코틀린 코루틴 2부 -2
취소
코틀린 코루틴에서 아주 중요한 기능 중 하나는 바로 취소입니다.
취소는 아주 중요한 기능입니다. DB 작업 등 작업이 취소되면 개발자는 자원을 해제해야 합니다. 그렇기에 단순히 스레드를 죽여서 동작을 중지하는 것은 자원을 해제할 수 없기에 최악의 방법입니다.
그렇다면 코루틴에서는 어떻게 취소할 수 있는지 한 번 살펴보겠습니다.
기본적인 취소
Job 인터페이스는 취소하게 하는 cancel 메서드를 가지고 있습니다.
- 호출한 코루틴은 첫 번째 중단점(delay 등등)에서 Job을 끝냅니다.
- Job이 자식을 가지고 있다면 그들 또한 취소됩니다. 하지만 부모는 영향을 받지 않습니다.
- Job이 취소되면, 취소된 Job은 새로운 코루틴의 부모로 사용될 수 없습니다. 취소된 Job은
Cancelling상태가 되었다가Cancelled상태로 바뀝니다.
suspend fun main(): Unit = coroutineScope {
val job = launch {
repeat(1_000) { i ->
delay(200)
println("Printing $i")
}
}
delay(1100)
job.cancel()
println("Cancelled successfully")
}
// Printing 0
// Printing 1
// Printing 2
// Printing 3
// Cancelled successfully
// Printing 4이때, job.join()을 뒤에 추가하면 코루틴이 취소를 마칠 때까지 중단되어 경쟁 상태가 발생하지 않습니다.
suspend fun main(): Unit = coroutineScope {
val job = launch {
repeat(1_000) { i ->
delay(200)
Thread.sleep(100) // 오래 걸리는 연산이라 가정합니다
println("Printing $i")
}
}
delay(1100)
job.cancel()
job.join()
println("Cancelled successfully")
}
// Printing 0
// Printing 1
// Printing 2
// Printing 3
// Printing 4
// Cancelled successfully
kotlinx.coroutines 라이브러리는 cancel과 join을 함께 호출할 수 있는 간단한 방법으로 cancelAndJoin이라는 편리한 확장 함수를 제공합니다.
// 지금까지 본 것 중 가장 명확한 함수 이름입니다
public suspend fun Job.cancelAndJoin() {
cancel()
return join()
}해당 방법은 job에 딸린 수 많은 코루틴을 한번에 취소할 때 자주 사용됩니다.
안드로이드를 예로 들면, 사용자가 뷰 창을 나갔을 때 뷰에서 시작된 모든 코루틴을 취소하는 경우입니다.
class ProfileVievModel : ViewModel() {
private val scope =
CoroutineScope (Dispatchers.Main + SupervisorJob())
fun onCreate() {
scope.launch { loadUserData() }
}
override fun onCleared() {
scope.coroutinecontext.cancelChildren()
}
// ...
}이때, cancel() 메서드를 호출하면 CancellationException 신호를 보냅니다
cancel() 메서드의 로직을 좀 더 구체적으로 살펴보면 다음과 같습니다.
cancel()이 이루어지는 과정
-
신호 보내기: job.cancel() 호출
- job의 상태를 취소 중(Cancelling) 상태로 바꿈
- 아무런 예외를 던지지 않고 즉시 리턴
-
신호 확인 (협조): 코루틴은 실행 도중에 suspension point에 도달할 때 job 스스로 취소되었는지를 스스로 확인합니다.
- kotlinx.coroutines 라이브러리의 모든 중단 함수들(delay(), yield(), withContext, channel.receive() 등)이 내부적으로 수행
-
예외 발생: 코루틴이 중단점에서 자신이 취소 중 상태임을 감지하면, 그 즉시
CancellationException을 스스로 던져서 자신의 실행을 중단시킵니다.@Test fun `cancel()을 호출하면 JobCancellationException이 발생한다`() = runTest { val job = launch { assertThrows<CancellationException> { repeat(1_000) { i -> println("코루틴 $i") delay(100) } } } delay(200) job.cancel() job.join() }
취소된 코루틴이 단지 멈추는 것이 아니라 내부적으로 예외를 사용해 취소된다는 것을 명심해야 합니다. 따라서 finally 블록 안에서 모든 것을 정리할 수 있습니다. 예를 들어서 finally 블록에서 파일이나 데이터베이스 연결을 닫을 수 있습니다.
suspend fun main(): Unit = coroutinescope {
val job = Job()
launch(job) {
try {
delay(Random.nextLong(2000))
println("Done")
} finally {
print("Will always be printed")
}
}
delay(1000)
job.cancelAndJoin()
}
// Will always be printed <- Random.nextLong(2000)이 1000보다 작은 경우
// (또는)
// Done
// Will always be printed취소 중 코루틴을 한 번 더 호출하기
코루틴은 모든 자원을 정리할 필요가 있는 한 계속 실행될 수 있습니다. 하지만 정리 과정 중에 중단을 허용하지는 않습니다. Job은 이미 Cancelling 상태가 되었기 때문에 중단되거나 다른 코루틴을 시작하는건 절대 불가능합니다.
다른 코루틴을 시작하려고 하면 그냥 무시해버리고, 중단할려고 하면 CancellationException을 던집니다.
@Test
fun `cancel()을 호출한 후, 중단 함수를 호출하면 JobCancellationException이 발생한다`() = runTest {
val job = launch {
delay(200)
println("job state: ${coroutineContext.job.isActive}")
assertThrows<CancellationException> {
delay(200)
}
}
delay(300)
job.cancelAndJoin()
}가끔씩 코루틴이 이미 취소되었을 때 중단 함수를 반드시 호출해야 하는 경우도 있습니다. 예를 들어서 데이터베이스 변경 사항을 롤백하는 경우입니다. 이런 경우 함수 콜을 withContext(NonCancellable)로 포장하는 방법이 많이 사용되고 있습니다.
withContext 내부에서 취소될 수 없는 job인 NonCancellable 객체를 사용하면 블록 내부의 job은 Active 상태를 유지하고 중단 함수를 원하는 만큼 호출할 수 있습니다.
예외 처리
코루틴이 예외를 받았을 때 자기 자신을 취소하고 예외를 부모에게 전파합니다. runBlocking 은 부모가 없는 루트 코루틴이기 때문에 프로그램을 종료시킵니다.
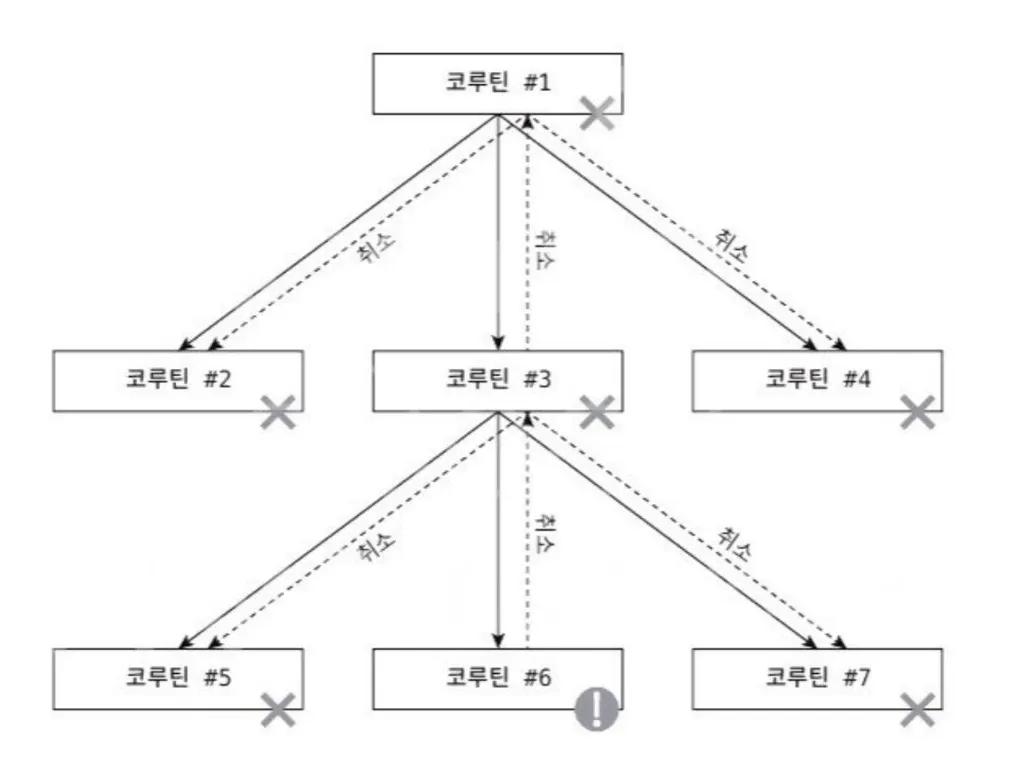
예외는 자식에서 부모로 전파되며, 부모가 취소되면 자식도 취소되기 때문에 쌍방으로 전파됩니다. 예외 전파가 정지되지 않으면 계통 구조상 모든 코루틴이 취소되게 됩니다.
SupervisorJob
코루틴 종료를 멈추는 가장 중요한 방법은 SupervisorJob을 사용하는 것입니다. SupervisorJob을 사용하면 자식에게 발생한 모든 예외를 무시할 수 있습니다.
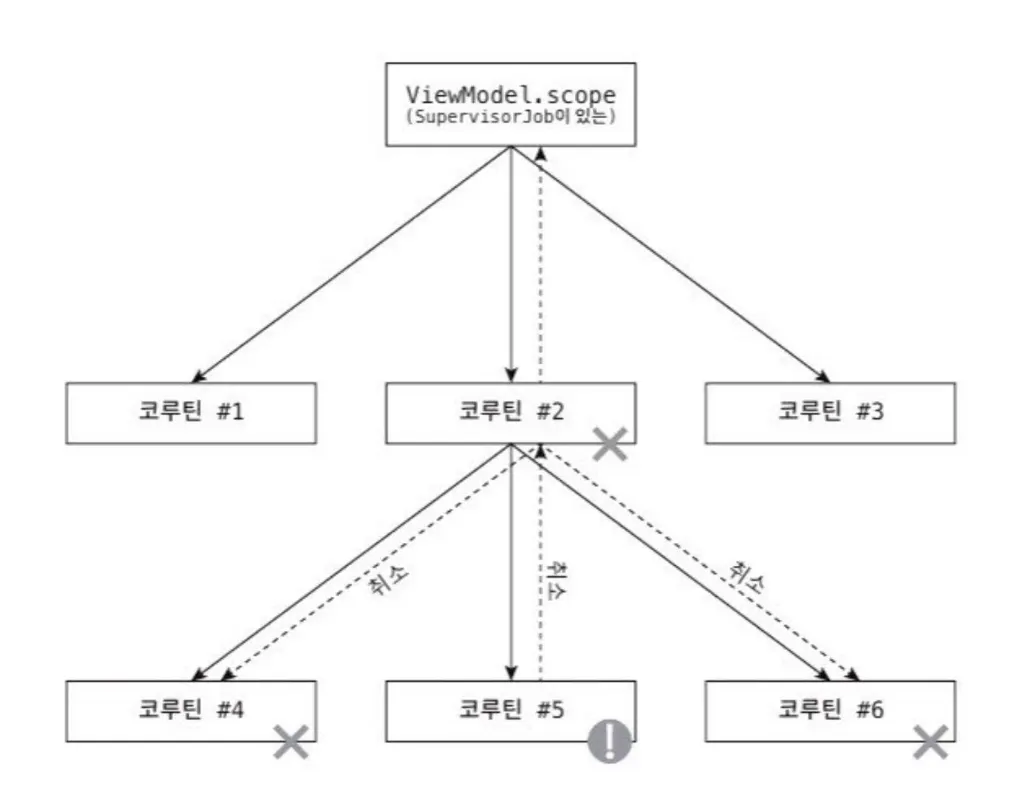
흔한 실수 중 하나는 SupervisorJob을 다음 코드처럼 부모 코루틴의 인자로 사용하는 것입니다.
다음 예시의 코드에서 launch가 SupervisorJob을 인자로 받는데, 이럴 경우 SupervisorJob은 단 하나의 자식만 가지기 때문에 예외를 처리하는 데 아무런 도움이 되지 않습니다.
fun main(): Unit = runBlocking {
// 이렇게 하지 마세요. 자식 코루틴 하나가 있고
// 부모 코루틴이 없는 잡은 일반 잡과 동일하게 작동합니다.
launch(Supervisorjob()) { // 1
launch {
delay(1000)
throw Error("Some error")
}
launch {
delay(2000)
println("Will not be printed")
}
}
delay(3000)
}
// Exception...하나의 코루틴이 취소되어도 다른 코루틴이 취소되지 않는다는 점에서, 같은 job을 다수의 코루틴에서 컨텍스트로 사용하는 것이 좀더 나은 방법입니다.
fun main(): Unit = runBlocking {
val job = SupervisorJob()
launch(job) {
delay(1000)
throw Error("Some error")
}
launch(job) {
delay(2000)
println("Will be printed")
}
job.join()
}
// (1초 후)
// Exception...
// (1 초 후)
// Will be printedsupervisorScope
예외 전파를 막는 또 다른 방법은 코루틴 빌더를 supervisorScope로 래핑하는 것입니다.
다른 코루틴에서 발생한 예외를 무시하고 부모와의 연결을 유지한다는 점에서 아주 편리합니다.
일반적으로 서로 무관한 다수의 작업을 스코프 내에서 실행할 때 사용합니다.
suspend fun notifyAnalytics(actions: List<UserAction>) =
supervisorscope {
actions.forEach { action ->
launch {
notifyAnalytics(action)
}
}
}CancellationException은 부모까지 전파되지 않는다
예외가 CancellationException의 서브클래스라면 부모로 전파되지 않습니다.
현재 코루틴을 취소시킬 뿐입니다. CancellationException 은 열린 클래스이기 때문에 다른 클래스나 객체로 확장될 수 있습니다.
object MyNonPropagatingException : CancellationException()
suspend fun main(): Unit = coroutinescope {
launch { // 1
launch { // 2
delay(2000)
println("Will not be printed")
}
throw MyNonPropagatingException // 3
}
launch { // 4
delay(2000)
println("Will be printed")
}
}
// (2초 후》
// Will be printed코루틴 예외 핸들러
예외를 다룰 때 예외를 처리하는 기본 행동을 정의하는 것이 유용할 때가 있습니다. 이런 경우 CoroutineExceptionHandler 컨텍스트를 사용하면 편리합니다. 예외 전파를 중단시키지는 않지만 예외가 발생했을 때 해야 할 것들을 정의하는데 사용할 수 있습니다.
fun main(): Unit = runBlocking {
val handler =
CoroutineExceptionHandler { ctx, exception ->
println("Caught $exception")
}
val scope = CoroutineScope(SupervisorJob() + handler)
scope.launch {
delay(1000)
throw Error("Some error")
}
scope.launch {
delay(2000)
println("Will be printed")
}
delay(3000)
}
// Caught java.lang.Error: Some error
// Will be printed코루틴 스코프 함수
코루틴 스코프 함수가 소개되기 전에 사용한 방법들
GlobalScope
대표적인 방법으로는 GlobalScope가 있습니다. 하지만 GlobalScope는 그저 EmptyCoroutineContext를 가진 스코프일 뿐입니다. GlobalScope에서 async를 호출하면 부모 코루틴과 아무런 관계가 없습니다. 이때 async 코루틴은
- 취소될 수 없습니다.
- 부모가 취소되어도 async 내부의 함수가 실행 중인 상태가 되므로 작업이 끝날 때까지 자원이 낭비됩니다.
- 부모로부터 스코프를 상속받지 않습니다.
- 항상 기본 디스패처에서 실행되며, 부모의 컨텍스트를 전혀 신경쓰지 않습니다.
스코프를 인자로 넘기는 방법
// 이렇게 구현하면 안 됩니다!
suspend fun CoroutineScope.getUserProfile(): UserProfileData {
val user = async { getUserData() }
val notifications = async { getNotifications() }
return UserProfileData(
user = user.await(), // (1초 후)
notifications = notifications.await(),
)
}이 방법은 취소가 가능하며 적절한 단위 테스트를 추가할 수 있다는 점에서 좀 더 나은 방식이라 할 수 있습니다. 문제는 스코프가 함수에서 함수로 전달되어야 한다는 점입니다.
예를 들어, async에서 예외가 발생하면 모든 스코프가 닫히게 됩니다. 또한 스코프에 접근하는 함수가 cancel 메서드를 사용해 스코프를 취소하는 등 스코프를 조작할 수 있습니다. 이러한 접근 방식은 다루기 어려울 뿐만 아니라 잠재적으로 위험합니다.
그리고 이런 문제들을 해결하기 위해 coroutineScope를 사용할 수 있습니다.
coroutineScope
coroutineScope는 스코프를 시작하는 중단 함수이며, 인자로 들어온 함수가 생성한 값을 반환합니다.
suspend fun <R> coroutineScope(
block: suspend Coroutinescope.() -> R
): Rasync나 launch와는 다르게 coroutineScope의 본체는 리시버 없이 곧바로 호출됩니다. coroutineScope 함수는 새로운 코루틴을 생성하지만 새로운 코루틴이 끝날 때까지 coroutineScope를 호출한 코루틴을 중단하기 때문에 호출한 코루틴이 작업을 동시에 시작하지는 않습니다.
생성된 스코프는 바깥의 스코프에서 coroutineContext를 상속받지만 컨텍스트의 Job을 오버라이딩합니다. 따라서 생성된 스코프는 부모가 해야 할 책임을 이어받습니다.
- 부모로부터 컨텍스트를 상속받습니다.
- 자신의 작업을 끝내기 전까지 모든 자식을 기다립니다.
- 부모가 취소되면 자식들 모두를 취소합니다.
suspend fun longTask() = coroutinescope {
launch {
delay(1000)
val name = coroutinecontext[CoroutineName]?.name
println("[$name] Fin丄shed task 1")
}
launch {
delay(2000)
val name = coroutinecontext[CoroutineName]?.name
println("[$name] Finished task 2")
}
}
fun main()= runBlocking(CoroutineName("Parent")) {
println("Before")
longTask()
println("After")
}
// Before
// (1 초 후)
// [Parent] Finished task 1
// (1 초 후)
// [Parent] Finished task 2
// After위의 예제에서 coroutineScope는 모든 자식이 끝날 때까지 종료되지 않으므로 “After”가 마지막에 출력되는 것을 볼 수 있습니다. 또한 CoroutineName이 부모에게 자식으로 전달되는 것도 확인할 수 있습니다.
coroutineScope 함수는 기존의 중단 메인 함수 본체를 래핑할 때 주로 사용됩니다. 다음은 runBlocking 함수를 coroutineScope가 대체한 것입니다.
suspend fun main(): Unit = coroutinescope {
launch {
delay(1000)
println("World")
}
println("Hello, ")
}
// Hello
// (1 초 후)
// World코루틴 스코프
스코프를 만드는 다양한 함수가 있으며, coroutineScope와 비슷하게 작동합니다.
그렇다면, 코루틴 스코프 함수와 코루틴 빌더는 어떤 차이점들이 있을까요?
| 코루틴 빌더(runBlocking 제외) | 코루틴 스코프 함수 |
|---|---|
| launch, async, produce | coroutineScope, supervisorScope, withContext, withTimeout |
| CoroutineScope의 확장 함수 | 중단 함수 |
| CoroutineScope 리시버의 코루틴 컨텍스트를 사용 | 중단 함수의 컨티뉴에이션 객체가 가진 코루틴 컨텍스트를 사용 |
| 예외는 Job을 통해 부모로 전파됨 | 일반 함수와 같은 방식으로 예외를 던짐 |
withContext
withContext 함수 coroutineScope와 비슷하지만 스코프의 컨텍스트를 변경할 수 있다는 점에서 다릅니다. withContext의 인자로 컨텍스트를 제공하면 부모 스코프의 컨텍스트로 대체합니다. 따라서 withContext(EmptyCoroutineContext)와 coroutineScope는 정확히 같은 방식으로 동작합니다.
fun main() = runBlocking(CoroutineName("Parent")) {
log("Before")
withContext(CoroutineName("Child 1")) {
delay(1000)
log("Hello 1")
}
withContext(CoroutineName("Child 2")) {
delay(1000)
log("Hello 2")
}
log ("After")
}
// [Parent] Before
// (1 초 후)
// [Child 1] Hello 1
// (1 초 후)
// [Child 2] Hello 2
// [Parent] After
coroutinescope { /*.../ }가 작동하는 방식이async { /.../ }.await()처럼 async의 await를 곧바로 호출하는 것과 비슷하다는 걸 앞에서 배웠습니다.withContext (context)또한async (context) { /...*/ }.await()와 비슷합니다
두 경우 모드 async의 await를 곧바로 호출하는 방법 대신 coroutineScope와 withContext를 사용하는 편이 좋습니다.
supervisorScope
supervisorScope 함수는 호출한 스코프로부터 상속받은 CoroutineScope를 만들고 지정된 중단 함수를 호출한다는 점에서 coroutineScope와 비슷합니다.
supervisorScope 는 서로 독립적인 작업을 시작하는 함수에서 주로 사용됩니다.
suspend fun notifyAnalytics(actions: List<UserAction>) =
supervisorscope {
actions.forEach { action ->
launch {
notifyAnalytics(action)
}
}
}async를 사용한다면 예외가 부모로 전파되는 걸 막는 것 외에 추가적인 예외 처리가 필요합니다. await를 호출하고 async 코루틴이 예외로 끝나게 된다면 await는 예외를 다시 던지게 됩니다.
따라서 async에서 발생하는 예외를 전부 처리할려면 try-catch 블록으로 await 호출을 래핑해야합니다.
class ArticlesRepositoryComposite(
private val articleRepositories: List<ArticleRepository>,
) : ArticleRepository {
override suspend fun fetchArticles(): List<Article> =
supervisorScope {
articleRepositories
.map { async { it.fetchArticlesO } }
.mapNotNull {
try {
it.await()
} catch (e: Throwable) {
e.printStackTrace()
null
}
}
.flatten()
.sortedByDescending { it.publishedAt }
}
}withTimeout
coroutineScope와 비슷한 또 다른 함수는 withTimeout 입니다. 이 함수 또한 스코프를 만들고 값을 반환합니다. withTimeout 에 아주 큰 타임아웃 값을 넣어주면 coroutineScope 와 다를 것이 없습니다. withTimeout 은 인자로 들어온 람다식을 실행할 때 시간 제한이 있다는 점이 다릅니다. 실행하는데 시간이 너무 오래 걸리면 람다식은 취소되고, CancellationException의 서브타입인 TimeoutCancellationException을 던집니다.
suspend fun testO: Int = withTimeout(1500) {
delay(1000)
println("Still thinking")
delay(1000)
println("Done!")
42
}
suspend fun main(): Unit = coroutineScope {
try {
test()
} catch (e: TimeoutCancellationException) {
printIn("Cancelled")
}
delay(1000) // 'test' 함수가 취소되었기 때문에,
// 타임아웃 시간을 늘려도 아무런 도움이 되지 않습니다
}
// (1 초 후)
// Still thinking
// (0.5초 후》
// Cancelled코루틴 빌더 내부에서 TimeoutCancellationException을 던지면 해당 코루틴만 취소되고 부모에게는 영향을 주지 않습니다.
추가적인 연산
작업을 수행하는 도중에 추가적인 연산을 수행하는 경우를 살펴봅시다.
예를 들어, 사용자 프로필을 보여준 다음, 분석을 위한 목적으로 요청을 보내고 싶을 수 있습니다. 동일한 스코프에서 launch를 호출하는 방법이 자주 사용됩니다.
class ShowUserDataUseCase(
private val repo: UserDataRepository,
private val view: UserDataView,
) {
suspend fun showUserData() = coroutinescope {
val name = async { repo.getNameO }
val friends = async { repo.getFriendsO }
val profile = async { repo.getProfileO }
val user = User(
name = name.await(),
friends = friends.await(),
profile = profile.await()
)
view.show(user)
launch { repo.notifyProfileShown() }
}
}하지만 이 방식에는 문제가 몇 가지 있습니다.
1. 작업이 끝날 때 까지 기다려야하는 문제
먼저 coroutineScope가 사용자 데이터를 보여 준 뒤 launch로 시작된 코루틴이 끝나기를 기다려야 하므로 launch에서 함수의 목적과 관련된 유의미한 작업을 한다고 보기 어렵습니다. 뷰를 업데이트할 때 프로그레스바를 보여주고 있다면, notifyProfileShown이 끝날 때까지 기다려야 합니다.
2. 취소
코루틴은 기본적으로 예외가 발생했을 때, 다른 연산을 취소하게 설계되어 있습니다. 필수적인 연산을 수행할 때 취소는 아주 유용합니다.
하지만 분석을 위한 호출이 실패했다고 해서 전체 과정이 취소되는 것은 말이 안 됩니다.
그렇다면 어떻게 해야할까요?
해결 방법
핵심 동작에 영향을 주지 않는 추가적인 연산이 있을 경우 또 다른 스코프에서 시작하는 편이 낫습니다. 쉬운 방법으로는 추가적인 연산을 위한 스코프를 만드는 것입니다.
class ShowUserDataUseCase(
private val repo: UserDataRepository,
private val view: UserDataView,
private val analyticsScope: Coroutinescope,
) {
suspend fun showUserDataO = coroutinescope {
val name = async { repo.getName() }
val friends = async { repo.getFriends() }
val profile = async { repo.getProfile() }
val user = User(
name = name.await(),
friends = friends.await(),
profile = profile.await()
)
view.show(user)
analyticsScope.launch { repo.notifyProfileShown() }
}
}생성자를 통해 주입하면 유닛 테스트를 추가할 수 있고, 스코프를 사용하는데도 편리합니다.
주입된 스코프에서 추가적인 연산을 시작하는 것은 자주 사용되는 방법입니다. 스코프를 전달하면 전달된 클래스를 통해 독립적인 작업을 실행한다는 것을 명확하게 알 수 있습니다. 따라서 중단 함수는 주입된 스코프에서 시작한 연산이 끝날 때까지 기다리지 않습니다. 스코프가 전달되지 않으면 중단 함수는 모든 연산이 완료될 때까지 종료되지 않을 것이라 예상할 수 있습니다.
디스패처
코틀린 코루틴 라이브러리가 제공하는 중요한 기능은 코루틴이 실행되어야 할 스레드를 결정할 수 있다는 것입니다.
영어 사전에서 디스패처를 ‘사람이나 차량, 특히 긴급 차량을 필요한 곳에 보내는 것을 담당하는 사람’이라 정의되어 있습니다. 코틀린 코루틴에서 코루틴이 어떤 스레드에서 실행될지 정하는 것은 CoroutineContext입니다.
기본 디스패처
디스패처를 설정하지 않으면 기본적으로 설정되는 디스패처는 CPU 집약적인 연산을 수행하도록 설계된 DIspatcher.Default입니다. 이 디스패처는 코드가 실행되는 컴퓨터의 CPU 개수와 동일한 수의 스레드 풀을 가지고 있습니다. 스레드를 효율적으로 사용하고 있다고 가정하면(CPU 집약적인 연산을 수행하며 블로킹이 일어나지 않는 환경) 이론적으로는 최적의 스레드 수라고 할 수 있습니다.
기본 디스패처 제한하기
비용이 많이 드는 작업이 Dispatcher.Default 스레드를 다 써버려서 같은 디스패처를 사용하는 다른 코루틴이 실행될 수 없다고 의심할 수 있습니다. 이런 상황을 마주쳤을 때, limitedParallelism을 사용하면 디스패처가 같은 스레드 풀을 사용하지만 같은 시간에 특정 수 이상의 스레드를 사용하지 못하도록 제한할 수 있습니다.
메인 디스패처
일반적으로 애플리케이션 프레임워크는 가장 중요한 스레드인 메인 혹은 UI 스레드 개념을 가지고 있습니다. 메인 스레드는 UI와 상호작용 하는 유일한 스레드이기 때문에, 아주 조심스럽게 다뤄야 합니다. 메인 스레드에서 코루틴을 실행하려면 Dispatcher.Main을 사용하면 됩니다.
안드로이드에서는 기본 디스패처로 메인 디스패처를 주로 사용합니다. 블로킹 대신 중단하는 라이브러리를 사용하고 복잡한 연산을 하지 않는다면 Dispatcher.Main으로 충분합니다. CPU 집약적인 작업을 수행한다면 Dispatcher.Deafult로 실행해야 합니다. 대부분의 애플리케이션에서는 두 개의 디스패처만 있어도 충분하지만 스레드를 블로킹해야 하는 경우 어떻게 해야할까요? 예를 들어서 시간이 오래 걸리는 I/O 작업이나 블로킹 함수가 있는 라이브러리가 필요할 때가 있습니다. 이러한 작업을 위해 Dispatcher.IO 을 사용할 수 있습니다.
IO 디스패처
Dispatcher.IO는 파일을 읽고 쓰는 경우, 안드로이드의 Shared Preference를 사용하는 경우, 블로킹 함수를 호출하는 경우 처럼 I/O 연산으로 스레드를 블로킹할 때 사용하기 위해 설계되었습니다. 다음 코드는 Dispatcher.IO가 같은 시간에 50개가 넘는 스레드를 사용할 수 있도록 만들어졌기 때문에 1초밖에 걸리지 않습니다.
suspend fun main() {
val time = measureTimeMillis {
coroutineScope {
repeat(50) {
launch(Dispatchers.IO) {
Thread.sleep(1000)
}
}
}
}
println(time) // 〜1000
}Dispatcher.IO는 64개, 혹은 더 많은 코어가 있다면 해당 코어의 수로 개수가 제한됩니다.
왜 개수가 제한될까요? 스레드가 무한한 풀을 상상해 봅시다. 처음에는 풀이 비어 있지만, 더 많은 스레드가 필요해지면 스레드가 생성되고 작업이 끝날 때까지 활성 상태로 유지됩니다. 이러한 스레드 풀이 존재하더라도 직접 사용하는 것은 안전하다고 볼 수 없습니다. 활성화된 스레드가 너무 많으면 점점 떨어지게 되고 결국 메모리 부족이 일어납니다. 그렇기에 Dispatcher.IO와 Dispatcher.Default 모두 개수가 제한됩니다.
앞에서 살펴봤듯이 Dispatcher.Default``와 Dispatcher.IO는 같은 스레드 풀을 공유합니다. 이는 최적화 측면에서 중요한 사실입니다. 스레드는 재사용되고 다시 배분될 필요가 없습니다. Dispatcher.Default로 실행하는 도중에 withContext(Dispatchers.IO) { … } 까지 도달하는 경우를 예를 들어 보겠습니다. 대부분은 같은 스레드로 실행되지만, 스레드 수가 Dispatcher.Default의 한도가 아닌 Dispatcher.IO의 한도로 적용됩니다. 스레드의 한도는 독립적이기 때문에 다른 디스패처의 스레드를 고갈시키는 경우는 없습니다.
suspend fun main(): Unit = coroutinescope {
launch(Dispatchers.Default) {
println(Thread.currentThread().name)
withContext(Dispatchers.IO) {
println(Thread.currentThread().name)
}
}
}
// DefaultDispatcher-worker-2
// DefaultDispatcher-worker-2Dispatchers.IO에서 64개의 스레드까지 사용할 수 있고, 8개의 코어를 가지고 있다면 공유 스레드 풀에서 활성화된 스레드는 72개일 것입니다. 스레드 재활용적인 측면에서 효율적이라 할 수 있으며, 디스패처의 스레드 수는 각각 별개로 설정됩니다.
커스텀 스레드 풀을 사용하는 IO 디스패처
Dispatcher.IO에는 limitedParallelism 함수를 위해 정의된 특별한 작동 방식이 있습니다. limitedParallelism 함수는 독립적인 스레드 풀을 가진 새로운 디스패처를 만듭니다. 이렇게 만들어진 풀은 우리가 원하는 만큼 많은 수의 스레드 수를 설정할 수 있으므로 스레드 수가 64개로 제한되지 않습니다.
limitedParallism을 다음과 같은 방식으로 생각할 수 있습니다.
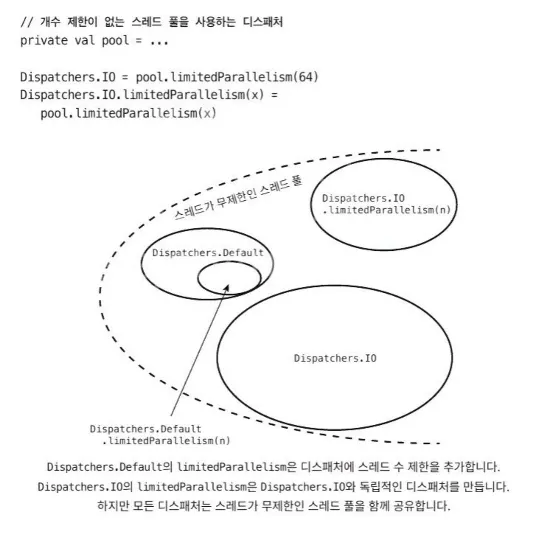
스레드를 블로킹하는 경우가 많은 클래스에서 자신만의 한도를 가진 커스텀 디스패처를 만들면 limitedParallism를 잘 활용할 수 있습니다. 한도는 정해진 답은 없습니다. 가장 중요한 사실은 이때 사용하는 스레드 한도가 Dispatcher.IO를 비롯한 다른 디스패처와 무관하다는 사실입니다. 따라서 한 서비스가 다른 서비스를 블로킹하는 경우는 없습니다.
정해진 수의 스레드 풀을 가진 디스패처
몇몇 개발자들은 자신들이 사용하는 스레드 풀을 직접 관리하기를 원하며, 자바는 이를 지원하기 위한 Api를 제공합니다. 예를 들어, Excutors 클래스를 스레드 수가 정해져 있는 스레드 풀이나 캐싱된 스레드 풀을 만들 수 있습니다. 하지만 이를 통해 만들어진 디스패처는 close 함수로 직접 닫아야 합니다. 개발자들이 종종 이를 깜빡하여 스레드 누수를 일으키는 경우가 있습니다. 또 다른 문제로는 정해진 수의 스레드풀을 만들면 스레드를 효율적으로 사용하지 않는 문제가 있습니다. 사용하지 않는 스레드가 다른 서비스와 공유되지 않고 살아있는 상태로 유지되기 때문입니다.
싱글스레드로 제한된 디스패처
다수의 스레드를 사용하는 모든 디스패처에서는 공유 상태로 인한 문제를 생각해야 합니다.
var i = 0
suspend fun main(): Unit = coroutinescope {
repeat(10_000) {
launch(Dispatchers.IO) { // 또는 Default 디스패처
i++
}
}
delay(1000)
println(i) // ~9930
}위의 예제에서는 10000개의 스레드가 i를 1씩 증가시키지만, 실제 값은 이보다 작은 값이 나옵니다. 이는 동일 시간에 다수의 스레드가 공유 상태를 변경했기 때문입니다.
이런 문제를 해결하는 다양한 방법이 있으며, 싱글 스레드를 가진 디스패처를 사용하는 방법이 그 중 하나입니다. 하지만 단 하나의 스레드만 가지고 있기 때문에 이 스레드가 블로킹되면 작업이 순차적으로 처리되는 것이 가장 큰 단점입니다.
프로젝트 룸의 가상 스레드 사용하기
JVM 플랫폼은 프로젝트 룸이라는 새로운 기술을 발표했습니다. 프로젝트 룸의 가장 혁신적인 특징은 일반적인 스레드보다 훨씬 가벼운 가상 스레드를 도입했다는 점입니다. 일반적인 스레드를 블로킹하는 것보다 가상 스레드를 블로킹하는 것이 비용이 훨씬 적게 듭니다.
코루틴에서는 Executors의 newVirtualThreadPerTaskExecutor로 익스큐터(excutor)를 생성한 후, 코루틴 디스패처로 변환할 수 있습니다.
val LoomDispatcher = Executors
.newVirtualThreadPerTaskExecutor()
.asCoroutineDispatcher()
object LoomDispatcher : ExecutorCoroutineDispatcher() {
override val executor: Executor = Executor { command ->
Thread.startVirtualThread(command)
}
override fun dispatch(
context: Coroutinecontext,
block: Runnable
) {
executor.execute(block)
}
override fun close() {
error("Cannot be invoked on Dispatchers.LOOM")
}
}제한받지 않는 디스패처
마지막으로 생각해 봐야 할 디스패처는 Dispatcher.Unconfined 입니다. 이 디스패처는 스레드를 바꾸지 않는다는 점에서 이전 디스패처들과 다릅니다. 제한받지 않는 디스패처가 시작되면 시작한 스레드에서 실행됩니다. 재개되었을 때는 재개한 스레드에서 실행됩니다.
suspend fun main(): Unit =
withContext(newSingleThreadContext("Thread1")) {
var continuation: Continuation<Unit>? = null
launch(newSingleThreadContext("Thread2")) {
delay(1000)
continuation?.resume(Unit)
}
launch(Dispatchers.Unconfined) {
println(Thread.currentThread().name) // Thread1
suspendCancellableCoroutine<Unit> {
continuation = it
}
println(Thread.currentThread().name) //. Thread2
delay(1000)
println(Thread.currentThread().name)
// kotlinx.coroutines.DefaultExecutor
// (delay가 사용한 스레드입니다)
}
}
}제한받지 않는 디스패처는 단위 테스트를 할 때 유용합니다. 모든 스코프에서 제한받지 않는 디스페처를 사용하면 모든 작업이 같은 스레드에서 실행되기 때문에 연산의 순서를 훨씬 쉽게 통제할 수 있습니다.
성능적인 측면에서 보면 스레드 스위칭을 일으키지 않는다는 점에서 제한받지 않는 디스패처의 비용이 가장 저렴합니다. 실행되는 스레드에 대해 전혀 신경쓰지 않아도 된다면 제한받지 않는 디스패처를 사용하는 것은 무모하다고 볼 수 있습니다.
메인 디스패처로 즉기 옮기기
코루틴을 배정하는 것에도 비용이 듭니다. withContext가 호출되면 코루틴은 중단되고 큐에서 기다리다가 재개됩니다. 스레드에서 이미 실행되고 있는 코루틴을 다시 배정하면 작지만 필요없는 비용이 든다고 할 수 있습니다.
suspend fun showUser(user: User) =
withContext(Dispatchers.Main) {
userNameElement.text = user.name
// ...
}위 함수가 이미 메인 디스패처에서 호출이 되었다면 다시 배정하는 데 쓸데없는 비용이 발생했을 것입니다. 게다가 메인 스레드를 기다리는 큐가 쌓여있다면 withContext 때문에 사용자 데이터는 약간의 지연이 있은 뒤에 보여지게 됩니다. (실행되고 있던 코루틴이 작업을 다시 하기 전에 다른 코루틴을 기다려야 합니다.)
이런 경우를 방지하기 위해 반드시 필요한 경우에만 배정을 하는 Dispatcher.Main.immediate가 있습니다. 메인 스레드에서 다음 함수를 호출하면 스레드 배정 없이 즉시 실행됩니다.
suspend fun showUser(user: User) =
withContext(Dispatchers.Main.immediate) {
userNameElement.text = user.name
// ...
}작업의 종류에 따른 각 디스패처의 성능 비교
각 디스패처를 비교하기 위해 같은 작업을 수행하는 100개의 독립적인 코루틴을 실행한 결과입니다.
| 중단 | 블로킹 | CPU 집약적인 연산 | 메모리 집약적인 연산 | |
|---|---|---|---|---|
| 싱글 스레드 | 1,002 | 100,003 | 39,103 | 94,358 |
| Default Dispatcher | 1,002 | 13,003 | 8,473 | 21,461 |
| IO 디스패처 | 1,002 | 2,003 | 9,893 | 20,776 |
| 스레드 100개 | 1,002 | 1,003 | 16,379 | 21,004 |
이를 통해 주목할만한 점은 다음과 같습니다.
- 단지 중단할 경우에는 사용하고 있는 스레드의 수가 얼마나 많은지는 문제가 되지 않습니다.
- 블로킹할 경우에는 스레드 수가 많은수록 모든 코루틴이 종료되는 시간이 빨라집니다.
- CPU 집약적인 연산에서는
Dispatcher.Default가 가장 좋은 선택지입니다.- 스레드를 더 많이 사용할수록, 프로세서는 스레드 사이를 스위칭하는데 쓰는 시간이 더 늘어나 의미있는 연산을 하는 시간이 줄어들기 때문입니다. Dispatcher.IO 또한 CPU 집약적인 연산에 사용하면 안됩니다. 블로킹 연산을 처리하기 위한 용도로 사용되기 때문에 다른 작업이 스레드 전체를 블로킹할 수 있습니다.
- 메모리 집약적인 연산을 처리하고 있다면 더. 많은 스레드를 사용하는 것이 좀 더 낫습니다.
- 유의미한 차이는 없습니다.
공유 상태로 인한 문제
시작하기 전에 아래에 있는 UserDownloader 클래스를 살펴봅시다. 이 클래스에서 아이디로 사용자를 받아오거나, 이전에 전송받은 모든 사용자를 얻을 수 있습니다. 이렇게 구현하면 어떤 문제가 있을까요?
class UserDownloader(
private val api: NetworkService
) {
private val users = mutableListOf<User>()
fun downloaded(): List<User> = users.toList()
suspend fun fetchUser(id: Int) {
val newllser = api.fetchUser(id)
users.add(newUser)
}
}앞의 구현 방식은 동시 사용에 대한 대비가 되어 있지 않습니다. fetchUser 호출은 users를 변경합니다. 같은 시간에 두개 이상의 스레드에서 함수가 호출될 수 있으므로 users는 공유 상태에 해당하며 보호될 필요가 있습니다. 동시에 리스트를 변경하면 충돌이 일어날 수 있기 때문입니다.
동기화 블로킹
위와 같은 문제는 자바에서 사용되는 전통적인 도구인 synchronized 블록이나 동기화된 컬렉션을 사용해 해결할 수 있습니다.
var counter = 0
fun main() = runBlocking {
val lock = Any()
massiveRun {
synchronized(lock) { // 스레드를 블로킹합니다!
counter++
}
}
println("Counter = $counter") // 1000000
} 이 방법은 작동하긴 하지만, 몇 가지 문제점이 있습니다. 가장 큰 문제점은 synchronized 블록 내부에서 중단 함수를 사용할 수 없다는 것입니다. 두 번째는 synchronized 블록에서 코루틴이 자기 차례를 기다릴 때 스레드를 블로킹한다는 것입니다. 디스패처의 원리를 생각해보면 코루틴이 스레드를 블로킹하는 것은 지양해야 합니다. 블로킹 없이 중단하거나 충돌을 회피하는 방법을 사용해야 합니다. 지금까지 봤던 방식과는 다른, 코루틴에서 사용하는 방식을 보도록 하겠습니다.
원자성
자바는 다양한 원자값을 가지고 있습니다. 원자값을 활용한 연산은 빠르며 스레드 안전을 보장합니다. 이러한 연산을 원자성 연산이라고 합니다. 원자성 연산은 락 없이 로우 레벨로 구현되어 효율적이고 사용하기 쉽습니다.
private var counter = AtomicInteger()
fun main() = runBlocking {
massiveRun {
counter.incrementAndGet()
}
println(counter.get()) // 1000000
}원자값은 의도대로 완벽하게 동작하지만, 사용성이 제한되어 있기 때문에 조심해서 다뤄야 합니다. 하나의 연산에서 원자성을 가지고 있다고 해서 전체 연산에서 원자성이 보장되는 것은 아니기 때문입니다.
private var counter = AtomicInteger()
fun mainO = runBlocking {
massiveRun {
counter.set(counter.get() + 1)
}
println(counter.get()) // ~ 430467
}UserDownloader를 안전하게 사용하기 위해서 읽기만 가능한 사용자 리스트를 AtomicReference로 래핑할 수 있습니다. 충돌 없이 값을 갱신하기 위해서는 getAndUpdate라는 원자성 보장 함수를 사용합니다.
class UserDownloader(
private val api: Networkservice
) {
private val users = AtomicReference(listOf<User>())
fun downloaded(): List<User> = users.get()
suspend fun fetchuser(id: Int) {
val newUser = api.fetchuser(id)
users.getAndUpdate { it + newUser }
}
}원자성은 하나의 프리미티브 변수 또는 하나의 레퍼런스의 안전을 보장하기 위해 사용되지만, 좀더 복잡한 경우에는 다른 방법을 사용해야 합니다.
싱글 스레드로 제한된 디스패처
싱글스레드 디스패처를 사용하는 것이 공유 상태와 관련된 대부분의 문제를 해결하는 가장 쉬운 방법입니다.
val dispatcher = Dispatchers.IO
.limitedParallelism(1)
var counter = 0
fun main() = runBlocking {
massiveRun {
withContext(dispatcher) {
counter++
}
}
println(counter) // 1000000
}디스패처를 사용하는 방법은 2가지가 있습니다.
코스 그레인 스레드 한정(coarse-grained thread confinement)
코스 그레인 스레드 한정 방법은 디스패처를 싱글 스레드로 제한한 withContext로 전체 함수를 래핑하는 방법입니다. 사용하기 쉬우며 충돌을 방지할 수 있지만, 함수 전체에서 멀티스레딩의 이점을 누리지 못하는 문제가 있습니다.
class UserDownloader(
private val api: Networkservice
) {
private val users = mutableListOf<User>()
private val dispatcher = Dispatchers.IO
.limitedParallelism(1)
suspend fun downloadedO: List<User> =
withContext(dispatcher) {
users.toList()
}
suspend fun fetchUser(id: Int) = withContext(dispatcher) {
val newUser = api.fetchUser(id)
users += newUser
}
}위의 예시에서 api.fetchUser(id)는 여러 개의 스레드에서 병렬로 시작할 수 있지만 함수 본체는 싱글스레드로 제한된 디스패처에서 실행됩니다. 그 결과, 블로킹되는 함수 또는 CPU 집약적인 함수를 호출하면 함수 실행이 느려집니다.
파인 그레인드 스레드 한정(fine-grained thread confinement)
두 번째 방법은 파인 그레인드 스레드 한정 입니다. 이 방법은 상태를 변경하는 구문들만 래핑합니다. 파인 그레인드 스레드 한정은 좀 더 번거롭지만 크리티컬 섹션이 아닌 부분이 블로킹되거나 CPU 집약적인 경우에 더 나은 성능을 제공합니다. 일반적인 중단 함수에 적용하는 경우에는 성능에 큰 차이가 없습니다.
대부분의 경우, 표준 디스패처가 같은 스레드 풀을 사용하기 때문에 싱글 스레드를 가진 디스패처를 사용하는건 쉬울 뿐 아니라 효율적입니다.
뮤텍스
마지막으로 가장 인기있는 방식은 Mutex를 사용하는 것입니다. 뮤텍스를 단 하나의 열쇠가 있는 방이라고 생각할 수 있습니다. 뮤텍스의 가장 중요한 기능은 lock입니다. 첫 번째 코루틴이 lock을 호출하면 열쇠를 가지고 중단 없이 작업을 수행합니다. 또 다른 코루틴이 lock을 호출하면, 첫 번째 코루틴이 unlock을 호출할 때까지 중단됩니다.
또 다른 코루틴이 lock 함수를 호출하면, 마찬가지로 작업을 중단한 뒤에 두 번째 코루틴 다음 순서로 큐에 들어가게 됩니다. 첫 번째 코루틴이 unlock 함수를 호출하면 열쇠를 반납하고 두 번째 코루틴이 재개한 뒤 lock 함수를 통과하게 됩니다.
따라서 단 하나의 코루틴만이 lock과 unlock 사이에 있을 수 있습니다.
suspend fun main() = coroutineScope {
repeat(5) {
launch {
delayAndPrint()
}
}
}
val mutex = Mutex()
suspend fun delayAndPrint() {
mutex.lock()
delay(1000)
println("Done")
mutex.unlock()
}
// (1 초 후)
// Done
// (1 초 후)
// Done
// (1 초 후)
// Done
// (1초 후)
// Done
// (1초 후)
// DoneMutex 주의할 점: 데드락
lock과 unlock 함수 사이에 예외가 발생하면 unlock을 호출할 수 없어서 데드락이 발생합니다. 대신 lock으로 시작해 finally 블록에서 unlock을 호출하는 wichLock 함수를 사용해 블록 내에서 어떤 예외가 발생하더라도 자물쇠를 성공적으로 풀 수 있게 할 수 있습니다. 실제 사용법은 synchronized와 비슷합니다.
val mutex = Mutex()
var counter = 0
fun main() = runBlocking {
massiveRun {
mutex.withLock {
counter++
}
}
println(counter) // 1000000
}synchronized 블록과 달리 뮤텍스가 가지는 이점은 스레드를 블로킹하는 대신 코루틴을 중단시킨다는 것입니다. 좀더 안전하고 가벼운 방식입니다. 병렬 실행이 싱글스레드로 제한된 디스패처를 사용하는 것과 비교하면 뮤텍스가 가벼우며 좀더 나은 성능을 가질 수 있습니다.
하지만 뮤텍스를 적절히 사용하는 것은 어렵습니다. 뮤텍스를 사용할 때 코루틴이 락을 두 번 통과할 수 없는 경우를 조심해야 합니다. 다음 코드를 실행하면 프로그램은 교착 상태에 빠지게 되며 영원히 블로킹 상태로 있게 됩니다.
suspend fun main() {
val mutex = Mutex()
println("Started")
mutex.withLock {
mutex.withLock {
println("Will never be printed")
}
}
}
// Started
// (영원히 실행됩니다)Mutex 주의할 점: 코루틴이 중단되었을 경우
뮤텍스가 가진 두 번재 문제점은 코루틴이 중단되었을 때 뮤텍스를 풀 수 없다는 점입니다.
다음 코드를 보면 delay 중에 뮤텍스가 잠겨있어 5초가 걸리는 걸 확인할 수 있습니다.
class MessagesRepository {
private val messages = mutableListOf<String>()
private val mutex : Mutex()
suspend fun add(message: String) = mutex.withLock {
delay (1000) // 네트워크 호출이라 가정합니다
messages.add(message)
}
}
suspend fun main() {
val repo = MessagesRepository()
val timeMillis = measureTimeMillis {
coroutineScope {
repeat(5) {
launch {
repo.add("Message$it")
}
}
}
}
println(timeMillis)// 〜5120
}싱글스레드로 제한된 디스패처를 사용하면 이런 문제는 발생하지 않습니다. delay나 네트워크 호출이 코루틴을 중단시키면 스레드를 가진 다른 코루틴이 사용합니다.
class MessagesRepository {
private val messages = mutableListOf<String>()
private val dispatcher = Dispatchers.IO
.limitedParallelism(1)
suspend fun add(message: String) =
withContext(dispatcher) {
delay(1000) // 네트워크 호출이라 가정합니다
messages.add(message)
}
}
suspend fun main() {
val repo = MessagesRepository()
val timeMillis = measureTimeMillis {
coroutineScope {
repeat(5) {
launch {
repo.add("MessageSit")
}
}
}
}
println(timeMillis) // 1058
}따라서 전체 함수를 뮤텍스로 래핑하는 건 지양해야 합니다.
뮤텍스를 사용하기로 했다면 락을 두 번 걸지 않고 중단 함수를 호출하지 않도록 신경써야 합니다.
세마포어
세마포어는 뮤텍스와 달리 여러 개의 접근을 허용하므로, acquire, release, withPermit 함수를 가지고 있습니다.
suspend fun main() = coroutineScope {
val semaphore = Semaphore(2)
repeat(5) {
launch {
semaphore.withPermit {
delay(1000)
print(it)
}
}
}
}
// 01
// (1초 후)
// 23
// (1초 후)
// 4세마포어는 공유 상태로 인해 생기는 문제를 해결할 수는 없지만, 동시 요청을 처리하는 수를 제한할 때 사용할 수 있는 처리율 제한 장치를 구현할 때 도움이 됩니다.
class LimitedNetworkUserRepository(
private val api: UserApi
) {
// 동시 요청을 10개로 제한합니다.
private val semaphore = Semaphore(10)
suspend fun requestuser(userid: String) =
semaphore.withPermit {
api.requestUser(userid)
}
}