TDL
NOTE2
자료구조의 활용
-
Searching 검색
- 특정 노드를 추가하거나 삭제를 위해서는 검색이 우선되어야 함
- 다양한 알고리즘을 활용하는 경우, 최적 알고리즘 경로를 측정하는데 쓰임.
- 검색하는 컬렉션이 무작위이고 정렬되지 않은 경우, 선형검색이 기본적인 검색방법이다.
-
Recursion 재귀
- 알고리즘과 방법론에서 자주 언급되고, 중요한 개념이니 반복 학습 중요!
- 재귀의 개념은 수학적 사고에 기반하고, 코드를 작성하기 전에 문제를 해결하는 재호출 로직을 발견해야한다. 수학공부하는 것처럼 직접 손으로 많이 풀어보기!
- 재귀 호출은 스택의 개념이 적용되며, 함수의 내부는 스택처럼 관리된다.(LIFO, 후입선출)
- 단점: 재귀를 사용하면 함수르 반복적으로 호출되는 상황이 벌어지므로, 메모리를 더 많이 사용하게 된다.
- 수학적으로 개념이 복잡한 경우에는 시간과 공간(메모리)복잡도 측면에서 효율이 안좋더라도 재귀를 사용해 문제를 해결하는 것이 좋다.
-
재귀로 문제 해결하기
- 해결할 수 있는 하위의 하위 문제로 나누기!
- 재귀적으로 다양한 문제를 해결할 수 있는데, 대표적으로 '분할정복법'이 있다.
- 재귀에서 중점적으로 생각해야할 부분은 조건에 따른 반복 계산이다.
-
분할정복법
- 하나의 문제를 분할하면서 해결하고 해결 후 다시 하나로 합치는 방법
- 재귀는 해결을 위한 특정 기능을 재호출한다는 측면이고, 분할정복은 문제를 분할하고 해결하는 구체적인 방법론이다.
-
재귀의 조건(규칙)
1) base case(기본 조건)이 있어야한다.
- 알고리즘은의 반복을 중지할 수 있다.
2) 추가조건과 기본 케이스의 차이를 확인한다.
3) 반드시 자기 자신(함수)를 호출해야 한다. -
트리(Tree)
- 루트(root): 가장 위쪽에 있는 노드 (단 1개)
- 서브트리 : 부모노드+자식노드의 역할을 모두 하는 트리
- 차수 : 최대 자식노드의 수
- 리프(leaf) : 가장 마지막에 있는 노드 (teraminal node, external node)
- level : 루트노드에서 얼마나 멀리 떨어져 있는지. 트리의 층. level 0, level1 등
- 높이 : level의 최대값
- sibling(형제) : 부모가 같은 노드
-
binary tree(이진트리)
: 노드별로 최대 2개의 서브 노드를 갖는 것. (left, right- 트리종류 중 가장 기본
- 왼쪽부터 오른쪽으로 검색하는 구조 (연결리스트를 참조해 만들어졌기때문)
- 이진트리의 2가지 조건
- 루트노드를 중심으로 두 개의 서브트리로 나눠짐- 나눠진 두 서브트리도 모두 두 개의 서브트리(노드값이 없을 수 있음)를 갖는다.
-
이진트리의 종류
1) 포화 이진 트리
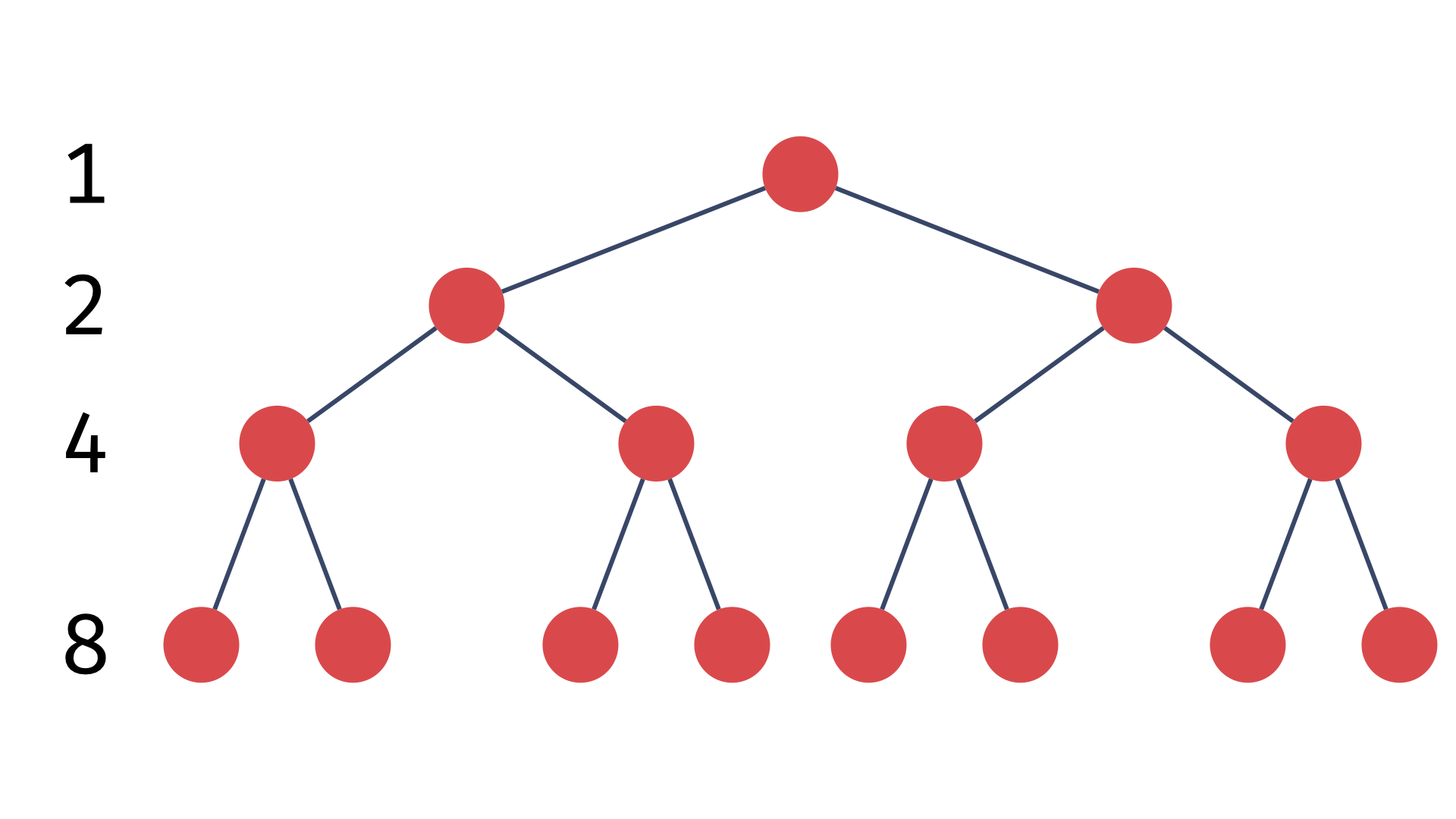
2) 완전 이진 트리
-
노드가 위에서 아래로 채워짐
-
노드가 왼쪽에서 오른쪽 순서대로 채워짐
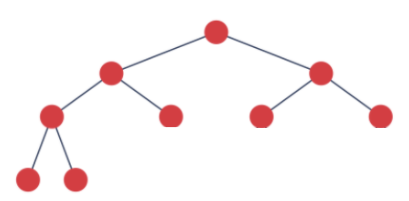
3) 이진 검색 트리 (Binary Search Trees, BST)
-
노드를 정확하게 정렬하는 특정 유형의 이진 트리.
-
값 크기 조건 : right child > root node > left child (중복값x)
-
검색하는 순서에 따라 노드값을 오름차순으로 얻는다
-
검색이 쉽기 때문에 노드를 삽입하기 쉽다.
-
천천히 소스코드의 흐름과 이론에서의 흐름을 매핑하면서 이해하는 것이 중요하다.
-
자료구조의 연결리스트, 큐, 스택을 구현한 로직과 비슷한 맥락
-
로직에 따라 값을 교환하는 흐름을 봐야한다.
-

https://gggggeun.tistory.com/