시작하며
Spark RDD
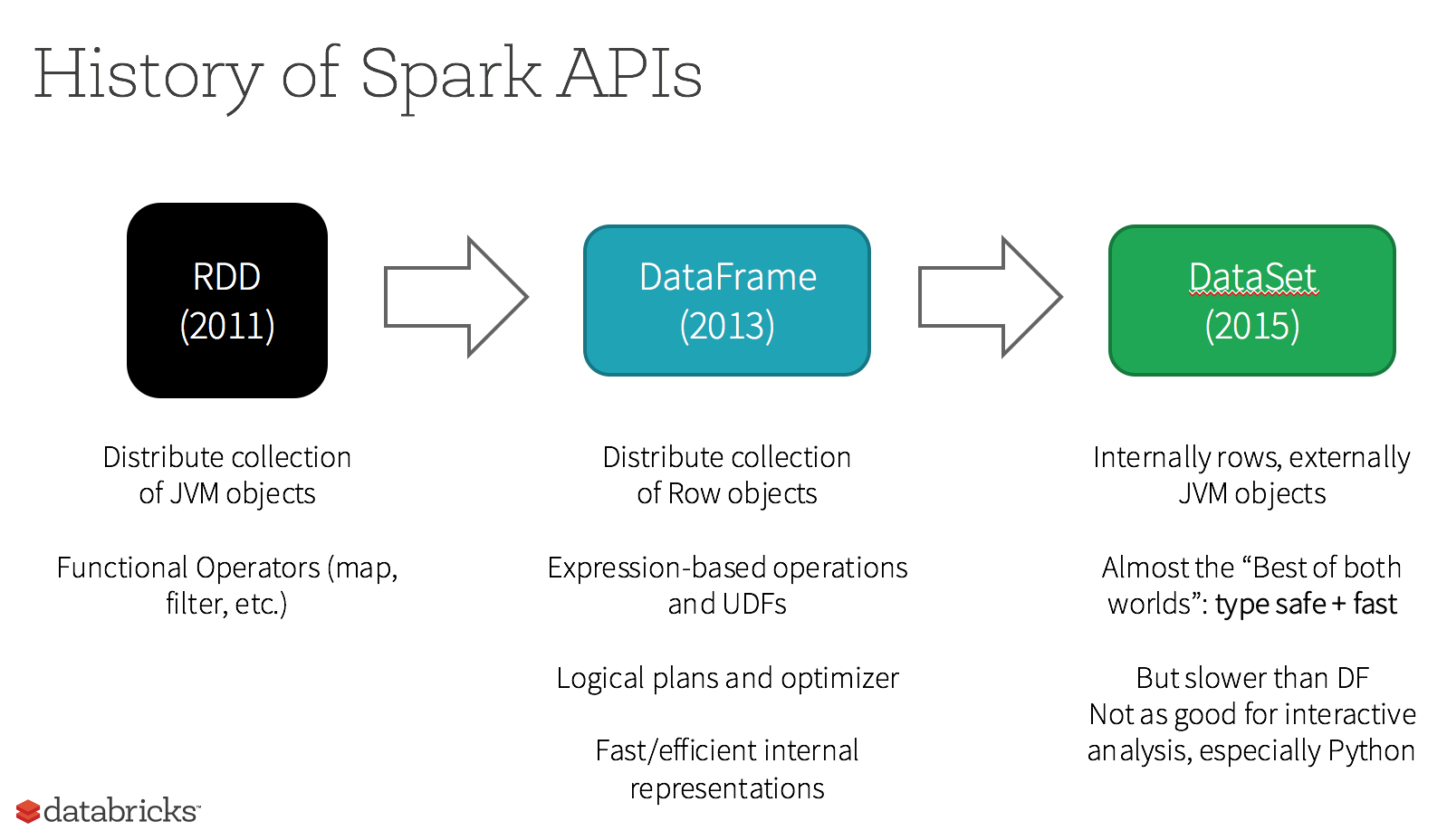
RDD는 Spark의 가장 기본적인 Interface이다. RDD의 핵심 특징은 다음과 같다.
- 의존성: 각 RDD의 DAG Leaneage를 가지고 있어 의존성을 뛴다.
- 파티션: 각 Executor들이 분산해 파티션별로 병렬 연산할 수 있다.
- 연산함수: Partition -> Iterator[T]
한계: 파이썬에서는 Iterator[T] 타입이 불투명하다. 파이썬에서는 객체로만 인식이 가능했다.T에 대한 타입 정보가 전혀없다. 이로인해 연산 순서를 재정렬해 효과적인 질의 계획으로 바꾸기 힘들다. 테이블 조인 효율화 같은 처리를 사용자가 직접 제어해야 했기 때문에 최적화에 어려움을 겪었다.
Spark 구조 확립
특정 패턴을 기반으로 연산(필터링, 선택, 집합, 집계, 평균, 그룹화)실행한다. DSL(domain specific language)을 사용하기 시작했고, 이로인한 장점은 다음과 같았다.
- API사용이 가능해졌다(다양한 언어에서 지원했다)
- Readability가 좋아졌다.
- 컴파일 타입 체킹이 가능해졌다.
Data Frame API
스파크 1.3에서 처리속도 증가를 위한 텅스텐의 일부로 소개 됐다. 데이터를 스키마 형태로 추상화 하고, 카탈리스트 옵티마이저가 쿼리를 최적화하여 처리한다. 특징은 다음과 같다.
- 데이터프레임은 컬럼과 스키마를 가진 분산 인메모리 테이블처럼 동작한다.
- 각 스키마의 컬럼은 특정한 데이터 타입을 가질 수 있다.
- 스키마를 읽고 변경, 컬럼 추가와 같은 기능들(SparkSQL)을 제공한다.
- 데이터 프레임은 불변성을 지니고, 모든 변경내역을 보관한다.
- 다양한 데이터 타입을 지원한다.
- 정형화 타입: SHORT, INT, LONG, STRING, BOOLEAN ..
- 복합 타입: BINARY, TIMESTAMP, MAP, STRUCT..
예제
// 데이터프레임 예제
val df = spark.read.json("examples/src/main/resources/people.json")
df.select($"name", $"age").filter($"age" > 20).show()
df.groupBy("age").count().show()
Schema, data frame 만들기
외부 데이터 Source로 부터 데이터를 가지고 올때, 사용자가 미리 정의한 스키마에 데이터를 구조화 해서 읽게 된다. 이때의 장점은 다음과 같다.
- 스파크 데이터 추론 책임을 덜어준다.
- 스파크가 스키마를 만드는데 별도의 잡을 만드는것을 방지한다.
- 데이터가 스키마와 맞지 않는 경우, 조기에 문제를 발견 가능하다.
스키마 정의하는 두가지 방식
1. API
val schema = StructType(Array(
StructField("author",StringType,false),
StructField("title",StringType,false),
StructField("pages",IntegerType,false)))2. DDL
val schema = "author STRING, title STRING, page INT"표현
컬럼과 로우를 RDBMS에 사용하는 쿼리를 이용해서 조회를 할 수 있고, 객체를 만들 수 있고, 컬럼 추가도 할 수 있으며, 판다스와 유사하게 데이터 프레임에 대한 표현식 사용과 조작이 가능하다.
Data Set API
데이타셋은 스파크 1.6에서 추가 되었습니다. 데이터의 타입체크, 데이터 직렬화를 위한 인코더, 카탈리스트 옵티마이저를 지원하여 데이터 처리 속도를 더욱 증가시켰다. 스파크 2.0에서 DataFrame과 DataSet을 통합 하였다.
특징은 다음과 같다.
-
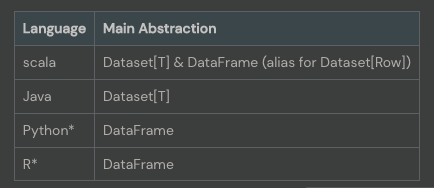
Dataset은 Scala, Java클래스에서 정의하는 case class를 통해 타입을 선언한 강력한 형식의 JVM객체이다. Datasets은 Scala와 Java만 지원하는데 Python과 R의 경우 컴파일 타입 안정성이 없기 때문이다.
-
Data Set API는 정적타입과 동적타입을 전부 가진다.
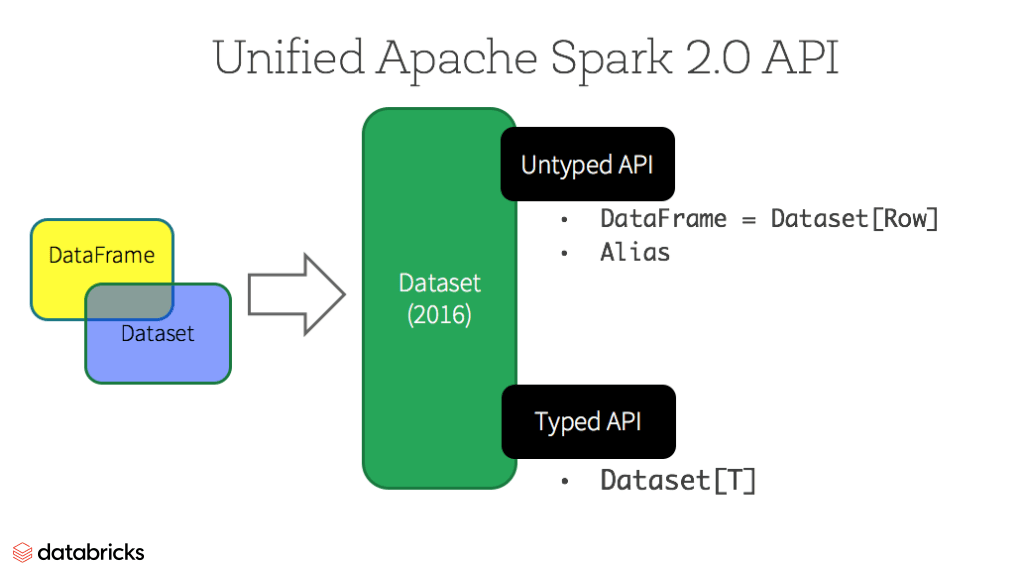
그림과 같이 DataFrame은 정적타입이며, DataSet[Row]라고 할 수 있다. Row는 서로 다른 타입의 값을 저장 할 수 있는 포괄적 JVM 객체라고 보면 된다. 반면 Dataset은 JVM객체이며, 자체가 Java Class라고 볼 수 있다. -
런타임 타입 안전성
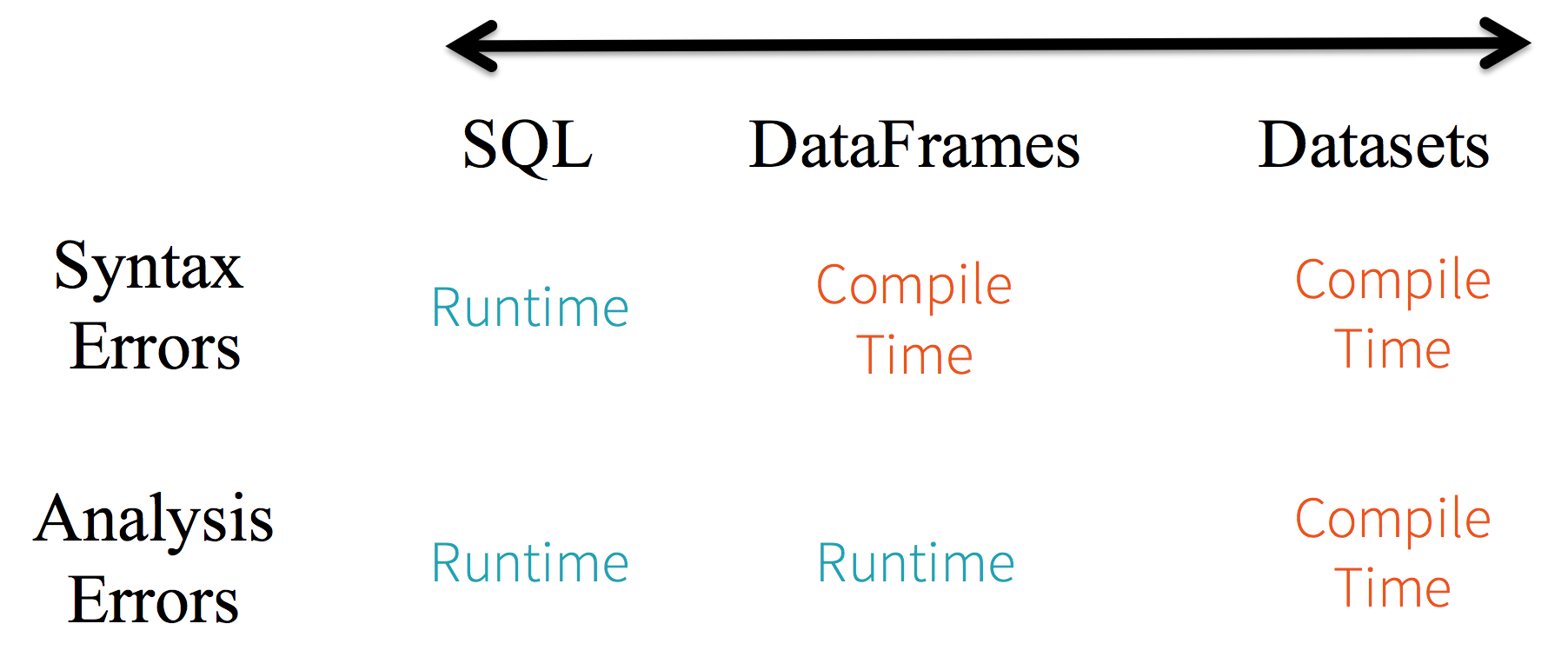
Dataframe, Dataset은 SparkSql을 사용하기에, Dataframe에서 API의 일부가 아닌 함수를 호출하면 컴파일 시점에 오류는 잡을 수 있다. 다만 런타임에서는 존재 하지 않는 열 이름 까지는 감지 할 수 없다. Dataset의 경우 람다 함수 및 JVM 타입 객체로 표현되기 때문에 타입이 지정된 매개변수의 불일치가 컴파일 시점에 감지되며 분석오류까지 알 수 있다.
-
높은 추상화와 구조/반 구조화에 대한 자유로움
Datasets[Row] 의 컬렉션인 DataFrames 는 구조화된 사용자 정의 보기를 반구조화된 데이터로 렌더링합니다. 예를 들어 JSON으로 표현되는 거대한 IoT 장치 이벤트 데이터 세트가 있다고 가정해 보겠습니다. JSON은 반구조화된 형식이므로 강력한 형식의 특정 Dataset[DeviceIoTData] 컬렉션으로 Dataset을 사용하는 데 적합하다.- Dataset[DeviceIoTData]{ "device_id" : 198164 , "device_name" : "sensor-pad-198164owomcJZ" , "ip" : "80.55.20.25" , "cca2" : "PL" , "cca3" : "POL" , "cn" : " 폴란드" , "위도" : 53.080000 , "경도" : 18.620000 , "스케일" : "섭씨" , "온도" : 21 , "습도": 65 , "battery_level" : 8 , "c02_level" : 1408 , "lcd" : "빨간색" , "타임스탬프" : 1458081226051 }
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)data 읽기
// read the json file and create the dataset from the
// case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]- Spark는 JSON을 읽고 스키마를 유추하고 DataFrames 컬렉션을 만든다.
- 이 시점에서 Spark는 정확한 유형을 모르기 때문에 데이터를 일반 Row 개체의 컬렉션인 DataFrame = Dataset[Row] 로 변환한다.
- 이제 Spark는 DeviceIoTData 클래스 에 따라 Dataset[Row] -> Dataset[DeviceIoTData] 유형별 Scala JVM 개체를 변환한다 .
예제
// 데이터셋 예제
val path = "examples/src/main/resources/people.json"
case class Person(name:String, age:Long)
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()Data Frame vs Data Set
- 풍부한 의미 체계, 높은 수준의 추상화 및 도메인별 API를 원하는 경우 DataFrame 또는 Dataset을 사용하자
- 처리에 고급 표현식, 필터, 맵, 집계, 평균, 합계, SQL 쿼리, 열 형식 액세스 및 반구조화된 데이터에 대한 람다 함수 사용이 필요한 경우 DataFrame 또는 Dataset을 사용하자.
- 컴파일 시간에 더 높은 수준의 유형 안전성을 원하고 유형이 지정된 JVM 개체를 원하고 Catalyst 최적화를 활용하고 Tungsten의 효율적인 코드 생성의 이점을 얻으려면 Dataset을 사용하자.
- Spark Libraries에서 API의 통합 및 단순화를 원하면 DataFrame 또는 Dataset을 사용하자.
- R 사용자라면 DataFrames를 사용자.
- Python 사용자인 경우 DataFrames를 사용하고 더 많은 제어가 필요한 경우 RDD에 다시 의지하자.
SparkSQL 엔진
참조
- https://data-flair.training/blogs/apache-spark-rdd-vs-dataframe-vs-dataset/
- popit.kr/spark2-0-new-features1-dataset/
- https://seamless.tistory.com/53
