TDL
알고리즘과 자동화
NOTE 3
-
정렬 알고리즘 : 모든 알고리즘의 기반. 숫자 두개 크기 비교->바꾸기->반복 순서맞추기.
-
문자열 메소드 : 예외처리 대신 사용하기 좋음.
PYTHON 문서 - 문자열 메소드
- strip()
- split()
-
swap (교환)
-
선형검색(linear search) : 기본. 한 번에 하나씩 모두 검색. 반복문 사용
-
이진검색(Binary search) : 반복으로 숫자를 반으로 줄이면서 검색. 선형보다 속도 빠름.
- 이미 정렬된 경우에만 작동. log2() = 2진수 시스템 작동
- 리스트를 처음 얻을 때 두 개의 다른 리스트(참조요소)를 설정해야함.
-
이진검색을 통한 알고리즘 원리 알기
- 알고리즘 활용의 기본은 상수계산이다.
- 상수계산은 쉽지만 복잡한 계산을 하려면 반복을 많이 사용 -> 시간,메모리 많이 소비.
- 그렇기 때문에 반복문과 조건문, 연산자 등을 활용해 효율적인 알고리즘 생성.
- 이진검색은 정렬된 선형의 숫자들 중 특정 숫자를 효율적으로 검색하기 위해 나온 방법.
- 즉, 모든 알고리즘의 기본 원리는 숫자와 조건을 활용해 발전시키는 것.
-
선택 정렬(Selection Sort)
- 가장 작은 노드 선택 후 맨 왼쪽 자리부터 교환하기. 반복.
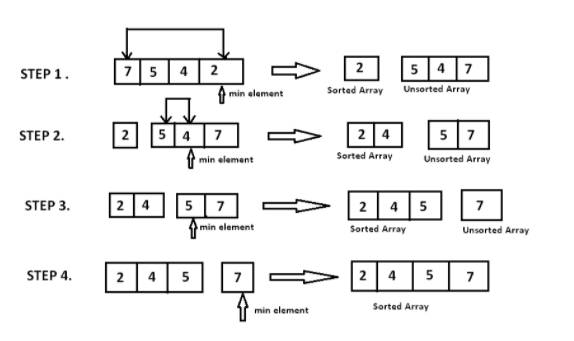
- complexity analysis(복잡도 분석) : 버블정렬과 달리 서로 이웃하지 않는 노드를 교환하므로, 안정적이지 않음.
- 노드값 비교 횟수 : O(n^2)
- 외부루프 : O(n-1)- 내부루프(최솟값찾기) : O((n-1),(n-2),...,2,1)
- 교환횟수 : 3(n-1)
- 가장 작은 노드 선택 후 맨 왼쪽 자리부터 교환하기. 반복.
-
삽입정렬(Insertion Sort)
- 선택한 노드보다 작은 값을 갖고 있는 노드가 나올때까지 비교.
- 아직 정렬되지 않은 특정 노드와 정렬된 노드들의 값을 비교하고 값이 작은 인덱스에 삽입하며 정렬하는 알고리즘.
- 선택정렬과 다른 점은 값이 가장 작은 원소를 선택하지 않는것.
- 비교 후 삽입을 동시에 진행.
- 소량의 데이터를 정렬에 효율적인 알고리즘.
- 선택과 버블정렬과는 달리, 정렬을 진행하면서 비교 및 탐색해야할 정렬 범위가 넓어짐.
- 복잡도 분석 : 최상인 경우(이미정렬)에서 O(n)시간에서 수행되고, 최악 및 평균의 경우 O(n^2)에 실행.
- 정렬된 경우, 배열의 각 항목을 통해 올바른 위치에 있는지 확인.- 오름차순 기준 최악의 경우는 내림차순(반대로 정렬된 경우) 이다.
- 내림차순을 오름차순으로 하려면 높은 숫자 항목을 오른쪽으로 이동시키기 위해 최대 반복 횟수를 수행해야 하며 시간복잡도가 O(n^2)이다.
-
버블정렬(Bubble Sort)
- 서로 이웃한 두 원소의 크기를 비교한 결과에 따라 교환을 반복(=단순 교환 정렬)
- 가장 간단한 정렬 알고리즘 중 하나. 매우 비효율적.
- 이미 정렬된 경우에도 모든 항목을 검사해야함.
- O(n^2) -> 무조건 n번 반복하니까
- 이웃노드만 교환해서 안정적임
- 노드 비교 횟수 : (n-1)+(n-2)+...+1 = n(n-1)/2 중첩반복문 사용.

https://gggggeun.tistory.com/