은 100으로 나눈 나머지가 1이기 때문에 1번 index에 넣어준 것이고, 7803은 3이기 때문에 3번 index에 넣어준 것이다.
여기에서 5502를 넣어준다하면 어디에 들어갈까?

나머지가 2이므로 2번에 들어갈 것이다.
Collision
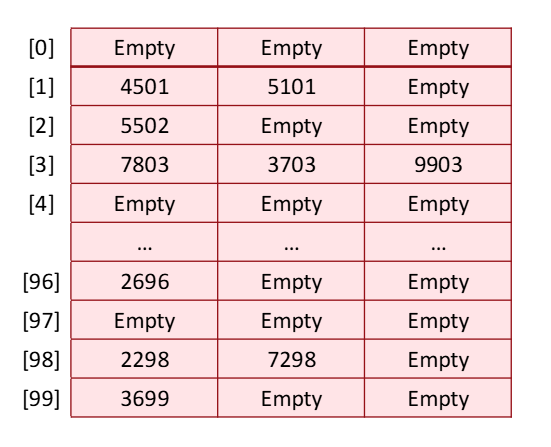
이때 만약 6702를 추가로 넣어야하면 어떨까? COLLISION이 발생한다.
두 개 이상의 key가 같은 hash location에 들어가려하면 collision이 발생하게 되는것이다.
이때 한 가지 사용할 수 있는 방법이 linear probling이다.
이는 rehash function을 이용한다. (HashValue + 1)%100
비어있는 공간을 찾을 때까지 이를 계속 반복해준다.
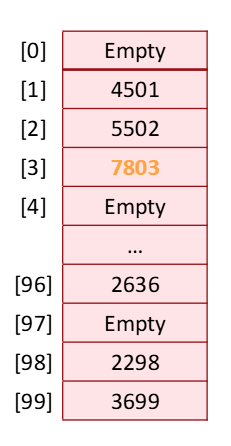
empty가 아니다.

비어있는 공간을 찾았고 매핑을 해주었다.
이때 만약 아래와 같은 상황이 오면 어떻게 될까?
- 5502 delete
- 6702 search

위와 같이 2번 index가 empty가 되어 6702를 찾지 못할 것이다. 그러므로 Empty라는 표현 대신 Deleted를 써준다.

위 방법 말고도 Bucket 방법과 Chain 방법이 존재한다.
Bucket 방법은 matrix를 만들어주는 것이다.
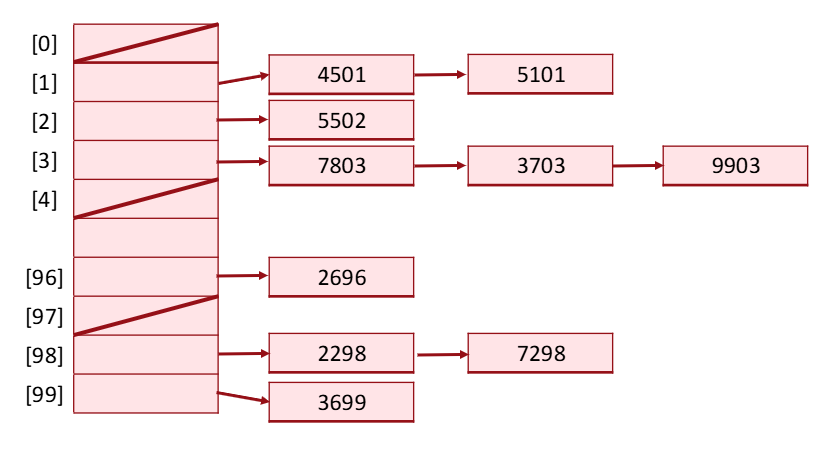
Chain 방법은 linked list를 만들어주는 것이다.
결론
셋 중에 어떤 방식이 좋을까? 결론부터 말하자면 셋다 안좋다.
애초에 Hash 함수를 잘 만들어서 collision이 가급적 발생하지 않도록하는 것이 중요하다.
Collision을 최소화하기 위한 두 가지 방법
1. Increase the range of the hash function ( hash 함수의 output 값의 range를 늘리는 것이다.)
- Distribute elements as uniformly as possible throughout the hash table (균일하게 나눈다.)
