TDL
NOTE4
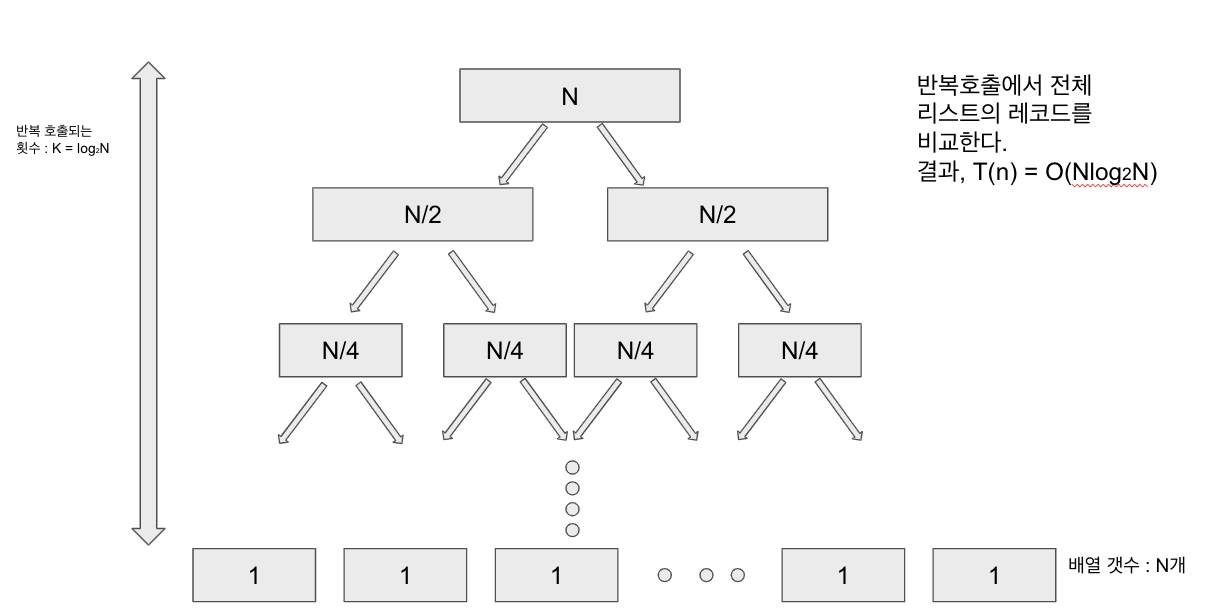
- 분할정복 (Divide and Conquer) 알고리즘
- 비슷한 크기로 문제를 분할하고, 해결된 문제를 제외하고 동일한 크기로 문제를 다시 분할.
- 과정 : 1) 본 문제를 서브문제로 분할(divide). 2) 서브문제의 답들을 구하고, 본 문제에 대한 답이 되도록 병합(merge) 3) 문제를 분할할 수 없거나, 할 필요없는 경우에 대한 답을 구함(base case, 기본케이스)
- 조건 : divide(본문제를 서브문제로 분할할 수 있는가?), merge,conquer(서브문제의 답을 병합(또는 조합)하여 본 문제의 답을 구하는 것이 효율적인가?
- 복잡하거나 큰 문제를 여러개로 나눠 푸는 방법.
- 병렬적으로 문제를 해결할 수 있음.
- 문제해결함수가 재귀적으로 호출될 수 있으므로 메모리가 추가적으로 사용될 수 있음.
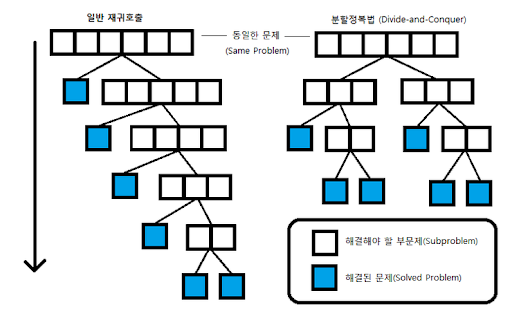
- 재귀호출과 분할정복의 차이
- 재귀호출 : 같은 함수코드를 재호출하는것 (같은 함수코드 사용)
- 분할정복 : 비슷한 작업을 재진행하는 것 (같은 함수코드가 아닐 수 있음)
-
퀵 정렬 (Quick Sort)
-
처음에 전체 탐색을 할 때 좌우로 나눠 재귀적으로 수행하기 때문에 병합정렬보다 빠르다. (파티션나누기 -> 피벗 중심으로 양쪽 영역나누기 -> 나뉜 영역 중심으로 재귀호출을 진행하는 분할정복구조를 갖음)
-
퀵정렬의 시간복잡도가 병합정렬보다 크다.(둘다 nlogn정도)
-
퀵소트는 한정적인 범위에서 데이터를 정렬하기 때문에 캐시를 덜 활용하고, 하드웨어적으로 효율적임.
-
퀵소트도 분할정복을 통해 정렬하고, 피벗이라는 별도의 노드를 지정해두고 재귀적으로 수행을 함.
-
성능이 우수함에도 성능편차가 크고, 피벗(노드)설정 등 다루기 어려운 점이 존재하기 때문에 실물에서는 활용되기 어려움.
-
불안정 정렬의 대표적인 경우로서, 노드 값이 중복되는 경우에는 계속해서 swap(교환)을 시도함. (정렬을 진해하는 경우 중복값의 순서가 유지되지 않는 경우가 있다.)
-
최악의 경우에 첫번째 노드를 피벗으로 설정하고, 불균형하게 분할정복을 시도하여 성능이 안좋아짐.
-
-
병합정렬 (Merge Sort)
- 분할과 교체를 반복. 시간을 들여 1개의 서브리스트가 나올때까지 분할을 진행
(비교->정렬-> 교환 후 합치기 과정 반복) - 분할정복 로직으로 인해, 전체 데이터를 기준으로 처음과 끝을 계속해서 탐색하기 때문에 퀵소트에 비해 느림.
- 퀵소트보다 빠르지는 않지만, 안정(stable) 정렬이기 때문에 데이터가 중복되었더라도 영향을 덜 받음.
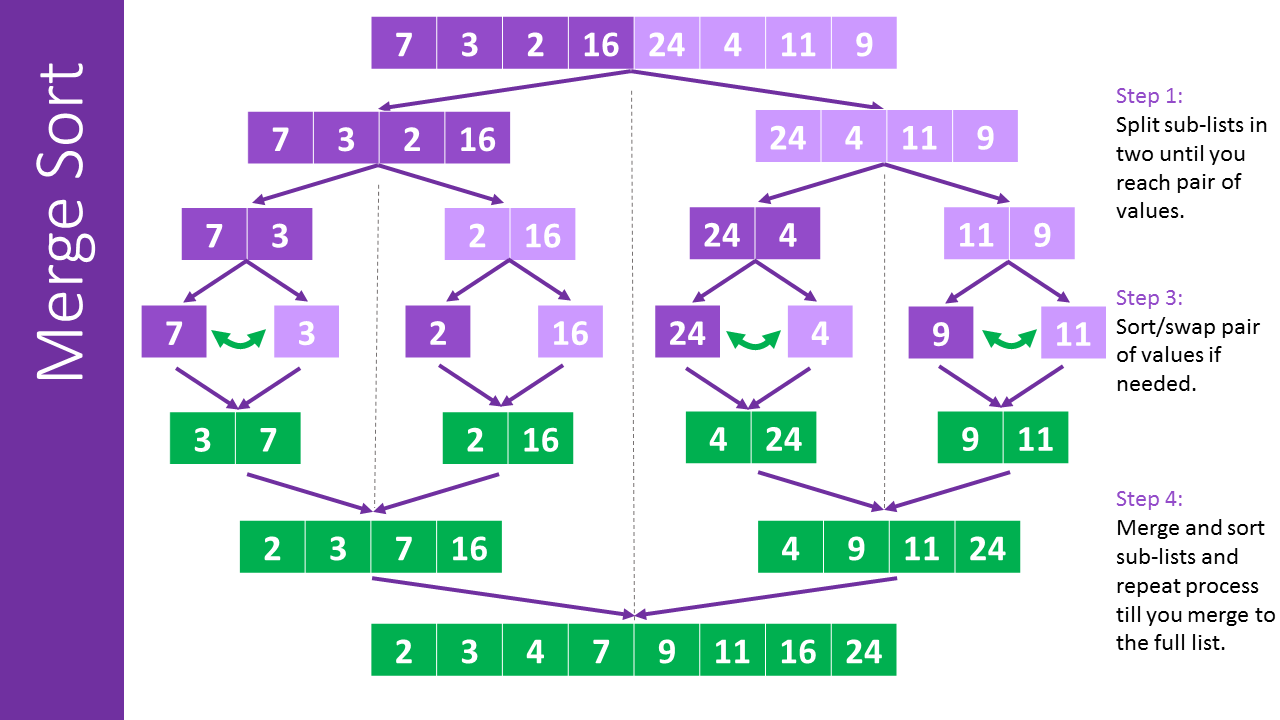
- 분할과 교체를 반복. 시간을 들여 1개의 서브리스트가 나올때까지 분할을 진행
-
성능
- 속도는 알고리즘을 처리하고 결과를 도출하는 속도(주로 소프트웨어에 영향을 주고받음)
- 성능은 메모리에 영향을 주는 정도(주로 하드웨어에 영향을 주고 받음)
-
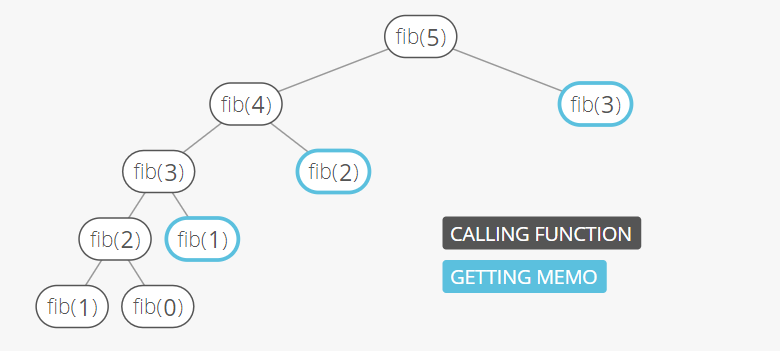
메모이제이션(memoization)
- 반복되는 계산 결과를 특정 변수에 저장하고, 재사용하는 방법.
- 분할된 서브문제를 해결하기 위해, 반복되는 해결법을 재사용하는 기법. (Dynamic Programming에서 활용)
- 미리 계산한 값을 재사용하므로 프로그램 실행속도를 빠르게 해줌.
- 동일한 입력을 가진 함수를 처음 호출할 때만 전체 호출 비용이 발생하도록 한다.
- 함수의 시간 복잡도를 감소히키고, 공간 복잡도를 증가시킨다.
memoizaiton : 컴퓨터 작업을 위한 소프트웨어 기술
memorization : 과학분야에서 범용적으로 쓰일 수 있는 기법 또는 전략. -
특수 케이스(Edge Cases)
- 주어진 조건에서 숫자나 문자 조건이 일정범위를 벗어난 경우.

https://gggggeun.tistory.com/