
제 스스로 정리할겸 머신러닝의 종류에 대해서 서술하려합니다.
(최근에 백엔드 공부를 하다보니 정리 이렇게라도 정리 안해두면 까먹을거같아요...🥔)
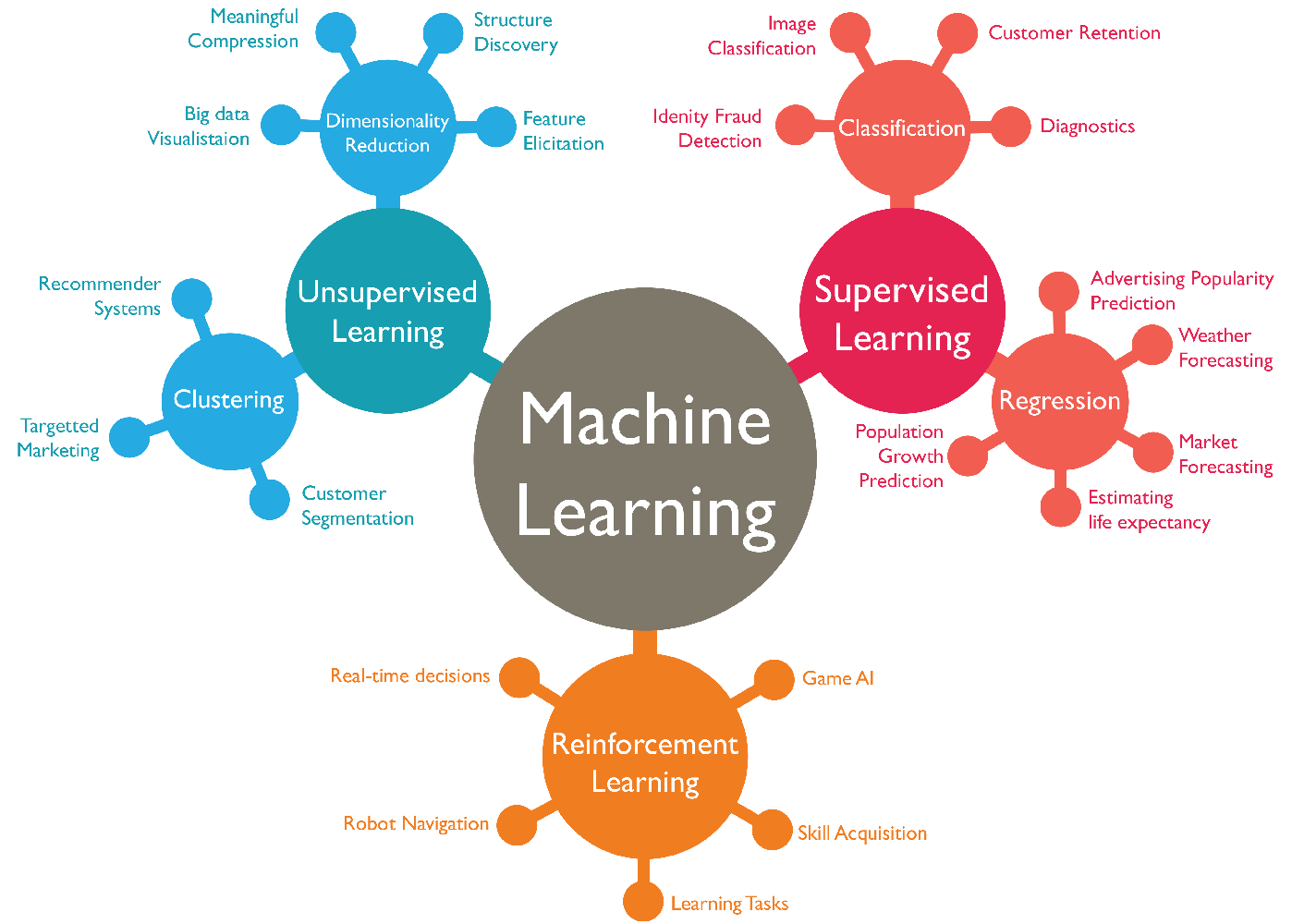
머신러닝의 기법은 아래와 같이 크게 세가지 로 분류할 수 있습니다.
- 지도학습 (Supervised Learning)
- 비지도학습 (Unsupervised Learning)
- 강화학습 (Reinforcement Learning)
각각의 종류에 대해 포스팅 해보겠습니다 😎
이번 포스트에서는 지도학습(Supervised Learning) 에 대해서 서술해 보겠습니다.
지도학습 (Supervised Learning)
지도학습 기법에는 우리가 예측하고자 하는 값에 대한 과거 데이터를 모델이 보고 학습하는 기법입니다.
따라서 지도학습에는 훈련 데이터에 레이블(Lable) 또는 타겟(Target)이라는 정답지가 포함되어있고, 모델은 이를 통해 예측과 분류를 합니다.
여기서 지도학습을 해결하려는 문제에 따라서 세부적으로 분류(Classification)와 회귀(Regression) 로 나눠볼 수 있습니다.
분류(Classification)
분류는 전형적인 지도학습의 Task 중 하나입니다.
이해하기 쉽게 예를 들어보겠습니다.
메일 스팸 필터프로그램과 같이 현재 온 메일이 스팸메일인지 아닌지 분류(Classification) 를 할 수 있게 과거에 스팸/비스팸 메일으로 분류가 된 데이터 즉, Lable된 데이터를 모델에게 학습시키게 됩니다.
모델은 데이터를 토대로 학습을 한 뒤 새로운 이메일을 학습한 내용으로 두 개의 범주(Category)인 스팸/비스팸 중 어디에 속하는지 예측하게 됩니다.
이처럼 개별적으로 Lable이 된 데이터를 학습 시키는 것을 지도 학습(Supervised Learning)의 분류(Classification)라고 합니다.
예로든 두 가지의 클래스를 분류하는 방식을 이진 분류(Binary Classification) 합니다. Binary Classification 외에도 두개 이상의 클래스를 분류하는 것을 목표로 하는 다중 분류(Multiclass Classification) 도 있습니다.

이 또한 예로 들어보자면 가장 직관적으로 알기 편한 예시가 손글씨(MNIST DataSet)이고, 아마 처음 공부하시는 분들이 가장 먼저 접하는 DataSet이라 생각합니다.
(약간 프로그래밍 언어를 배울 때의 Hello, World를 출력해보는 느낌입니다.)
처음 보시는 분들을 위해서 조금 더 설명을 해보자면 MNIST DataSet은 간단한 Computer Vision DateSet으로 위의 사진과 같이 사람이 손으로 쓴 숫자(0 ~ 9) 글씨의 이미지 데이터로 약 60,000 개의 Train Data Set과 10,000개의 Test Data Set으로 구성되어 있습니다.
앞서 문제마다 해결 방식에 따라 접근 방식이 나뉜다고 서술했는데, 이와 같은 문제를 마주치면 이전과 같은 Binary Classification 방식으로는 모든 숫자를 분류해 낼 수 는 없을것 같은 느낌적인 느낌이 오시죠?!
이럴 때 쓰이는 문제 해결 방법이 Multiclass Classification 입니다.
앞서 설명한 MNIST DataSet으로 모델에게 학습을 시키면 숫자(0 ~ 9)가 가지는 특징(feature)을 보고 학습합니다.
학습된 모델은 새로운 손글씨 숫자 이미지가 들어오면 기존에 학습한 데이터를 토대로 새로운 데이터의 특징을 보고 분류를 하게 됩니다.
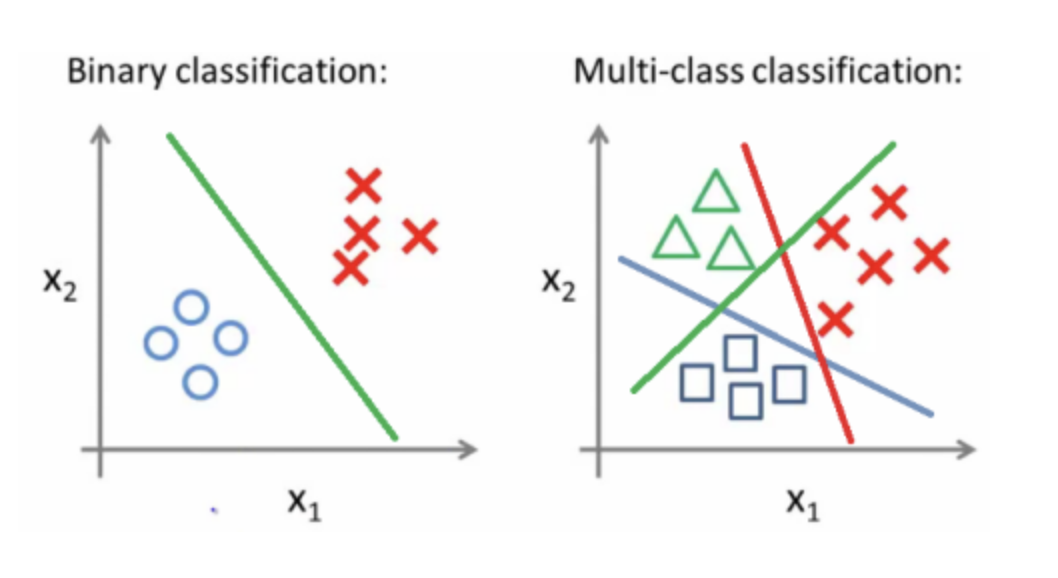
이해를 돕기위해서 Binary Classification과 Multiclass Classification의 시각화된 이미지도 첨부해두겠습니다 :)
회귀(Regression)
앞서 서술한 분류(Classification)은 연속되지 않은 즉 범주형 순서가 없는 Lable을 모델에게 학습시키고 새로운 Data의 Lable을 맞추는 문제였습니다.
하지만 회귀(Regression) 은 연속적인 출력 값을 예측하는 문제입니다.
Regression은 예측 변수(Predictor Variable) 와 연속적인 반응 변수(Response Variable) 이 주어졌을 때 두 변수 사이의 관계를 찾고 학습합니다. 그리고 새로운 데이터가 들어오면 앞서 데이터로 학습한 변수간의 관계를 통해서 새로운 데이터의 출력 값을 예측할 수 있습니다.
마찬가지로 이해를 돕기 위해서 회귀(Regression)의 예를 들어 보겠습니다.
최근 증권어플에서 많이 볼 수 있는 주식 가격 예측을 예로 들어보겠습니다.
주식 Data가 주어졌고, 저희는 미래의 주식 가격을 예측해야되는 문제입니다.
DataSet에는 저희가 최종적으로 예측해야하는 과거부터 현재까지의 주식 가격 Data와 여러 특징을 가진 Column 들이 있습니다.
Column들 중 당일 발행된 뉴스의 총 개수가 담겨있는 Column과 주식 가격과의 연관성이 크다고 가정하겠습니다.
두 변수 사이의 관계가 높다면 모델에게 당일 발행된 뉴스의 총 개수와 주식 가격 데이터로 훈련 데이터를 만든 뒤 모델에게 학습을 시키게 되면 다음날 발행될 뉴스의 총 예상 개수를 모델에게 알려주면 주식의 가격을 예측하게됩니다.
(예시일 뿐입니다... 저렇게 단순하게 되지 않아요... 😂...)
Note 회귀는 1886년 프란시스 갈톤(Francis Galton)이 쓴 “Regression towards Mediocrity in Hereditary Stature”에서 유래되었습니다. 갈톤은 사람 키의 분산이 시대가 흘러도 증가하지 않는 생물학적 현상을 설명했습니다. 그는 부모의 키가 자녀에게 전달되지 않는 것을 관찰했습니다. 오히려 자녀 키는 인구 전체 평균으로 회귀합니다.
위는 선형회귀(Linear Regression) 의 간단한 개념을 설명해주고 있습니다!
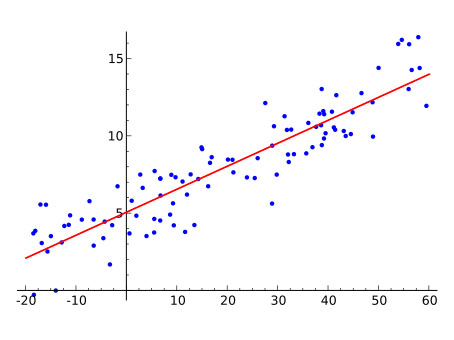
선형회귀(Linear Regression) 는 입력 값(input)과 맞춰야 할 출력(target)이 주어지면 모든 샘플들의 가장 중간 거리가 되는 선을 그을 수 있게 됩니다.
(이는 일반적으로 샘플들과의 평균 제곱거리를 이용해서 구합니다.)
이렇게 사전 Train Data를 통해 학습한 직선의 기울기와 절편을 통해서 새로운 데이터의 출력 값을 예측할 수 있습니다.
이외에도 회귀에는 많은 종류가 있습니다.
- 선형회귀
- 부분회귀
- 정규화 선형회귀
- etc...
모든 걸 다 담기에는 양이 너무많기 때문에... Pass하겠습니다..

지도학습에 이용되는 알고리즘의 대표적인 종류는 아래와 같습니다!
- 랜덤 포레스트(Random Forests)
- 결정 트리(Decision Trees)
- K-Nearest Neighbors / KNN)
- 서포트 벡터머신(Support Vector Machines / SVC)
- 선형회귀(Linear Regression)
- 로지스틱 회귀(Logistric Regression)
- ⭐️신경망(Newral Networks)⭐️
신경망(Newral Networks) 을 이용한 DeepLearning을 Mushine Learning과 전혀 다른 방식이라고 생각하실 수 있는데 이 부분도 나중에 포스팅해보겠습니다 🤖
📝 Summery
- 지도학습 (Supervised Learning)
- 분류(Classification)
- 이중 분류
- 다중 분류
- 회귀(Regression)
- 선형 회귀
- 부분 회귀
- 정규화 선형회귀
- etc...
- 분류(Classification)
끗
