Recursion
개요
Recursive call이라는 말은 자기 자신을 호출하는 것을 말한다. 이는 두 가지 방식으로 나뉜다.
- Direct recursion: A가 A를 부름
- Indirect recursion: A가 B, B가 C, C가 A 즉, 두 개 이상의 method가 chain을 이루어 recursion되는 방식이다.
보통의 경우 Recursion이 Iteration보다 직관적이긴 하나 덜 효율적이다.
또한 Recursion을 사용할 때 무한 루프에 빠지지 않도록 조심해야한다.
정의
Recusion은 General (recursive) case를 돌다가 Base case를 만나면 종료되게 된다.
General Format
void recursiveFunction(parameters){
if (some conditions for which answer is known){
solution statement // base case
}
else {
recursiveFunction() // general case
}
}이제 recursion을 사용한 예들을 살펴보자.
Factorial
int recursiveFactorial(int number) {
if (number == 0){
return 1; // base case
}
else {
return number * recursiveFactorial(number - 1);
}
}Combinations
int comnbinations(int n, int k){
if (k == 1) {
return n; // base case 1
}
else if (k == n) {
return 1; // base case 2
}
else {
return combinations(n-1, k) + combinations(n-1, k-1); // general case
}
}Recursion + ADT
개요
이제 recursion을 사용해서 findItem, RevPrint, insertItem등의 ADT를 구현해보자.
recursion은 pointer를 사용할 때 빛을 발한다.
findItem()
bool findItem(ListType list, int item, int startIndex) {
if (list.getItem(startIndex) == item) { // base case 1
return true;
}
else if (startIndex == list.size()) { // base case2
return false;
}
else { // general case
return findItem(list, item, startIndex + 1);
}
}Binary Search
Base case를 생각해보자.
base case
1. mid == item -> true
2. first > lase -> false
general case
1. item > mid -> search upper half
2. item < mid -> search lower half
bool SortedType::findItem(ItemType item, int first, int last) {
int mid;
if (first > last) {
return false; // base case 1
}
mid = (first + last) / 2;
else if (item == data[mid]){
return true; // base case 2
}
else if(item > data[mid]) {
return findItem(item, mid + 1, last);
}
else {
return findItem(item, first, mid - 1);
}
}RevPrint()
위 list의 값을 역으로 출력하는 함수를 작성해보자.
만약 이를 iterative한 방식으로 구현하면 시간복잡도는 이 나온다.
혹은 Stack을 이용할 수도 있긴하다.
이번엔 recursion을 이용해서 구현해보자.
void RevPrint(NodeType* listPtr){
if (listPtr != nullptr) {
RevPrint(listPtr->next);
cout << listPtr->value << endl;
}
}insertItem()
Linked Structure Sorted List에서 insertItem()을 구현해보자.
먼저 구현한 것을 살펴보자.
template<class ItemType>
void insert(NodeType<ItemType>*& location, ItemType item){
if(location == nullptr || (item < location -> value)){ // base case
NodeType<ItemType>* tempPtr = location;
location = new NodeType<ItemType>;
location -> value = item;
location -> next = tempPtr;
}
else {
insert(location->next, item);
}
}
template<class ItemType>
void SortedType<ItemType>::insertItem(ItemType item) {
insert(listData, item);
}base case를 한번 살펴보자.
원래 insertItem은 두 개의 pointer를 수정한다.
- PrevNode->next = newNode;
- newNode->next = nextNode;
그런데 base case를 잘보면 2만 수행하는 것을 알 수 있다. 이를 이해해보자.
함수 인자를 만약 call-by-value로 받았다면 아무일도 일어나지 않았을 것이다.
근데 함수의 인자를 보면 call-by-ref 방식인 것을 알 수 있다.
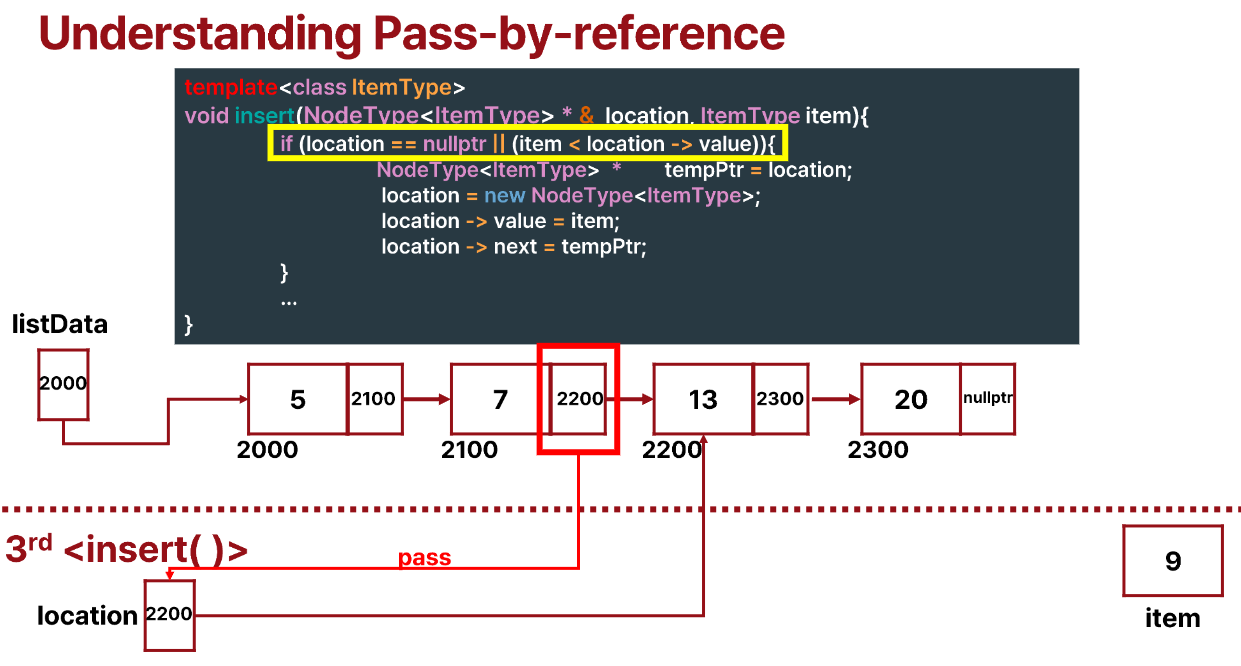
if문에 도달했을 때 위와 같은 모양으로 memory map이 생길 것이다.
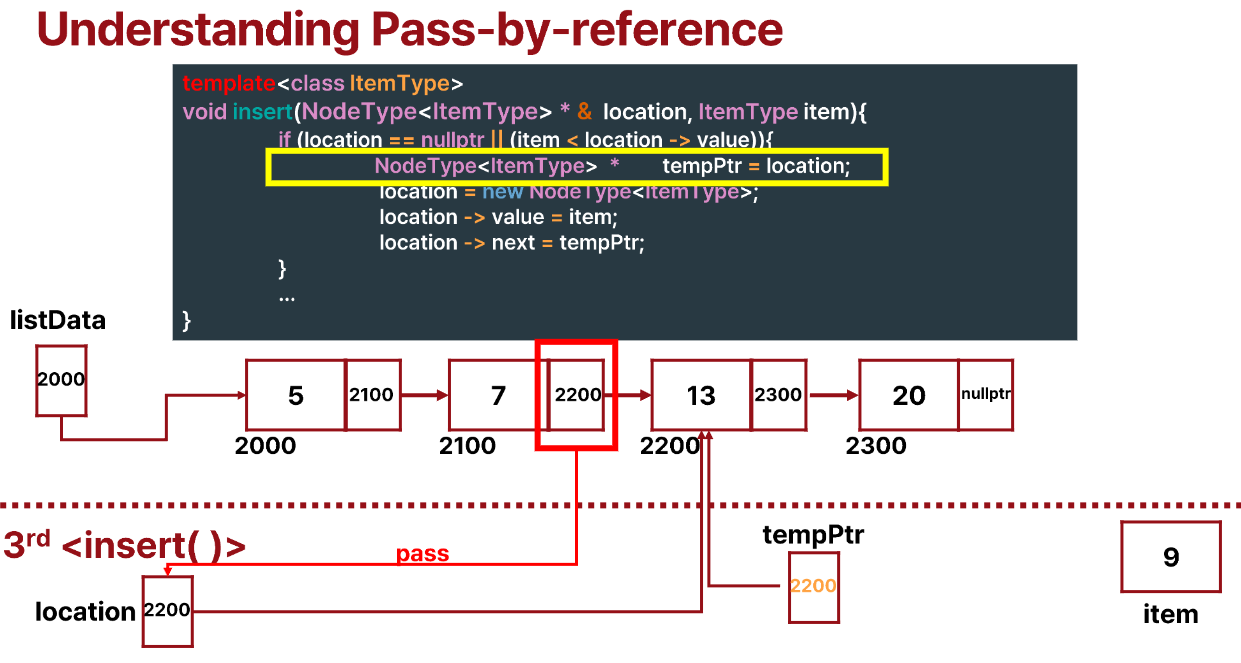
그후 tempPtr을 만들면 위와 같은 모양이 된다.
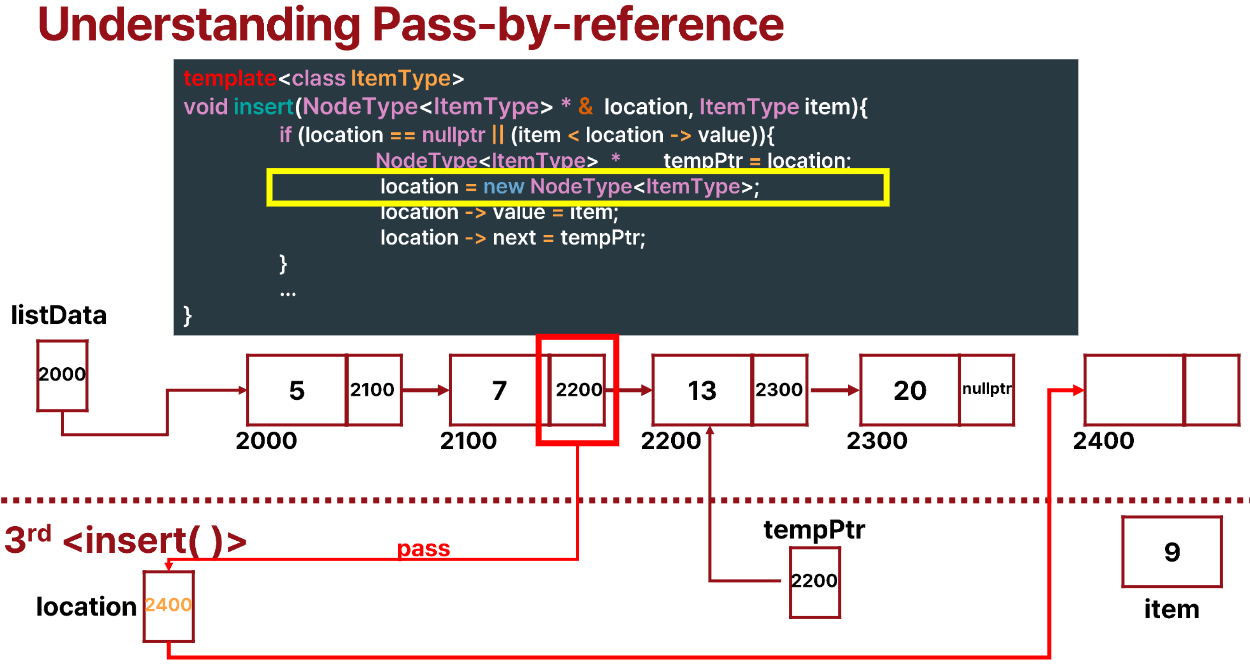
그 다음 location = new NodeType<ItemType>;을 하면 새로운 node를 만들고 loaction이 새로운 노드를 가리키는 것을 알 수 있다.
이때 node의 pointer변수를 pass-by-ref 방식으로 받았기 때문에 원래 node의 pointer 변수도 2400이 된다.
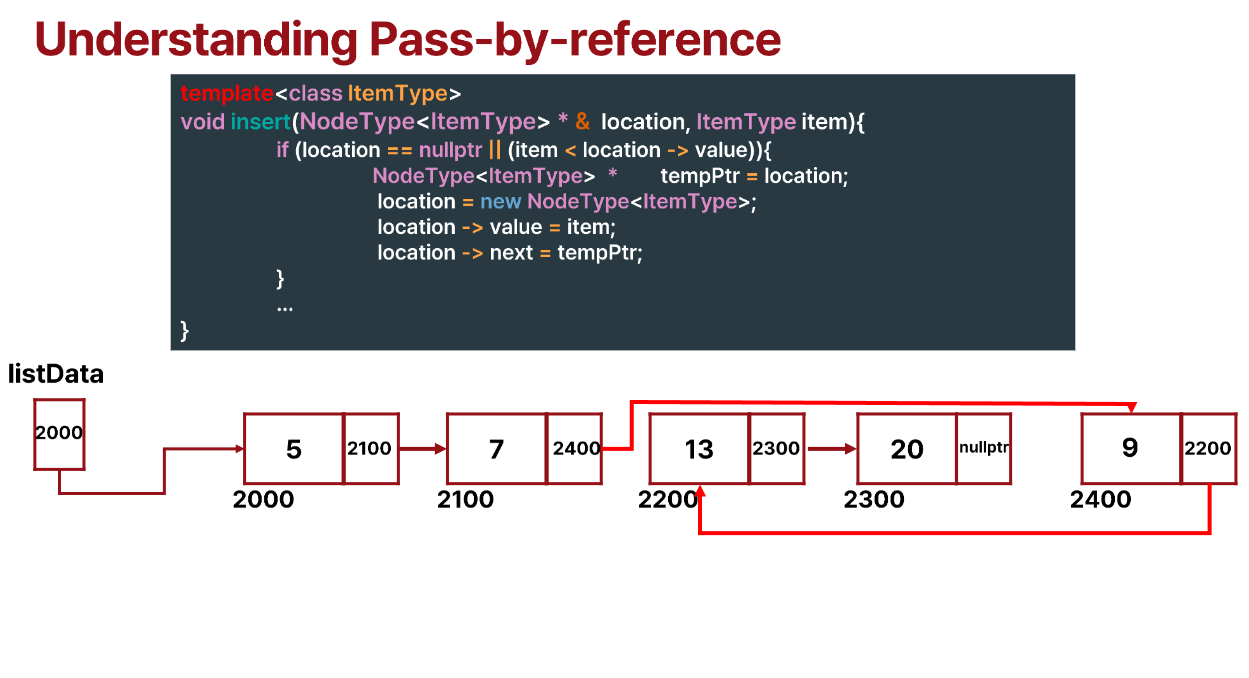
마지막까지 진행하면 location->next가 tempPtr을 가리키도록 하여 위와 같은 구성이 된다.
이렇게 pass-by-ref 방식으로 구현하여 두 개의 pointer를 수정하지 않아도 되게 되었다.
deleteItem()
deleteItem()도 방금처럼 pass-by-ref를 활용하여 pointer를 하나만 수정해서 구현하도록 해보자.
template<class ItemType>
void delete(NodeType<ItemType>*& location, ItemType item){
if (item == location->value){
NodeType<ItemType>* tempPtr = location;
location = location->next;
delete tempPtr;
}
else {
delete(location->next, item);
}
}
template<class ItemType>
void SortedType<ItemType>::deleteItem(ItemType item){
delete(listData, newItem);
}값을 찾으면 tempPtr 만들어 주고
location = location->next;로 location이 가리키는 위치를 바꾸어준다. 그리고 delete tempPtr을 해준다.
Tail Recursion
보통 recursion을 수행할 경우 recursion을 수행할 때마다 Stack에 Activation record가 쌓이게 된다. 아래처럼 정의된 함수를 생각해보자.
int f(n){
if (n == 1 ){
return 0;
}
else {
return n * f(n - 1);
}
}위와 같이 return에서 바로 재귀 함수를 return하지 않고 추가 적인 연산을 수행한다면 함수가 종료되지 않아 activation record가 쌓이게 된다.
또한 return이후 추가적인 동작을 수행한다면 그 또한 계속 해서 activation record가 쌓이게 된다.
tail recursion은 stack에 activation record가 쌓이지 않도록 하기 위해서 정의한다.
사실 컴파일러마다 activation record가 쌓일 수도 있고 안쌓일 수도 있다. 이는 그냥 최적화를 해주는 기법이라 생각하자
함수의 return에 추가적인 연산을 하지않고 바로 f(n)과 같이 값만 전달 해주는 방식이다.
또한 이러한 재귀 호출이 함수의 마지막 연산이어야 한다. 만약 f(n)으로 return을 하고 그 뒤에 또 다른 동작이 있다면 이는 tail recursion이 될 수 없다.
int f(n){
if (n == 1 ){
return 0;
}
else {
return f(n - 1);
}
}위와 같은 방식이 tail recursion이라 할 수 있다.
Recursion VS Iteration
우선 recursion, iteration 둘 다 서로 대체 가능하다.
recursion이 iteration보다 보통 덜 효율적이긴 하다. (시간 복잡도 측면과 자원 측면 둘 다)
하지만 Pointer를 쓸 때 더 유리한 경우가 있고 더 짧고 명확한 코드를 짤 수 있는 경우가 많다.
그리고 다음 자료구조 문제에서 살펴볼 건데 조합에서 Memoization을 사용할 경우 효율성을 극대화 할 수 있다.
