.png)
Review
Section 1에서는 선형회귀,릿지회귀 그리고 로지스틱에 대해 배웠다.
이번 Section 2 의 note1에서는 결정트리(Decision tree)를 배운다.
로지스틱 등을 공부하면서 자꾸 결정트리라는게 튀어나왔는데, 뭘까 궁금했지만 회귀만으로도 벅차 차마 쳐다 볼 수도 없었다 ㅋㅋㅋㅋㅋㅋㅋㅋ 이번주는 드디어 결정트리라는 것을 알게 된다.
이 결정트리는 나중에 앙상블 이라는 것을 배우는데 중요한 기초라고 말씀하셨다.
아직 저번주 회귀가 정리가 다 안됐는데 그래도 이전 내용과 많이 부딪히지는 않을 것 같아서 안심이다.
아아 ! 또한 내가 정말정말 궁금했떤 pipeline 도 나온다! 저번에 읽은 어느 한 Data science 분이 썼던 글에서 회귀분석은 pipeline의 일부분이다! 라고 쓴 글을 보았기 때문이다. 회귀가 나무라면 pipeline은 숲? 이겠지? 이번주도 화이팅하자!
TDL
NOTE1
-
전처리
중복데이터 처리
train.T.duplicated()
카테고리형 원소개수 확인 (cardinality)
train.describe(exclude='number').T.sort_values(by='unique')
카테고리 원소 개수 확인
train['열 이름'].value_counts() -
판다스 프로파일링(minimal)
from pandas_profiling import ProfileReport profile = ProfileReport(train, minimal=True).to_notebook_iframe() -
pipline
sklearn.pipline.Pipeline
Pipelines and composite estimators
from category_encoders import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipelinepipe = make_pipeline(OneHotEncoder(),SimpleImputer(),StandardScaler(),LogisticRegression(n_jobs=-1))
pipe.fit(X_train, y_train)
print('검증세트 정확도', pipe.score(X_val, y_val))
y_pred = pipe.predict(X_test) -
결정트리(Decision Tree)
Node 질문이나 말단의 정답 / Edge 노드를 연결하는 선
처음 Root node / 중간 internal node / 말단 external,leaf,terminal node
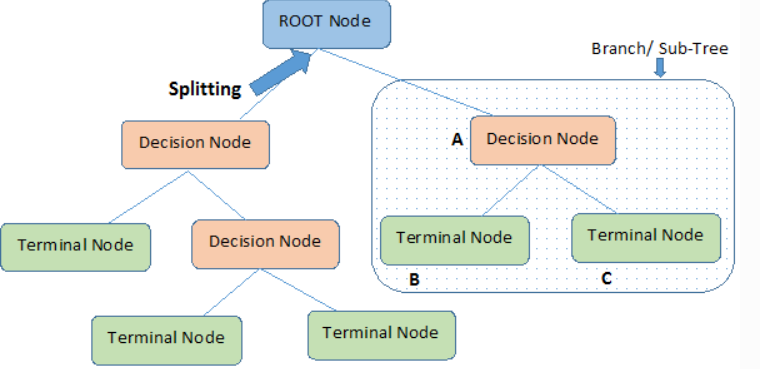
-
기준모델 : 분류 (최빈값) + 정규화
y_val.value_counts(normalize=True) -
Gini Impurity or Gini Index (지니 불순도)
-
Entropy (엔트로피)
-
Imformation Gain(정보획득)
특정한 특성을 사용해 분할했을 때 엔트로피의 감소량.
(분할 전 node gini - 분할 후 node gini) -
사이킷런으로 결정트리 구현하기
sklearn.tree.DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
pipe = make_pipeline(OneHotEncoder(use_cat_names=True),SimpleImputer(), DecisionTreeClassifier(random_state=2, criterion='entropy')) pipe.fit(X_train, y_train)
print('훈련 정확도: ', pipe.score(X_train, y_train))
print('검증 정확도: ', pipe.score(X_val, y_val))
-
결측값 대치하기 (Imputation of missing values)
Imputation of missing values -
과적합(overfitting)
학습데이터의 정확도는 높게나오지만, validation 또는 test data는 기준모델과 비슷하다면 과적합이라고 볼 수 있다. -
과적합을 줄이기 위한 hyperparameters
sklearn.tree.DecisionTreeClassifier
min_samples_split
DecisionTreeClassifier(min_samples_split=10, random_state=2)
min_samples_leaf : external node에 최소한 존재해야 하는 샘플의 수 지정
DecisionTreeClassifier(min_samples_leaf=10, random_state=2)
max_depth
DecisionTreeClassifier(max_depth=6, random_state=2)
-
결정트리의 특성중요도 (feature importance)
선형모델에서는 특성과 타겟의 관계를 확인하기 위해 회귀계수(coefficients)를 봤다면,
결정트리에서는 특성중요도를 확인해 볼 수 있다. 특성중요도는 회귀계수와 다르게 항상 양수값을 가진다. 이 값을 통해 특성이 얼마나 자주, 일찍 분기에 사용되는지 결정된다.
model_dt = pipe.named_steps['decisiontreeclassifier']
importances = pd.Series(model_dt.feature_importances_, encoded_columns) plt.figure(figsize=(10,30)) importances.sort_values().plot.barh(); -
결정트리모델의 장점
선형모델과 달리 비선형, 비단조(non-monotonic), 특성상호작용(feature interactions)에 영향을 덜 받아 데이터 분석에 더 용의하다. -
회귀트리 (그래프)
import graphviz
(jupyterlab 사용시: jupyter labextension install @jupyter-widgets/jupyterlab-manager)
from ipywidgets import interact
from sklearn.tree import DecisionTreeRegressor, export_graphviz
from sklearn.tree import DecisionTreeRegressor -
회귀트리 + interact
from ipywidgets import interact
from sklearn.tree import DecisionTreeRegressor, export_graphviz
