
1.서론
글을 작성하는 이유
-
백엔드 개발자로 근무하면서 학습이 필요한 부분은 매우 많다. 취준을 하면서 데이터베이스 인덱스를 공부를 하였다. 그런데 추가적으로 글을 작성하는 이유는 인덱스의 중요성 때문이다.
-
결국 병목이 발생하는 부분은 많은 데이터가 있는 데이터베이스 부분에서 자주 발생한다. 이 부분에서 인덱스를 통하여 문제를 해결할 수 있는 경우가 매우 많았고 인덱스를 적절하게 걸어야지 성능이 향상되지 잘못되게 걸면 오히려 성능이 나빠진다.
-
이번에 자세하게 인덱스를 학습하여 현업에서 일을 더 잘하기 위해서 작성한다.
2.본론
2-1.인덱스를 사용하는 이유
- 컴퓨터 구조를 살펴보면 데이터를 저장하는 공간은
디스크,메모리가 있다.
| 메모리 | 디스크 | |
|---|---|---|
| 속도 | 빠르다. | 느리다. |
| 영속성 | 전원이 공급하지 않으면 휘발 | 영속성을 지닌다. |
| 가격 | 비쌈 | 저렴하다. |
- 데이터베이스의 데이터는 디스크에 저장한다. 결국 데이터베이스의 데이터는 디스크에 저장되고 성능이 느리다. 이러한 문제점을 해결하기 위해서는 디스크 I/O를 최소화를 하는 것이다.
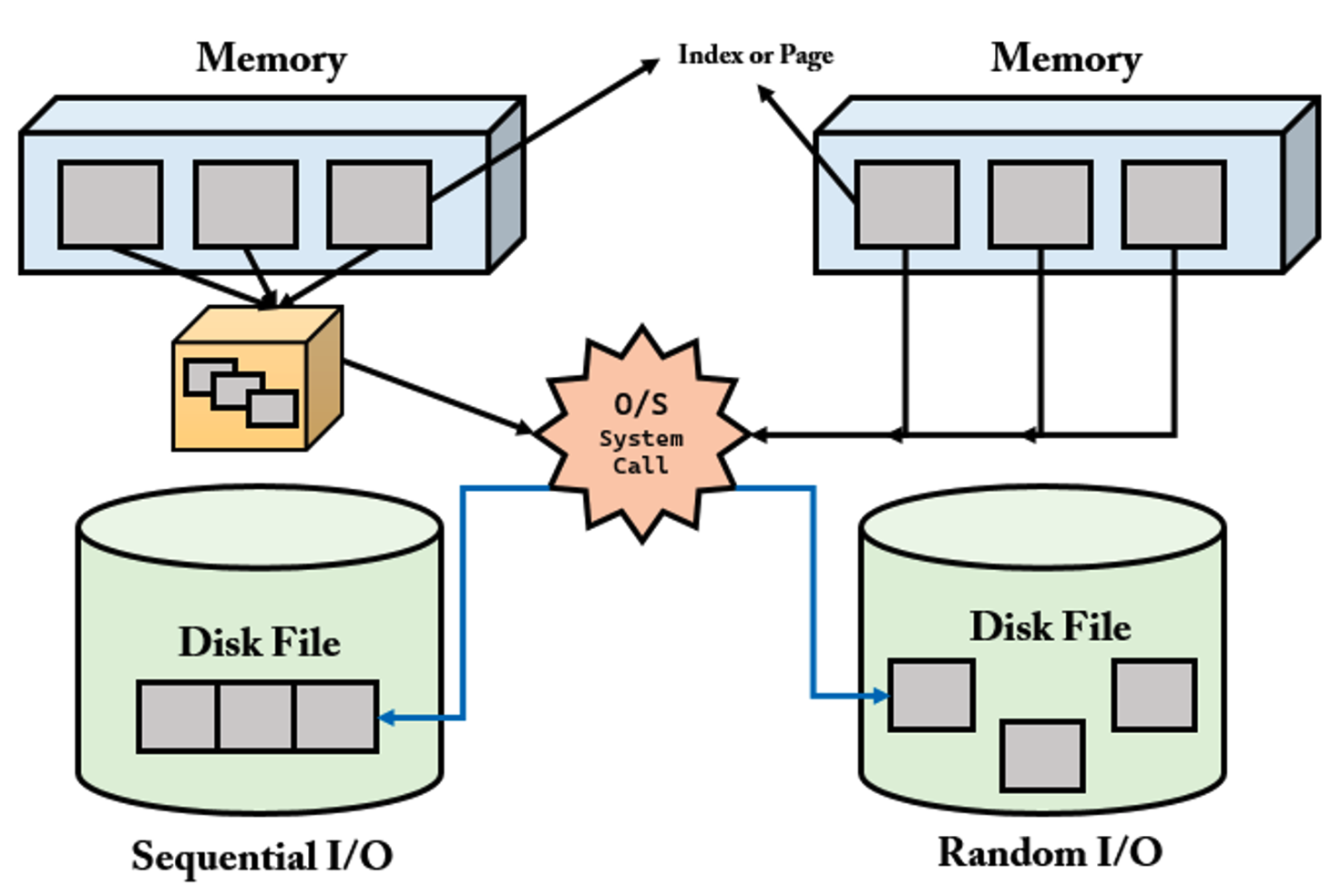
-
디스크에 접근하는 방식은 크게 2가지가 있다. 랜덤 방식은 무작위로 데이터를 가져오는 방식인 랜덤 I/O 그리고 연속된 Block의 데이터를 가지고 오는 순차 I/O가 있다.
-
대부분의 트랜잭션은 무작위 Write가 발생한다. (랜덤 I/O)
-
랜덤I/O방식과 순차I/O 방식의 공통적인 행동이 있는데 플래터를 돌려서 읽어야 할 데이터가 저장된
위치로 디스크 헤더를 이동시킨 다음 데이터를 읽는다. 하지만 여기서 차이가 나는 부분은 순차I/O는 1번의 시스템 콜을 호출하고 랜덤I/O는 3번의 호출을 하였다. -
이렇게 살펴보면 순차 I/O를 사용하면 효율이 좋겠지만 기본적으로 랜덤 I/O를 사용하고 있는 MySQL을 현실적 특성상 순차 I/O로 변경하기 어렵다.
-
그래서 랜덤 I/O를 사용을 하면서 접근 Row의 수를 줄이기 위해 인덱스를 사용한다.
2-2.인덱스 자료구조
 |  |
|---|
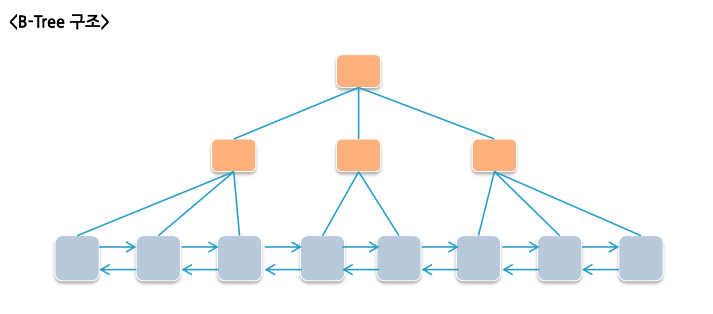
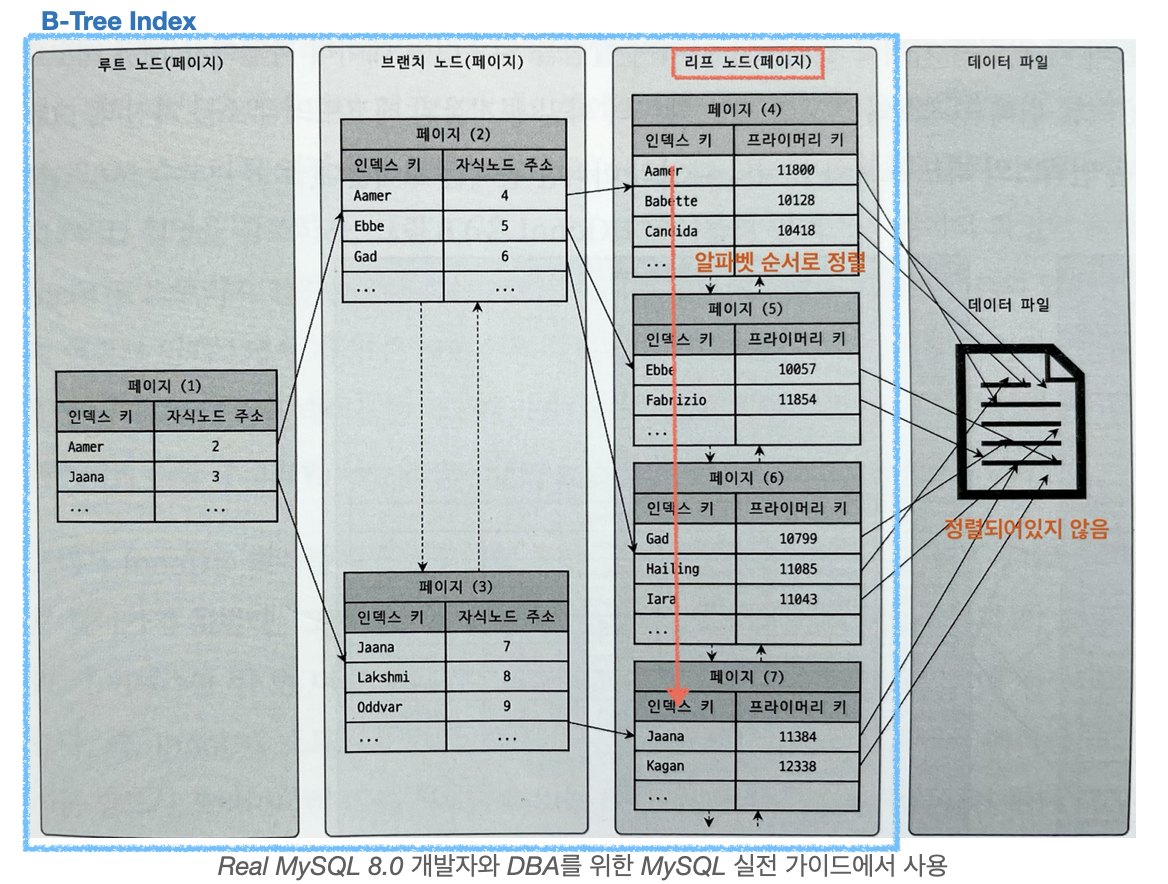
- MySQL은 기본적으로 B-Tree(Balanced Tree) 형태의 (PK, Uniqe Key, Index)로 적용이 됩니다. B-Tree는 항상 정렬된 상태로 유지하기 때문에 Write 작업을 수행 시 정렬되게 저장이 됩니다. 즉. Write 작업을 수행할 때 성능적으로 이점을 얻을 수 없지만, Read 작업을 수행을 하였을 때 성능적인 이점을 얻을 수 있습니다.
왜 인덱스는 B+Tree 자료구조를 선택을 하였는가?
- 인덱스의 핵심은 탐색, 즉. 검색 범위를 최소화 하는 것이다. 다양한 자료구조에서 인덱스의 특징에 따라서 장단점을 살펴보겠다.
- HashMap
- HashMap은 단건의 검색 속도는 O(1)으로 매우 빠른 속도를 가지고 있다. 그러나 범위 탐색은 O(N)이며 전방 일치 탐색이 불가능하다.
like 'AB%'전방 탐색을 하기 위해서는 HashMap은 키를 꺼내서 하나하나 다 비교를 하기 때문에 적절하지 않다.
- List
- List에서
정렬되지 않은 탐색은 O(N)이고정렬된 리스트의 탐색은 O(logN)이다. 결국 정렬되지 않은 리스트의 정렬 시간 복잡도는O(N) ~ O(N*logN)이 된다. - 또한 삽입 / 삭제를 하는 Write 작업을 하는데 비용이 매우 높다.
- Tree
- 트리는 차수 즉. 트리의 높이에 따라 시간 복잡도가 결정이 된다. 그래서 트리의 높이를 최소화하는 것이 매우 중요하다.
- 그렇기 때문에 한쪽으로 노드가 다 치우치지 않게 균형을 잡아주는 트리를 사용한다. B Tree
- B+Tree
- B Tree말고 일반적으로 B+Tree를 사용한다. 사실 B+Tree는 B Tree에서 진화된 버전이라고 생각하면 된다.
- B+Tree는 삽입/삭제시 항상 균형을 이룬다. ( 여기서 B는 이진이 아니라 균형을 의미한다. )
- 또한
하나의 노드가 여러 개의 자식 노드를 가질 수 있다.이를 통하여 차수를 줄일 수 있다. 이를 통하여 시간 복잡도를 낮출 수 있다. - 마지막으로 리프노드에만 데이터가 존재한다. 이거는 B Tree와 차이점으로 B Tree는 모든 노드에 데이터가 있지만
B+Tree는 리프 노드에만 데이터가 있기 때문에 연속적인 데이터 접근 시 이점을 가진다.
2-3.인덱스 종류
-
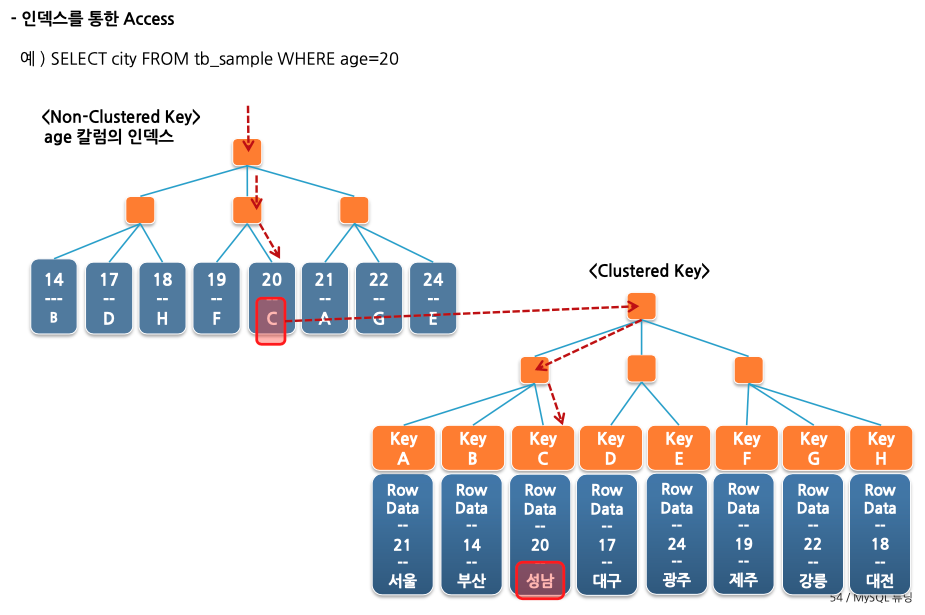
인덱스의 종류는 크게
Clustered Index / Non Clustered Index로 구분할 수 있다. InnoDB 엔진은 B+Tree 구조를 기본으로 클러스터 인덱스 구조를 가진다. 클러스터 인덱스의 리프 노드에 모든 Row 데이터를 저장한다. -
Clustered Index의 특징은 하나의 테이블에 1개만 존재한다.
PK가 있다면 PK가 Clustered가 되고 PK가 없고 Unique Key만 있다면 Clustered가 되고 모두 없다면 Hidden Key가 생성되어 Clustered가 됩니다. 이때 Hidden Key는 rowId를 의미합니다. -
그리고 MySQL에서 논클러스터 키의 차이점은 논클러스터는 클러스터의 주소를 가진다. 즉. 논클러스터 인덱스는 한번 탐색하고 그 주소를 기반으로 클러스터에 들어가 조회를 수행한다.
2-4.다중 컬럼 인덱스
- Multiple-column index는 복합 인덱스라고 알려져 있다. 이는 테이블에 여러 컬럼을 조합해서 구성되는 인덱스를 의미한다.
- 여기서
중요한 부분은 복합 인덱스는 명시된 컬럼의 순으로 정렬되어 있다는 것이다. - 복합 인덱스를 설계할 때 컬럼 순서에 따라서 쿼리의 성능 차이가 나기 때문에 설계가 매우 중요하다.
복합 인덱스에서 만약에 인덱스로 { 이름, 시력 } 으로 인덱스를 구축하면 먼저 이름 순서로 정렬 -> 시력 순으로 정렬을 한다. 이때 만약에 처음 인덱스 외에 시력으로만 조건을 걸어서 쿼리를 날리면 인덱스 풀 스캔이 발생한다.
효과적인 인덱스 디자인 전략
-
일반적으로 복합 인덱스를 설계하는 기준은
카디널리티입니다. 카디널리티가 높은 컬럼을 선행 컬럼으로 선정하는 것이다. 하지만 무작정 카디널리티만 높다고 인덱스를 설정하면 안된다. -
자주 사용하는 쿼리가 무엇인지, 조인에도 인덱스가 사용하는지, 선행 컬럼이 범위 기반의 쿼리로 많이 이용하는가
실제 테스트
create table orders(
order_id int auto_increment,
customer_id int,
order_date date,
product_id int,
quantity int,
status varchar(50),
primary key(order_id)
);import csv
import random
from datetime import datetime, timedelta
# 데이터 생성 함수
def generate_order_data(record_count):
statuses = ['배송 중', '배송 완료', '주문 취소']
start_date = datetime(2023, 1, 1)
end_date = datetime(2023, 12, 31)
for order_id in range(1, record_count + 1):
customer_id = random.randint(1, 10000)
order_date = start_date + timedelta(days=random.randint(0, (end_date - start_date).days))
product_id = random.randint(1, 1000)
quantity = random.randint(1, 10)
status = random.choice(statuses)
yield [customer_id, order_date.strftime('%Y-%m-%d'), product_id, quantity, status]
# CSV 파일 저장
def save_to_csv(filename, data):
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['customer_id', 'order_date', 'product_id', 'quantity', 'status'])
writer.writerows(data)
# 메인 실행
if __name__ == "__main__":
record_count = 1000000 # 100만 건
filename = 'orders_data.csv'
data = generate_order_data(record_count)
save_to_csv(filename, data)
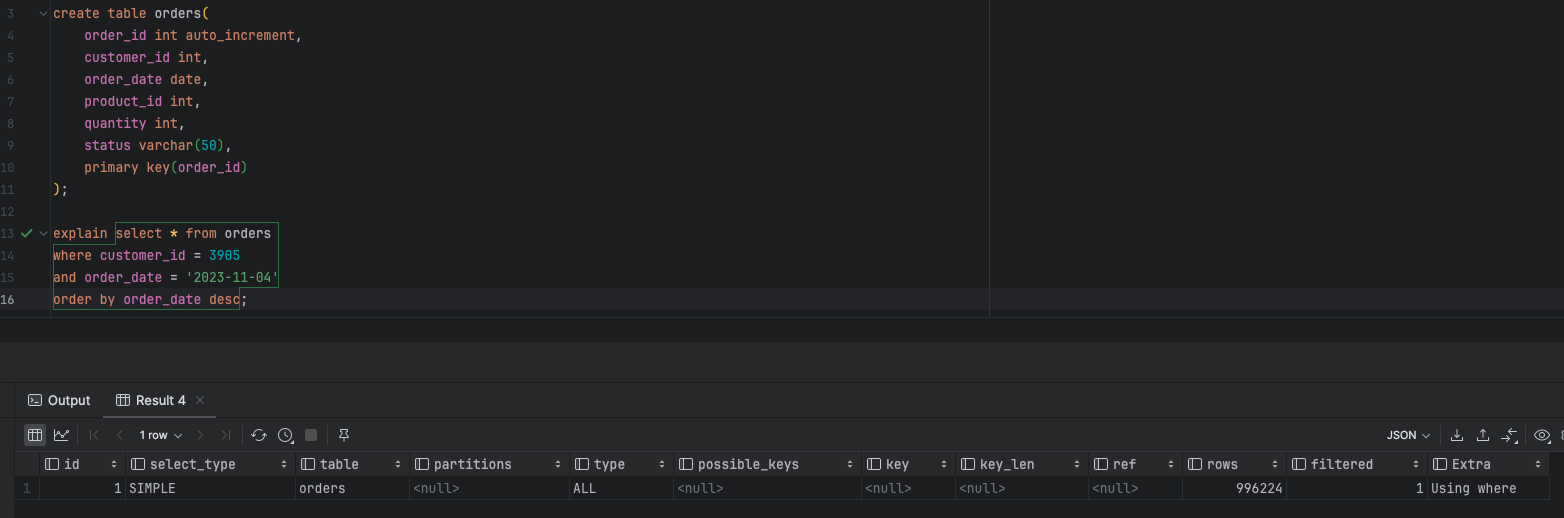
print(f"{filename}에 {record_count}건의 데이터가 저장되었습니다.")- 다음 구조를 가지는 테이블에 10,000건의 데이터를 적재하고 customer_id와 order_date에 조건을 걸어 조회를 하였을 때 테이블 풀 스캔을 하고 있는 사실을 알 수 있다. 현재 인덱스가 없기 때문인데 이제 인덱스를 추가를 하겠습니다.
create index idx_order_date_customer_id on orders(order_date, customer_id);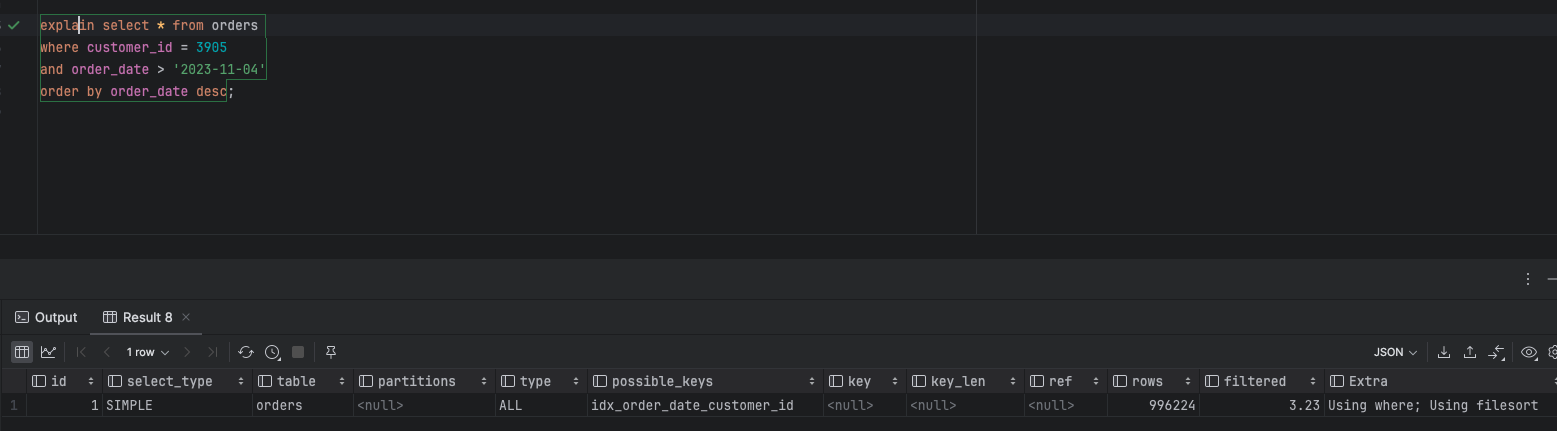
- 일단 선행 컬럼을 order_date로 설정하고 customer_id를 후행 컬럼으로 만들고 조회를 하면 테이블 full scan을 피했지만 rows와 filtered를 보면 996224의 데이터를 탐색하고 이 중에서 3.23%만 유효하다고 나옵니다. 일단 full scan을 피했지만 아직 완전한 쿼리가 아니라고 생각합니다.

- 다음은 customer_id를 선행으로 만들고 실행계획을 살펴보면 6개의 row를 100% 유효하게 탐색을 하는 것을 볼 수 있다. 이를 통해 알 수 있는 부분은 선행 컬럼의 선택에 따라서 성능에 유효한 영향을 줄 수 있다고 알 수 있습니다.
카디널리티를 알 수 있는 쿼리
analyze table orders update histogram on customer_id, order_date with 100 buckets;
use information_schema;
select * from COLUMN_STATISTICS
where table_name = 'orders';- 위에 쿼리를 통하여 buckets를 구할 수 있고 이를 통하여 카디널리티를 확인할 수 있다. 현재 예시를 살펴보면 customer_id의 buckets에서 각 분포도의 3번째 값을 살펴보면 알 수 있다.
저는 개인적으로 =(동등 조건)과 같은 조건은 선행으로 배치하고 < > , Between, order by, group by의 조건은 후행으로 자주 배치를 합니다.
2-5.커버링 인덱스
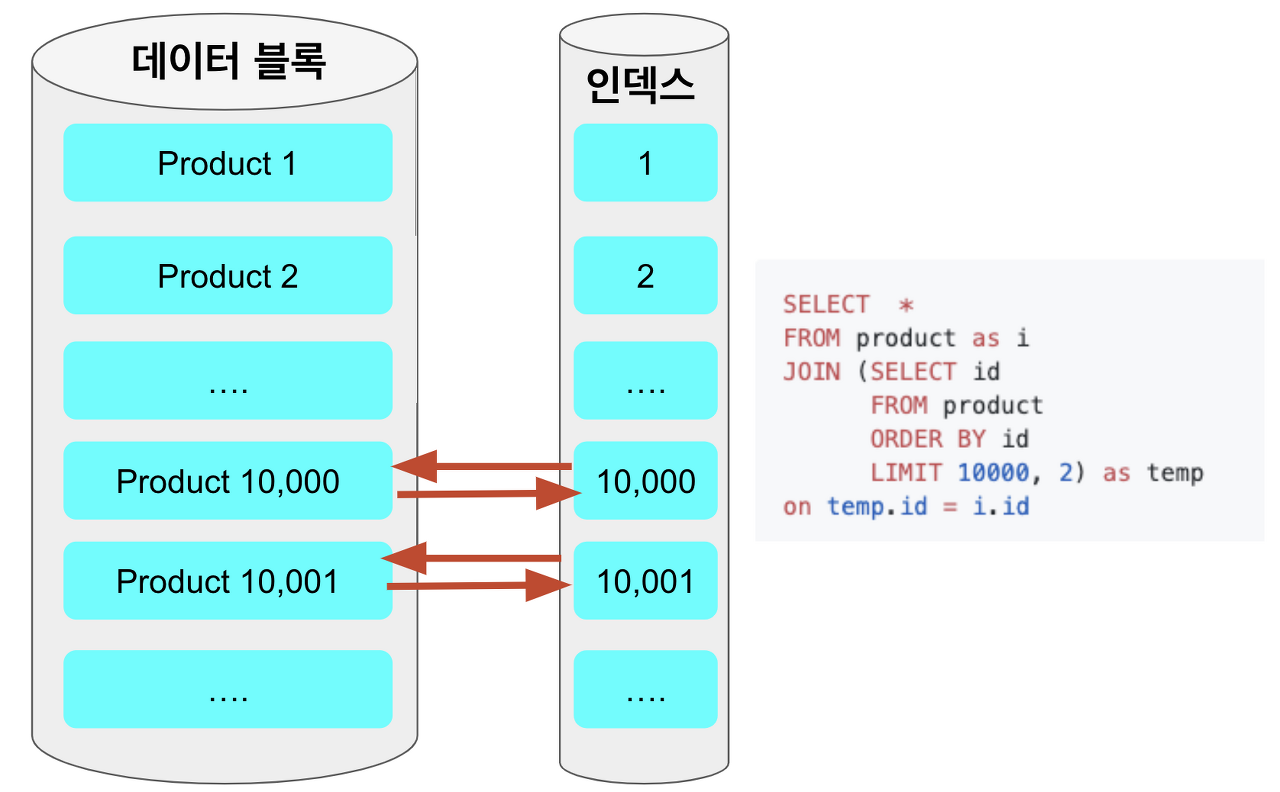
- 커버링 인덱스란 읽기 쿼리 성능을 높히기 위해 사용하는 방식입니다. 인덱스를 사용하여 쿼리를 처리할 때 인덱스에 있는 컬럼만드로 충분하지 않으면 실제 레코드에 접근합니다. 하지만 커버링 인덱스를 사용하면 테이블 레코드에 접근하는 방식 없이 인덱스 수준에서만 쿼리를 처리할 수 있다.
커버링 인덱스는 언제 사용하나요??
- 커버링 인덱스를 사용하는 경우는 다음과 같습니다.
- 특정 컬럼을 자주 조회를 해야되는 상황 : 특정 컬럼 때문에 테이블에 접근하는 것이 비용이 크게 느껴질 때 유용하다.
- 조인 연산 비용 줄이기 : 여러 테이블을 연결할 때 발생하는 비용을 줄일 수 있다.
- 일기 성능의 향상이 필요한 경우 : 인덱스 레벨에서만 필터링하여 읽기 성능 향상이 필요한 경우 적용할 수 있습니다.
커버링 인덱스를 무조건 사용하는게 좋나요?? Trade Off는
- 물론 성능을 향상 시키는 장점이 있어서 처음 이 키워드를 접하였을 때 혹~~!! 하였습니다. 하지만 커버링 인덱스를 적용하는데 트레이드 오프가 있습니다.
- 인덱스 크기 : 인덱스는 그냥 생성이 되는 것이 아닙니다. 인덱스가 커지면 인덱스 블록에 들어갈 수 있는 데이터의 수는 줄어듭니다.
- 쓰기 비용 : 인덱스에 추가된 컬럼이 자주 업데이트 되는 경우, 추가적인 쓰기 비용이 발생을 합니다.
쓰기 비용이 증가하는 이유는 B+Tree를 사용하기 때문입니다. 이 자료구조를 사용하면 데이터를 정렬되게 저장하기 때문에 Write 작업을 수행하면 노드의 이동이 발생을 합니다.
- 컬럼 크기 : 크기가 큰 컬럼은 인덱스로 추가하기 비효율적입니다.
- 카디널리티 : 카디널리티가 낮은 컬럼을 인덱스로 추가할 경우, 읽기 성능이 향상하지 않을 수 있습니다.
실제 테스트
- 테스트를 위한 코드는 위에 복합 인덱스를 하는 테이블과 똑같이 진행을 하겠습니다.
- 현재 인덱스는
customer_id,order_date에 걸려있다. 이때 살펴보면 좋은 부분은 조회하는 컬럼, where, group by가 있다.
explain select customer_id, order_date
from orders
where customer_id = 2565
group by customer_id, order_date
order by order_date desc
limit 10[
{
"id": 1,
"select_type": "SIMPLE",
"table": "orders",
"partitions": null,
"type": "ref",
"possible_keys": "idx_customer_order_date",
"key": "idx_customer_order_date",
"key_len": "5",
"ref": "const",
"rows": 106,
"filtered": 100,
"Extra": "Backward index scan; Using index"
}
]-
해당 실행계획을 살펴보면
Using Idex를 살펴볼 수 있다. 이것은 커버링 인덱스를 의미한다. 이 쿼리가 왜 커버링 인덱스로 조회된 이유는 조회하는 컬럼, group by, where절이 모두 복합 인덱스로 이루어져 있고 where절에서 customer_id로 조회하여 복합 인덱스의 선형 인덱스로 적용되었기 때문이다. -
이제 조회하는 컬럼, where, group by를 인덱스와 다르게 하였을 때 발생하는 문제에 대해서 알아보겠다.
조회하는 컬럼
explain select customer_id, order_date, product_id
from orders
where customer_id = 2565
order by order_date desc
limit 10;- 해당 쿼리를 살펴보면 현재 인덱스
customer_id,order_date가 있는데 여기서는product_id가 추가가 되었습니다. 인덱스에서는 product_id에 대한 정보가 없기 때문에 결국 테이블에 접근하여 관련된 정보를 얻어와야 합니다. 결국 커버링 인덱스가 성립하지 못합니다.
[
{
"id": 1,
"select_type": "SIMPLE",
"table": "orders",
"partitions": null,
"type": "ref",
"possible_keys": "idx_customer_order_date",
"key": "idx_customer_order_date",
"key_len": "5",
"ref": "const",
"rows": 106,
"filtered": 100,
"Extra": "Backward index scan"
}
]where
- 커버링 인덱스는 인덱스으로 결과를 처리하는 경우이다. 이때 복합 인덱스의 경우에는 처음 인덱스 이외에 후행 인덱스로 조회를 하였을 때 방식이 다르다. Mysql 8.0으로 넘어가면서 Skip scan이 생겨서 더욱 인덱스의 탐색에 도움을 주었다.
explain select customer_id, order_date
from orders
where customer_id = 2565
order by order_date desc
limit 10;explain select customer_id, order_date
from orders
where order_date = '2023-01-01'
# where product_id = 1
order by order_date desc
limit 10;
인덱스 스킵 스캔
MySQL 8.0 버전부터는 다중 칼럼 인덱스에서 옵티마이저가 특정 칼럼 인덱스를 건너 뛰어서 검색할 수 있도록하는 인덱스 스킵 스캔(index skip scan) 최적화 기능이 도입되었습니다. 이를 통해 인덱스를 통한 검색의 용도가 더 넓어졌습니다.
WHERE + GROUP BY + ORDER BY
- 결론부터 말하면
WHERE + ORDER BY 의 경우엔 WHERE가 동등일 경우엔 ORDER BY가 나머지 인덱스 컬럼만 있어도 인덱스를 탈 수 있으나 GROUP BY + ORDER BY 의 경우엔 둘다 인덱스 컬럼을 탈수있는 조건이어야만 합니다.
2-6.형변환

- 파란색인 컬럼은 단일 컬럼 인덱스가 설정이 되어져 있습니다. 그 전에 형번환에 우선순위에 대해서 설명하겠습니다.
- 문자와 숫자가 만나면 문자가 숫자로 형변환됩니다.
- 문자와 날짜는 양쪽으로 형변환됩니다.
- 형변환은 유리한 방향으로 이루어집니다. 즉, 데이터를 더 큰 범위의 형식으로 변환하려고 합니다.
- 변수쪽이 형변환되면 인덱스를 탈 수 없게 됩니다.
- 이러한 우선순위를 고려하여 쿼리를 작성해야 한다. 형변환이 발생하며 인덱스를 탈 수 있는지 여부를 판단할 수 있다.
# 1. 문자는 숫자로 형변환이 되어서 인덱스 스캔을 합니다.
select * from order where order_no = '1';
# 1. order_status_cd 쪽이 문자에서 숫자로 형변환이 되어서 인덱스를 타지 않는다.
select * from order where order_status_cd = 10
# 2. 문자형은 date/time형태로 형변환을 하여 인덱스로 활용할 수 있습니다.
select * from order where order_ymdt = '2024-03-24';
# 2. 상수쪽이 datetime으로 형변환이 되므로 인덱스를 활용합니다.
select * from order where ordr_ymdt = cast('2024-03-24' as datetime);
# 컬럼을 substring으로 형변환이 되었기 때문에 인덱스를 탈 수 없다. 이 방식은 between을 통해 개선할 수 있습니다.
select * from order where substring(ordr_ymdt , 1, 4) = '2023' and substring(ordr_ymdt , 6, 2) = '02';2-7.Null의 인덱싱
- MySQL에서는 NULL 값도 인덱싱 처리가 가능합니다. 이러한 처리를 통해 IS NULL 조건으로 검색 시에도 인덱스 range scan을 통해 빠르게 처리할 수 있습니다.
먼저, 테이블의 NULL 값을 인덱싱하기 위해서는 추가적인 공간이 필요합니다. 일반적으로 NULL 값을 인덱싱하기 위해서는 1bit의 추가 공간이 필요하며, 이는 인덱스 내에서 NULL 값을 표현하기 위한 용도로 사용됩니다.
예를 들어, 다음과 같이 테이블을 변경하여 NULL 값을 인덱싱할 수 있습니다.
ALTER TABLE order MODIFY COLUMN age INT NULL;위와 같이 테이블의 컬럼 속성을 nullable로 변경함으로써 NULL 값을 인덱싱할 수 있게 됩니다.
그 후, 예를 들어 다음과 같이 NULL 값에 대한 쿼리를 수행할 때에도 인덱스를 활용하여 빠르게 처리할 수 있습니다.
EXPLAIN SELECT * FROM order WHERE age IS NULL;위의 쿼리를 수행하면 인덱스 range scan을 통해 빠르게 NULL 값을 찾을 수 있습니다.
하지만, NULL 값을 가지지 않는 NOT NULL 컬럼에 대해서는 NULL 비교를 수행하는 쿼리는 불가능한 비교에 해당하므로 MySQL은 스키마 정보만으로 빠르게 Impossible WHERE임을 판단하여 처리합니다.
따라서, MySQL에서는 NULL 값을 인덱싱 처리할 수 있으며, 이를 통해 NULL 값을 가진 레코드를 효율적으로 조회할 수 있습니다.
2-8. IN절 인덱스 처리
-
MySQL에서 인덱싱된 컬럼에 대한 IN 쿼리 검색은 MySQL에 내부적으로 UNION 방식으로 바꾸어서 처리를 합니다.
-
위에 예제를 기반으로 관련 쿼리를 만들겠습니다.
create index idx_order_customer_order on orders (customer_id, order_date);
explain select * from orders where customer_id in ('2911','6947') and order_date > '2023-01-01';- 해당 쿼리는 customer_id, order_date로 이루어진 인덱스에 IN으로 인덱싱 조회를 하는 쿼리 입니다. 실제 이것의
explain. analyze를 통해 살펴보면 실제로 실행된 쿼리는 다음과 같습니다.
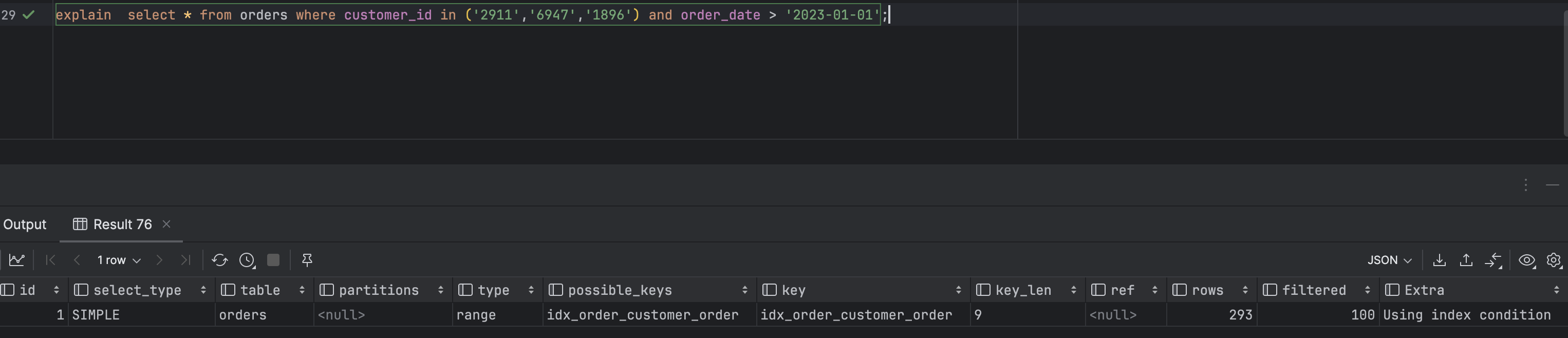
select * from orders customer_id = 2911 AND '2023-01-01' < order_date
union
select * from orders customer_id = 6947 AND '2023-01-01' < order_date2-9. 인덱스를 안타는 쿼리
- 위에 내용을 보면 인덱스에 대해서 대표적인 기능에 대해서 살펴봤습니다. 어느정도 인덱스에 대해서 학습을 하였는데 마지막으로 쿼리를 작성하면서 인덱스를 안타는 쿼리에 대해서 대표적인 부분만 설명을 하겠습니다.
1. 함수나 연산자를 사용
- 인덱스가 있는 열에 함수, 또는 연산을 수행하는 경우 데이터베이스는 인덱스를 사용하지 못한다. 또한 where절에 컬럼을 수정하는 경우 인덱스를 탈 수 없습니다.
select * from orders where upper(status)) = 'SHIPPED';
explain select * from orders where year(order_date) = 2023;
explain select * from orders where customer_id +1 = 2565;2. LIKE문 검색에서 와일드카드의 위치
- LIKE 절에서 와일드카드 %가 뒤에 있는 경우, 인덱스를 활용할 수 있지만, %가 앞이나 중간에 있을 경우는 인덱스를 활용할 수 없습니다. 이는 인덱스의 B-트리 구조와 LIKE 절의 검색 패턴이 일치하지 않기 때문입니다.
# 인덱스 적용
select * from orders where customer_name = 'John%';
# 인덱스 적용 X
select * from orders where customer_name = '%John';
# 인덱스 적용 X
select * from orders where customer_name = '%John%';3. OR절을 사용
- OR 절을 사용하는 경우 인덱스를 활용할 수 없습니다. OR 절은 여러 개의 조건 중 하나라도 참이면 전체 조건을 참으로 판단하므로 데이터베이스가 모든 가능성을 검사하고 결과를 결합해야 합니다. 따라서 최적의 OR 조건을 뽑기 어려워 인덱스를 사용할 수 없습니다.
# 인덱스 적용 X
select * from orders where customer_id = '2911' or order_date > '2023-01-01';4. 테이블 전체를 반환
- 테이블의 전체 레코드를 반환하는 경우에는 인덱스를 사용할 필요가 없습니다. 데이터베이스가 모든 레코드를 반환해야 하므로 인덱스를 사용할 이유가 없습니다.
select * from orders;5. 컬럼의 자료형이 다른 검색
- 컬럼의 자료형이 다른 경우 비교하는 쿼리를 실행할 때 인덱스의 성능이 저하될 수 있습니다. 인덱스는 데이터의 값을 기반으로 정렬되어 있기 때문에 자료형 변환이 필요할 경우 성능이 저하될 수 있습니다.
- 문자와 숫자가 만나면 문자가 숫자로 형변환이 된다. 이때 문자에서 숫자로 형변환이 되지 않는 경우 인덱스를 타지 않는다.
select * from order where order_status_cd = 107. IN 연산자를 사용한 검색에서 IN 목록의 개수가 많은 경우
- IN 연산자를 사용한 검색에서 IN 목록의 개수가 많을 경우 인덱스를 사용하지 않고 수행할 가능성이 높습니다. 이 경우 JOIN을 사용하여 인덱스를 효율적으로 사용할 수 있습니다.
SELECT * FROM order WHERE id IN (1, 2, 3, ..., 10000);