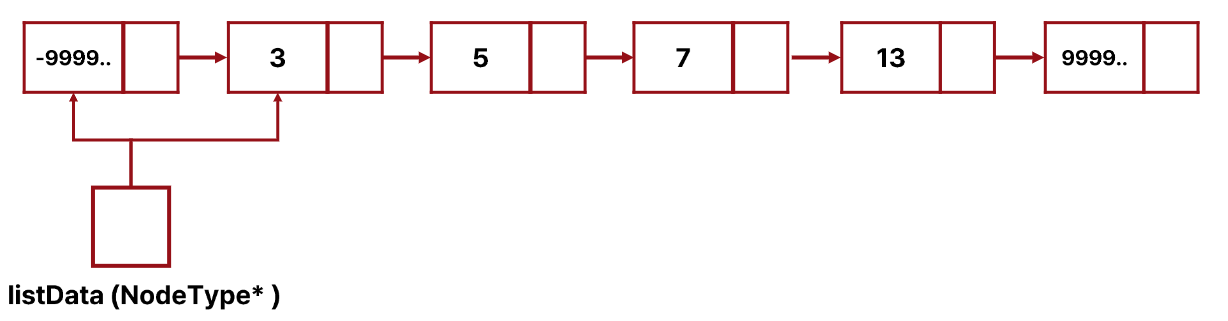
개요
이번에는 Linked Structure - Unsorted List와 Sorted List, Doubly Linked List에 대해 알아보자.
Array vs Linked Structure
Performance
일반적으로 array based structure가 linked structure보다 빠르다.
size(), clear(), destructor에서 각각 O(1), O(N)으로 array based structure가 더 빠르다고 한다.
근데 이 연산자들을 자주 사용할까?
Memory Efficiency
Linked Structure에선 Node에 Pointer(8Byte)가 있어서 메모리 효율성이 array based structure보다 좋지 않다. int type의 경우 4byte 인데 8byte를 낭비하는 꼴이다.
근데 만약 데이터의 크기가 매우 크다면(ex. 1KB) 8byte의 크기가 상대적으로 작지않을까?
Scalability
앞의 내용들만을 봤을 땐 array를 사용하는 것이 좋아보인다. 그럼 linked structure는 왜 사용하는 것일까?
바로 확장성(Scalability)이다.
만약 데이터의 크기가 변동한다면 우리는 array의 크기를 결정할 수 없다. (예를 들어 특정 날짜에 카카오톡 트래픽이 급증함)
Linked Structure는 node를 할당하고 없애면서 데이터의 크기를 조절할 수 있다.
즉, Efficient memory management 특징을 갖고 있다. 관리가 효율적이라는 뜻으로 Memory efficient와는 다른 개념이다.
즉, variability와 data의 크기에 따라 array와 linked structure사이에 고민을 해야한다.
Linked Structure (Unsorted List)
정의
template<class ItemType>
struct NodeType{
ItemType value;
NodeType * next;
}
template<class ItemType>
class UnsortedType{
private:
NodeType<ItemType> * listData;
int length;
Public:
UnsortedType();
void appendItem(ItemType value);
void removeItem(ItemType value);
void clear();
int size();
bool isFull();
bool isEmpty();
bool findItem(ItemType & Item);
ItemType getItem(int pos);
};removeItem()
Logical Level
나머지 연산자들
생성자
template<class ItemType>
UnsortedType<ItemType>::UnsortedType(){
length = 0;
listData = nullptr;
}size()
template<class ItemType>
int UnsortedType<ItemType>::size() const{
return length;
}findItem()
linear search 방식을 이용한다.
template<class ItemType>
bool UnsortedType<ItemType>::findItme(ItemType & item){
NodeType<ItemType> * tempPtr;
tempPtr = listData;
while(tempPtr != nullptr){
if(item == tempPtr -> value){
item = tempPtr -> value;
return true;
}
tempPtr = tempPtr -> next;
}
return false;
}appendItem()
여기에서 append는 front, 앞에서 이루어진다.
front에 추가하면 O(1), rear는 O(N)
template<class ItemType>
void UnsortedType<ItemType>::appendItem(ItemType item){
NodeType<ItemType> * tempPtr;
tempPtr = new NodeType<ItemType>;
tempPtr->value = item;
tempPtr->next = listDta;
listData = tempPtr;
length ++;
}Linked Structure (Sorted List)
개요
Unsorted List에서 사용했던 대부분의 연산자는 그대로 사용하고 insertItem(), removeItem, findItem 만 따로 정의하여 사용한다.
findItem()
Logical Level
array-based sorted list는 binary search를 사용하여 시간복잡도를 으로 만들 수 있었다.
linked structure에서는 탐색할 때 하나씩 탐색해야 하므로 binary search를 사용할 수 없고 linear search를 이용해야한다.
insertItem()
Logical Level
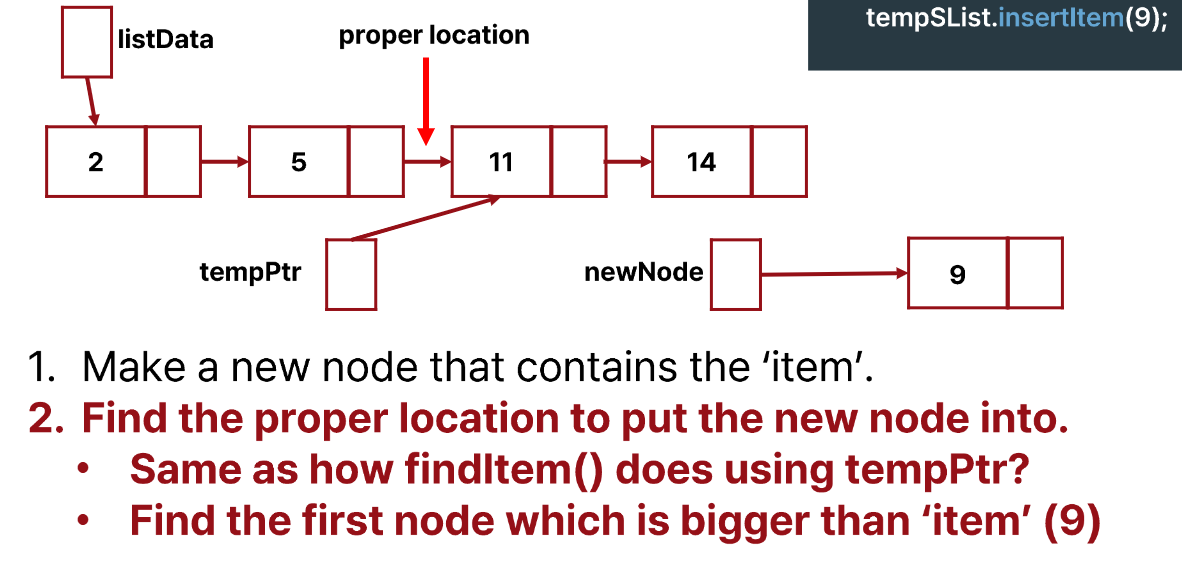
- item 값을 포함하는 newNode를 만든다.
- newNode가 들어갈 위치를 찾는다.
- item보다 큰 값이 있는 node를 찾았다.
- 이전 node를 가리킬 pointer가 사라져서 linked structure를 유지할 수 없게 되었다.
이 문제를 어떻게 해결하면 좋을까?
tempPtr->next로 값을 검사해서 큰 값이 나왔을 때 연결해준다면 이전 node에 대한 pointer를 잃지 않을 수 있을 것이다.
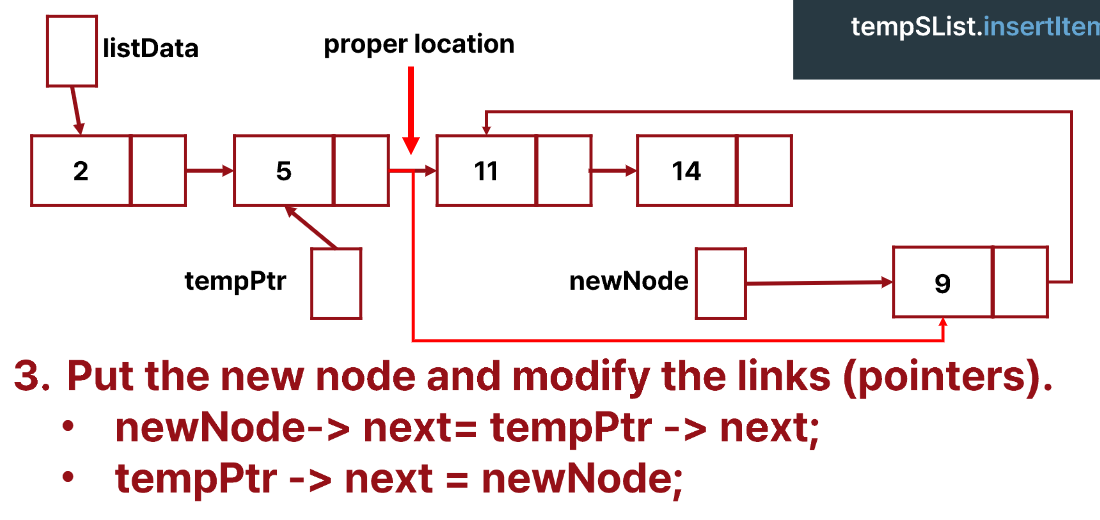
- tempPtr->next로 값을 검사한다.
- 적절한 위치를 찾았다면
newNode->next = tempPtr->next;tempPtr->next = newNode;로 마무리 해준다.
이것이 끝이 아니다 tempPtr->next로 값을 검사하는 것이기 때문에 list가 비었을 때, 첫 번째 위치에 넣을 때, 마지막 위치에 넣을 때 등등 edge case를 고려해주어야 한다.
Implementation Level
template <class ItemType>
void SortedType<ItemType>::insertItem(ItemType item)
{
if (isFull()) { // 꽉찼을 때
return;
}
NodeType<ItemType>* tempPtr;
NodeType<ItemType>* newNode;
tempPtr = listData;
newNode = new NodeType<ItemType>;
newNode->value = item;
newNode->next = nullptr;
if (isEmpty()) { // 비었을 때
listData = newNode;
length++;
return;
}
if (tempPtr->value > item) { // 첫 번째에 넣는 상황
newNode->next = tempPtr;
listData = newNode;
length++;
return;
}
while (tempPtr->next != nullptr) {
if ((tempPtr->next)->value > item) {
break;
}
tempPtr = tempPtr->next;
}
if (tempPtr->next == nullptr) { // 마지막에 넣는 상황
tempPtr->next = newNode;
length++;
return;
}
newNode->next = tempPtr->next; // 마지막 처리
tempPtr->next = newNode;
length++;
}주의 사항
node를 이용하여 구현하는 경우 tree가 되었든, heap이 되었든, linked structure가 되었든 새로 만드는 node는 반드시!! next = nullptr로 지정을 해주어야 오류가 안난다.
removeItem()
이도 InsertItem과 마찬가지로 값을 찾고 지운뒤 새로 연결을 해주는데 next로 검사를 하여 linked structure를 유지한다.
구현
template <class ItemType>
void SortedType<ItemType>::removeItem(ItemType item)
{
NodeType<ItemType>* tempPtr;
NodeType<ItemType>* deallocPtr;
tempPtr = listData;
if (isEmpty()) { // 비었을 때
return;
}
else if (tempPtr->value == item) { // 첫 번째 Item 지우는 과정
listData = tempPtr->next;
delete tempPtr;
length--;
return;
}
if (tempPtr->next == nullptr) { // 값이 없을 때
return;
}
while (item != tempPtr->next->value) { // 값 찾기
tempPtr = tempPtr->next;
if (tempPtr->next == nullptr) {
return;
}
}
deallocPtr = tempPtr->next;
if (deallocPtr->next == nullptr) { // 마지막 Item 지울 때
delete deallocPtr;
tempPtr->next = nullptr;
length--;
return;
}
tempPtr->next = tempPtr->next->next; // 지우는 과정
delete deallocPtr;
length--;
}시간 복잡도
시간복잡도 측면에서는 Array로 구현하는 것이 유리하다. findItem(), clear() 등 유리함
그러나 Linked Structure로 구현하면 Scalability가 유리하다.
Doubly Linked List
정의
지금까지 우리는 linked structure를 한 방향으로만 탐색할 수 있었다.
그러나 doubly linked structure는 successor와 predecessor를 갖고있어 양 방향으로 탐색이 가능하다.
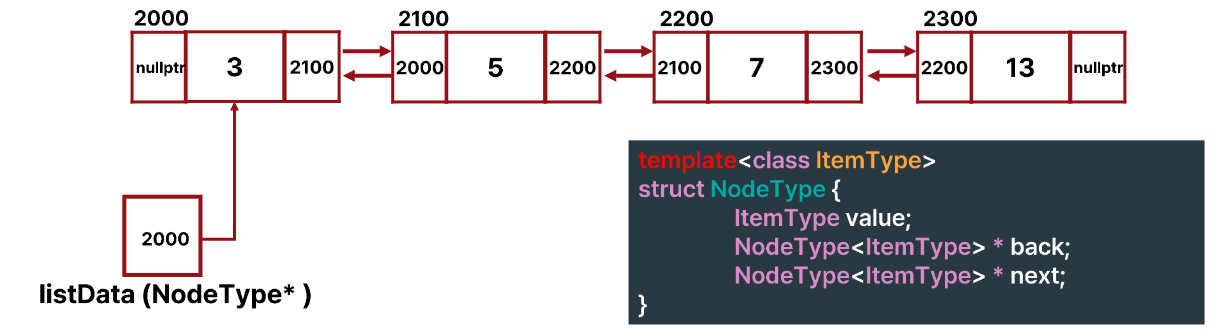
insertItem()
Logical Level
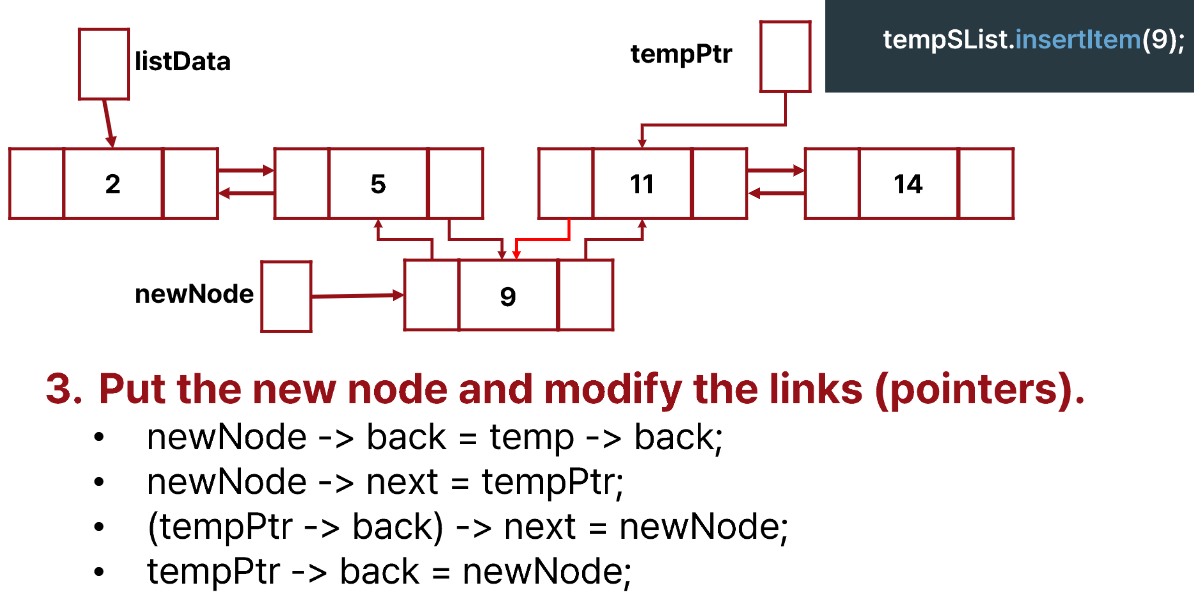
- 새로운 newNode를 만든다.
- newNode의 next, back은 전부 nullptr로 설정해야한다.
- tempPtr로 위치를 찾는다.
- 위 그림과 같은 과정을 거친다.
이것이 끝이 아니다.
empty list에 insert하는 경우, 첫 번째에 insert하는 경우, 마지막에 insert하는 경우의 edge case를 고려해야 한다.
Implementaion Level
template <class ItemType>
void DoubleSortedType<ItemType>::insertItem(ItemType item)
{
NodeType<ItemType>* newNode;
NodeType<ItemType>* tempPtr;
newNode = new NodeType<ItemType>;
newNode->value = item;
newNode->next = nullptr; // 반드시 설정해야함 안하면 오류생김
newNode->back = nullptr;
tempPtr = listData;
if (listData == nullptr) { // empty list일 때
listData = newNode;
length++;
return;
}
if (isFull()) {
return;
}
if (tempPtr->value > item) { // 첫 번째에 insert할 때
newNode->next = tempPtr;
tempPtr->back = newNode;
listData = newNode;
length++;
return;
}
tempPtr = tempPtr->next;
while (tempPtr != nullptr) {
if (tempPtr->value > item) { // insert 과정
newNode->back = tempPtr->back;
newNode->next = tempPtr;
(tempPtr->back)->next = newNode;
tempPtr->back = newNode;
length++;
return;
}
if (tempPtr->next == nullptr) { // 마지막에 insert할 때
tempPtr->next = newNode;
newNode->back = tempPtr;
length++;
return;
}
tempPtr = tempPtr->next;
}
}removeItem()
removeItem()도 마찬가지로 값을 찾고 remove하되, edge case를 고려하여 구현한다.
template <class ItemType>
void DoubleSortedType<ItemType>::removeItem(ItemType item)
{
NodeType<ItemType>* tempPtr;
tempPtr = listData;
if (isEmpty()) { // 비었을 때
return;
}
if (tempPtr->value == item) { // 첫 번째 item일 때
listData = tempPtr->next;
if (listData != nullptr) {
listData->back = nullptr;
}
length--;
delete tempPtr;
return;
}
tempPtr = tempPtr->next;
while (tempPtr != nullptr) {
if ((tempPtr->value) == item) {
if (tempPtr->next == nullptr) { // 마지막일 때
(tempPtr->back)->next = nullptr;
}
else { // 지우는 과정
(tempPtr->back)->next = tempPtr->next;
(tempPtr->next)->back = tempPtr->back;
}
length--; // 지우는 과정
delete tempPtr;
return;
}
else {
tempPtr = tempPtr->next;
}
}
return;
}
Minimizing Edge cases
list에 head와 tail node를 사용하여 edge case를 최소화 할 수 있다.
head엔 가능한 작은 값을 넣고 tail엔 가능한 큰 값을 넣음으로써 edge case를 최소화할 수 있다.