1. 서론
- 프로젝트를 하면서 문제를 검색하는 부분에서 성능의 문제점을 발견을 하였습니다. 조건 없는 기본 검색을 POSTMAN으로 했을 때 20 ~ 25MS가 발생하며 조건을 추가를 하였을 때 160MS으로 발생을 하였다. 아무래도 4개의 테이블을 조인해서 가져오고 정렬이 필요하기 때문이라고 생각을 하였습니다. 이러한 문제점을 보기 위해서 MySQL의 실행계획을 통하여 문제를 분석을 하였습니다.
2. 본론
explain select
distinct question.question_id as c1,
question.question_title as c2,
categorys.category_title as c3,
case
when memberquestion.member_id=2 then case
when memberquestion.question_success<>0 then 1
when memberquestion.question_fail<>0 then 2
else 0
end
else 0
end as col_3_0_
from
question question
left outer join
category categorys
on question.category_id=categorys.category_id
left outer join
member_question memberquestion
on question.question_id=memberquestion.question_id
left outer join
member members
on memberquestion.member_id=members.member_id
where
question.question_title='Sample Question 66'
and question.category_id = (
select
categorysub.category_id
from
category categorysub
where
categorysub.category_title='네트워크'
)
and members.member_id=2
and memberquestion.question_success<>1
and limit 100;
-
기존의 조건 검색을 실행계획을 살펴보니 다음과 같다. 현재 이 부분에 Type이 ALL로 Full Scan을 하고 있다고 생각을 했습니다.
-
Explain Analyze를 통하여 실행을 순서대로 살펴보겠습니다.
2-1. 실행 계획
ID 컬럼
- 하나의 SELECT 문장은 다시 1개 이상의 하위 SELECT 문장을 포함할 수 있습니다.
- 실행 계획에서 가장 왼쪽에 표시되는 ID 컬럼은 단위 SELECT 쿼리별로 부여되는 식별자 값입니다.
Select Type
- SELECT TYPE은 각 단위 SELECT 쿼리가 어떤 타입의 쿼리인지 표시되는 컬럼입니다.
SIMPLE: UNION이나 서브쿼리를 사용하지 않는 가장 단순한 SELECT 쿼리인 경우 해당 쿼리 문장의 타입이 SIMPLE로 표시가 됩니다.
union이란
하나의 테이블에 다른 테이블의 정보를 담기 위해서는 서브쿼리와 조인의 방식으로 데이터를 표현을 합니다. 하지만 다른 테이블이지만 각각의 테이블에 동일한 컬럼에 담아서 표현하고 싶은 경우에 union을 사용할 수 있습니다.
-
PRIMARY: UNION이나 서브쿼리를 가지는 SELECT 쿼리의 실행 계획에서 가장 OUTER에 있는 단위 쿼리를 의미합니다. -
UNION: UNION 결합하는 단위 SELECT 쿼리 가운데 첫 번째를 제외한 두번째 이후 단위 SELECT 쿼리의 타입을 UNION으로 표시합니다. -
SUBQUERY: FROM절 이외에서 사용되는 서브쿼리만 의미를 합니다.
Table
- MySQL 서버의 실행 계획은 단위 SELECT 쿼리 기준이 아니라 테이블 기준으로 표시를 합니다. 테이블의 이름에 별칭이 부여된 경우에는 별칭이 사용을 합니다.
- 만약에 From 테이블에 없다면 Dual이 반환이 됩니다.
EXPLAIN SELECT NOW();
EXPLAIN SELECT NOW() FROM DUAL;TYPE
-
저느 쿼리의 실행 계획에서 가장 중요하게 보는 부분입니다. MySQL서버가 각 테이블의 레코드를 어떤 방식으로 읽었는지를 나타냅니다. 여기서 방식이란 인덱스를 사용을 하였는지아니면 풀 테이블 스캔으로 레코드를 읽었는지 등 다양한 방식을 의미를 합니다.
-
타입에는 많은 방식이 있지만 가장 많이 살펴본 방식 몇가지를 소개를 하겠습니다.
CONST: 테이블의 레코드 건수와 관계없이 쿼리가 pk, 유니크 키 컬럼을 사용하여 where 절을 가지고 있으며 반드시 1개만 반환이 되는 처리 방식을 의미를 합니다. 보통 이것을 유니크 인덱스 스캔이라고 말합니다.eq_ref: 여러 테이블이 조인되는 쿼리의 실행 계획에서 표시를 합니다. 조인에서 처음 읽은 테이블의 컬럼값을 그다음 읽어야 할 테이블의 pk나 유니크 키 컬럼의 검색 조건에 사용할 때 eq_ref로 표현을 합니다.ref: 조인의 순서와 관계없이 사용을 합니다. 보통 pk, 유니크 키등 제약 조건이 없습니다. 인덱스의 종류와 상관없이 EQUAL조건으로 검색을 할때 사용을 합니다.ALL: 가장 문제가 되는 부분 입니다. 풀 테이블 스캔을 의미를 합니다. 테이블을 처음부터 끝까지 전부 읽어서 불필요한 레코드를 제거하고 반환을 합니다. 가장 비효율적인 방법입니다.index: INDEX는 보통 READ의 효율을 높인다고 학습을 하였지만 실행 계획에서 INDEX는 인덱스 풀 스캔을 의미를 합니다. 범위 접근 방법과 효율적인 인덱스의 필요한 부분만 읽는 것과 다릅니다.
Key
- 키 컬럼은 인덱스는 최종 선택된 실행 계획에서 사용하는 인덱스를 의미를 합니다. 보통 1개의 키를 가지는데 TYPE이 INDEX_MERGE가 아닌 경우에는 반드시 테이블 하나당 하나의 인덱스만 이용을 합니다.
Extra
Using filesort: Order by를 처리하기 위해 Index를 사용할 수 있지만 인덱스가 적절하지 않는 경우에 MySQL이 조회된 레코드를 다시 정렬을 합니다. Order By 처리가 인덱스를 사용하지 못할 때만 실행 계획의 Extra 컬럼에 Using filesort가 표시가 된다.Using temporary: MySQL 서버에서 쿼리를 처리하는 동안 중간 결과를 담아 두기 위한 임시 테이블을 사용을 합니다. 임시 테이블을 사용하기 때문에 디스크상에 생성될 수 있어 성능적인 저하가 발생을 합니다.Using Index: 데이터 파일을 전혀 읽지 않고 인덱스만 읽어서 모두 처리할 수 있을 때 Using Index로 표시가 된다. 이것을 커버링 인덱스로 표현을 합니다.커버링 인덱스
쿼리를 충족시키는데 필요한 모든 데이터를 갖고 있는 인덱스를 의미를 합니다.
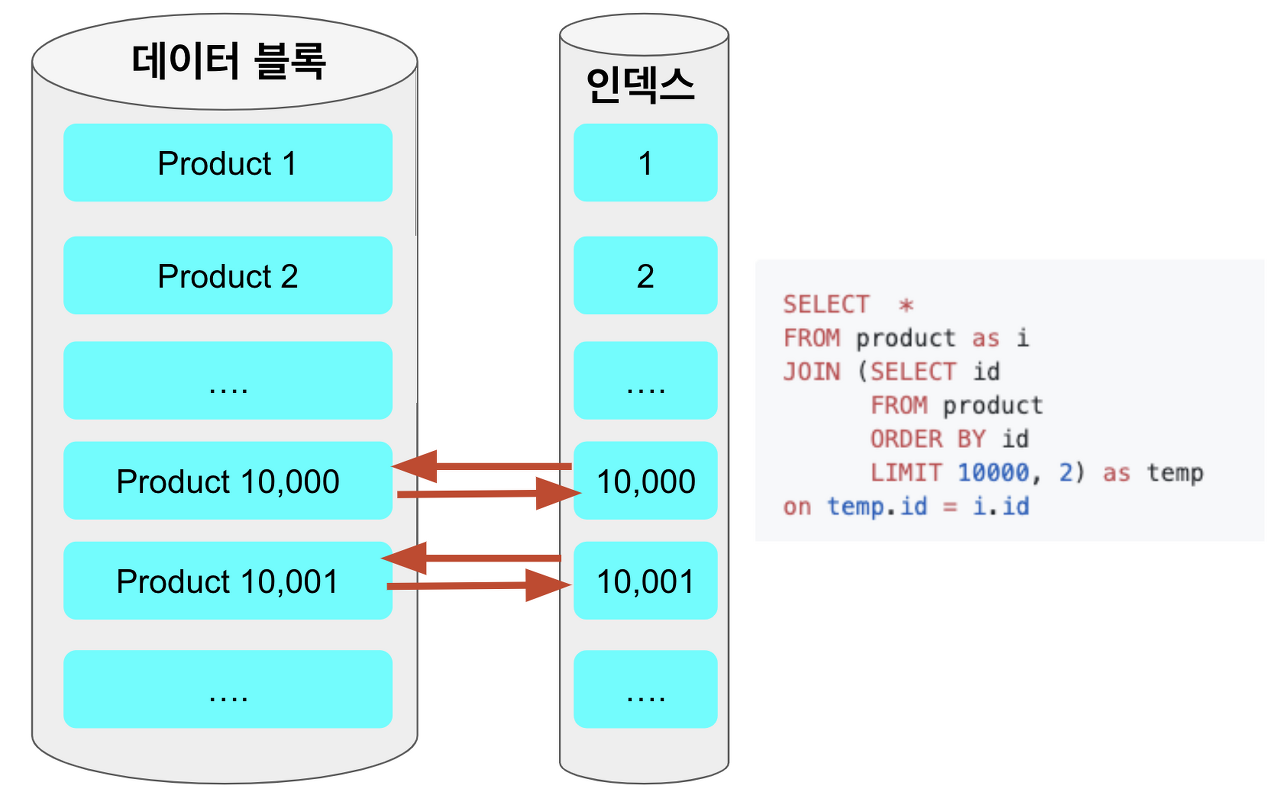
https://frogand.tistory.com/195
Using Join buffer(Hash join): 일반적으로 MySQL의 옵티마이저는 조인되는 두 테이블에 있는 각 컬럼에서 인덱스를 조사하고 인덱스가 없는 테이블이 있으면 그 테이블을 먼저 읽어서 조인을 합니다.- 왜냐하면 뒤에 읽는 테이블은 주로 검색 위주로 사용되기 때문에 인덱스가 없으면 성능에 미치는 영향이 매우 크기 때문입니다. 만약에 뒤에 있는 테이블에 검색을 위한 적절한 인덱스가 없다면 Hash Join을 실행을 합니다.
문제 해결
- 기존의 QueryDSL 코드를 살펴보면 문제를 페이징 하는 코드입니다.
이 코드를 살펴보면 @QueryProjection을 사용하여 특정 DTO를 조회를 하며 WHERE 조건을 4가지가 있습니다. (1) 문제 제목을 기준으로 조회 (2) 카테고리 아이디를을 기준으로 카테고리 타이틀과 서브쿼리 (3) 회원 아이디에 대한 조회 (4) STATUS에 대한 조회 입니다. STATUS는 다른 코드와 다르게 추가적인 설정을 하였습니다. 특정 회원 A가 문제를 풀었을 때 정답을 저장하고 문제가 틀렸을 때 틀린 번호를 지정하여 테이블에 저장을 합니다. - 이때 STATUS를 보여주는 코드에서는 정답이면 1 오답이면 2 모두 해당하지 않는다면 0으로 초기화 하는 조건을 추가를 하였습니다.
public class QuestionRepositoryCustomImpl implements QuestionRepositoryCustom {
private final JPAQueryFactory queryFactory;
public QuestionRepositoryCustomImpl(JPAQueryFactory queryFactory) {
this.queryFactory = queryFactory;
}
@Override
public Page<QuestionPageWithCategoryAndTitle> findQuestionPageWithCategory(Pageable pageable, QuestionSearchCondition questionSearchCondition, LoginUserDto loginUserDto) {
List<QuestionPageWithCategoryAndTitle> content = queryFactory.select(
new QQuestionPageWithCategoryAndTitle(
question.id.as("questionId"),
question.title.as("questionTitle"),
category.categoryTitle.as("categoryTitle"),
divisionStatusAboutMemberId(loginUserDto)
)).from(question)
.distinct()
.leftJoin(question.category, category)
.leftJoin(question.questions, memberQuestion)
.leftJoin(memberQuestion.member, member)
.where(
questionTitleEq(questionSearchCondition.getQuestionTitle()),
memberIdEq(questionSearchCondition.getMemberId()),
statusEq(questionSearchCondition.getStatus()),
question.category.id.eq(category.id)
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
return new PageImpl<>(content, pageable, content.size());
}
private static NumberExpression<Integer> divisionStatusAboutMemberId(LoginUserDto loginUserDto) {
return Expressions.cases()
.when(memberQuestion.member.id.eq(loginUserDto.getMemberId())).then(
Expressions.cases()
.when(memberQuestion.success.ne(0)).then(1)
.when(memberQuestion.fail.ne(0)).then(2)
.otherwise(Expressions.constant(0))
)
.otherwise(Expressions.constant(0))
.as("status");
}
private BooleanExpression categoryTitleEqSubquery(String categoryTitle) {
if (StringUtils.hasText(categoryTitle)) {
JPAQuery<Long> subquery = queryFactory.select(category.id)
.from(category)
.where(category.categoryTitle.eq(categoryTitle));
return question.category.id.eq(subquery);
} else {
return null;
}
}
private BooleanExpression questionTitleEq(String questionTitle) {
return StringUtils.hasText(questionTitle) ? question.title.eq(questionTitle) : null;
}
private BooleanExpression memberIdEq(Long memberId) {
return memberId != null ? member.id.eq(memberId) : null;
}
private BooleanExpression statusEq(Integer status) {
if (status != null) {
if (status.equals(1)) {
return memberQuestion.success.ne(0);
} else if (status.equals(2)) {
return memberQuestion.fail.ne(0);
}
}
return null;
}
}
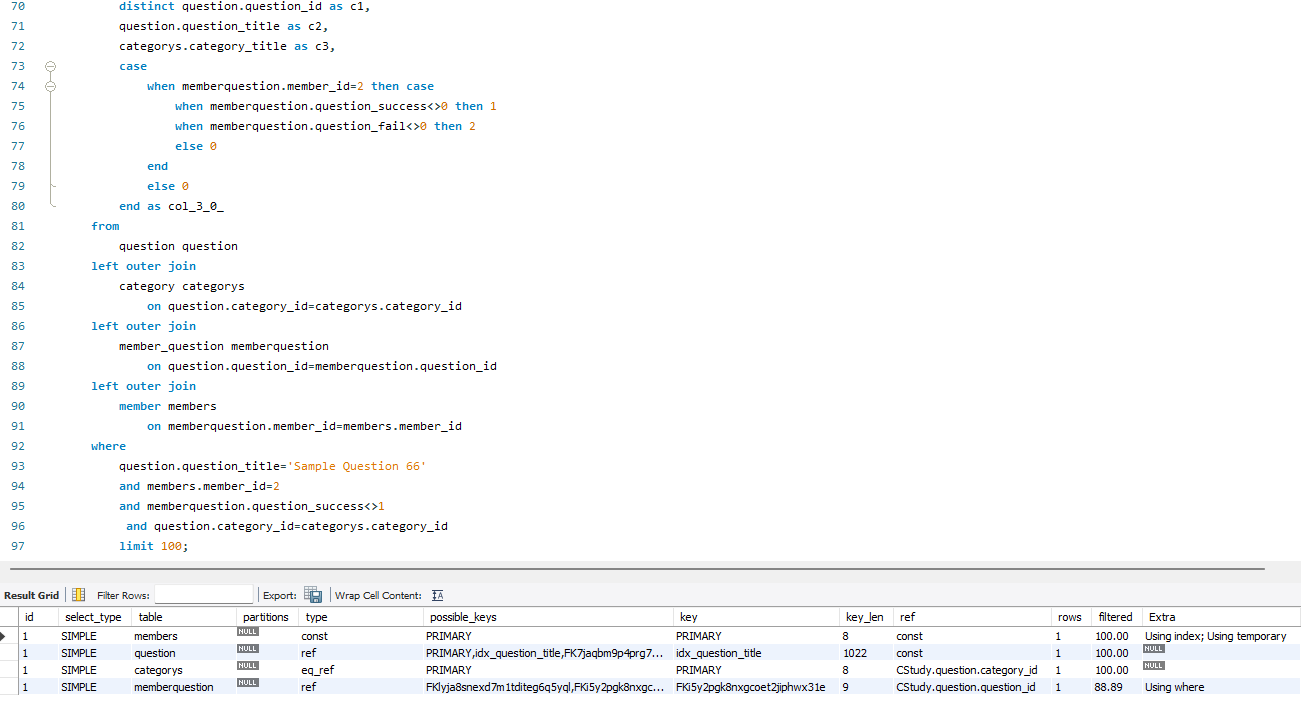
- 위 실행 계획을 살펴보면 3개의 테이블이 Table Full Scan을 진행하며 Using temporary, Using Hash Join을 하는 문제를 볼 수 있다. 이것을 살펴보면 Table Full Scan을 하기 때문에 Filter를 하였는데 10,000건의 데이터를 살펴보고 있다. 이것은 성능적으로 문제가 될 수 있다고 생각하여 해결을 하였다.
해결하기 위해 적용한 방법
1. 인덱스
@Entity
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Table(name = "Category", indexes = {
@Index(name = "idx_category_title", columnList = "category_title")
})
public class Category {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "category_id")
private Long id;
... 생략
}
@Entity
@Getter
@NoArgsConstructor
@Table(name = "question", indexes = {
@Index(name = "idx_question_title", columnList = "question_title")
})
public class Question {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "question_id")
private Long id;
...생략
}2. 카테고리 서브쿼리에서 동등 비교
private BooleanExpression categoryTitleEq(String categoryTitle) {
return StringUtils.hasText(categoryTitle) ? category.categoryTitle.eq(categoryTitle) : null;
}- 기존의 category는 서브쿼리에서 request의 categoryTitle을 직접 비교하는 방식으로 수정을 하였습니다. 서브쿼리를 하면 추가적인 리소스가 필요하기 때문에 성능적 저하를 막고 코드의 가독성을 높혔습니다.
3. 실행 계획을 통한 조인 순서 최적화
- 실행 계획을 살펴보면서 where절의 조건에 따라서 조인 순서가 바뀌는 것을 알 수 있었습니다.
- 일단 기존의 서브쿼리를
카테고리 타이틀로 동등 조인한 쿼리와 실행 계획을 살펴보겠습니다.
...생략
where
question.question_title='Sample Question 66'
and categorys.category_title='네트워크'
and members.member_id=2
and memberquestion.question_success<>1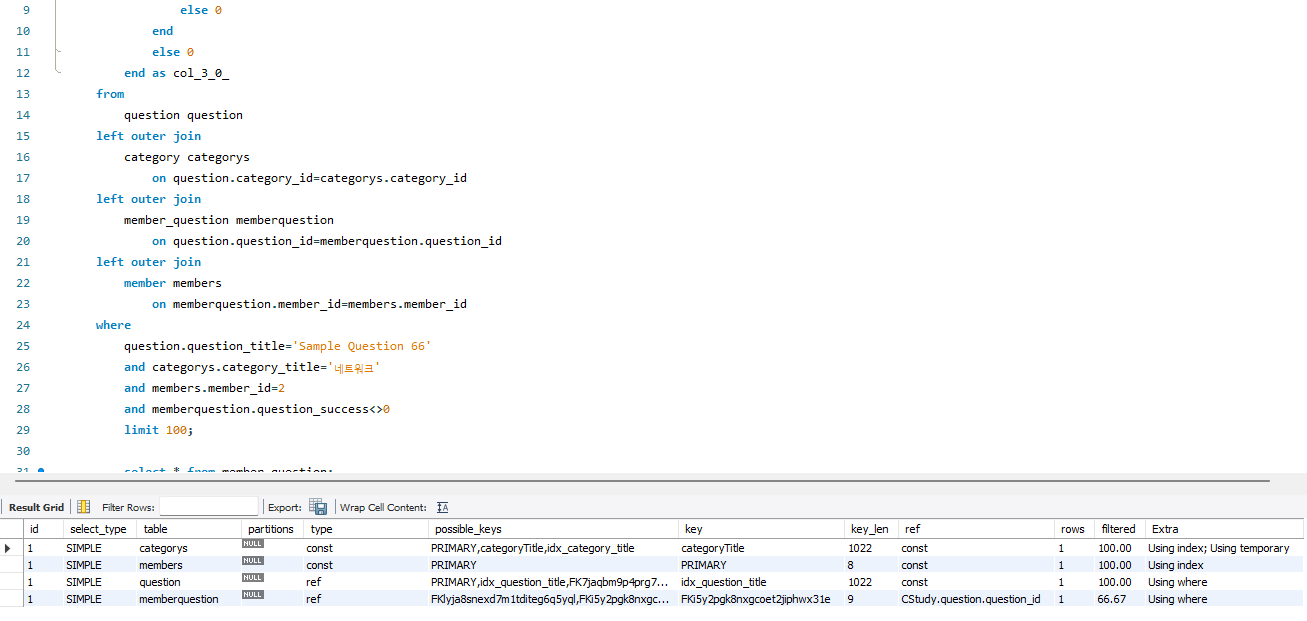
-
위에 사진을 보면 category를 먼저 조인하고 데이터를 처리를 하는 모습을 살필 수 있습니다.
-
일단 이때 동등 비교를 하기 때문에 카테고리에 인덱스를 추가를 하였습니다.
-
이렇게 하였을 때 기존의 3개의 filter를 통해 full scan을 하는 쿼리에서 비교적 최적화를 시킨 모습을 살필 수 있습니다.
-
이 부분에서 인덱스를 추가적으로 학습을 하면서 클러스터, 논클러스터 인덱스에 대해서 학습을 하였습니다.
-
학습을 하면서 지금의
and categorys.category_title='네트워크'의 비교 where절을 바꿀 수 있다고 생각을 했습니다.
리펙토링
where
question.question_title='Sample Question 66'
and members.member_id=2
and memberquestion.question_success<>1
and question.category_id=categorys.category_id
limit 100;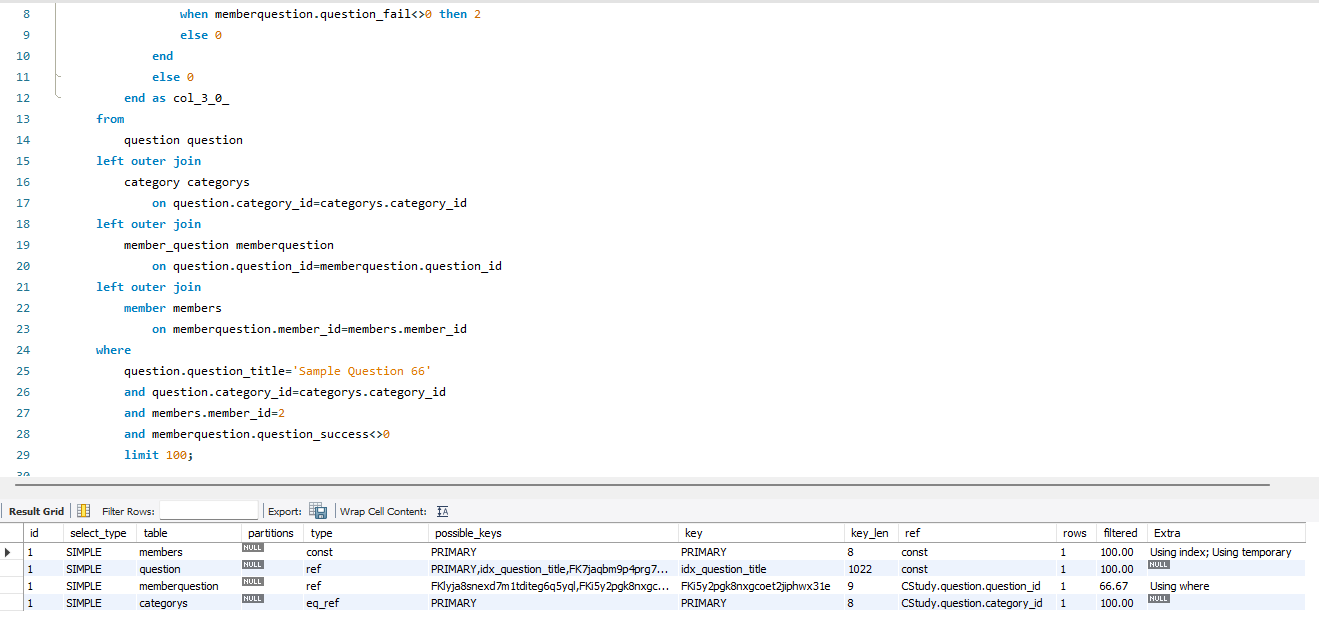
- question 테이블의 조인 테이블 category의 pk로 비교를 하게 시켰습니다.
이렇게 리펙토링을 하여 다음과 같은 효과를 얻을 수 있었습니다.
1. 불필요한 Category_title 인덱스 제거
2. 논클러스터 인덱스를 타지 않고 바로 클러스터 인덱스로 더욱 빠르게 조회
- 어처피 논클러스터 인덱스도 결국 PK를 타고 조회를 해야되는데 바로 pk를 타고 조회가 가능하여 좋음
3. 실행계획의 순서가 바뀌어 추가적인 using where가 필요없음
- 위에 실행 계획은 1번 쿼리와 다르게 카테고리 보다는 member를 먼저 접근을 합니다. 이후 question, category, memberquestion으로 접근을 하여서 category에 있는 using where을 제거하여 더욱 최적화를 시켰습니다.
넌 클러스터 인덱스
-
Oracle과 다르게 MySQL은 Index를 다르게 PK를 기반해서 데이터를 찾습니다.
- 아마도 Oracle은 pk 말고 주소를 기반으로 찾는 것으로 알고 있습니다.
-
이때 category_title을 설정해서 비교를 하게 되면 넌 클러스터 인덱스를 찾고 이후 클러스터 인덱스를 찾아서 데이터베이스에 조회를 하게 됩니다.
-
이걸 클러스터 인덱스로만 가능하다면 1단계를 생략할 수 있기 때문에 좋다고 생각한다.
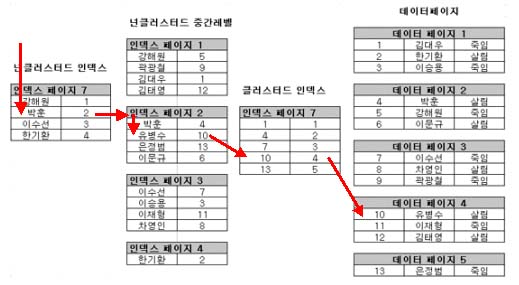
변경된 부분
QueryDsl
@Override
public Page<QuestionPageWithCategoryAndTitle> findQuestionPageWithCategory(Pageable pageable, QuestionSearchCondition questionSearchCondition, LoginUserDto loginUserDto) {
List<QuestionPageWithCategoryAndTitle> content = queryFactory.select(
new QQuestionPageWithCategoryAndTitle(
question.id.as("questionId"),
question.title.as("questionTitle"),
category.categoryTitle.as("categoryTitle"),
divisionStatusAboutMemberId(loginUserDto)
)).from(question)
.distinct()
.leftJoin(question.category, category)
.leftJoin(question.questions, memberQuestion)
.on(memberQuestion.member.id.eq(loginUserDto.getMemberId()))
.leftJoin(memberQuestion.member, member)
.where(
questionTitleEq(questionSearchCondition.getQuestionTitle()),
categoryTitleEq(questionSearchCondition.getCategoryTitle()),
memberIdEq(questionSearchCondition.getMemberId()),
statusEq(questionSearchCondition.getStatus())
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
JPAQuery<Long> countQuery = queryFactory
.select(question.count())
.from(question)
.leftJoin(question.category, category)
.leftJoin(question.questions, memberQuestion)
.where(memberQuestion.member.id.eq(loginUserDto.getMemberId()))
.leftJoin(memberQuestion.member, member)
.where(
questionTitleEq(questionSearchCondition.getQuestionTitle()),
categoryTitleEq(questionSearchCondition.getCategoryTitle()),
memberIdEq(questionSearchCondition.getMemberId()),
statusEq(questionSearchCondition.getStatus())
);
return PageableExecutionUtils.getPage(content, pageable, countQuery::fetchCount);
}
private static NumberExpression<Integer> divisionStatusAboutMemberId(LoginUserDto loginUserDto) {
return Expressions.cases()
.when(memberQuestion.member.id.eq(loginUserDto.getMemberId())).then(
Expressions.cases()
.when(memberQuestion.success.ne(0)).then(1)
.when(memberQuestion.fail.ne(0)).then(2)
.otherwise(Expressions.constant(0))
)
.otherwise(Expressions.constant(0))
.as("status");
}
private BooleanExpression categoryTitleEq(String categoryTitle) {
return StringUtils.hasText(categoryTitle) ? category.categoryTitle.eq(categoryTitle) : null;
}
private BooleanExpression questionTitleEq(String questionTitle) {
return StringUtils.hasText(questionTitle) ? question.title.contains(questionTitle) : null;
}
private BooleanExpression memberIdEq(Long memberId) {
return memberId != null ? member.id.eq(memberId) : null;
}
private BooleanExpression statusEq(Integer status) {
if (status != null) {
if (status.equals(1)) {
return memberQuestion.success.ne(0);
} else if (status.equals(2)) {
return memberQuestion.fail.ne(0);
}
}
return null;
}
explain SELECT DISTINCT
question.question_id AS questions,
question.question_title AS question_title,
categorys.category_title AS category_title,
CASE
WHEN memberquestion.member_id = 4 THEN CASE
WHEN memberquestion.question_success <> 0 THEN 1
WHEN memberquestion.question_fail <> 0 THEN 2
ELSE 0
END
else 0
END AS member_status
FROM
question question
LEFT OUTER JOIN
category categorys
ON question.category_id = categorys.category_id
LEFT OUTER JOIN
member_question memberquestion
on (question.question_id=memberquestion.question_id and memberquestion.member_id=4)
AND memberquestion.member_id = 4
LEFT OUTER JOIN
member members
ON memberquestion.member_id = members.member_id
where
question.question_title='question_title'
and memberquestion.question_success<>1
and question.category_id=categorys.category_id limit 100;결론
-
기존에 카테고리는 Full Scan에서 const로 pk, fk로 반드시 1개만 반환을 하게 설정 + 서브쿼리를 이용하여 조회에서 동등 조인으로 코드 가독성 및 서브쿼리를 제거를 하였습니다.
-
추가적으로 인덱스를 사용하여 Full Scan을 하는 category와 memberquestion이 const, ref로 변경을 했습니다.
테이블 풀 스캔
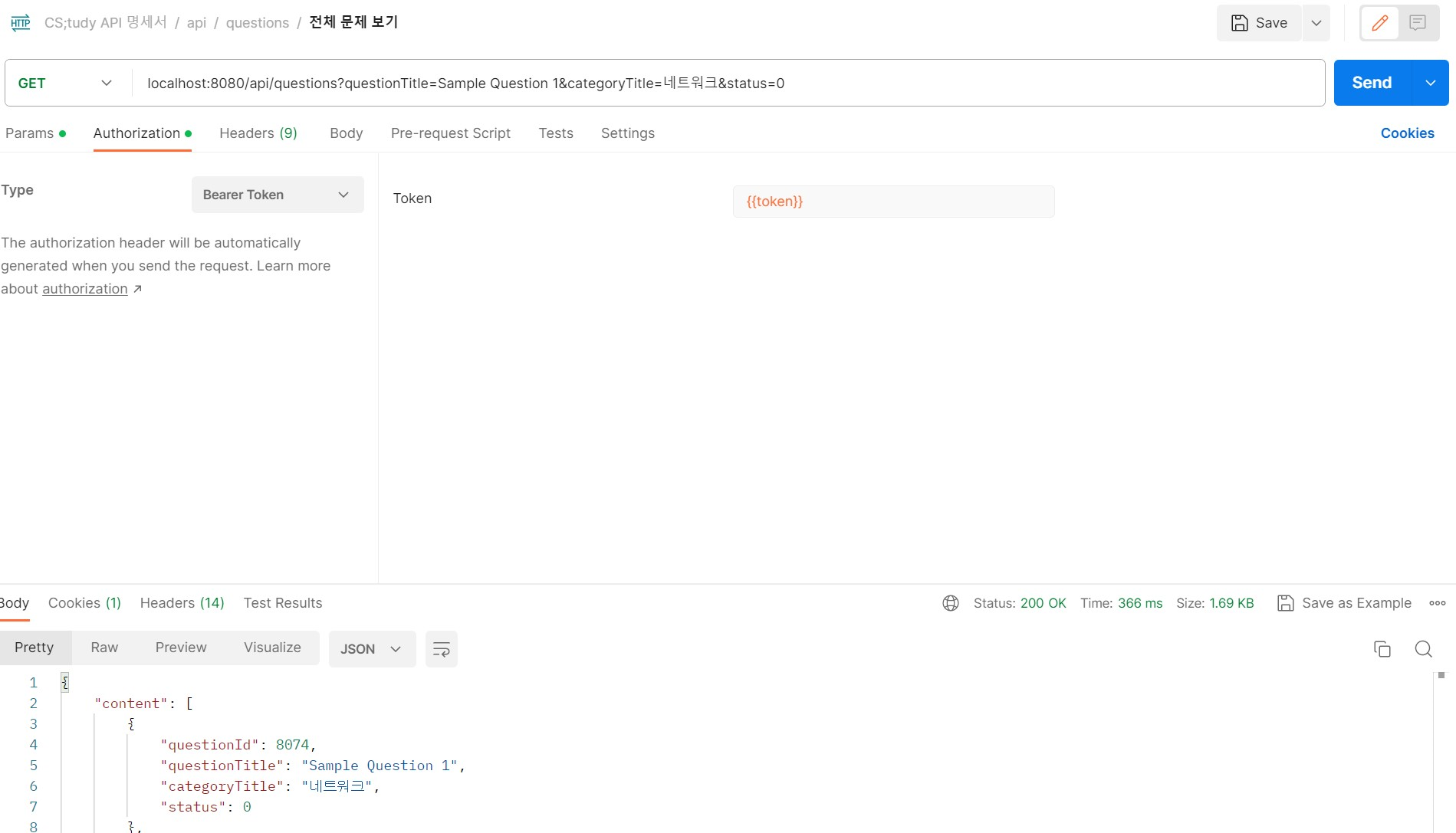
- 10,000건의 데이터를 추가하여 특정 조건을 검색을 하였을 때 366ms가 발생을 하였습니다.
리펙토링
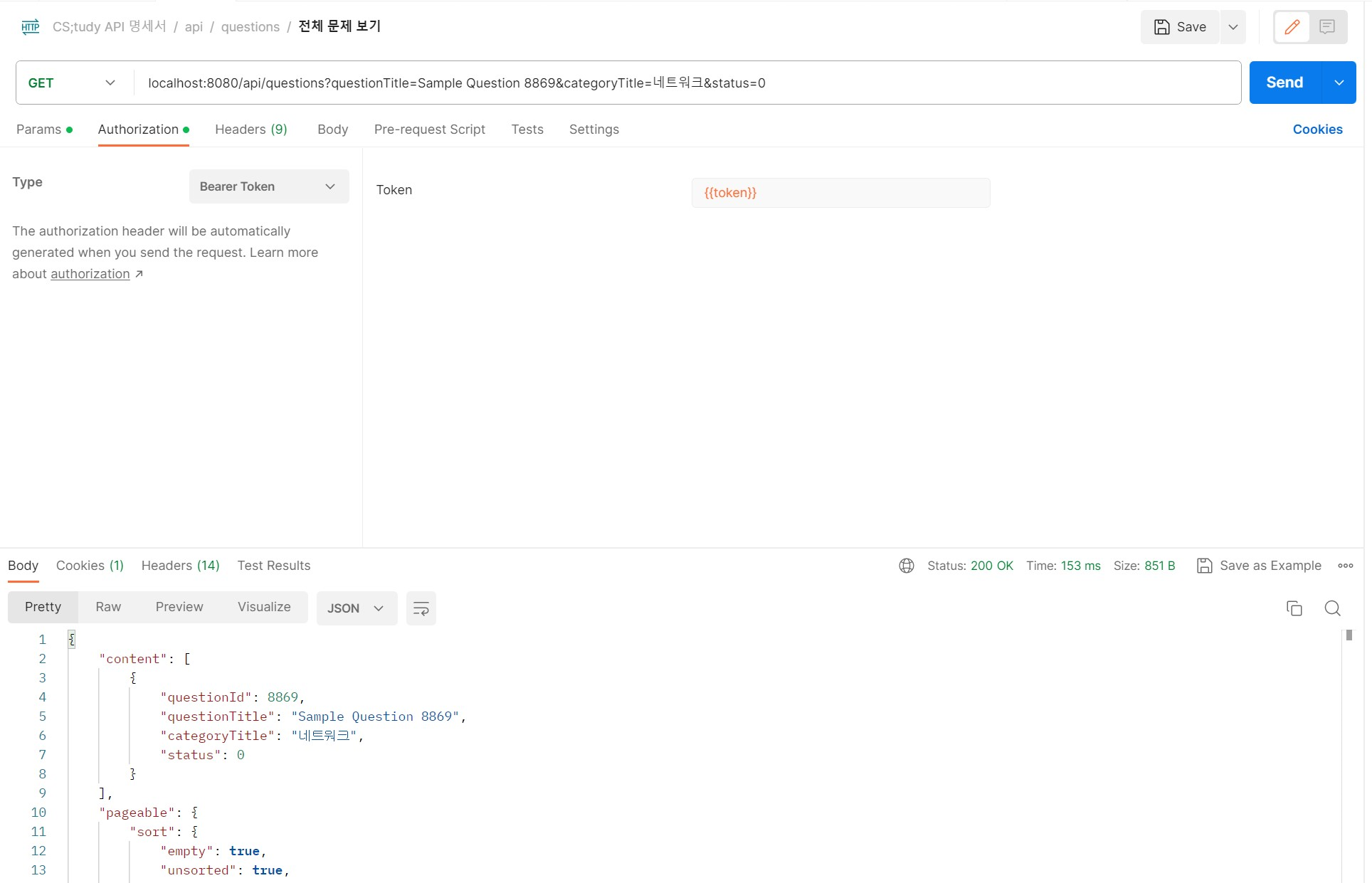
- 10,000건의 데이터를 추가하여 특정 조건을 검색을 하였을 때 153ms가 발생을 하였습니다.
성능 비교
초기 성능: 366 ms
개선된 성능: 153 ms
성능 개선 차이 = 초기 성능 - 개선된 성능
성능 개선 차이 = 366 - 153 = 213
성능 개선 백분율 = (성능 개선 차이 / 초기 성능) * 100
성능 개선 백분율 = (213 / 366) * 100 = 58.20
출처
https://velog.io/@boo105/%EC%BB%A4%EB%B2%84%EB%A7%81-%EC%9D%B8%EB%8D%B1%EC%8A%A4
https://jojoldu.tistory.com/476
