[러닝 스파크 Chapter4] Spark SQL과 데이터 프레임: 내장 데이터 소스
1. SparkSql 특징
-
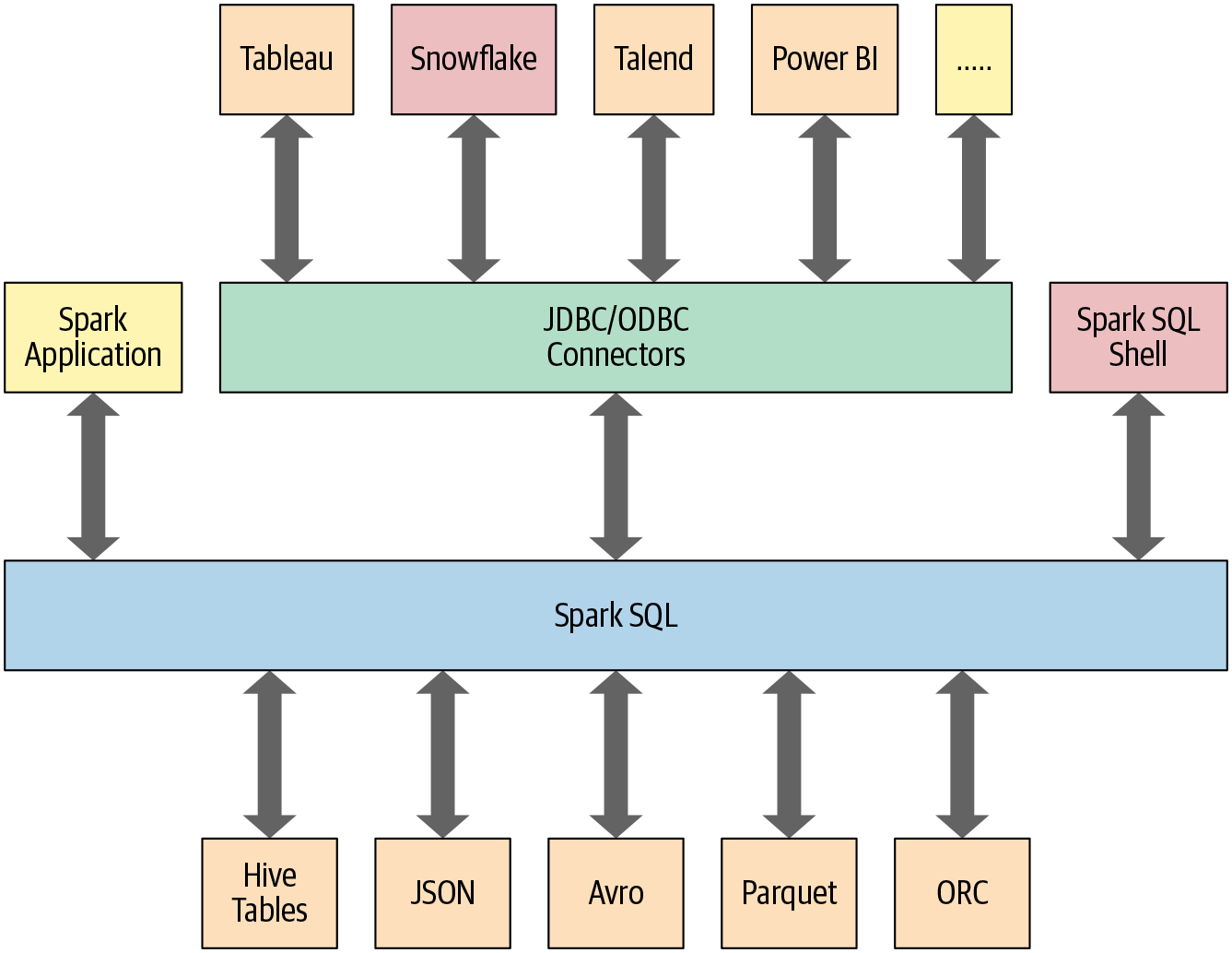
다양한 구조화된 형식(예: JSON, Hive 테이블, Parquet, Avro, ORC, CSV)으로 데이터를 읽고 쓸 수 있습니다.
-
Tableau, Power BI, Talend와 같은 외부 비즈니스 인텔리전스(BI)부터 MySQL 및 PostgreSQL과 같은 RDBMS등 에서 JDBC/ODBC 커넥터를 사용하여 데이터를 쿼리할 수 있습니다.
-
Spark 애플리케이션의 데이터베이스에 테이블 또는 view로 저장된 정형 데이터와 상호 작용할 수 있는 프로그래밍 방식 인터페이스를 제공합니다.
-
정형 데이터에 대해 SQL 쿼리를 실행하기 위한 대화형 셸을 제공합니다.
SParkSql 사용하기
SparkSession은 정형화 API로 스파크를 프로그래밍하기 위한 진입점을 제공한다. SparkSession을 이용하면 쉽게 클래스를 가져오고 코드에서 인스턴스 생성 가능하다.
예제
// 스칼라 예제
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("SparkSQLExampleApp")
.getOrCreate()
// dataset 경로
val csvFile="/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
// csv load
val df = spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.load(csvFile)
// 임시뷰 생성
df.createOrReplaceTempView("us_delay_flights_tbl")
//shema생성
val schema = "date STRING, delay INT, distance INT,
origin STRING, destination STRING"
// spark 쿼리
spark.sql("""SELECT distance, origin, destination
FROM us_delay_flights_tbl WHERE distance > 1000
ORDER BY distance DESC""").show(10)
//DataFrame이용
(df.select("distance", "origin", "destination")
.where(col("distance") > 1000)
.orderBy(desc("distance"))).show(10)
SQL 테이블과 뷰
중앙 메타스토어에 저장됩니다.
Spark 테이블에 대해 별도의 메타스토어를 사용하는 대신 Spark는 기본적으로 /user/hive/warehouse에 있는 Apache Hive 메타스토어를 사용하여 테이블에 대한 모든 메타데이터를 유지합니다. spark.sql.warehouse.dir그러나 Spark 구성 변수 를 로컬 또는 외부 분산 저장소로 설정할 수 있는 다른 위치 로 설정하여 기본 위치를 변경할 수 있습니다.
관리형 테이블 vs 비관리형 테이블
관리형
- 메타데이터, 파일 저장소의 데이터를 모두 관리한다.
- 파일 저장소는 HDFS, S3, Azule Blob과 같은 객체 저장소일 수 있다.
- Drop Table과 같은 명령은 메타,실제 데이터 모두 삭제한다.
- 데이터 생성 예제:
# In Python
csv_file = "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv"
schema="date STRING, delay INT, distance INT, origin STRING, destination STRING"
flights_df = spark.read.csv(csv_file, schema=schema)
flights_df.write.saveAsTable("managed_us_delay_flights_tbl")비관리형
- 오직 메타데이터만을 관리하고, 외부 데이터 소스에서 데이터 직접 관리
- 데이터 삭제 시 메타 데이터만 삭제한다.
- 데이터 생성 예제
( flights_df
.write
.option("경로", "/tmp/data/us_flights_delay")
.saveAsTable("us_delay_flights_tbl"))
뷰 생성하기
사용법
- native sql
df_sfo = spark.sql("SELECT date, delay, origin, destination FROM
us_delay_flights_tbl WHERE origin = 'SFO'")- dataframe api
//전체뷰
df_sfo.createOrReplaceGlobalTempView("us_origin_airport_SFO_global_tmp_view")
//임시뷰
df_jfk.createOrReplaceTempView("us_origin_airport_JFK_tmp_view")임시뷰 vs 전역 뷰
임시뷰: SparkSession에서만 접근가능
전체뷰: 전체 Sesisond에서 접근가능
메타데이터 보기
spark.catalog.listDatabases()
spark.catalog.listTables()
spark.catalog.listColumns("us_delay_flights_tbl")SQL테이블 캐싱
데이터 프레임 및 SQL 테이블을 위한 데이터 소스
DataFrameReader
데이터 소스에서 데이터프레임으로 데이터를 읽기 위한 핵심 구조이다.
- 사용패턴: format().option().schema().load() ..
DataFrameReader.format(args).option("key", "value").schema(args).load()- format: "parquet", "csv", "txt", "json", "jdbc" ..
- option: 일련의 key, value 옵션이다. 기본모드는 PERMISSIVE이다.
- shema: 스키마를 유출 할 수있다.
- load: 데이터 소스 경로이다. option에 path가 지정된 경우 비워둘 수 있다.
- 예
val file = """/databricks-datasets/learning-spark-v2/flights/summary-data/parquet/2010-summary.parquet"""
val df = spark.read.format("parquet").load(file)
// Use Parquet
val df2 = spark.read.load(file)
// Use CSV
val df3 = spark.read.format("csv")
.option("inferSchema", "true")
.option("header", "true")
.option("mode", "PERMISSIVE")
.load("/databricks-datasets/learning-spark-v2/flights/summary-data/csv/*")
// Use JSON
val df4 = spark.read.format("json")
.load("/databricks-datasets/learning-spark-v2/flights/summary-data/json/*")DataFrameWriter
지정된 내장 데이터 소스에 데이터를 저장하거나 쓰는 작업을 수행한다. SparkSession이 아닌 저장하려는 데이터 프레임에서 인스턴스에 엑세스가능하다.
DataFrameWriter.format(args)
.option(args)
.bucketBy(args)
.partitionBy(args)
.save(path)
DataFrameWriter.format(args).option(args).sortBy(args).saveAsTable(table)파케이
- 장점
높은 압축률. 칼럼 단위로 구성하면 데이터가 더 균일하므로 압축률이 높아진다.
데이터를 전체 칼럼중에서 일부 칼럼을 선택해서 가져오는 형식이므로 선택되지 않은 칼럼의 데이터에서는 I/O가 발생하지 않게된다.
칼럼에 동일한 데이터 타입이 저장되기 때문에 칼럼별로 적합한(데이터형에 유리한) 인코딩을 사용할 수 있다.
요약
SparkSql을 사용했을때 다음과 같은 이점을 얻을 수 있다.
- Spark SQL, DataFrameAPI를 사용하여 관리형 및 비 관리형 테이블을 생성할 수 있다.
- 다양한 내장 데이터 소스 및 파일 형식을 읽고 쓸 수 있다.
- Spark SQL 테이블 또는 뷰로 저장된 정형화 데이터에 spark.sql 프로그래밍 인터페이스를 사용하여 SQL쿼리를 실행 할 수 있다.
- 스파크 카탈로그를 통해 테이블 및 뷰와 관련된 메타데이터를 검사할 수 있다.
- DataframeWriter, DataFrameReader API를 사용할 수 있다.
