1. 통합 분석 엔진
하둡 단점
- API는 많은 양의 기본 셋업 코드가 필요하고, 장애 대응에 불안정
- 관리하기 쉽지 않음
- 맵리듀스 MR(태스크)필요로 하고 그 과정 로컬에 쌓아야함 ->(IO 증가)
- 작업이 대규모에만 한정적임
스파크란?
- 속도
- 효과적인 멀티스레딩, 병렬처리 지원하는 유닉스 기반OS, 내부 구현 효율적
- DAG의 스케줄러와 질의 최적화 모듈 => 클러스터 워커 노드 병렬 수행
- 텅스텐 엔진 => 간결한 코드 생성해낸다.
- 중간 결과는 메모리에만 유지되면 IO를 제한적으로 사용
- 사용 편리성
RDD => 단순성을 실현 트랜스포메이션, 액션의 잡힙과 단순한 프로그래밍 모델 제공 - 모듈성
- 다양한 타입의 워크로드 적용 가능
- 모든 프로그래밍 언어 표현가능
- 문서화과 잘된 API들로 이루어진 통합 라이브러리 제공
- 하나의 통합엔진에서 핵심 스파크 컴퍼넌트(spark sql, spark streaming)연동해서 사용가능
- 확장성
1.다양한 데이터 DB, 소스로부터 읽어들여 처리가능
단일화된 스택으로의 아파치 컴퍼넌트
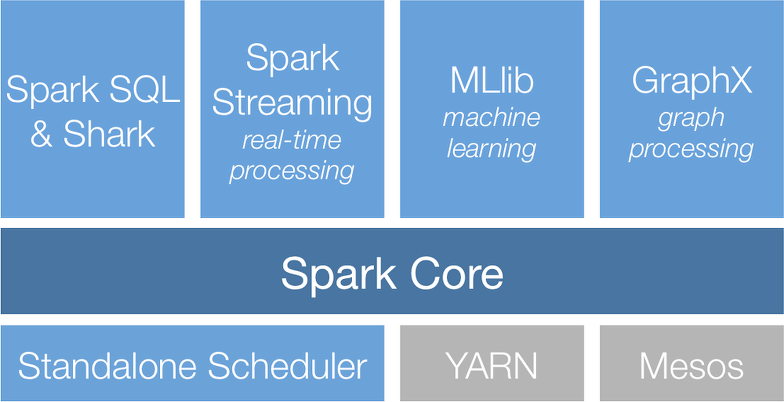
- Spark SQL
RDBMS와 같은 테이블 혹은 구조화된 데이터 파일 포멧(json) 데이터 읽어들일 수 있음 - MLlib
범용머신 알고리즘 라이브러리 제공 - 정형화 스트리밍
스트리밍 혹은 정적데이터 -> 새로운 레코드가 추가되는 형태로 본다. - GraphX
그래프를 조작하고 그래프 병렬 연산을 수행하기 위한 라이브러리 - Cluster Managerduler
아파치 스파크 분산실행
하나의 드라이버 프로그램으로 이루어진다. 드라이버는 SparkSession 객체를 통해 클러스터의 분산 컴퍼넌트들로 이루어진다.
- 스파크 드라이버
- SparkSession객체 초기화역할
- 클러스터 매니저와 통신 스파크 executor들에게 필요한 자원요청
- 모든 스파크 작업 DAG연산 형태로 변환하고 스케줄링및 태스크로 나누어 executor들에게 분배
- SparkSession
모든 스파크 연산과 데이터에 대한 통합 연결 채널이 되었다. 스파크 작업을 간단하고 쉽게만들어줌
연결채널을 통해 jvm 실행 파라미터 만들고, 데이터 프레임이나 데이터 세의 정의, 데이터 접근, SQL질의 실행 가능하다. 모든 스파크 기능을 한군데에서 접근할수 있는 시작점 제공
클러스터 매니저
- STANDALONE, YARN, MESOS, KUBNETES
spark executor
클러스터의 어쿼 노드에서 동작, 태스크 실행 역할한다. 배포모드에서는 노드당 하나의 executor만 실행된다.
분산 데이터와 파티션
물리적인 데이터는 HDFS나 클라우드 저장소에 존재하는 파티션이 되어 저장소 전체에 분산된다.
executor는 가급적 데이터 지역성 고려해서 네트워크에서 가장 가까운 파티션을 읽어 들이도록 태스크 할당한다.
파티셔닝은 효과적인 병렬 처리 가능하게한다. => 데이터 청크, 파티션 분산저장해서 네트워크 사용 최소화하며 가까이 있는 데이터만 처리하게 해준다.

끈임없이 발전하자.